当前位置:网站首页>Reading notes of Clickhouse principle analysis and Application Practice (4)
Reading notes of Clickhouse principle analysis and Application Practice (4)
2022-07-04 06:10:00 【Aiky WOW】
Begin to learn 《ClickHouse Principle analysis and application practice 》, Write a blog and take reading notes .
The whole content of this article comes from the content of the book , Personal refining .

The fifth chapter :
The first 6 Chapter MergeTree Principle analysis
MergeTree As ck The most basic table engine , A primary key index is provided 、 Data partition 、 Basic capabilities such as data copy and data sampling , Other table engines in the family are MergeTree Each has his own strengths on the basis of .

6.1 MergeTree Creation method and storage structure of
MergeTree When writing a batch of data , Data is always written to the magnet in the form of data fragments disc , And the data fragment cannot be modified . To avoid too many fragments ,ClickHouse Through the background thread , Merge these pieces of data on a regular basis , Data fragments belonging to the same partition will be combined into a new fragment .
6.1.1 MergeTree How to create
Statement Engine=MergeTree()
MergeTree Several important parameters of the table engine :
- PARTITION BY [ optional ]: The partitioning key . You can have multiple column fields , Support the use of list expressions . Do not declare partition keys , be ClickHouse Will generate a file named all The partition .
- ORDER BY [ Required ]: Sort key . By default, the primary key (PRIMARY KEY) Same as sort key . You can have multiple column fields , At this time, sort by field .
- PRIMARY KEY [ optional ]: Primary key . The primary index will be generated according to the primary key field , The default is the same as the sort key .MergeTree Duplicate data is allowed in the primary key (ReplacingMergeTree You can get rid of it ).【 When the specified primary key and sorting key are different :】
- At this time, the sort key is used to sort in the data segment , The primary key is used to write marks in the index file .
- The primary key expression tuple must be the prefix of the sort key expression tuple , That is, the primary key is (a,b), Sort column must be (a,b,******).
- SAMPLE BY [ optional ]: Sampling expression . Declare the standard by which the data is sampled . Sampling expressions need to be matched SAMPLE Subquery uses , This function is useful for selecting samples The data is very useful , For more information about the use of sampling queries, see 9 Chapter introduction .
【 In addition, the book also writes settings, But this current version is no longer applicable . In addition, the new version also adds ttl】
- TTL [ optional ]: Specify the storage duration of rows and define the logic for automatic part movement between disks and volumes . The expression must have a Date perhaps DateTime As a result , for example `TTL date + INTERVAL 1 DAY`, Type of rule `DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'|GROUP BY`
- SETTINGS[ optional ]: control MergeTree Additional parameters of behavior , For details, please refer to the official website .
6.1.2 MergeTree Storage structure of
MergeTree The data in the table engine has physical storage , The data will be saved to the disk in the form of partition Directory .

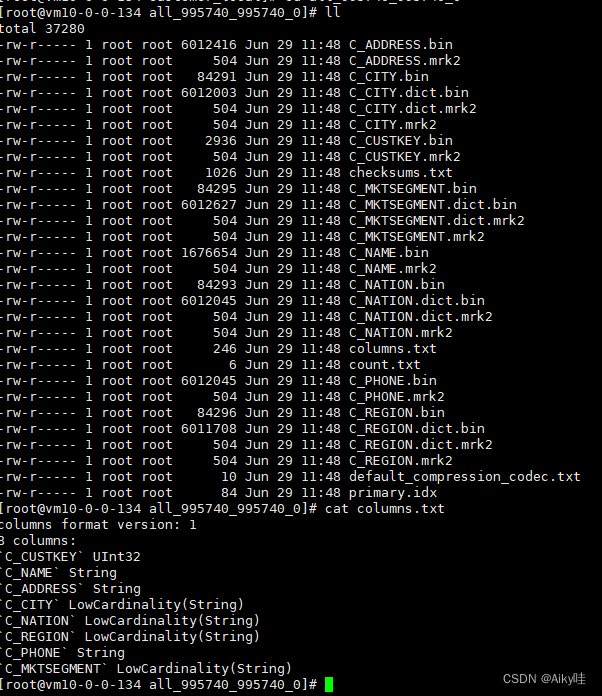
Storage instructions under a table folder :
partition: Partition Directory
Various data files (primary.idx、 [Column].mrk、[Column].bin etc. ) They are organized and stored in the form of partition directory Of .
Data of the same partition , It will eventually be merged into the same partition Directory .
checksums.txt: Verify File
Store in binary format .
Save the remaining files (primary.idx、count.txt etc. ) Of size Size and size Hash value of , It is used to quickly verify the integrity and correctness of files .
columns.txt: Column information file
Clear text format storage . Used to save the column field information under this data partition .
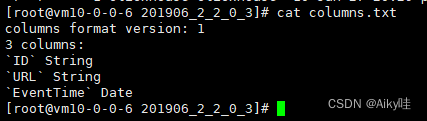
count.txt: Count files
Store in clear text format . Used to record the total number of rows of data under the current data partition directory .
primary.idx: First level index file
Binary format storage . Used to store sparse indexes , a sheet MergeTree A table can only declare a first level index once ( adopt ORDER BY perhaps PRIMARY KEY).
[Column].bin: Data files
Store in a compressed format , The default is LZ4 Compressed format . Each column field has its own .bin Data files
[Column].mrk/[Column].mrk2: Column field tag file
Binary format storage . The tag file contains .bin Offset information of data in the file . Each column field will have its corresponding .mrk Tag file .
Mark file alignment with sparse index , And .bin The documents correspond to each other .
