当前位置:网站首页>Adaptive spatiotemporal fusion of multi-target networks for compressed video perception enhancement
Adaptive spatiotemporal fusion of multi-target networks for compressed video perception enhancement
2022-07-04 07:01:00 【mytzs123】
Adaptive Spatial-Temporal Fusion of Multi-Objective Networks for Compressed
Video Perceptual Enhancement
Abstract
Because there is still no appropriate perceptual similarity loss function between two video pairs , Therefore, the perceptual quality enhancement of severely compressed video is a difficult problem . Because it is difficult to design a unified training goal , These targets are perceptually friendly to enhance areas with smooth content and areas with rich textures at the same time , In this paper , We propose a simple and effective new solution , be called “ Adaptive spatiotemporal fusion of two-stage multi-objective Networks ”(ASTF), Enhancement results for adaptive fusion of networks trained with two different optimization objectives . say concretely , The ASTF Take the enhanced frame and its adjacent frames as input , Common prediction mask , To indicate areas with high-frequency text details . then , We use a mask to fuse the two enhancement results , You can preserve smooth content and rich textures . A lot of experiments show that , This method has good performance in enhancing the perceptual quality of compressed video .
1. Introduction
In recent years , We have witnessed the explosive growth of video data on the Internet . In order to transmit video with limited bandwidth , Video compression is crucial to significantly reduce the bit rate . However , Existing compression algorithms usually introduce artifacts , This will seriously reduce the quality of the experience (QoE)[33、9、5、1、20]. therefore , The research on quality enhancement of compressed video is very important .
lately , The research on compressed video quality enhancement is very limited [33、9、5、25]. Multi frame quality enhancement (MFQE 1.0)[33] First, vector quantization using time information ,MFQE 2.0[9] To further improve performance , Time fusion scheme is also adopted , This scheme uses dense optical flow for motion compensation . Space-time deformable fusion (STDF)[5] Gather time information , At the same time, avoid explicit optical flow estimation . However , All these methods use pixel level metrics , Such as MSE、PSNR and SSIM, To calculate the similarity between the two images , This cannot explain many subtle differences in human perception .MW-GAN[25] A generation countermeasure network based on multi-level wavelet packet transform is proposed (GAN), Used to recover high-frequency details , To improve the perceptual quality of compressed video .
Although human beings can quickly evaluate the perceptual similarity between two images almost effortlessly , But its basic process is considered to be quite complex .lpips[35] It is proposed to evaluate the perceptual similarity between two images . However , There is still no application to VQE Indicators of . Single image perceptual quality enhancement with a single image in space ( Focus on internal attributes ) comparison , Video perceptual quality enhancement poses additional challenges , Because it involves time blinking , Although image perception quality is considered separately , Each enhanced frame in the video sequence seems to have been well enhanced . say concretely , Use peak signal-to-noise ratio and SSIM Trained VQE Smooth video will be generated , While using LPIP The training generates time flashing video with more text details .
In order to solve the above problems , We use a multi-target network with adaptive spatio-temporal fusion module to enhance both smooth areas and texture rich areas . say concretely , We use a two-stage strategy to enhance . The first stage aims to obtain relatively good intermediate results with high fidelity . In the second phase , We have trained two basic CVSR[3] Model , For different refinement purposes . One for text details , The other is for time smoothing areas . To eliminate time flicker and preserve text details , We design a new adaptive spatiotemporal fusion scheme . say concretely , A spatiotemporal mask generation module is proposed to generate spatiotemporal masks , And used to fuse two network outputs . Then we use image sharpening to further enhance the video .
The main contributions are as follows :
(1) We observed that , Due to compression loss , Areas with smooth content and rich textures are degraded differently , In order to better enhance these areas , We have designed different optimization objectives , Adopt a two branch architecture .
(2) An adaptive spatiotemporal fusion module is proposed , To combine the advantages of the two network branches , At the same time, achieve space-time consistency to avoid flickering
(3) BasicVSR be used as VQE The trunk , For proof of concept , The experimental results verify the effectiveness of our solution
2. Related Work
2.1. Quality Enhancement
In the last few years , A lot of work has been put forward to improve the objective quality of compressed images [19、8、14、16、7、10、28、18、34]. say concretely , Non depth learning method uses shape adaptation DCT Or sparse coding to reduce blocking effect 、 Ringing effect and JPEG The artifact [8、14、16]. Deep learning method , Such as D3[28] And depth dual domain convolution network (DDCN)[10] utilize JPEG Compressed prior knowledge to improve JPEG Quality of compressed image .
