当前位置:网站首页>Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
2022-07-04 06:59:00 【mytzs123】
code: https://github.com/zhaominyiz/RFDA-PyTorch.
 Includes two main components : Space-time feature fusion (STFF) modular , For temporal feature fusion , Quality enhancement (QE) modular , Used to reconstruct fused features . And in the STFF Module , Recursive fusion (RF) Module is the key to fuse multiple frames in a large time range .
Includes two main components : Space-time feature fusion (STFF) modular , For temporal feature fusion , Quality enhancement (QE) modular , Used to reconstruct fused features . And in the STFF Module , Recursive fusion (RF) Module is the key to fuse multiple frames in a large time range .
ABSTRACT
Many algorithms based on deep learning have been proposed to recover high-quality video from low-quality compressed video . among , Some recover the missing details of each frame by mining the spatio-temporal information of adjacent frames . However , These methods usually have a narrow time horizon , Therefore, some useful details other than adjacent frames may be lost . In this paper , In order to improve the artifact removal rate , One side , We propose a recursive fusion (RF) Module to model the time dependence in a long time range . To be specific ,RF Use the current reference frame and the previous hidden state to make better space-time compensation . On the other hand , We designed an efficient deformable space-time attention (DSTA) modular , This model makes it possible to recover the regions with abundant artifacts such as the boundary region of moving objects more diligently . A lot of experiments show that , stay MFQE 2.0 On dataset , Our method is superior to the existing methods in terms of fidelity and perceptual effect .
1 INTRODUCTION
Now , Lossy video compression algorithm ( for example H.264 \/ Video compression algorithm [28] and H.265 \/ Video compression algorithm [23]) It is widely used to reduce the cost of video storage and transmission . As the compression ratio increases , These algorithms greatly reduce the bit rate , But it also introduces unwanted artifacts , Thus seriously reducing the quality of experience (QoE). Besides , Artifacts in low-quality compressed video will also damage the performance of tasks facing downstream video ( for example , Action recognition and positioning [29,43], Video summary [1,32]). therefore , Video compression artifact reduction has become a hot topic in the multimedia field , Its purpose is to reduce the introduced artifacts and recover the details lost in the severely compressed video [7、11、21、33、34、36]. In recent years , There are many compression artifact removal methods based on deep neural network , Its performance has been significantly improved . These jobs can be roughly divided into three types : Work based on a single image [5、9、12、16、24、41], Work based on various video compression priorities [6、14、39], And work based on additional time information [7、8、11、19-21、33-35、37]. To be specific ,[9、16、41] For enhancement JPEG Designed for quality . These methods can adapt to the video by restoring each frame separately .[6、14、39] in consideration of I \/P \/B Frames are compressed with different strategies , It should be handled by different modules , They take a single frame as input , Ignoring the time information of the video . In order to make up for this defect ,[11,21] Use the two most recent high-quality peak quality frames (PQF) As a reference frame ,[19,20] Use the depth Kalman filter network and capture spatiotemporal information from the previous frame ,[7,33] Use nonlocals separately convlsm And deformable convolution to capture the dependencies between multiple adjacent frames . in summary , Recent work uses the previous frame 、 Nearby PQFs Or multiple adjacent frames are used as reference frames to utilize the spatio-temporal information between video frames . Although these methods have made great progress in this regard , But their performance is still limited by the narrow time range , This makes them unable to make full use of the spatiotemporal information in the previous frame .
In order to solve the above problems , One side , We propose a recursive fusion (RF) Module to reduce video compression artifacts . To be specific , In order to use relevant information in a large time range , We have developed a recursive fusion scheme , And recursively combine the previous compensation feature with the current feature with limited additional computational cost . chart 1 It is shown that RF Examples of using details from distant frames . As we can see , When not used RF When the module , We cannot recover the 56 Details in the frame , And we use RF The modular approach can be achieved by utilizing 49-51 The corresponding area in the frame successfully recovers the details of the area between the two scoreboards . This is due to the increase of the time receptive field of the RF module . On the other hand , When rebuilding its high-quality version , It is unreasonable to treat different areas of the framework equally . for example : The boundary region of a moving object usually has serious distortion , Therefore, more attention should be paid to reducing artifacts . therefore , We design an effective and efficient deformable spatiotemporal attention mechanism (DSTA), Make the model pay more attention to the artifact rich area in the frame . here , stay RF After the module , The spatiotemporal correlation between frames is divided into different channels . therefore , After deformable convolution , Use the channel attention mechanism to align spatial information along the time dimension .
