当前位置:网站首页>Flink < --> Introduction to JDBC +with parameter
Flink < --> Introduction to JDBC +with parameter
2022-07-03 10:48:00 【Samooyou】
Introduce
JDBC Connector Provide for the right to MySQL、PostgreSQL、Oracle And other common database read-write support .
at present Oceanus Provided flink-connector-jdbc Connector Components have been built in MySQL and PostgreSQL Driver program . If necessary, connect Oracle Wait for other databases , By attaching Custom package The way , Upload the corresponding JDBC Driver Of JAR package .
Using range
JDBC Support as data source table (Source), Used to scan tables by fixed columns and for JOIN The right table of ( Dimension table ). It is also supported as a data destination table (sink), be used for Tuple Data flow tables and are used for Upsert Data flow table ( You need to specify a primary key ).
If necessary JDBC The change records of the database are consumed as streaming source tables , Use the built-in CDC data source . If built-in CDC The data source cannot meet the demand , You can also use Debezium、Canal etc. , Yes JDBC Capture and subscribe to changes in the database , then Oceanus These change events can be further handled . Details can be found at Message queue Kafka.
Example
Used as a data source for column scanning (Source)
|
Used as dimension table data source (Source)
|
For data purposes (Tuple Sink)
|
For data purposes (Upsert Sink)
|
Universal WITH Parameters
Parameter values | Required | The default value is | describe |
|---|---|---|---|
| connector | yes | nothing | When connecting to the database , Need to fill in 'jdbc'. |
| url | yes | nothing | JDBC Database connection URL. |
| table-name | yes | nothing | Database table name . |
| driver | no | nothing | JDBC Driver The name of the class . If you don't type , Automatically from url Infer from . |
| username | no | nothing | Database user name .'username' and 'password' Must be used at the same time . |
| password | no | nothing | Database password . |
| scan.partition.column | no | nothing | Specify to scan the input partition (Partitioned Scan) Column name of , The column must be of numeric type 、 The date type 、 Timestamp type, etc . Details about partition scanning , See also Partition scan . |
| scan.partition.num | no | nothing | After partition scanning is enabled , Specify the number of partitions . |
| scan.partition.lower-bound | no | nothing | After partition scanning is enabled , Specify the minimum value of the first partition . |
| scan.partition.upper-bound | no | nothing | After partition scanning is enabled , Specify the maximum value of the last partition . |
| scan.fetch-size | no | 0 | Every time you read from the database , The number of rows obtained in batch . The default is 0, It means reading line by line , Low efficiency ( Throughput is not high ). |
| lookup.cache.max-rows | no | nothing | The query cache (Lookup Cache) The maximum number of cached data in . |
| lookup.cache.ttl | no | nothing | Query the maximum cache time of each record in the cache . |
| lookup.max-retries | no | 3 | When the database query fails , Maximum number of retries . |
| sink.buffer-flush.max-rows | no | 100 | Batch output , How much data is cached in the cache at most . If set to 0, Indicates that output caching is prohibited . |
| sink.buffer-flush.interval | no | 1s | Batch output , Maximum interval per batch ( millisecond ). If 'sink.buffer-flush.max-rows' Set to '0', And this option is not zero , It means that the pure asynchronous output function is enabled , That is, the data is output to the operator 、 The threads from the operator to the database are completely decoupled . |
| sink.max-retries | no | 3 | When the database write fails , Maximum number of retries . |
Primary key description
- about Append(Tuple) data , Homework DDL There is no need to set the primary key ,JDBC There is no need to define a primary key for a database table , It is not recommended to define a primary key ( Otherwise, the write may fail due to repeated data ).
- about Upsert data ,JDBC Table of database must Define the primary key , And need to DDL Of the statement CREATE TABLE in , Add the corresponding column name
PRIMARY KEY NOT ENFORCEDconstraint .
Be careful :
- about MySQL surface ,Upsert The realization of function depends on
INSERT .. ON DUPLICATE KEY UPDATE ..grammar , Common versions of MySQL Both support this syntax .- about PostgreSQL surface ,Upsert Function realization depends on
INSERT .. ON CONFLICT .. DO UPDATE SET ..grammar , This syntax requires PostgreSQL 9.5 And above versions are supported .- about Oracle surface ,Upsert Function implementation depends on
MERGE .. INTO .. USING ON .. WHEN UPDATE .. WHEN INSERT ..grammar , This syntax requires Oracle 9i And above versions can support .
Partition scan
Partition scan (Partitioned Scan) Can speed up multiple parallelism Source Operator read JDBC Data sheet , Each subtask can read its own private partition . When using this function , All four scan.partition All parameters at the beginning must be specified , Otherwise, an error will be reported .
Be careful :
there
scan.partition.upper-boundThe specified maximum value andscan.partition.lower-boundSpecified minimum , It refers to the step size of each partition , It will not affect the number and accuracy of data finally read .
Read cache
Flink Provides read cache (Lookup Cache) function , It can improve the performance of dimension table reading . At present, the implementation of this cache is synchronous , Default not enabled ( Every request will read the database , Throughput is very low ), Must be set manually lookup.cache.max-rows and lookup.cache.ttl Two parameters to enable this function .
Be careful :
If it's cached TTL Too long , Or there are too many cached entries , It may cause the data in the database to be updated ,Flink The job still reads the old data in the cache . Therefore, operations sensitive to database changes , Please use caching function with caution .
Batch write optimization
By setting sink.buffer-flush The first two parameters , You can write to the database in batches . It is recommended to match the parameters of the corresponding underlying database , To achieve better batch writing effect , Otherwise, the bottom layer will still write one by one , The efficiency is not high .
- about MySQL, It is suggested that url After connecting parameters, add rewriteBatchedStatements=true Parameters .
|
- about PostgreSQL, It is suggested that url After connecting parameters, add reWriteBatchedInserts=true Parameters .
|
Reference resources :JDBC | Apache Flink
边栏推荐
- MySQL -- index principle + how to use
- Flink <-->JDBC的使用介绍+with参数
- 如何监测服务器主机的进出流量?
- 6、 Data definition language of MySQL (1)
- QT:QSS自定义 QSlider实例
- Flink--Chain的条件源码分析
- extern关键字
- FileNotFoundError: Could not find module ‘... dll‘ (or one of its dependencies).
- Numpy quick start (II) -- Introduction to array (creation of array + basic operation of array)
- [untitled]
猜你喜欢
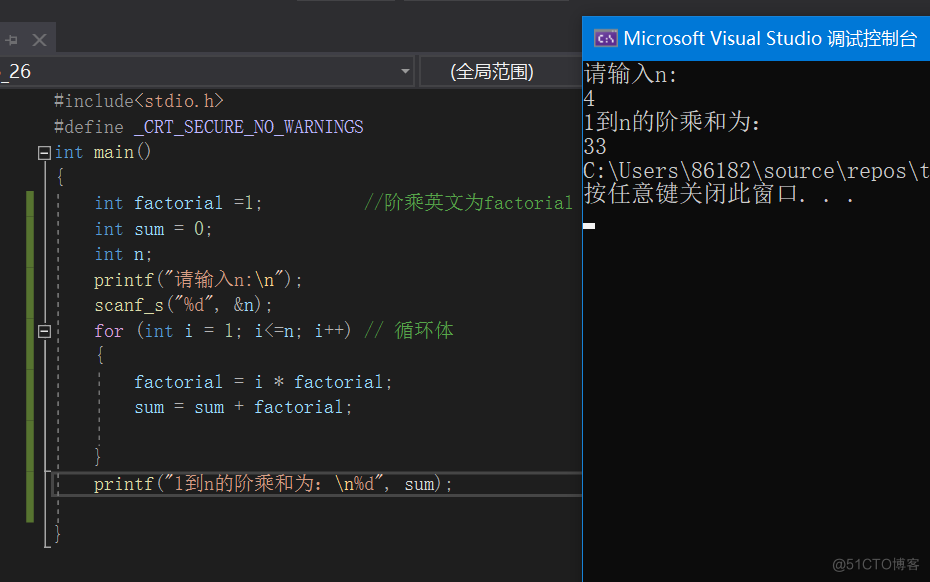
DAY 7 小练习

