当前位置:网站首页>Data preprocessing - Data Mining 1
Data preprocessing - Data Mining 1
2022-07-03 10:24:00 【Why】
- Put the data in “?” Make up the missing data of the sign .
use “ Mean replacement ” Methods to make up the missing data , Replace the missing value of the column with the mean value of each column .
# Import pandas The library operates on file data
import pandas as pd
# Read file data set
df = pd.read_excel(' Homework 1_ Data preprocessing dataset .xls')
# Calculate the average value of each column to fill the missing value of the corresponding column
df.fillna(value = df.mean(),inplace=True)
# Export the populated dataset to another excel In file
df.to_excel(" Homework 1_ Missing values filled .xlsx",index=False)
- Calculate the quartile of each numerical dimension , And make a box diagram .
Calculate the quartile of each numerical dimension :
Method 1 :
# Read the dataset file that has filled in the missing values
df = pd.read_excel(' Homework 1_ Missing values filled .xlsx')
# Calculate the quartile of each numerical dimension
print(" Total basic integral of observation window ")
print(" The upper quartile is :"+str(df.iloc[:,2].quantile(0.25)))
print(" The lower quartile is :"+str(df.iloc[:,2].quantile(0.75)))
print("\n The total ticket price in the second year ")
print(" The upper quartile is :"+str(df.iloc[:,3].quantile(0.25)))
print(" The lower quartile is :"+str(df.iloc[:,3].quantile(0.75)))
print("\n Total flight kilometers of observation window ")
print(" The upper quartile is :"+str(df.iloc[:,4].quantile(0.25)))
print(" The lower quartile is :"+str(df.iloc[:,4].quantile(0.75)))
print("\n Total weighted flight kilometers of observation window (Σ Space discount × Leg distance )")
print(" The upper quartile is :"+str(df.iloc[:,5].quantile(0.25)))
print(" The lower quartile is :"+str(df.iloc[:,5].quantile(0.75)))
print("\n The quarterly average basic integral accumulation of the observation window ")
print(" The upper quartile is :"+str(df.iloc[:,6].quantile(0.25)))
print(" The lower quartile is :"+str(df.iloc[:,6].quantile(0.75)))
 |  |
Method 2 :
df = pd.read_excel(' Homework 1_ Missing values filled .xlsx')
print(df.describe())
