当前位置:网站首页>Policy Gradient Methods of Deep Reinforcement Learning (Part Two)
Policy Gradient Methods of Deep Reinforcement Learning (Part Two)
2022-07-03 10:13:00 【Most appropriate commitment】
Abstract
This paper will discuss the distribution space Natrual Gradient, And then Natural Gradient be used for Actor Critic. In addition Trust Region Policy Optimization(TRPO) and Proximal Policy Optimization(PPO) Algorithm .
Part One: Basic Knowledge in Natural Gradient
Disadvantages of parameter space update :
When we simulate a function with finite parameters , Even if we make a small change to a parameter , Every time we change, sometimes it's huge .
Such as below , The distribution in the figure is normal , The figures on the left are  , On the right are
, On the right are  . In the parameter space, the Euler distances of the two curves of the left and right graphs are 1(
. In the parameter space, the Euler distances of the two curves of the left and right graphs are 1( ). However, we can clearly see that the similarity between the two curves in the left figure is poor , The similarity in the right figure is high . therefore , Directly change the parameters in the parameter space , Even if the parameter change is very small , Sometimes it will cause great changes in strategy . And the huge change of strategy will cause the instability of learning . Besides, we are Actor-critic methods The strategy changes less each time ,value function It can be updated every time , Match the current strategy . When the strategy changes greatly ,value function It will be difficult to respond to current policies , Make the update direction appear huge deviation , Will not get the optimal solution .
). However, we can clearly see that the similarity between the two curves in the left figure is poor , The similarity in the right figure is high . therefore , Directly change the parameters in the parameter space , Even if the parameter change is very small , Sometimes it will cause great changes in strategy . And the huge change of strategy will cause the instability of learning . Besides, we are Actor-critic methods The strategy changes less each time ,value function It can be updated every time , Match the current strategy . When the strategy changes greatly ,value function It will be difficult to respond to current policies , Make the update direction appear huge deviation , Will not get the optimal solution .

In order to solve the problems in the above parameter space , We need to introduce distribution space , That is, the space where the actual distribution is located . The space where the actual distribution is located is the numerical distribution of the physical quantity concerned . At the same time, it is necessary to introduce physical quantities to measure the similarity of the two distributions .
KL(Kullback-Leiber) divergence
For two distributions p and q Describe the degree of similarity , We introduced KL Divergence The measurement of .
![D_{KL}(p||q)=\int p(x) \ log \frac{p(x)}{q(x)} dx=E_{x \sim p}[log \frac{p(x)}{q(x)}]](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_0.gif)
We will integrate in the distribution space ( The actual process will be sampling, Then sum it ), Then superimpose the results of each point . We can see if p and q Exactly the same ,KL Divergence It will be 0. Besides, we can see KL Divergence It's asymmetric ,  , But when p and q Very close , The two are approximately equal .
, But when p and q Very close , The two are approximately equal .
Of course , We can also introduce Jensen-Shannon(JS) Divergence, Eliminate this asymmetry :

Of course , When p and q Very close ,
The connection between parameter space and distribution space : Fisher Matrix
We actually manipulate Change strategy in parameter space , But we need to ensure that the strategies of adjacent steps have high similarity in the distribution space , It has been less than our set value  . So we need to establish and KL Divergence The relationship between .
. So we need to establish and KL Divergence The relationship between .

For the first one ![\bigtriangledown_{\theta'} D_{KL}[p(x;\theta)||p(x;\theta +\Delta \theta)] =\bigtriangledown_{\theta'} E_{p(x;\theta)}[log \ p(x;\theta)]- \bigtriangledown_{\theta'}E_{p(x;\theta)}[log \ p(x;\theta+\Delta \theta)]](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_21.gif)
And one of
![\bigtriangledown_{\theta'}E_{p(x;\theta)}[log\ p(x;\theta)]= E_{p(x;\theta)}[\bigtriangledown_{\theta'}log \ p(x;\theta)]=\int p(x;\theta) \bigtriangledown_{\theta'}log\ p(x;\theta)=\int p(x;\theta) \frac{\bigtriangledown_{\theta'}p(x;\theta)}{p(x;\theta)} = \int \bigtriangledown_{\theta'}p(x;\theta)=\bigtriangledown_{\theta'}\int p(x;\theta)=\bigtriangledown_{\theta'} 1=0](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_12.gif)
![\bigtriangledown_{\theta'}E_{p(x;\theta)}[log \ p(x;\theta+\Delta \theta)]=E_{p(x;\theta)}[\bigtriangledown_{\theta'}log\ p(x;\theta')]|_{\theta'=\theta}=0](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_32.gif)
![\bigtriangledown_{\theta'} D_{KL}[p(x;\theta)||p(x;\theta +\Delta \theta)] =0](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_30.gif)
therefore ,