MergeTree Created by marking files primary.idx Sparse index and .bin Mapping between data files . First, dilute Sparse index (primary.idx) Find the offset information of the corresponding data (.mrk), Then directly from... By offset .bin The data is read from the file .
If an index interval of adaptive size is used ( Parameter control ), The tag file will be marked with .mrk2 name . Its working principle and function are similar to .mrk The tag file is the same .
partition.dat And minmax_[Column].idx:
Partition key is used , Will generate additional partition.dat And minmax Index file , They are stored in binary format .
partition.dat Used to save the final value generated by the partition expression under the current partition .
minmax The index is used to record the minimum and maximum values of the partition field corresponding to the original data under the current partition .
for example ,EventTime The original data corresponding to the field is 2019-05-01、2019-05-05, The partition expression is PARTITION BY toYYYYMM(EventTime).partition.dat The value saved in will be 2019- 05, and minmax The value stored in the index will be 2019-05-012019-05-05.
You can quickly skip unnecessary data partition directories when querying data .
skp_idx_[Column].idx And skp_idx_[Column].mrk:
If a secondary index is declared , Generate the corresponding secondary index and tag files additionally , They also use binary storage .
The secondary index is in ClickHouse It is also called hop count Indexes , Currently owned minmax、set、ngrambf_v1 and tokenbf_v1 Four types . The details will be 6.4 Section describes .
6.2 Data partition
6.2.1 Partition rules of data
Partition ID The generation logic currently has four rules :
- Do not specify partition key : I don't use PARTITION BY, Then partition ID The default name is all.
- Use integer : If the partition key value belongs to integer type and cannot be converted to date type YYYYMMDD Format , Then output directly in the character form of the integer , As a partition ID The value of .
- Use date type : The date type may be changed to YYYYMMDD Integer of format , Use according to YYYYMMDD As a partition ID The value of .
- Other types : for example String、Float etc. , Through 128 position Hash The algorithm takes its Hash Value as partition ID The value of .

If you use multiple partitioning keys , Then follow the above rules , Use - Connect .
PARTITION BY (length(Code),EventTime)
Zoning :
2-20190501
2-201906116.2.2 Naming rules for partitioned directories
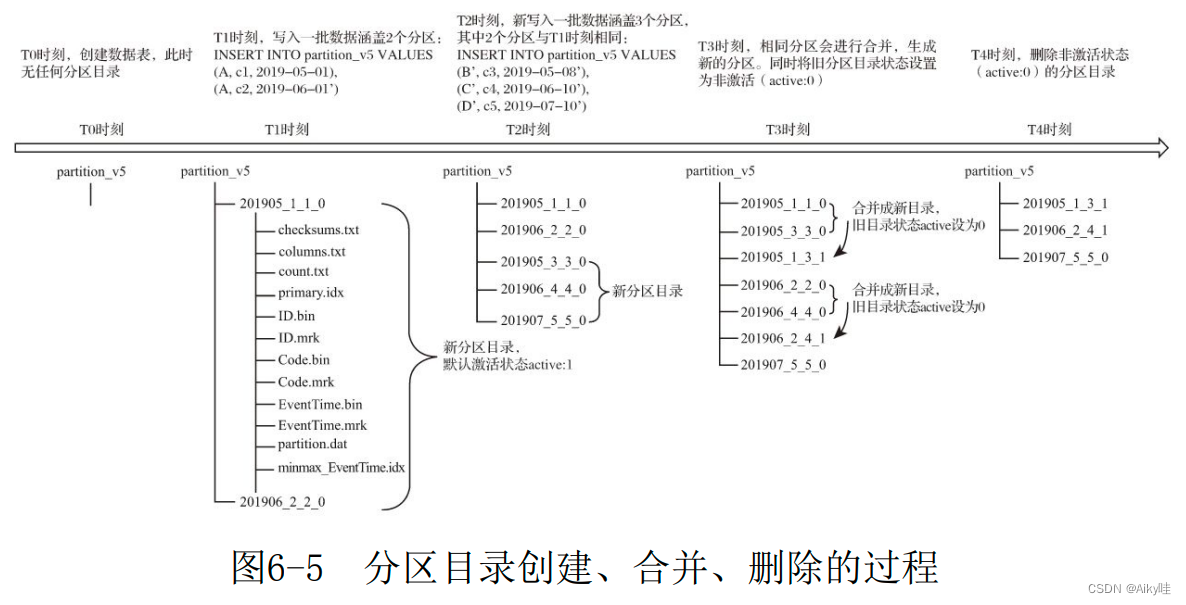
MergeTree The full physical name of the partition directory , stay ID Followed by a string of strange numbers , for example 201905_1_1_0.

The naming formula of a complete partition directory is as follows :
PartitionID_MinBlockNum_MaxBlockNum_Level
- PartitionID: Partition ID
- MinBlockNum and MaxBlockNum: Minimum block number and maximum block number . there BlockNum Is an integer self increasing number . Count n On the sheet MergeTree Global accumulation in the data table ,n from 1 Start , Create a new partition directory each time , Count plus 1. Therefore, the minimum and maximum data block numbers of the new directory are equal to n.
- Level: The level of consolidation , The number of times a partition has been merged . The initial value of each newly created partition directory is 0, If the same partition is merged , Then count and accumulate in the corresponding partition 1.
6.2.3 The merging process of partition directories
MergeTree Write each batch of data ( once INSERT sentence ), MergeTree Will generate a batch of new partition directories .
Even if the data written in different batches belong to the same partition , Different partition directories will also be generated .
In the following ck The background will merge multiple directories belonging to the same partition into a new directory .
The old partition directory will not be deleted immediately , Instead, the background task is deleted .