 |  |
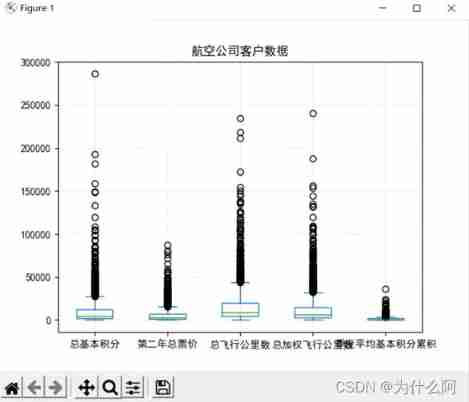
Box chart :
The box diagram adopts python Related drawing packages matplotlib.pyplot draw
Result analysis : The data is mainly concentrated in [0,25000] In interval , Uneven data distribution , There is a separation group point .
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif']=['SimHei']
df = pd.read_excel(' Homework 1_ Missing values filled .xlsx')
df.plot.box(title=" Airline customer data ")
plt.grid(linestyle="--", alpha=0.3)
plt.show()
- Make a histogram of each numerical dimension 、 Q-Q Plot 、 Scatter map .
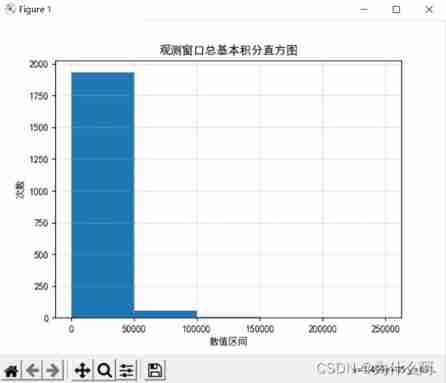
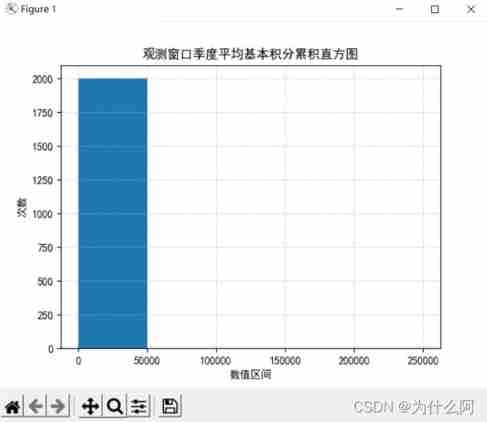
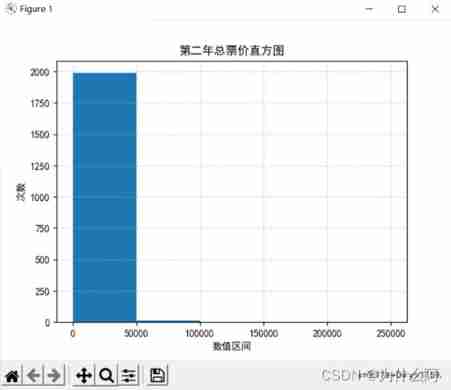
Histogram :
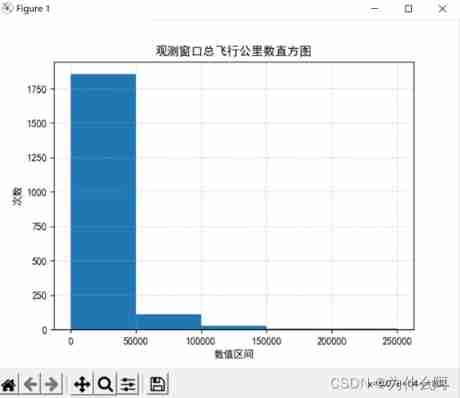
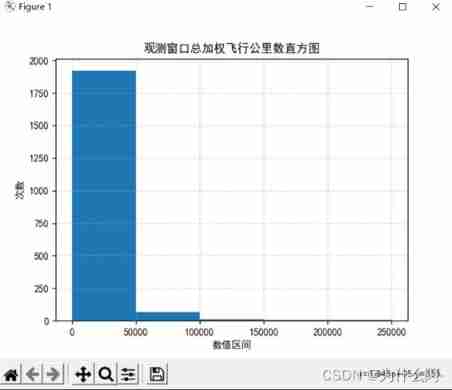
Result analysis : The data is mainly concentrated in 0-50000 Between , Uneven data distribution , The interval distribution of attribute data is generally similar .
df = pd.read_excel(' Homework 1_ Missing values filled .xlsx')
plt.hist(df.iloc[:,6], bins=[0,50000,100000,150000,250000])
# Show horizontal axis labels
plt.xlabel(" Numerical range ")
# Displays the vertical axis label
plt.ylabel(" frequency ")
# Show picture title
plt.title(" Observation window quarterly average basic integral cumulative histogram ")
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
Q-Q Plot :
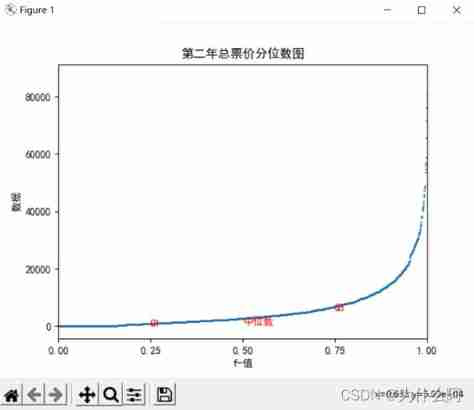
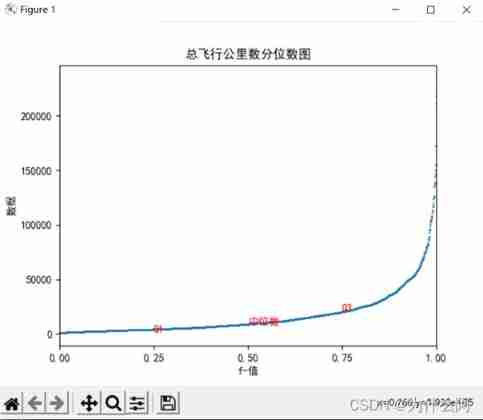
Result analysis : The data is mainly concentrated in 0-20000, Unevenly distributed
df = pd.read_excel(' Homework 1_ Missing values filled .xlsx')
plt.scatter((np.arange(2000)+1)/2000,df.iloc[:,2].sort_values(),s=0.5)
x_major_locator=MultipleLocator(0.25)
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.xlim(0,1)
# Show picture title
plt.text(0.25,df.iloc[:,2].sort_values()[24],"Q1",color="r")
plt.text(0.50,df.iloc[:,2].sort_values()[49]," Median ",color="r")
plt.text(0.75,df.iloc[:,2].sort_values()[74],"Q3",color="r")
plt.title(" Figure of total basic integral and cumulative integral digits of observation window ")
plt.xlabel("f- value ")# Abscissa name
plt.ylabel(" data ")# The ordinate name
plt.show()