The main contributions of this paper are summarized as follows :
1、 We propose a recursive fusion module , More space-time information in video frames can be used in a larger time range , But the additional calculation cost is limited .
2、 We developed a deformable spatiotemporal attention mechanism , To guide the artifact rich region of the model in each frame .
3、 We are MFQE 2.0 A lot of experiments have been done on data sets , The superiority of this method is proved .
The rest of this article is organized as follows : The first 2 This section reviews the related work , It also emphasizes the difference between our method and the existing method based on multi framework . The first 3 Section describes the technical details of the proposed method . The first 4 Section introduces the empirical results , Including the performance comparison with the latest methods and ablation experiments , The first 5 Section summarizes the article .
2 RELATED WORK
In this part , We review the related work of video compression artifact reduction based on deep learning . According to the domain knowledge and the number of input frames used , The existing methods can be roughly divided into image-based methods 、 Single frame based method and multi frame based method .
Image-based approaches: These methods aim to solve JPEG Image quality enhancement 【5、9、10、13、16、17、40–42】. When applied to compressed video , These methods will extract a frame from the video , And enhance it without knowing the video compression algorithm . for example ,AR-CNN【9】 Four convolution layers are introduced to reduce JPEG Compression artifacts .DnCNN【41】 It is a deep model with batch normalization and residual learning .[5,40] Adopt wavelet \ Frequency domain information to enhance visual quality .NLRN【17】 and RNAN【42】 A deeper network with residual nonlocal attention mechanism is proposed , To capture the long-distance dependency between pixels .
Single-frame based approaches: In these methods ,[6、14、26、38、39] Using the knowledge of different coding modes in video compression algorithm ( for example I \/P \/B frame ), And adopt special strategies to deal with them . To be specific ,DS-CNN【39】 and QECNN【38】 Two independent models are proposed , Processing intra coding and inter coding modes respectively . However , These methods ignore the temporal continuity of video space , Make it difficult for them to deal with time noise .
Multi-frame based approaches:[19,20] The video compression artifact reduction task is modeled as a Kalman filter process , And capture time information from the enhanced previous frame , Recursively recover the current frame . They also combine the quantized prediction residuals in the compressed bitstream as strong prior knowledge . However , It is not enough to only use the time information of the previous frame , because B Frames are compressed by using the previous and subsequent frames as references .[11,21] Use nearby high-quality frames ( be called PQF) Establish time dependency . They first use classifiers to detect PQF, And then PQF As a reference frame to repair non PQF. In implementation , They first use optical flow for motion compensation , Then design a quality enhanced reconstruction network . later ,[37] An improved convolution is adopted LSTM To further use the useful information of frames in a large time range . Non local mechanism and deformable convolution network are used to capture spatiotemporal correlations in multiple adjacent frames respectively . lately ,[34] Use reference frame suggestions and fast Fourier transform (FFT) Loss to select high-quality reference frames , And focus on high-frequency information recovery .
Difference between our method and existing multi-frame based approaches:
Using spatiotemporal information has become the mainstream of video enhancement in recent years . However , The existing methods are limited by the time range , Unable to mine enough information from the video . This paper presents a new recursive fusion module , The module uses the hidden state and current features to expand the receiving field , Improve recovery performance . Besides , Because of the huge amount of computation , Traditional nonlocal attention is inefficient in this task , And treat different areas equally in each frame . therefore , We further developed an efficient deformable spatiotemporal attention (DSTA) Module to capture artifact rich areas , And make the model pay more attention to these areas , So as to obtain better recovery performance .
3 METHOD
In this section , We will introduce the technical details of our method . The architecture of our method is shown in Figure 2 Shown . Before describing in detail , We first discuss the problem of reducing artifacts in video compression , And the method is summarized .