The indexes and data files in the merged directory will also be merged accordingly .
- PartitionID: unchanged
- MinBlockNum: Take the smallest of all directories in the same partition MinBlockNum value .
- MaxBlockNum: Take the largest of all directories in the same partition MaxBlockNum value .
- Level: Take the maximum in the same partition Level Value plus 1.
6.3 First level index
MergeTree The primary key of PRIMARY KEY Definition , More common is through ORDER BY Refers to the primary key .
MergeTree Will be based on index_granularity interval ( Default 8192 That's ok ), Generate a primary index for the data table and save it to primary.idx In the file .
PRIMARY KEY And ORDER BY Define different application scenarios in SummingMergeTree The engine chapter will introduce .
6.3.1 Sparse index
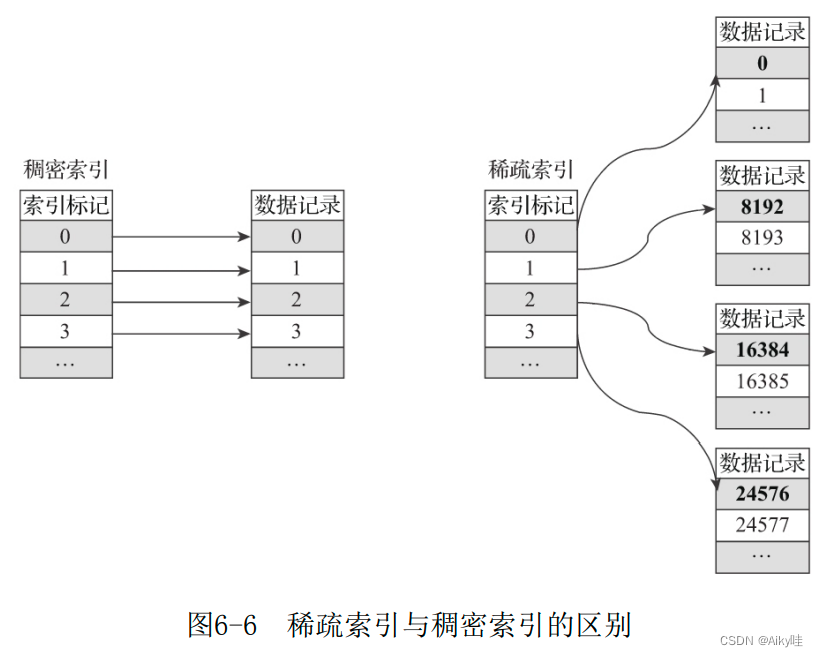
Sparse index takes up less space , therefore primary.idx Index data in is resident in memory , The access speed is naturally very fast .
6.3.2 Index granularity
Index granularity is very important to MergeTree Is a very important concept .
By the parameter index_granularity Definition .
MergeTree Use MarkRange Express A specific interval , And pass start and end Indicates its specific scope .
index_granularity It will also affect the data marking (.mrk) And data files (.bin).
6.3.3 Generation rules of index data
MergeTree Interval required index_granularity Data will generate an index record .
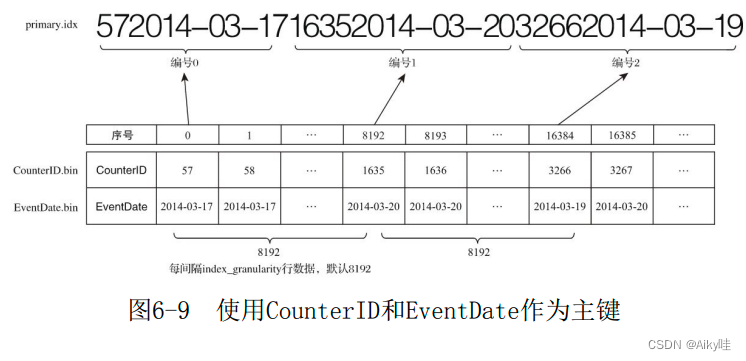
If you use CounterID A primary key (ORDER BY CounterID), Then every interval 8192 Row data will be fetched once CounterID As the index value , The index data will eventually be written primary.idx Keep the file .
for example . The first 0(8192*0) That's ok CounterID Value 57, The first 8192(8192*1) That's ok CounterID Value 1635, And the first 16384(8192*2) That's ok CounterID Value 3266, The final index data will be 5716353266.

I can see MergeTree The storage of sparse indexes is very compact .
If you use multiple primary keys , for example ORDER BY(CounterID,EventDate), Then every interval 8192 Line can be taken at the same time CounterID And EventDate The values of the two columns are used as index values .
6.3.4 Query process of index
A specific data segment is a MarkRange . Corresponds to the index number , Use start and end Two attributes represent its interval norm around .
The whole index query process can be roughly divided into 3 A step .
- Generate query condition interval : Convert query criteria into condition interval .
WHERE ID = 'A003' ['A003', 'A003'] WHERE ID > 'A000' ('A000', +inf) WHERE ID < 'A188' (-inf, 'A188') WHERE ID LIKE 'A006%' ['A006', 'A007') - Recursive intersection judgment : Start from the largest interval :
- If there is no intersection , Then the whole segment is optimized directly by pruning algorithm MarkRange.
- If there is an intersection , And MarkRange It can't be broken down , Record MarkRange And back to .
- If there is an intersection , And MarkRange Decomposable , Continue recursion .
- Merge MarkRange Section : Will finally match MarkRange Get together , Merge their scope .
6.4 Secondary indexes
The purpose is the same as the primary index , It also helps reduce the scope of data scanning during query .
