当前位置:网站首页>TensorFlow2学习笔记:6、过拟合和欠拟合,及其缓解方案
TensorFlow2学习笔记:6、过拟合和欠拟合,及其缓解方案
2022-08-04 05:28:00 【不负卿@】
1、什么是过拟合、欠拟合
无论在机器学习还是深度学习建模当中都可能会遇到两种最常见结果,一种叫过拟合(over-fitting )另外一种叫欠拟合(under-fitting)。
过拟合
定义:过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差。通俗一点地来说过拟合就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差。
欠拟合
定义:欠拟合是指模型在训练和预测时表现都不好的情况,反映到评估指标上,就是模型在训练集和测试集上的表现都不好。欠拟合就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
直观表现,如下图:
回归算法中的三种拟合状态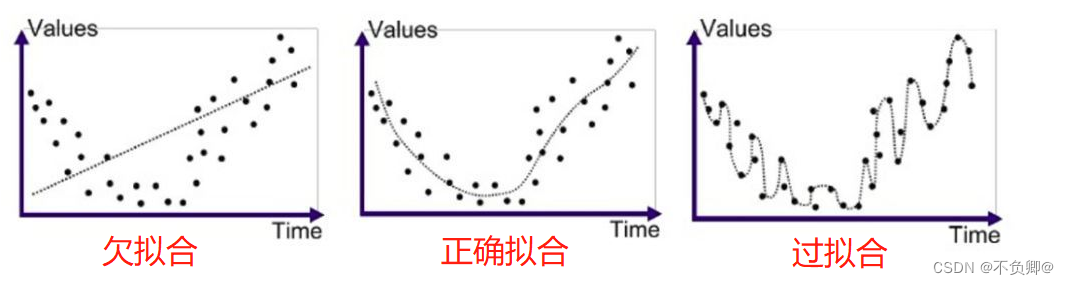
分类算法中的三种拟合状态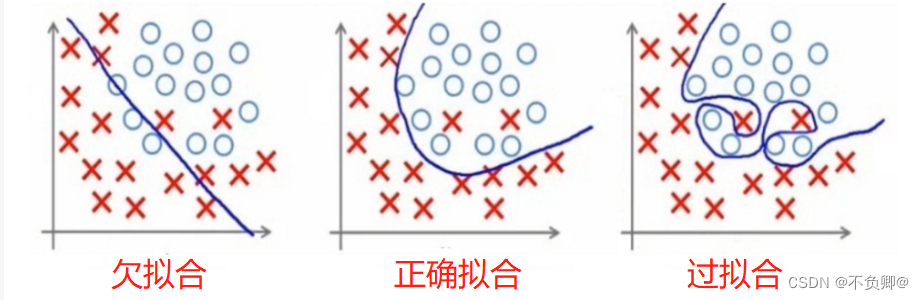
2、过拟合解决方法
- 清洗数据
- 增大训练集
- 采用正则化
- 增大正则化参数
3、欠拟合解决方法
- 清洗数据
- 增大训练集
- 采用正则化
- 增大正则化参数
4、正则化及使用方法

- L1正则化:对所有参数w的绝对值求和。大概率会将很多参数变为0,因此该方法可通过稀疏参数(即减少参数的数量),降低复杂度。
- L2正则化:对所有参数w的平方绝对值求和。使参数接近0 但不为0,因此该方法可通过减小参数值,降低复杂度。减少因数据集中的噪声引起的过拟合。

边栏推荐
猜你喜欢


随机推荐
CTFshow—Web入门—信息(9-20)
编程Go:return、break、continue
Shell(2)数值运算与判断
flink问题整理
自动化运维工具Ansible(4)变量
什么是跨域和同源
剑指 Offer 2022/7/9
oracle临时表与pg临时表的区别
k3s-轻量级Kubernetes
简单说Q-Q图;stats.probplot(QQ图)
SQL练习 2022/7/4
编程Go:内置打印函数 print、println 和 fmt 包中 fmt.Print、fmt.Println 的区别
【树 图 科 技 头 条】2022年6月27日 星期一 今年ETH2.0无望
SQL的性能分析、优化
(十三)二叉排序树
(九)哈希表
[NSSRound#1 Basic]
智能合约安全——delegatecall (2)
MySql的concat和group_concat的区别
关系型数据库-MySQL:约束管理、索引管理、键管理语句