3.1 Problem Formulation and Method Overview
Given compressed video V=[ ,
, ,...,
,..., ] from T The frame of ,
] from T The frame of ,





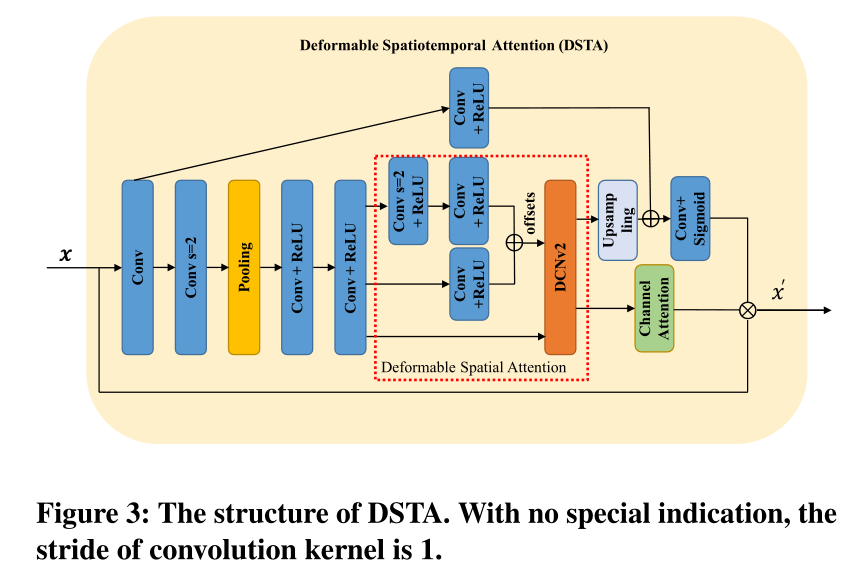
3.2 Recursive Fusion Module
Recursive fusion (RF) The module introduces the previous hidden state ℎt-1' To refine the fusion features ℎt, Such as 【7】 Designed by ,STDF Take advantage of an efficient U The network of nets 【22】 To predict the offset field ![]() For deformable convolution kernel , among K Is the core size of the deformable convolution . then , These position specific offsets Δ Guide deformable convolution network to fuse input frames effectively .
For deformable convolution kernel , among K Is the core size of the deformable convolution . then , These position specific offsets Δ Guide deformable convolution network to fuse input frames effectively .
stay [7] in , Fusion features ℎt Direct feed QE modular , And in this article , We suggest that RF Refine the module ℎt By further using the space-time information of the frame . say concretely ,RF The core idea of the module is to recursively use the previous hidden state ℎt-1' As a clue to adjust the current function ℎt . RF The operation of the module can be formalized as :
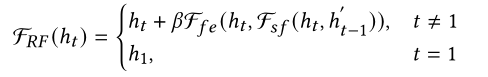
ℎt yes STDF The fusion characteristics of information technology ,Fsf Is to integrate the current ℎt Features and hidden features ℎt-1' Sub fusion module ,Ffe Is a feature extractor , Aims to learn residuals and to ℎt Provide other learning information . In our implementation process , Set through grid search to 0.2.
Set through grid search to 0.2.

3.3 Deformable Spatiotemporal Attention
QE Modules are crucial in this task , Because it needs to decode the hidden state into residuals , So as to reconstruct high-quality frames . However ,QE Modules have received little attention in recent work . In order to improve the QE Module performance , This paper designs a deformable space-time attention (DSTA) Mechanism . generally speaking ,QE Partially utilize hidden states ℎ ′ from STFF As input and generate a residual , This residual is used together with the compressed frame to recover the compressed frame .
QE Refer to figure for the structure of the module 2, It includes L+2 Convolutions and L individual DSTA block . meanwhile , chart 3 It is shown that DSTA Block structure . Generally speaking ,DSTA It is to make the model pay more attention to the artifact rich areas , For example, the boundary of the moving object in the frame , In order to QE Modules can achieve better performance in these areas
stay DSTA in , Let's start with 1×1 Convolution to reduce the number of channels , In order to obtain enough receiving fields and low computational cost , This is influenced by the literature [18] Inspired by the . then , In steps of 2 After the convolution layer of is a 7×7 Pool layer , To reduce the space size of features . After reducing the space size of features , We use multi-scale structure to predict the offset . then , The deformable convolution layer uses the predicted offset to calculate the attention graph . Then feed the mapping into the upsampling operator and channel attention module , Generate spatial attention mask and channel weight respectively . It is worth mentioning that , The channel attention mechanism plays a selective role in the hidden state , Among them, different dimensions represent different temporal relationships with the target frame . therefore , The channel attention mechanism can distinguish useful time information through the weighted sum on the channel . Last ,DSTA Block input and space map Multiply by the channel weight .
Please note that , Nonlocal attention mechanism ( See [42]) It may bring more performance improvements , But its huge amount of calculation increases the time cost of recovery , This is unacceptable , It's not in line with our motivation . our DSTA The module achieves a good balance between computation and performance , And consider both time and space dependencies for better performance . Pictured 4 Shown , The proposed attention block focuses more on the mobile area , So Guide QE Modules work harder to recover them .