Need to be in CREATE Define... Within a statement :
INDEX index_name expr TYPE index_type(...) GRANULARITY granularityThe corresponding index and tag files will be generated additionally (skp_idx_[Column].idx And skp_idx_[Column].mrk).
6.4.1 granularity And index_granularity The relationship between
Different secondary indexes share granularity Parameters .
index_granularity Defines the granularity of data , and granularity Defines the granularity of aggregation information summary .granularity Defines how many hops a row index can skip index_granularity Interval data .

6.4.2 Type of hop index
MergeTree In support of 4 A hop index , Namely minmax、set、 ngrambf_v1 and tokenbf_v1.
CREATE TABLE skip_test (
ID String,
URL String,
Code String,
EventTime Date,
INDEX a ID TYPE minmax GRANULARITY 5,
INDEX b(length(ID) * 8) TYPE set(2) GRANULARITY 5,
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5,
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
) ENGINE = MergeTree()
Omit ...minmax:
minmax The index records the minimum and maximum extreme values in a piece of data .
Similar to partition directory minmax Indexes , Can quickly skip useless data intervals .
set:
set The index directly records the value of the declaration field or expression ( only value , No repetition ).
Its complete form is set(max_rows), among max_rows It's a threshold , It means in a index_granularity Inside , The maximum number of data rows recorded by the index .
If max_rows=0, It means unlimited .
ngrambf_v1:
Bloom table filter for data phrases , Only support String and FixedString data type .
Can only improve in、notIn、like、equals and notEquals Query performance .
The complete form is ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_fun ctions,random_seed).
- n:token length , basis n The length of cuts the data into token The phrase .
- size_of_bloom_filter_in_bytes: The size of the bloon filter .
- number_of_hash_functions: Used in Bloom filters Hash Of function Count .
- random_seed:Hash Random seed of function .
tokenbf_v1:
yes ngrambf_v1 Variants , It is also a bloom filter index .
and ngrambf_v1 The difference is that there is no need to specify token length .
tokenbf_v1 Will automatically follow the non character 、 String segmentation of numbers token.
6.5 data storage
6.5.1 Each column is stored independently
Each column field has a corresponding .bin Data files .
Columnar storage is better for data compression , Minimize the scope of data scanning .
MergeTree The design of the :
- The data is compressed , At present, we support LZ4、ZSTD、Multiple and Delta Several algorithms , By default LZ4 Algorithm ;
- The data will be in accordance with ORDER BY Sort of declarations ;
- The data is It is organized and written in the form of compressed data blocks .bin In the document .
6.5.2 Compressed data block
It consists of header information and compressed data .
Header information is fixed 9 Bit byte means , Specific reasons 1 individual UInt8(1 byte ) Integer sum 2 individual UInt32(4 byte ) Integer composition , Each represents the type of compression algorithm used 、 The data size after compression and the data size before compression

adopt ClickHouse Provided clickhouse-compressor Tools , Be able to query a .bin Statistics of compressed data in the file .
clickhouse-compressor --stat bin File path 
Each row of data represents the header information of a compressed data block , It represents the size of uncompressed data and compressed data in the compressed block respectively .
The upper and lower limits of each compressed data block are respectively determined by min_compress_block_size( Default 65536) And max_compress_block_size( Default 1048576) Parameter assignment .
The final size of a compressed data block and an interval (index_granularity) The actual size of the data in the .
MergeTree In the specific writing process of data , According to the index granularity ( By default , Every time 8192 That's ok ), Obtain and process data by batch . If the uncompressed size of a batch of data is set to size, Then the whole writing process follows the following rules :
- size<64KB: Single batch data is less than 64KB, Then continue to obtain the next batch of data , Until it accumulates to size>=64KB when , Generate the next compressed data block .
- 64KB<=size<=1MB : If the data size of a single batch is exactly 64KB And 1MB Between , Then directly generate the next compressed data block .
- size>1MB : If the data of a single batch directly exceeds 1MB, First, according to 1MB The size is truncated and the next compressed data block is generated . The remaining data continues to be executed in accordance with the above rules . At this time, a batch of data generates multiple compressed data blocks .
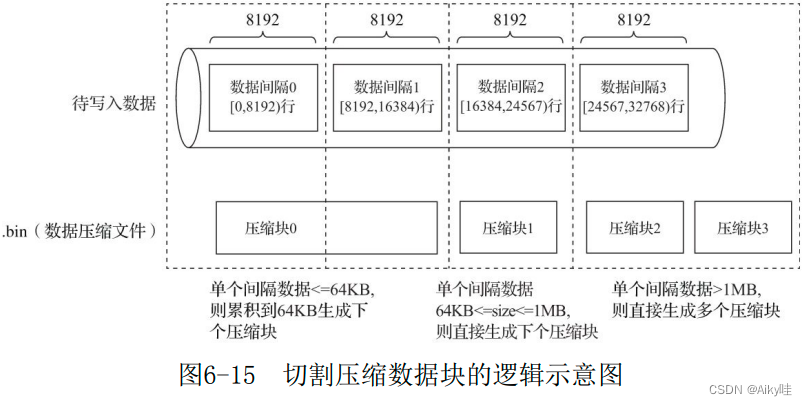
Between multiple compressed data blocks , End to end in writing order .
.bin The purpose of introducing compressed data blocks into the file :
- Find a balance between performance loss and compression ratio
- Reduce read granularity to the compressed block level
6.6 Data tags
If you put MergeTree Compared to a Book ,primary.idx The primary index is like the primary chapter catalogue of this book ,.bin The data in the document is like the text in this book , So the data tag (.mrk) The association will be established between the first level chapter directory and the specific text . For data markers , It records two important information : firstly , It is the page information corresponding to the first level chapter ; second , It is the starting position information of a paragraph of text on a page .