Therefore, the similarity sum of two adjacent strategies in the distribution space The relationship between them is established . But we still need to know KL divergence What does the second derivative of mean .
![\bigtriangledown^2_{\theta'}D_{KL}[p(x;\theta)||p(x;\theta')] = -\int p(x;\theta) \bigtriangledown^2_{\theta'} log\ p(x|\theta')|_{\theta'=\theta} dx=-\int p(x;\theta) H_{log \ p(x|\theta)}dx= -E_{p(x;\theta)}[H_{log \ p(x;\theta)}]](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_43.gif)
We can get  The second step of is
The second step of is  The negative expectation of Hessian matrix .
The negative expectation of Hessian matrix .
The negative expectation of Hessian matrix is Fisher Matrix.
![F=E_{p(x;\theta)}[\bigtriangledown log\ p(x;\theta) \bigtriangledown log \ p(x;\theta)^T]=\frac{1}{N}\sum_{i=1}^{N}\bigtriangledown\ log\ p(x_i|\theta) \bigtriangledown\ log \ p(x_i|\theta)^T](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_34.gif)
Fisher Information Matrix - Agustinus Kristiadi's Blog
Natural Gradient Descent - Agustinus Kristiadi's Blog
Natural Gradient
Aim


Constraint:

According to convex optimization, we can get the result :

and  The specific function content is the same as natural gradient irrelevant , because natrual gradient It just solves the problem of making adjacent strategies have strong similarity ( Changed the update direction of the parameter vector ), Ensure the stability of the learning process . meanwhile natural gradient Curvature dependent inverse , When the loss equation is in a flat position , Larger step size ; When the loss equation is in a steeper region , Smaller step size . It's just Fisher Matrix The size of increases with the size of the parameter vector , The size is
The specific function content is the same as natural gradient irrelevant , because natrual gradient It just solves the problem of making adjacent strategies have strong similarity ( Changed the update direction of the parameter vector ), Ensure the stability of the learning process . meanwhile natural gradient Curvature dependent inverse , When the loss equation is in a flat position , Larger step size ; When the loss equation is in a steeper region , Smaller step size . It's just Fisher Matrix The size of increases with the size of the parameter vector , The size is  , Therefore, finding the inverse will be more troublesome . So sometimes we use conjugate gradient,K-FAC Etc .
, Therefore, finding the inverse will be more troublesome . So sometimes we use conjugate gradient,K-FAC Etc .
Part Two: Natural Actor Critic
Part Three: Trust Region Policy Optimization TRPO
Objective Function
TRPO The objective function used in is ![\eta(\pi_\theta)=E_{\tau \sim \pi_\theta}[\sum_{t=0}^{\infty}\gamma^t r_t]](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_28.gif%3DE_%7B%5Ctau%20%5Csim%20%5Cpi_%5Ctheta%7D%5B%5Csum_%7Bt%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Et%20r_t%5D)

prove :
![E_{\tau \sim \pi_{i+1}}[\sum_{t=0}^\infty \gamma^t A^\pi(s_t,a_t)] \\= E_{\tau \sim \pi_{i+1}}[\sum_{t=0}^\infty \gamma^t( R(s_t,a_t,s_{t+1})+\gamma V^\pi (s_{t+1})-V^\pi(s_t) )] \\=\eta(\pi_{i+1})+ E_{\tau \sim \pi_{i+1}}[\sum_{t=1}^{\infty} \gamma^{t}V^\pi(s_t) - \sum_{t=0}^{\infty}\gamma^t V^{\pi}(s_t) ] \\= \eta(\pi_{i+1}) - E_{\tau \sim \pi_{i+1}}[V^\pi(s_0)] \\= \eta(\pi_{i+1}) - \eta(\pi)](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_14.gif)
Surrogate Function
TRPO use Minorize-Maximization Algorithom, Find a lower boundary function under the parameter vector at each time surrogate function, Parameter vectors are also used as parameters , Under this parameter vector and  equal , Less than... Under other parameters in the parameter space . In addition, the lower boundary function needs to be easier to optimize than the original function .
equal , Less than... Under other parameters in the parameter space . In addition, the lower boundary function needs to be easier to optimize than the original function .
Because we know that the lower boundary function is close to the objective function under the current parameter vector , Therefore, we can know the direction of the lower boundary function near the current parameter vector The optimization direction is approximate to the objective function , So we can choose a lower boundary function at every moment , Then optimize the lower boundary function every time , So as to get the optimization of the objective function . So the key is how to choose the lower boundary function .