3.4 Training Scheme
In order to further improve the performance of our method , We train the model in two stages . In the first phase , We remove RF modular , Focus on STDF and DSTA modular . When these two modules merge , We will reduce their learning rate , And will RF Add modules to your workout . In the second phase , We use video clips as input to train the RF module . This training strategy can shorten the training time . by comparison , The convergence speed of the single-stage training strategy is much slower than ours . In these two stages , We all use Charbonnier Loss to optimize the model .
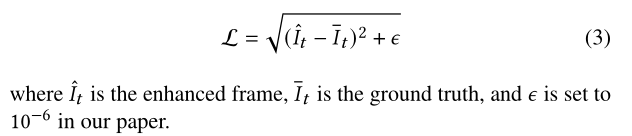
4 EXPERIMENTS
In this part , We have conducted a large number of experiments to evaluate the effectiveness and superiority of our proposed method . Our assessment consists of two parts :(1) Comparison with the latest method ,(2) Ablation study of the influence of different sub modules , All of this is in MFQE 2.0 On the dataset , There are five QP.
4.1 Datasets
stay [7,11,34] after , We are MFQE 2.0 Experiments on data sets . It is from Xiph Collected 126 A video sequence .org【31】、VQEG【25】 and JCT-VC【2】.MFQE 2.0 The resolution range of the video sequence contained in is very large :SIF(352×240)、CIF(352×288)、NTSC(720×486)、4CIF(704×576)、240p(416×240)、360p(640×360)、480p(832×480)、720p(1280×720)、1080p(1920×1080) and WQXGA(2560×1600). For a fair comparison , We are in accordance with the 【7、11、34】 Settings in : among 108 People are used to train , rest 18 People are used for testing . All sequences use HEVC Low-Delay-P(LDP) Configuration encoding , Use HM 16.20,QP=22、27、32、37 and 42【11】
4.2 Implementation Details
In this paper , We use literature [7] The most advanced method in STDF-R3 For the baseline , It means R = 3 For the STDF. In the training phase , We randomly crop from the original video and the corresponding compressed video 112×112 Clips as training samples , Set the batch size to 32. We also use flipping and rotation as data expansion strategies to further expand the data set . In the first training stage , Model from Adam(15) The optimizer trains , The initial learning rate is 10−4, When reach 60% and 90% Iteration time of , This value will be reduced by half . In the second training stage , We will STDF and QE The learning rate of is set to 10−5 Each video in the training set is divided into multiple video clips . Each video clip contains 15 frame . It is worth mentioning that , In the first training stage , We calculate the loss frame by frame , And in the second training stage , We calculate the loss of the whole clip , In order to make better use of the characteristics of the RF module . Our model is in 4 individual NVIDIA GeForce RTX 3090 GPU Upper use PyTorch1.8 Training .
To evaluate , according to [7,34] Set up , We only report YUV /YCbCr In the space Y The quality of the channel is enhanced . We use the peak signal-to-noise ratio of compression (ΔPSNR) And structural similarity (ΔSSIM) To evaluate quality enhancement performance . With ΔPSNR For example , We use enhancement PSNR Difference between ( According to the enhanced video And basic fact value ) And compressed PSNR( According to the compressed video calculation and basic facts 푉) The performance of the measurement method , namely ![]()
4.3 Comparison with State of the art Methods
To prove the advantages of our method , We compared our method with the most advanced method , Including image-based methods [9、16、41]、 Method based on single frame [26、38] And multi frame method [7、11、21]. In order to fully verify the effectiveness of the modules in our method , We will also RF and DSTA Apply to STDF-R3. The literature [7,11] The results of existing methods are cited .