大型电商项目-环境搭建

Drop out (pytoch)

EFFICIENT PROBABILISTIC LOGIC REASONING WITH GRAPH NEURAL NETWORKS

Unity group engineering practice project "the strongest takeaway" planning case & error correction document

8、 Transaction control language of MySQL
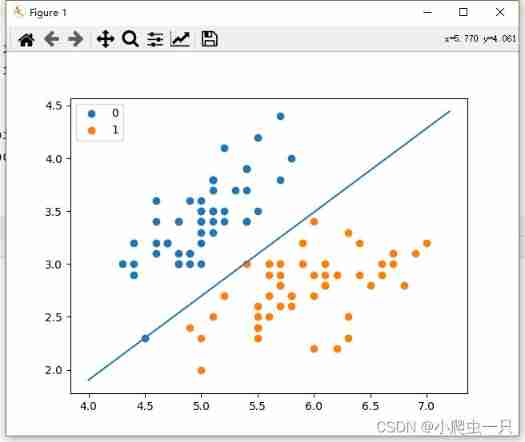
Numpy realizes the classification of iris by perceptron

如何在游戏中制作一个血条
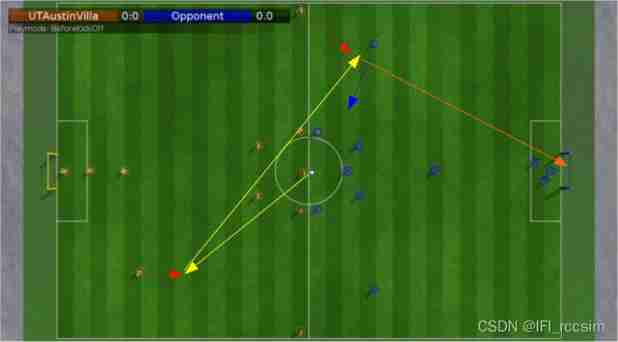
Ut2015 learning notes

Jetson TX2 刷机
随机推荐
How does MySQL find the latest data row that meets the conditions?
QT:QSS自定义 QMenuBar实例
MySql 怎么查出符合条件的最新的数据行?
【吐槽&脑洞】关于逛B站时偶然体验的弹幕互动游戏魏蜀吴三国争霸游戏的一些思考
Leetcode刷题---704
Wechat applet training notes 1
安装yolov3(Anaconda)
Numpy quick start (I) -- pre knowledge (create array + constant + data type)
Introduction to deep learning linear algebra (pytorch)
Chiyou (), a specific mythical image, is also gradually abstracted as a dramatic character type "Jing". "Jing", born in Dan Dynasty and ugly at the end, is the earliest "profession" in Chinese drama
Leetcode skimming ---1
Unity learning notes: online game pixel Adventure 1 learning process & error correction experience
Ut2013 learning notes
Numpy quick start (IV) -- random sampling and general functions
QT:QSS自定义 QScrollBar实例
帶你走進雲原生數據庫界扛把子Amazon Aurora
Ut2012 learning notes
项目组织战略管理
如何监测服务器主机的进出流量?
Ind kwf first week