【 The offset position is not recorded in the index , The value is recorded , Jump needs to be marked with data .】
6.6.1 Rules for generating data tags
The data marker and index interval are aligned , All in accordance with index_granularity Granularity interval of . Data tag files are also associated with .bin The documents correspond to each other .
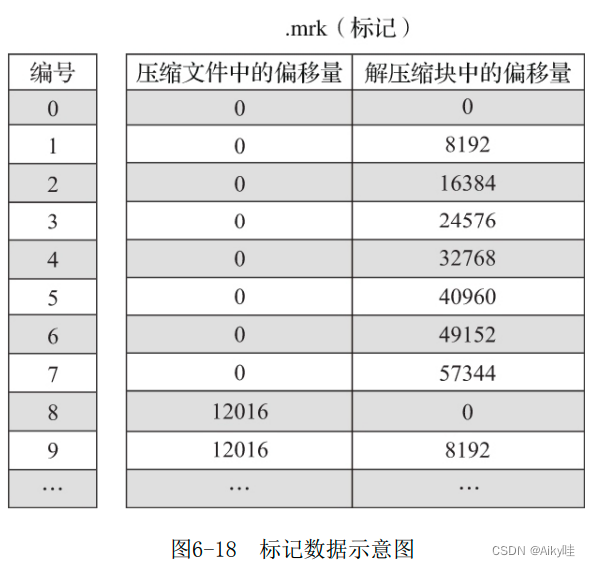
Each column field [Column].bin Each file has a corresponding [Column].mrk Data tag file , Used to record data in .bin Offset information in the file .
A row of marked data is represented by a tuple of two integers , Respectively represents the starting offset of the compressed data block ; And uncompress after decompression The starting offset of the reduced data .
Tag data is different from primary index data , It does not reside in memory , But use LRU( Recently at least use ) Cache policy speeds up its access .
6.6.2 How data markers work
Mergetree The steps of reading data can be divided into two steps: reading compressed data blocks and reading data .
With hits_v1 Of the test table JavaEnable Field as an example .JavaEnable The data type of the field is UInt8, So each row of values takes 1 byte .index_granularity The granularity is 8192, The data size of an index fragment is exactly 8192B. Generate rules according to data compression blocks ,JavaEnable In the tag file , Every time 8 Row mark data corresponds to 1 Compressed data blocks .
The corresponding relationship between the marked data and the compressed data :

Read compressed data block
MergeTree Only load specific compressed data blocks into memory , There is no need to load the whole at once .bin file .
Tag data , The offset of the two compressed files is the first offset interval with fast compression .
stay .mrk In file , The first 0 The cut-off offset of compressed data blocks is 12016. And in the .bin In the data file , The first 0 The compressed size of compressed data blocks is 12000. Why are the two values different ?
The reason is simple ,12000 Just the number of bytes after data compression , There is no header part . A complete compressed data block is composed of header information and compressed data , Its header information is fixed by 9 Byte composition , The compressed size is 8 Bytes . therefore ,12016=8+12000+8
After the compressed data block is completely loaded into memory , Will decompress , After that, we will enter the specific data reading link .
Reading data
When reading the decompressed data ,MergeTree You don't need to scan the whole section of decompressed data at one time , It can... As needed , With index_granularity The granularity of loading a specific segment . To implement this feature , You need to use the offset in the decompressed data block saved in the tag file .
For example, in figure 6-19 As shown in , adopt [0,8192] Able to read compressed data blocks 0 The first data segment in .
6.7 For partitions 、 Indexes 、 Collaborative summary of tagged and compressed data
From the writing process 、 check Inquiry process , And three corresponding relations between data mark and compressed data block .
6.7.1 Write process
First step , With each batch of written data , Generate a new partition Directory . These new partition directories will be merged in the background .
The second step , according to index_granularity Index granularity , Will be generated separately primary.idx First level index ( If a secondary index is declared , Also create a secondary index file )、 Of each column field .mrk Data markers and .bin Compressed data file .
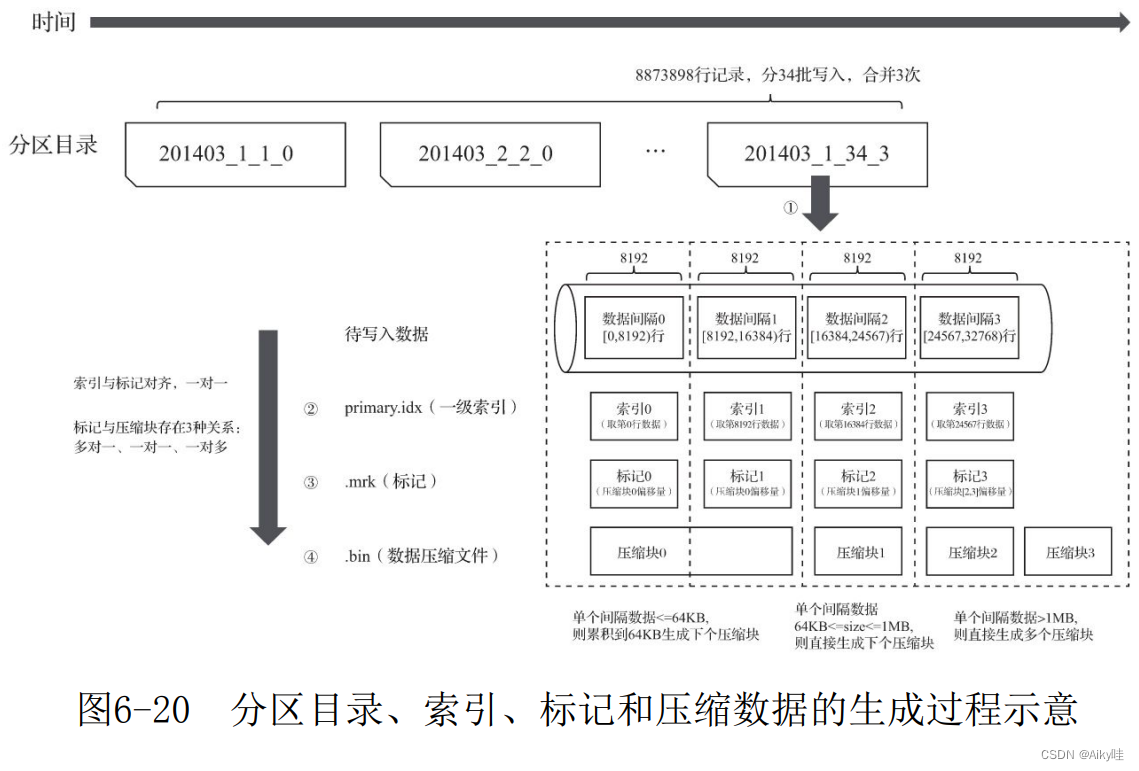
among , Index and marker intervals are aligned , The marked and compressed blocks are different according to the size of interval data , Will generate many to one 、 One to one and one to many .