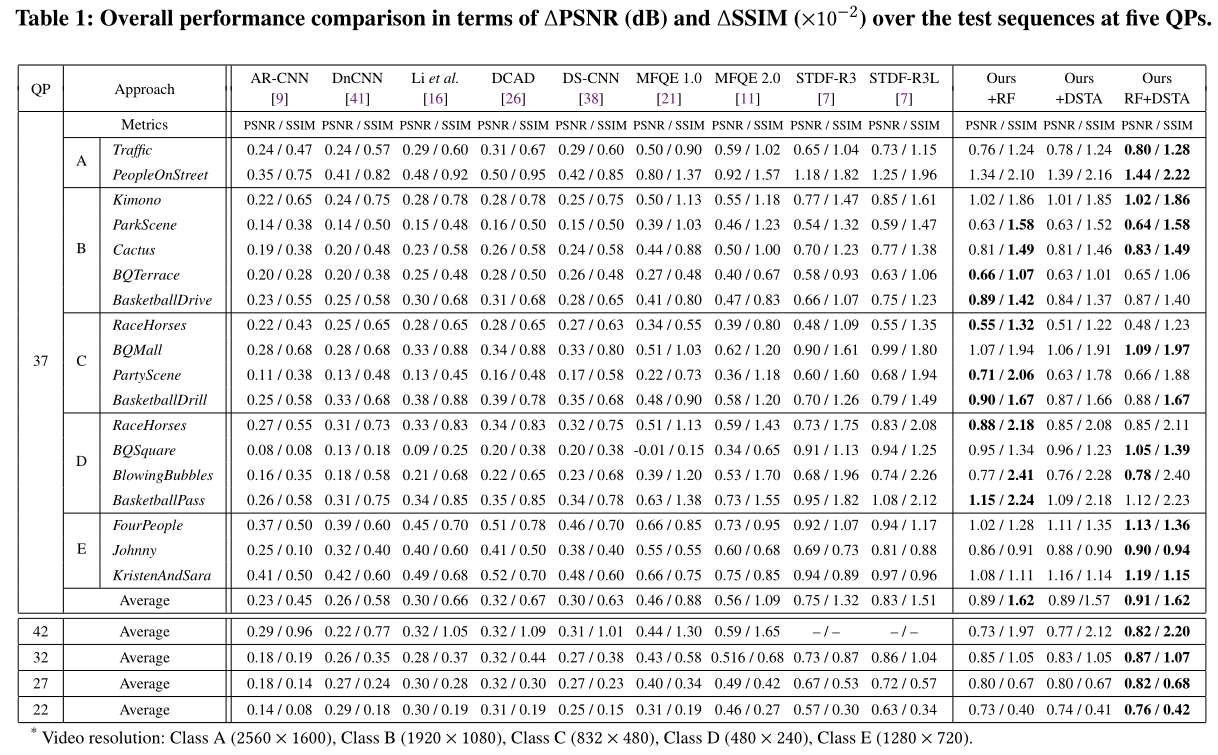
Overall performance:PSNR/SSIM The improved results are shown in the table . To verify the effectiveness of different components , We also separately reported the use of RF and DSTA Time performance . From the table 1 We can see , Due to the advantage of using space-time information , The performance of multi frame method is better than all image-based methods . And our method is in five QPs Better performance than all existing methods , This verifies the effectiveness and superiority of the proposed method . Besides , Only with RF or DSTA Of STDF-R3 In four QP The performance is also better than the most advanced methods .
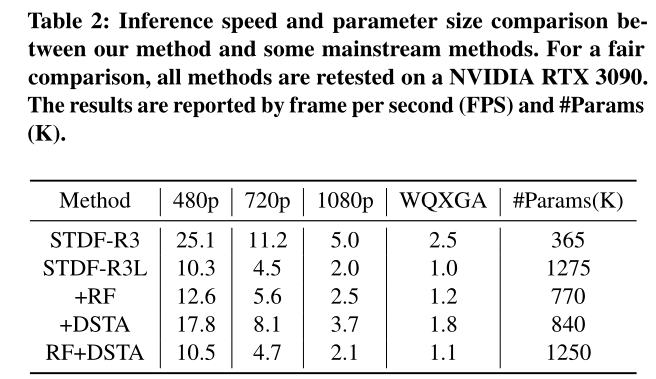
Speed and parameter size comparison: We also compare the reasoning speed and parameter size of our method with some existing methods . As shown in the table 2 Shown . Our method is superior to the most advanced method in reasoning speed and parameter size STDF-R3L. To be specific , Our method averages ΔPSNR Improved 8.8%( from 0.83 Up to 0.91, See table 1), And will infer FPS Improved 0.1∼0.2( Improve 2∼10%, See table .2) , And the parameter ratio of our model STDF-R3L Less (1250k Than 1275k, See table 2), This proves the effectiveness and superiority of our proposed method . Besides , Through the table 1 And table 2, We can see , Even if you only use RF or DSTA In the recovery effect 、 Speed and parameter size , It can still be in four QP Lower implementation ratio STDF-R3L Better performance .