We define functions


Then we define surrogate function:

among 
How to understand TRPO All the mathematical derivation details in ? - You know (zhihu.com)
here  Meet the following three conditions :
Meet the following three conditions :



therefore Is a lower boundary function of the objective function , The objective function can be optimized through the lower boundary function at the point of the parameter vector .
Use it directly natural gradient To optimize
aim: 
constraint: 
![g_k \\=\bigtriangledown_{\theta_{i+1}}J_{\theta_i}(\theta_{i+1})\\=E_{s \sim \rho_{\theta_i},a \sim \pi_{\theta_i}}[\frac{\bigtriangledown_{\theta_{i+1}}\pi_{i+1}(a|s)}{\pi_i(a|s)}A_\pi(s,a)]\\=E_{s \sim \rho_{\theta_i},a \sim \pi_{\theta_i}}[\bigtriangledown_{\theta_{i}}log \ \pi(a|s)A_\pi(s,a)]|_{\theta_{i+1}=\theta_i} \\=\frac{1}{N}\sum_{l=0}^N \sum_{t=0}^{T}\bigtriangledown_{\theta_i} log \ \pi(a_t|s_t)A_\pi(s_t,a_t)](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_20.gif)
however , In order to prevent the new parameter vector and the original parameter vector exceed , We use the following formula to update the parameter vector :

j Take the minimum nonnegative integer that can make the similarity of adjacent strategies meet the requirements .
TRPO It works better in the full connection layer , But in CNN perhaps RNN Poor performance in the middle school .
Part Four: Proximal Policy Optimization PPO
In view of the above TRPO Poor algorithm complexity , Higher computation ,PPO By changing surrogate function To optimize .
![L^{CLIP}(\theta) = E_t[min( \rho_t(\theta)A_{\pi_{\theta_{old}}}(s_t,a_t), \ clip(\rho_t(\theta),1-\epsilon,1+\epsilon)A_{\pi_{\theta_{old}}}(s_t,a_t)) ]](http://img.inotgo.com/imagesLocal/202202/15/202202150539009801_6.gif)
When  At the right time , It shows that this is a better action , We should increase the probability , But in order to prevent the probability of increasing too much , We need to limit , Make the parameter vector in the right direction , Move smaller steps , Make the adjacent strategies approximate . When When it's negative , This is an action that should reduce the probability , In order to prevent too much reduction , We limit its step size .
At the right time , It shows that this is a better action , We should increase the probability , But in order to prevent the probability of increasing too much , We need to limit , Make the parameter vector in the right direction , Move smaller steps , Make the adjacent strategies approximate . When When it's negative , This is an action that should reduce the probability , In order to prevent too much reduction , We limit its step size .
in addition , We go through clip The similarity limit of adjacent strategies has been implemented , Therefore, it is possible to avoid KL Divergence The calculation of , It can reduce a lot of computation , But use SGD(stochastic gradient descent) Achieve a first-order gradient . meanwhile , Because the similarity between adjacent strategies is high , Can not be completely satisfied on-policy How to update , Can be in multiple episodes Updated many times in , The complexity of the algorithm is greatly reduced .

Proximal Policy Optimization — Spinning Up documentation (openai.com)
Part Five: Actor-Critic with Experience Replay ACER
边栏推荐
- The underlying principle of vector
- 波士顿房价预测(TensorFlow2.9实践)
- LeetCode - 703 数据流中的第 K 大元素(设计 - 优先队列)
- CV learning notes - image filter
- LeetCode - 933 最近的请求次数
- Screen display of charging pile design -- led driver ta6932
- 20220603 Mathematics: pow (x, n)
- LeetCode - 673. 最长递增子序列的个数
- Leetcode-513: find the lower left corner value of the tree
- 20220601数学:阶乘后的零
猜你喜欢
LeetCode - 673. 最长递增子序列的个数
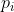
Retinaface: single stage dense face localization in the wild

openCV+dlib实现给蒙娜丽莎换脸

【C 题集】of Ⅵ

LeetCode - 508. 出现次数最多的子树元素和 (二叉树的遍历)

What can I do to exit the current operation and confirm it twice?
[C question set] of Ⅵ
Leetcode-513: find the lower left corner value of the tree

LeetCode 面试题 17.20. 连续中值(大顶堆+小顶堆)
LeetCode - 673. Number of longest increasing subsequences
随机推荐
My openwrt learning notes (V): choice of openwrt development hardware platform - mt7688
Opencv note 21 frequency domain filtering
Tensorflow2.0 save model
Leetcode-404: sum of left leaves
Markdown latex full quantifier and existential quantifier (for all, existential)
Swing transformer details-1
Window maximum and minimum settings
CV learning notes - clustering
Wireshark use
4G module IMEI of charging pile design
20220601 Mathematics: zero after factorial
LeetCode 面试题 17.20. 连续中值(大顶堆+小顶堆)
使用sed替换文件夹下文件
LeetCode - 508. 出现次数最多的子树元素和 (二叉树的遍历)
LeetCode - 1670 設計前中後隊列(設計 - 兩個雙端隊列)
『快速入门electron』之实现窗口拖拽
El table X-axis direction (horizontal) scroll bar slides to the right by default
CV learning notes - scale invariant feature transformation (SIFT)
Cases of OpenCV image enhancement
Yocto technology sharing phase IV: customize and add software package support