当前位置:网站首页>Knowledge map enhancement recommendation based on joint non sampling learning
Knowledge map enhancement recommendation based on joint non sampling learning
2022-07-03 10:32:00 【kormoie】
Thesis title :Jointly Non-Sampling Learning for Knowledge Graph Enhanced Recommendation
- Abstract
Knowledge graph (KG) contains well-structured external information and has shown to be effective for high-quality recommendation. However, existing KG enhanced recommendation methods have largely focused on exploring advanced neural network architectures to better investigate the structural information of KG. While for model learning, these methods mainly rely on Negative Sampling (NS) to optimize the models for both KG embedding task and recommendation task. Since NS is not robust (e.g., sampling a small fraction of negative instances may lose lots of useful information), it is reasonable to argue that these methods are insufficient to capture collaborative information among users, items, and entities.
Knowledge map (KG) Contains well structured external information , It has been proved to be an effective method of high-quality recommendation . However , The existing KG Enhance the recommendation method Mainly focused on exploration Advanced neural network architecture , To better study KG Structure information of . For model learning , These methods mainly rely on negative sampling (NS) Yes KG Optimize the model of embedded tasks and recommended tasks . because NS Not robust ( for example , Sampling a small number of negative instances may lose a lot of useful information ), There is reason to think that these methods are not enough to capture users 、 Collaboration information between projects and entities .
In this paper, we propose a novel Jointly Non-Sampling learning model for Knowledge graph enhanced Recommendation (JNSKR). Specifically, we first design a new efficient NS optimization algorithm for knowledge graph embedding learning. The subgraphs are then encoded by the proposed attentive neural network to better characterize user preference over items. Through novel designs of memorization strategies and joint learning framework, JNSKR not only models the fine-grained connections among users, items, and entities, but also efficiently learns model parameters from the whole training data (including all non-observed data) with a rather low time complexity. Experimental results on two public benchmarks show that JNSKR significantly outperforms the state-of-the-art methods like RippleNet and KGAT. Remarkably, JNSKR also shows significant advantages in training efficiency (about 20 times faster than KGAT), which makes it more applicable to real-world largescale systems.
This paper proposes a knowledge graph enhanced recommendation model based on joint non sampling learning (JNSKR). say concretely , We first designed a The new efficient knowledge map is embedded in learning NS optimization algorithm . The subgraph is then generated by the proposed Pay attention to neural network coding , To better represent users' preferences for the project .JNSKR adopt Novel memory strategies and joint learning framework design , Not only for users 、 project 、 Between entities fine-grained Connect to model , It can also get the whole training data with low time complexity ( Include all unobserved data ) Learn model parameters efficiently . The experimental results of two public benchmarks show ,JNSKR Significantly better than state-of-the-art methods , Such as RippleNet and KGAT. It is worth noting that ,JNSKR It also shows significant advantages in training efficiency ( About than KGAT fast 20 times ), This makes it more suitable for large-scale systems in the real world .
- Non-sampling Learning for Top-K Recommendation
For implicit data, the observed interactions are rather limited, and non-observed examples are of a much larger scale. To learn from such a sparse data, there are generally two optimization strategies: 1) negative sampling strategy [5, 14, 25] and 2) non-sampling (whole-data based) strategy [7, 15, 16]. The first strategy samples a fraction of negative instances from non-observed entries, while the second one sees all the non-observed data as negative. In previous work (especially neural recommendation studies), negative sampling is widely adopted for efficient training. However, some recent studies have shown that sampling would inevitably limit the recommendation performance as it can ignore some important examples, or lead to insufficient training of them [7, 15, 43, 46]. In contrast, non-sampling strategy leverages the whole data with a potentially better coverage, but inefficiency can be an issue [7]. Some efforts have been devoted to resolving the inefficiency issue of non-sampling learning. For instance, Pilaszy et al. [24] describe an approximate solution of Alternating Least Squares (ALS). He et al. [15] propose an efficient ALS with non-uniform missing data. Some researchers [43, 46] study fast Batch Gradient Descent (BGD) methods. Recently, Chen et al. [7, 8] derive a flexible non-sampling loss for neural recommendation models, which achieves both effective and efficient performance
For implicit data , The observed interactions are quite limited , The scale of the unobserved examples is much larger . For such sparse data , There are generally two optimization strategies :1) Negative sampling strategy [5,14,25] and 2) Nonsampling ( Based on full data ) Strategy [7,15,16]. The first strategy extracts some negative instances from items that have never been observed , The second strategy Treat all unobserved data as negative data . In the past work ( Especially neural recommendation research ), Negative sampling is widely used for effective training . However , Some recent studies show that , Sampling inevitably limits recommended performance , because Sampling ignores some important examples , Or lead to insufficient training for these examples [7,15,43,46]. contrary , The non sampling strategy utilizes the entire data , Better potential coverage , But inefficiency can be a problem . In solving the problem of low efficiency of non sampling learning , Some efforts have been made . for example ,Pilaszy Etc. [24] Alternating least squares (ALS) The approximate solution of . He and others proposed an effective method with non-uniform missing data ALS. Some researchers [43,46] Fast batch gradient descent is studied (BGD) Method . lately ,Chen wait forsomeone [7,8] A flexible non sampling loss is derived for the neural recommendation model , It achieves effective and efficient performance .
Despite the existing Non sampling The research has been successful , But they are mainly concentrated stay CF On the way , Only the relationship between users and items is considered . Apply these methods directly to Learning consists of entities - Relationship - Entity triplet KG Enhancing recommendation is of great significance . As far as we know , This is the first study KG Enhance the recommended effective non sampling methods .
- Efficient non sampling collaborative filtering
lately , Some research finds , Non sampling strategy is very helpful to achieve optimal recommendation performance [7,15,16,46]. We briefly introduce an efficient non sampling collaborative filtering method , It is designed to learn users' preferences for projects . For implicit data , A common non sampling loss is to minimize user feedback yuv And the predicted results yuv Differences between [16]: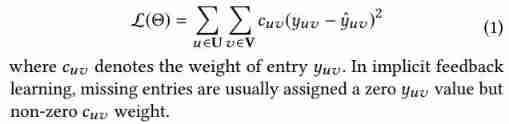
- Efficient Non-sampling Knowledge Graph Embedding
Knowledge graph embedding is on the premise of maintaining graph structure , An effective way to transform entities and relationships into vector representations . It has been widely used in knowledge enhancement Recommendation Algorithm [1,34,38]. Existing knowledge graph embedding methods [2,21,44] The negative sampling method is mainly used to optimize the model , But recent studies have shown that it is not robust [7,43]. This paper proposes to apply non sampling strategy to knowledge graph embedding learning . among , For a group of entities B, The square loss of graph embedding learning is defined as 
in addition , Loss of non observed data It can be used The residual between the loss of all data and the loss of positive data To express . We have the following derivation :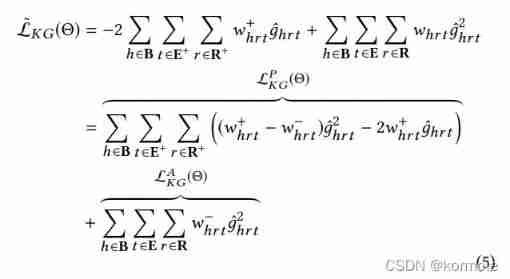
边栏推荐
- [graduation season] the picture is rich, and frugality is easy; Never forget chaos and danger in peace.
- Leetcode刷题---367
- Handwritten digit recognition: CNN alexnet
- Leetcode刷题---278
- 20220531 Mathematics: Happy numbers
- Leetcode-513: find the lower left corner value of the tree
- Ut2014 learning notes
- Ut2012 learning notes
- 安装yolov3(Anaconda)
- Leetcode-404: sum of left leaves
猜你喜欢