Quality fluctuation: Quality fluctuation is another observable indicator to enhance the overall quality of video . The violent quality fluctuation of frames leads to serious texture jitter and the decline of experience quality . We go through 【11、33、38】 Standard deviation of each test sequence in (SD) And peak V Lane difference (PVD) To assess volatility . The average of all test sequences of our method and the main existing methods PVD and SD As shown in the table .3、 We can see , Our method has the minimum average PVD and SD, This shows that our method is more stable than other methods .
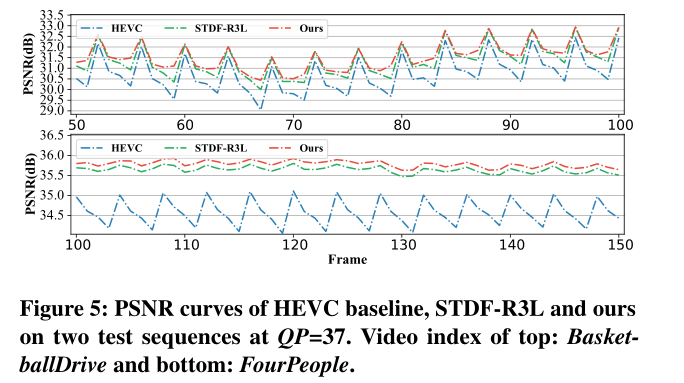
chart 5 Two groups are shown PSNR curve , Each group consists of HEVC Three compressed test sequences PSNR Curves and STDF-R3L And two corresponding sequences enhanced by our method . And STDF-R3L comparison , Our method has a larger PSNR improve , But the fluctuation is small .
Rate-distortion: Here it is , We evaluated the rate distortion of our method , And compare it with the most advanced methods . For illustration purposes , We only show the results of compressed video 、 Two state-of-the-art methods (MFQE 2.0 and STDF-R3L) The enhancement results and figure 6 The method in . because [7] Lack of data in , We didn't show QP=32 Of STDF-R3L Result , From the picture 6 We can see that , For similar bit rates , Our method gets more than other methods PSNR, This shows that our method is superior to the most advanced method in rate distortion .
4.4 Ablation Study
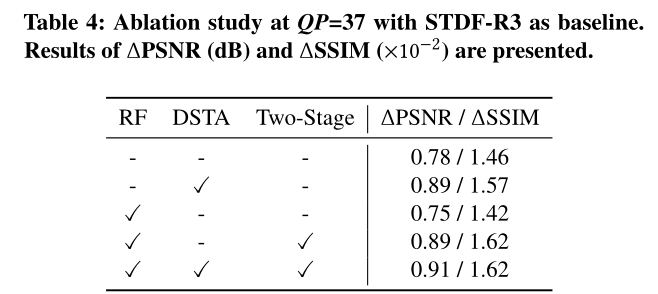
To verify the effect of our module , We use STDF-R3 For the baseline , And insert different module combinations into the baseline . For a fair comparison , We are right. STDF-R3 Retraining , A similar experimental setup was used . tab .4 The combination of different modules STDF-R3 and STDF-R3 Result . For the sake of simplicity , We abbreviate the two-stage training strategy as two stages .
Effect of Recursive Fusion: ad locum , We evaluate the effectiveness of our RF module . As shown in the table 4 The fourth original input in 、 RF module with two-stage training strategy ΔPSNR by 0.89, Higher than the baseline method 0.11. chart 7 The visual examples in also show ,RF The module benefits by learning to recover lost details from previous frames . In order to better illustrate the effectiveness of the RF module , We also trained one STDF-R4 Model , The model requires 2 Additional reference frames for enhancement .STDF-R4 Of ΔPSNR by 0.79, And our RF module ΔPSNR by 0.89, This proves once again the effectiveness of the RF module .
We noticed that , There is an inconsistency between our training and reasoning stages : We use a length of 15 Video clips of train our model , In the process of reasoning , We use RF Recursively generate the entire video . In order to better verify whether our model has the ability to use spatiotemporal correlation in a long time range , We designed three variants : nothing RF、 Yes RF And have RF-15,RF-15 It means in training and reasoning , We segment each video into multiple 15 Frame video clip , And enhance one by one . chart 8 The peak signal-to-noise ratio curves of various RF variants are shown .RF and RF-15 All better than w/o RF. However ,RF-15 Performance ratio at the start frame of each clip RF Bad , This further verifies the effectiveness of introducing distant previous frame information .
We will also RF Replace with ConvLSTM【30】, And under the same experimental setup ( Two stages ,QP=37) With the RF Compare . We got 0.78ΔPSNR, Far below RF Of 0.89, And that proves it RF The advantages of .