6.7.2 The query process
The essence of query is to continuously reduce the scope of data .
In the best case ,MergeTree First, you can use the partition index in turn 、 Primary and secondary indexes , Reduce the data scanning range to a minimum . Then mark with the help of data , Reduce the range of data to be decompressed and calculated to a minimum .
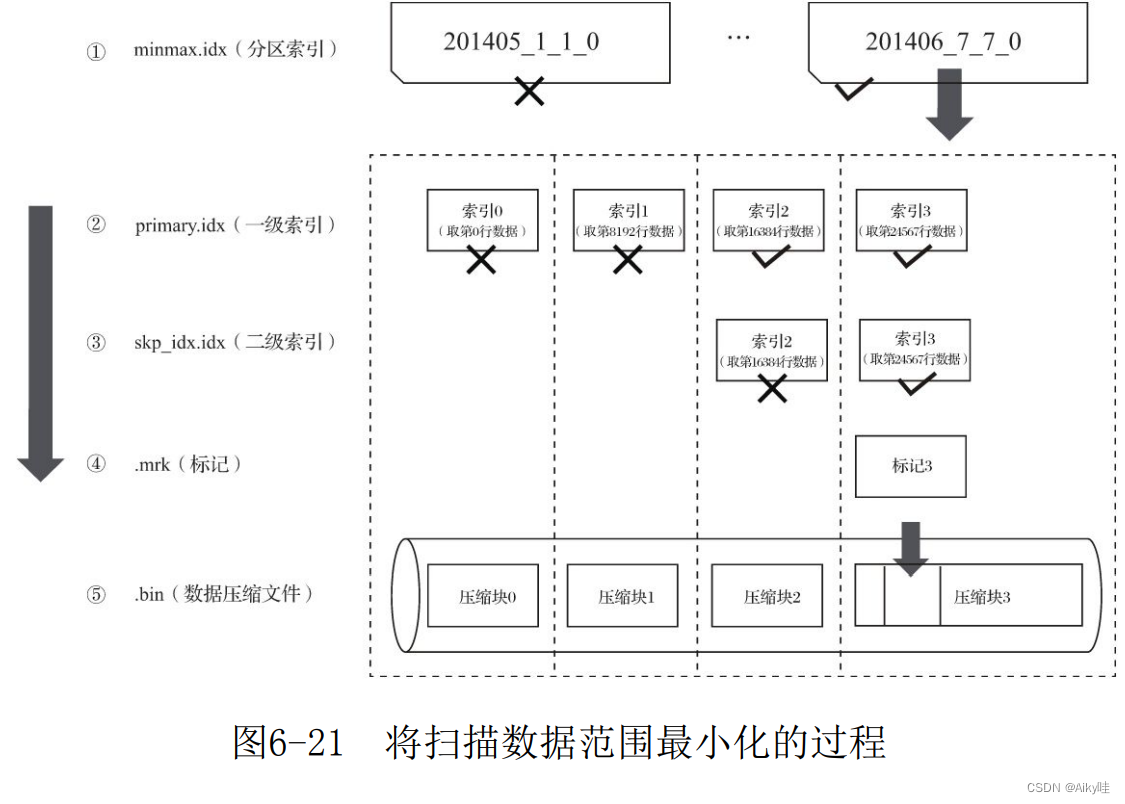
If a query statement does not specify any WHERE Conditions , Or specified WHERE Conditions , But the condition does not match any index ( Partition index 、 Primary and secondary indexes ), that MergeTree You can't reduce the data range in advance .
During subsequent data query , It will scan all partition directories , And the maximum range of index segments in the directory .
Although the data range cannot be reduced , however MergeTree Can still be marked with data , Read multiple compressed data blocks simultaneously in the form of multithreading , To improve performance .
6.7.3 The correspondence between the data mark and the compressed data block
【min_compress_block_size( Default 65536) And max_compress_block_size( Default 1048576) Specify the upper and lower limits of the compressed fast size 】
1. For one more
Multiple data tags correspond to a compressed data block , When an interval (index_granularity) Uncompressed size of data in size Less than 64KB when , This correspondence will appear .