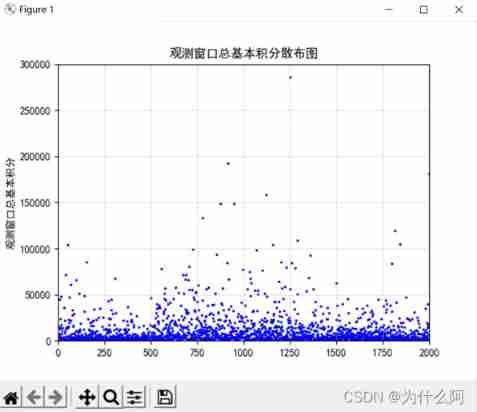
Scatter map :
Visible data is concentrated in 0-50000 Between , There are small separated group points
df = pd.read_excel(' Homework 1_ Missing values filled .xlsx')
plt.scatter(np.arange(2000),df.iloc[:,2],edgecolor='blue',s=2)
# Displays the vertical axis label
plt.ylabel(" The quarterly average basic integral accumulation of the observation window ")
# Show picture title
plt.title(" Cumulative scatter diagram of quarterly average basic integral of observation window ")
plt.axis([0,2000,0,300000])
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()

- Minimize the data according to each attribute - Maximize normalization and z-score Normalization .
Use python Language , Use the following formula to write code to minimize the data - Maximize normalization and z-score Normalization .
Minimum - Maximum normalization :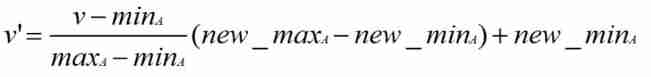
# Minimum - Maximum normalization
a1=(df.iloc[:,2] - df.iloc[:,2].min())/(df.iloc[:,2].max() - df.iloc[:,2].min())
print(" The total basic integral is the smallest - Maximum normalization :"+str(a1))
a2=(df.iloc[:,3] - df.iloc[:,3].min())/(df.iloc[:,3].max() - df.iloc[:,3].min())
print(" The total ticket price in the second year is the smallest - Maximum normalization :"+str(a2))
a3=(df.iloc[:,4] - df.iloc[:,4].min())/(df.iloc[:,4].max() - df.iloc[:,4].min())
print(" The minimum total flying kilometers - Maximum normalization :"+str(a3))
a4=(df.iloc[:,5] - df.iloc[:,5].min())/(df.iloc[:,5].max() - df.iloc[:,5].min())
print(" The total weighted flight kilometers are the smallest - Maximum normalization :"+str(a4))
a5=(df.iloc[:,6] - df.iloc[:,6].min())/(df.iloc[:,6].max() - df.iloc[:,6].min())
print(" The cumulative average of quarterly basic points is the smallest - Maximum normalization :"+str(a5))
Because there's so much data , The omission is shown below :
z-score Normalization :
# zero - Mean normalization
b1=(df.iloc[:,2] - df.iloc[:,2].mean())/df.iloc[:,2].std()
print(" Total basic integral z-score Normalization :"+str(b1))
b2=(df.iloc[:,3] - df.iloc[:,3].mean())/df.iloc[:,3].std()
print(" The total ticket price in the second year z-score Normalization :"+str(b2))
b3=(df.iloc[:,4] - df.iloc[:,4].mean())/df.iloc[:,4].std()
print(" Total flying kilometers z-score Normalization :"+str(b3))
b4=(df.iloc[:,5] - df.iloc[:,5].mean())/df.iloc[:,5].std()
print(" Total weighted flight kilometers z-score Normalization :"+str(b4))
b5=(df.iloc[:,6] - df.iloc[:,6].mean())/df.iloc[:,6].std()
print(" Quarterly average basic points accumulation z-score Normalization :"+str(b5))
Because there's so much data , The omission is shown below :
边栏推荐
- QT is a method of batch modifying the style of a certain type of control after naming the control
- LeetCode - 706 设计哈希映射(设计) *
- Hands on deep learning pytorch version exercise answer - 2.2 preliminary knowledge / data preprocessing
- Discrete-event system
- 20220602数学:Excel表列序号
- LeetCode - 5 最长回文子串
- 2312. Selling wood blocks | things about the interviewer and crazy Zhang San (leetcode, with mind map + all solutions)
- Leetcode-112:路径总和
- CV learning notes - BP neural network training example (including detailed calculation process and formula derivation)
- QT creator uses OpenCV Pro add
猜你喜欢

Deep learning by Pytorch
Opencv Harris corner detection
LeetCode - 919. Full binary tree inserter (array)

Opencv histogram equalization
Powshell's set location: unable to find a solution to the problem of accepting actual parameters

Leetcode - 460 LFU cache (Design - hash table + bidirectional linked hash table + balanced binary tree (TreeSet))*
Dictionary tree prefix tree trie

Hands on deep learning pytorch version exercise answer - 2.2 preliminary knowledge / data preprocessing

2312. Selling wood blocks | things about the interviewer and crazy Zhang San (leetcode, with mind map + all solutions)
重写波士顿房价预测任务(使用飞桨paddlepaddle)
随机推荐
LeetCode - 715. Range module (TreeSet)*****
Hands on deep learning pytorch version exercise solution - 3.1 linear regression
CV learning notes alexnet
20220610其他:任务调度器
Opencv image rotation
20220609其他:多数元素
Leetcode bit operation
20220601 Mathematics: zero after factorial
Label Semantic Aware Pre-training for Few-shot Text Classification
Leetcode-513: find the lower left corner value of the tree
2.1 Dynamic programming and case study: Jack‘s car rental
波士顿房价预测(TensorFlow2.9实践)
LeetCode - 1172 餐盘栈 (设计 - List + 小顶堆 + 栈))
What did I read in order to understand the to do list
Problems encountered when MySQL saves CSV files
Toolbutton property settings
CV learning notes convolutional neural network
One click generate traffic password (exaggerated advertisement title)
When the reference is assigned to auto
20220605数学:两数相除