Effect of Deformable Spatiotemporal Attention: From the table 4, We can come to a conclusion ,DSTA Great contribution to performance improvement . In order to study in depth , Let's think about it DSTA Branch structure of the module for additional ablation studies . Intuitively speaking , The proposed DSTA There are three variants of the module : No DA Of DSTA( Delete the deformable attention part and generate the attention graph using the basic convolution layer )、 No CA Of DSTA( Delete the attention section of the channel ) and DSTA( Use two branches ). The experimental results are shown in the table .5、 We can see , Both single branch note settings can improve STDF-R3 Performance of , But more than DSTA Poor performance .
Effect of Two-Stage Training: ad locum , We examine the need for a two-stage training strategy . For a fair comparison , We use the same optimizer and learning rate decay settings to train with / Model without two-stage strategy . surface 4 The use of / The result of not using a two-stage training model . We can see , Two stages get 0.14 /0.2×10−2ΔPSNR /ΔSSIM improvement ( The fourth and third lines ), It shows the effectiveness of the two-stage strategy .
4.5 Qualitative Comparison
We also made a qualitative comparison , And provide several visual examples , In the figure 9 Medium QP=37. ad locum , We compare our method with the existing four main methods :AR-CNN、DnCNN、MFQE 2.0 And baseline STDF-R3. Pictured 9 Shown , Compressed fragment ( The first 2 In the column ) There are serious compression artifacts ( for example , Lack of human details ), The single frame method cannot deal with temporal noise , and MFQE 2.0 and STDF-R3 There is excessive smoothing . However , Our method restores more detail or texture than other methods , Especially the details of the boundary area of the fast moving object .
5 CONCLUSION
This paper presents a new method to improve the performance of video compression artifact suppression . Our method consists of two new modules : Recursive fusion (RF) Modules and deformable spacetime note (DSTA) modular . The former aims to capture spatiotemporal information from frames in a large time range , The latter aims to highlight the artifact rich areas in each frame , For example, the boundary area of a moving object . A lot of our experiments show that , Our proposed method can achieve better performance than existing methods . The proposed module can also easily adapt to the existing multi frame methods and low-level tasks related to video .