2. one-on-one
A data tag corresponds to a compressed data block , When an interval (index_granularity) Uncompressed size of data in size Greater than or equal to 64KB And less than or equal to 1MB when , This correspondence will appear .
3. One to many
One data tag corresponds to multiple compressed data blocks , When an interval (index_granularity) Uncompressed size of data in size Directly greater than 1MB when , This correspondence will appear .
6.8 Summary of this chapter
Explained MergeTree Basic properties and physical storage structure .
Introduces data partitioning 、 First level index 、 Secondary indexes 、 Important features of data storage and data marking .
Sum up MergeTree The above features work together The working process of .
The next chapter will further introduce MergeTree Specific usage methods of other common table engines in the family .
【 The next chapter mainly starts to look at the most commonly used in the work environment ReplicatedMergeTree 了 】
边栏推荐
- How to choose the middle-aged crisis of the testing post? Stick to it or find another way out? See below
- Average two numbers
- Sort list tool class, which can sort strings
- JS扁平化数形结构的数组
- JSON Web Token----JWT和传统session登录认证对比
- 注释与注解
- js如何将秒转换成时分秒显示
- How to realize multi account login of video platform members
- Leetcode question brushing record | 206_ Reverse linked list
- px em rem的区别
猜你喜欢
buuctf-pwn write-ups (8)
