当前位置:网站首页>Numpy realizes the classification of iris by perceptron
Numpy realizes the classification of iris by perceptron
2022-07-03 10:38:00 【Machine learning Xiaobai】
import random
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
def sign(x):
if x >= 0:
return 1
else:
return -1
def get_loss(dataset,target,w):
results = [np.matmul(w.T,data) for data in dataset]
''' Predictive value '''
predict = [sign(i) for i in results]
''' Misclassification point '''
error_index = [i for i in range(len(target)) if target[i] != predict[i]]
print(' And then there were {} Error points '.format(len(error_index)))
''' Calculation loss'''
loss = 0
for i in error_index:
loss += results[i] * (predict[i] - target[i])
return loss
def get_w(dataset,target,w,learning_rate):
results = [np.matmul(w.T,data) for data in dataset]
''' Predictive value '''
predict = [sign(i) for i in results]
''' Misclassification point '''
error_index = [i for i in range(len(target)) if target[i] != predict[i]]
''' Select random misclassification points '''
index = random.choice(error_index)
''' Stochastic gradient descent '''
w = w - learning_rate * (predict[index] - target[index]) * dataset[index]
return w
if __name__ == '__main__':
''' Calyx length 、 Calyx width 、 Petal length 、 Petal width '''
'''0,1 Divisible , Select two categories '''
dataset, target = datasets.load_iris()['data'], datasets.load_iris()['target']
target = target[:100]
target = np.array([1 if i == 1 else -1 for i in target])
dataset = dataset[:100]
dataset = np.array([np.array(data[:2]) for data in dataset])
dataset = np.hstack((np.ones((dataset.shape[0], 1)), dataset))
w = np.random.rand(len(dataset[0]))
loss = get_loss(dataset,target,w)
print(loss)
epoch = 10000
learning_rate = 0.1
for i in range(epoch):
''' to update w'''
w = get_w(dataset,target,w,learning_rate)
''' Calculation loss'''
loss = get_loss(dataset,target,w)
print(' after {} iteration ,loss:{}'.format(i,loss))
if loss == 0:
break
print(w)
x_point = np.array([i[1] for i in dataset])
y_point = np.array([i[2] for i in dataset])
x = np.linspace(4,7.2,10)
y = (-w[1] * x - w[0])/w[2]
plt.scatter(x_point[:50],y_point[:50],label = '0')
plt.scatter(x_point[-50:],y_point[-50:],label = '1')
plt.legend() # Show Legend
plt.plot(x,y)
plt.show()Here is a random gradient descent
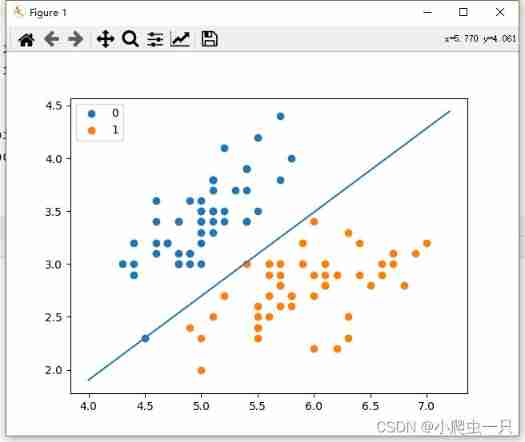 jie The result of perceptron classification is not unique
jie The result of perceptron classification is not unique
边栏推荐
- What useful materials have I learned from when installing QT
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation
- [LZY learning notes dive into deep learning] 3.1-3.3 principle and implementation of linear regression
- 2-program logic
- Leetcode刷题---75
- 【吐槽&脑洞】关于逛B站时偶然体验的弹幕互动游戏魏蜀吴三国争霸游戏的一些思考
- Advantageous distinctive domain adaptation reading notes (detailed)
- Leetcode skimming ---852
- 神经网络入门之矩阵计算(Pytorch)
- A super cool background permission management system
猜你喜欢

Handwritten digit recognition: CNN alexnet

Leetcode - the k-th element in 703 data flow (design priority queue)

丢弃法Dropout(Pytorch)
一个30岁的测试员无比挣扎的故事,连躺平都是奢望

【吐槽&脑洞】关于逛B站时偶然体验的弹幕互动游戏魏蜀吴三国争霸游戏的一些思考

The imitation of jd.com e-commerce project is coming

Hands on deep learning pytorch version exercise solution - 2.4 calculus

7、 Data definition language of MySQL (2)

Policy Gradient Methods of Deep Reinforcement Learning (Part Two)
Ut2015 learning notes
随机推荐
Jetson TX2 刷机
Synchronous vs asynchronous
Matrix calculation of Neural Network Introduction (pytoch)
The imitation of jd.com e-commerce project is coming
Preliminary knowledge of Neural Network Introduction (pytorch)
Out of the box high color background system
【SQL】一篇带你掌握SQL数据库的查询与修改相关操作
Type de contenu « Application / X - www - form - urlencoded; Charset = utf - 8 'not supported
Pytorch ADDA code learning notes
Leetcode skimming ---704
丢弃法Dropout(Pytorch)
2018 y7000 upgrade hard disk + migrate and upgrade black apple
Tensorflow—Image segmentation
Leetcode刷题---75
Hands on deep learning pytorch version exercise solution - 2.6 probability
Seata分布式事务失效,不生效(事务不回滚)的常见场景
MySQL reports an error "expression 1 of select list is not in group by claim and contains nonaggre" solution
【毕业季】图匮于丰,防俭于逸;治不忘乱,安不忘危。
Numpy Foundation
Ut2011 learning notes