边栏推荐
猜你喜欢

期末周,我裂开
关于IDEA如何设置快捷键集

Knowledge payment applet dream vending machine V2
![[network data transmission] FPGA based development of 100M / Gigabit UDP packet sending and receiving system, PC to FPGA](/img/71/1d6179921ae84b1ba61ed094e592ff.png)
[network data transmission] FPGA based development of 100M / Gigabit UDP packet sending and receiving system, PC to FPGA

Responsive - media query

centos8安装mysql.7 无法开机启动
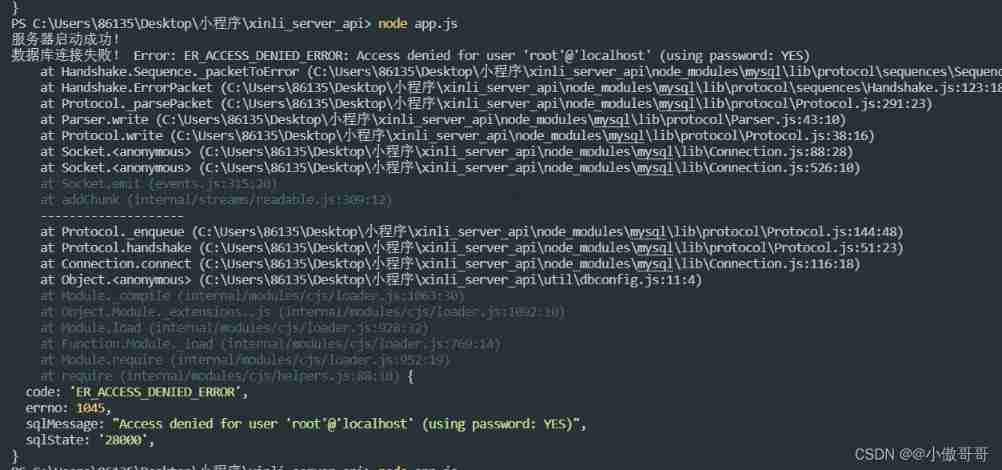
Node connection MySQL access denied for user 'root' @ 'localhost' (using password: yes

Cervical vertebra, beriberi
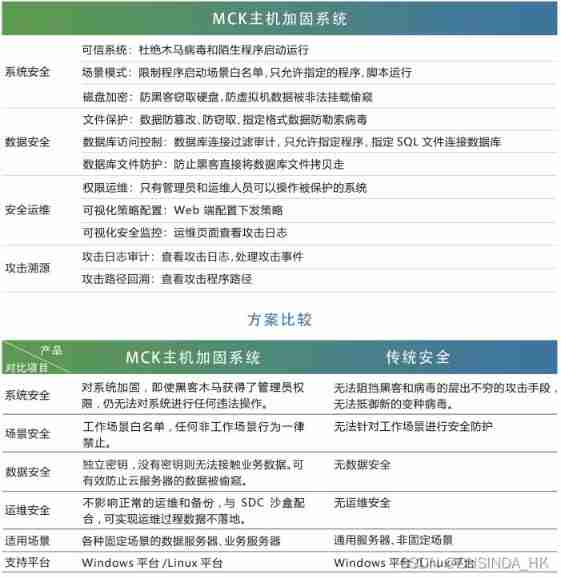
Industrial computer anti-virus
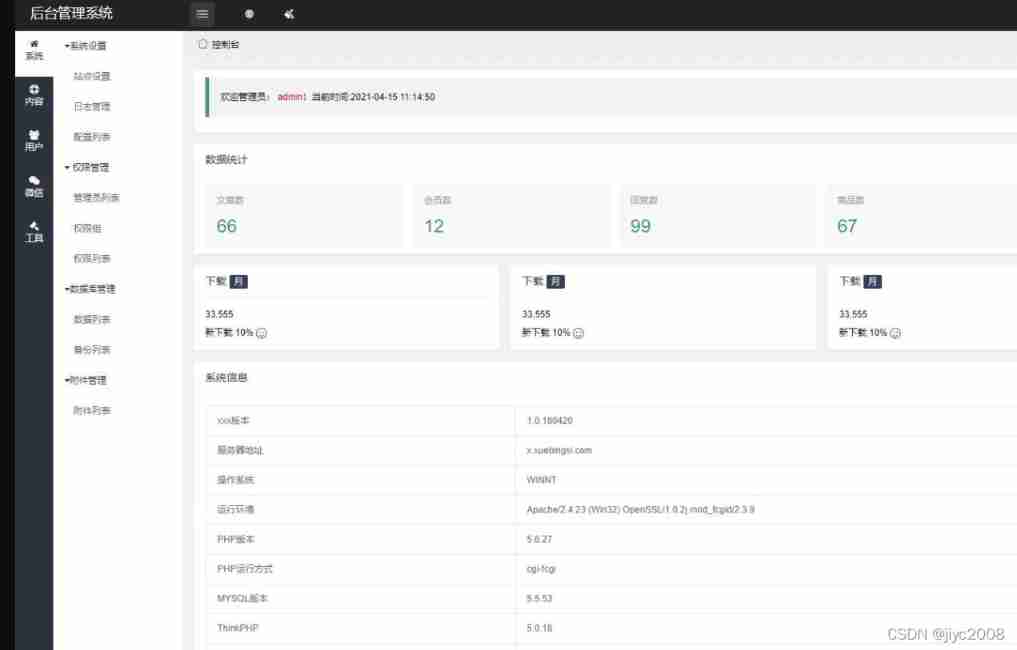
CMS source code of multi wechat management system developed based on thinkphp6, with one click curd and other functions
随机推荐
Tar source code analysis Part 7
Four sets of APIs for queues
How notepad++ counts words
Data double write consistency between redis and MySQL
Explain in one sentence what social proof is
Status of the thread
【FPGA教程案例7】基于verilog的计数器设计与实现
Research on an endogenous data security interaction protocol oriented to dual platform and dual chain architecture
uniapp小程序分包
Cochez une colonne d'affichage dans une colonne de tableau connue
JS common time processing functions
同一个job有两个source就报其中一个数据库找不到,有大佬回答下吗
Introduction to deep learning Ann neural network parameter optimization problem (SGD, momentum, adagrad, rmsprop, Adam)
Paddleocr prompt error: can not import AVX core while this file exists: xxx\paddle\fluid\core_ avx
Selenium ide plug-in download, installation and use tutorial
The final week, I split
How does the inner roll break?
2022 wechat enterprise mailbox login entry introduction, how to open and register enterprise wechat enterprise mailbox?
MySQL relearn 2- Alibaba cloud server CentOS installation mysql8.0
Splicing plain text into JSON strings - easy language method