【微服务】Nacos集群搭建以及加载文件配置
webrtc 快速搭建 视频通话 视频会议
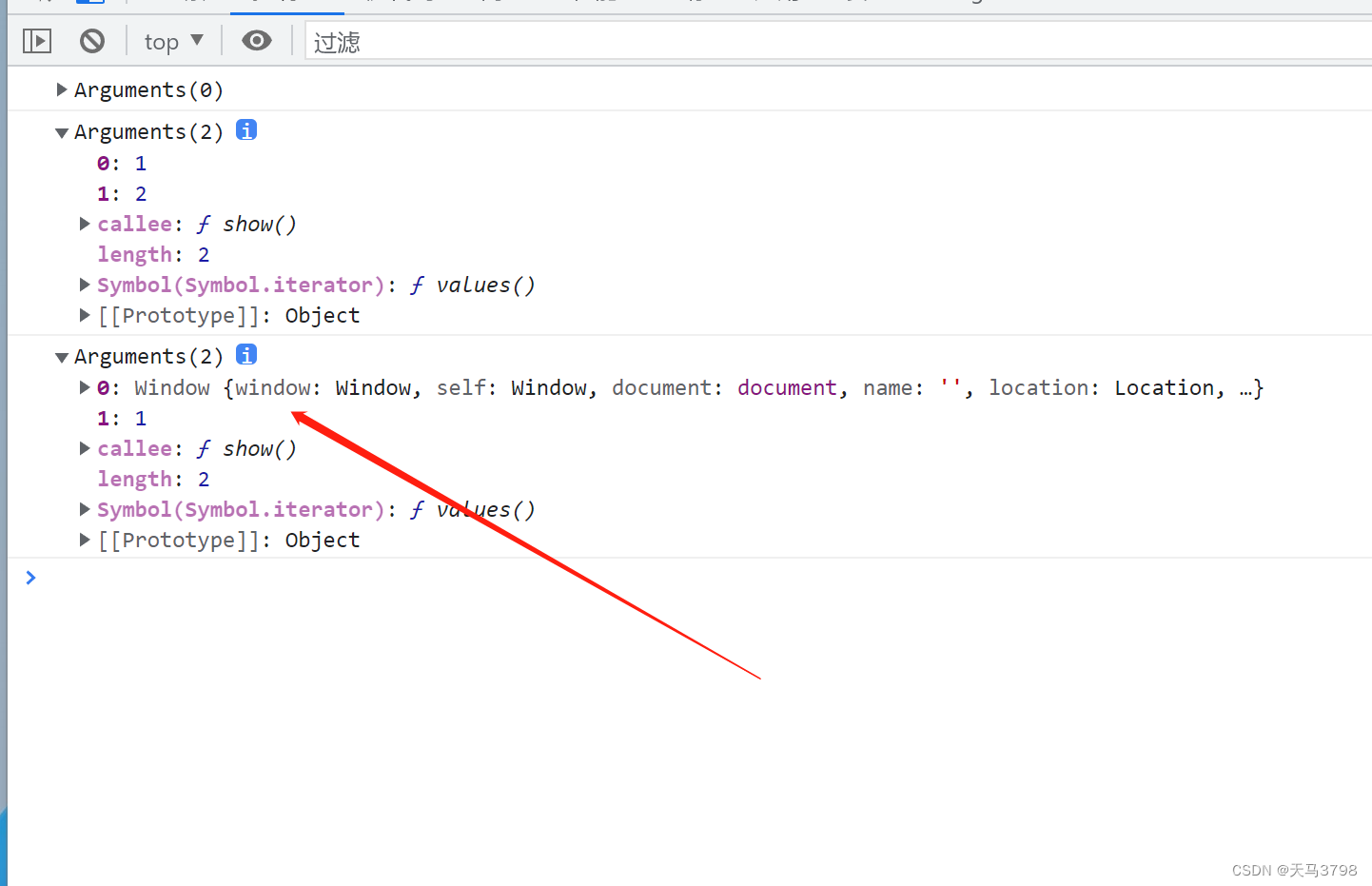
JS arguments parameter usage and explanation
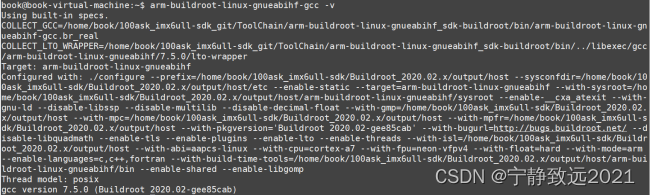
Configure cross compilation tool chain and environment variables
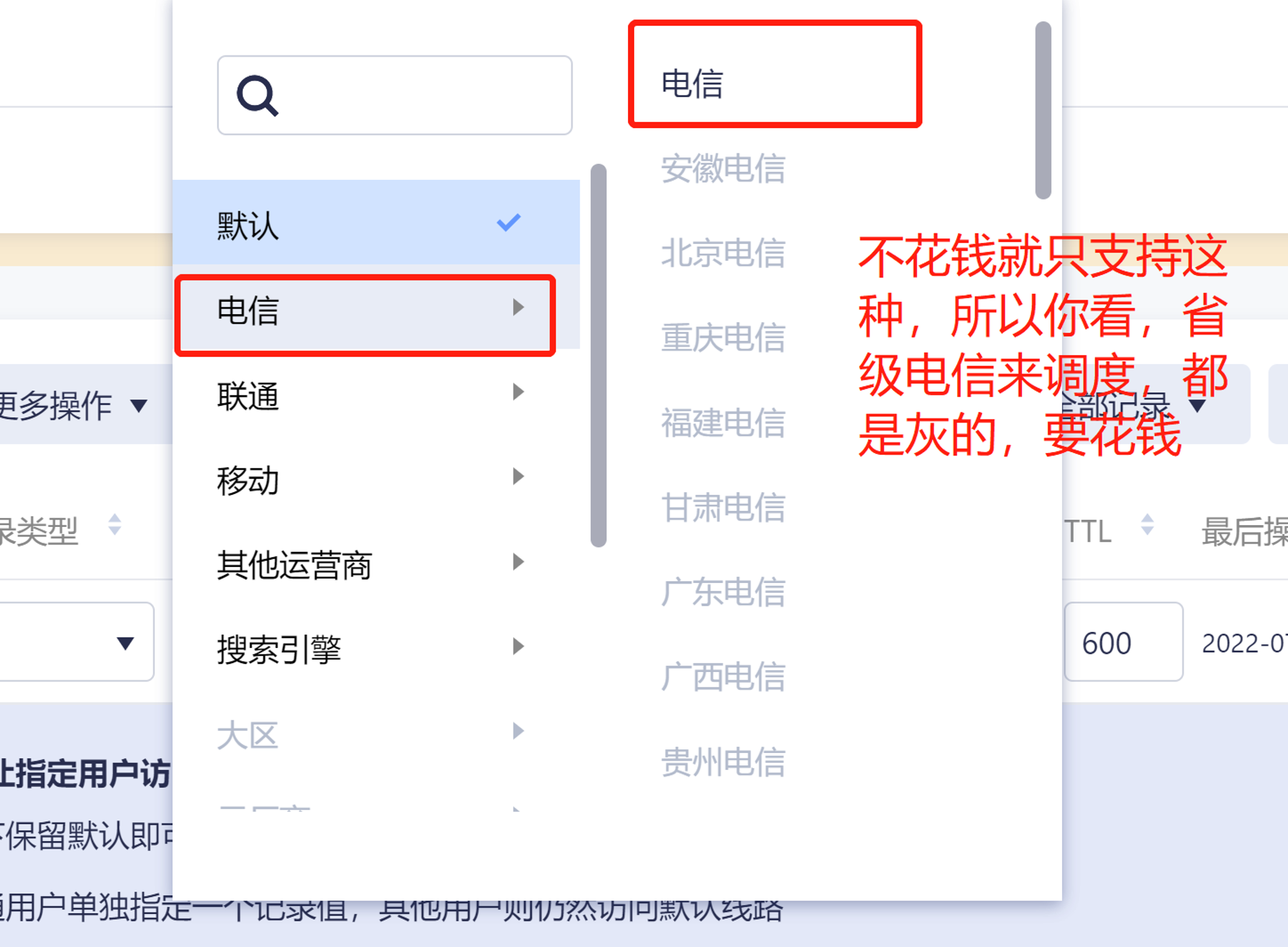
A little understanding of GSLB (global server load balance) technology
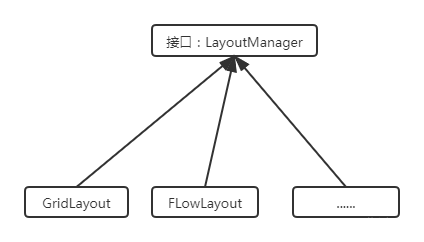
AWT introduction

198. House raiding

APScheduler如何设置任务不并发(即第一个任务执行完再执行下一个)?

Accidentally deleted the data file of Clickhouse, can it be restored?
随机推荐
509. Fibonacci number, all paths of climbing stairs, minimum cost of climbing stairs
卸载Google Drive 硬盘-必须退出程序才能卸载
【微服务】Nacos集群搭建以及加载文件配置
js如何将秒转换成时分秒显示
How to solve the component conflicts caused by scrollbars in GridView
Kubernets first meeting
Arc135 a (time complexity analysis)
Learning multi-level structural information for small organ segmentation
C language exercises (recursion)
2022.7.3-----leetcode. five hundred and fifty-six
After the festival, a large number of people change careers. Is it still time to be 30? Listen to the experience of the past people
198. House raiding
JS扁平化数形结构的数组
Steady! Huawei micro certification Huawei cloud computing service practice is stable!
每周小结(*63):关于正能量
740. Delete and get points
The end of the Internet is rural revitalization
Experience weekly report no. 102 (July 4, 2022)
微信小程序使用rich-text中图片宽度超出问题
How to implement cross domain requests