A complete answer sheet recognition system
Implementation of "quick start electronic" window dragging

Raspberry pie 4B deploys lnmp+tor and builds a website on dark web

High imitation bosom friend manke comic app

Realize an online examination system from zero

Hands on deep learning pytorch version exercise solution - 2.4 calculus

Leetcode - 706 design hash mapping (Design)*
Out of the box high color background system
![[LZY learning notes -dive into deep learning] math preparation 2.1-2.4](/img/92/955df4a810adff69a1c07208cb624e.jpg)
[LZY learning notes -dive into deep learning] math preparation 2.1-2.4
ECMAScript--》 ES6语法规范 ## Day1
随机推荐
Data classification: support vector machine
Mise en œuvre d'OpenCV + dlib pour changer le visage de Mona Lisa
20220602 Mathematics: Excel table column serial number
Step 1: teach you to trace the IP address of [phishing email]
Ut2017 learning notes
20220606数学:分数到小数
Jetson TX2 刷机
Data preprocessing - Data Mining 1
Leetcode - 706 design hash mapping (Design)*
20220607其他:两整数之和
R language classification
Hands on deep learning pytorch version exercise solution - 2.5 automatic differentiation
Leetcode刷题---202
SQL Server Management Studio cannot be opened
20220608其他:逆波兰表达式求值
[LZY learning notes -dive into deep learning] math preparation 2.5-2.7
Hands on deep learning pytorch version exercise solution - 3.1 linear regression
Softmax 回归(PyTorch)
Ut2016 learning notes
波士顿房价预测(TensorFlow2.9实践)