For compressed video , Most methods use single frame quality enhancement methods to deal with video enhancement [4、26、32]. Excited by multi frame super-resolution ,MFQE[33] He is the first person to use adjacent frames for compressed video enhancement . And then put forward MFQE 2.0[9], It is MFQE Extended version of . These two kinds of MFQE Methods all adopt the time fusion scheme , This scheme combines dense optical flow for motion compensation . Compression artifacts may seriously distort the video content and destroy the correspondence of pixel directions between frames , Therefore, the estimated optical flow is often inaccurate and unreliable , This leads to ineffective quality enhancement . Space-time deformable fusion (STDF)[5] Gather time information , At the same time, avoid explicit optical flow estimation . All of the above methods try to minimize pixel loss , Such as MSE、PSNR and SSIM, In order to obtain high objective quality that is inconsistent with human judgment . lately ,MW-GAN[25] A generation countermeasure network based on multi-level wavelet packet transform is proposed to recover high-frequency details , To improve the perceptual quality of compressed video .
2.2. Video Super Resolution
Our closest work is video super-resolution (VSR).VSR and VQR The significant difference between them is VSR The final upper sampling layer is required . several VSR Method [2、23、29] Use optical flow to estimate the motion between frames , And use space warps to align . Other methods use more complex implicit alignment methods [24、27、15、12、13、3]. say concretely ,TDAN[24] and EDVR[27] Deformable convolution is used to align different frames .BasicVSR[3] Propose to untie VSR Some of the most basic components of , Such as communication 、 alignment 、 Aggregation and upsampling , It is found that the combination of two-way propagation and simple optical flow based feature alignment is superior to many of the most advanced methods . In this work , We use BasicVSR As our basic model , We will delete the final upper sampling layer .
3. Proposed Method
Given a highly compressed video , The goal of our method is to produce high-quality results , It has the best perceptual quality compared with the real situation of the reference ground . say concretely , We use a two-stage strategy to enhance . Pictured 1 Shown , The first stage aims to achieve relatively good high fidelity intermediate results . At this stage , Use Charbonnier Loss [17] Basic training CVSR[3] Model . In the second phase , We have trained two basic CVSR Model , For different refinement purposes . Use the compromise loss function Charbonnier Loss +lpips Lose to train an improved BasicVSR Model ( We call it EnhanceNet2). the other one refine BasicVSR Model ( be called EnhanceNet1) Use only lpips I'm going to train . ad locum ,lpips loss [35] It is an objective video quality measurement for learning , More in line with human perception . such ,EnhanceNet1 Better at restoring texture to meet human perception needs , But it can cause the time flicker of the video smoothing area , meanwhile EnhanceNet2 Will produce smoother results , Especially the time flicker is well eliminated . To overcome this problem , We design a new adaptive spatiotemporal fusion scheme . say concretely , A spatiotemporal mask generation module is proposed to generate spatiotemporal masks , And used to fuse two network outputs . then , We use image sharpening to further enhance the Gaussian kernel size 3 In the video .
3.1. EnhanceNet
For the stage 1 Coarse reinforcing mesh in , We use Charbonnier Loss [17] Generate high fidelity rough results, such as PSNR and SSIM. However , According to previous research [35], Traditional indicators (L2/PSNR,SSIM) Inconsistent with human judgment .Charbonnier Loss is l1 Differentiable variants of norms :
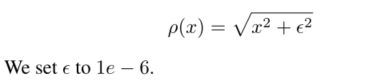
According to our observations , It is difficult to design a unified training goal , These targets are perceptually friendly to areas that enhance both content smoothing and texture rich areas . therefore , The trade-off between objective quality and perceived quality is important to solve this problem , This is similar to the perceptual distortion tradeoff [6]
In the second phase , We trained two basic CVSR Model , Pay attention to the trade-off between perceived quality, objective quality and perceived quality . say concretely , We only use lpips Loss [35] To train Refine EnhanceNet1, To produce results focused on restoring texture details , This is consistent with human perception and judgment . But it may also lead to the disadvantage of time flicker in the video smoothing area . To overcome this problem , We fine tune EnhanceNet2 Use trade-off loss Function training .
![]()
The key to producing results is to restore smooth results , This is a trade-off between objective quality and perceived quality . Be careful , We set up α=0.15 and β=10000, send Charbonnier Loss is almost lpips Three times the loss . We are lpips Used in loss VGG Network training , stay lpips Used in loss Alex Network verification
3.2. ASTF
We design a new adaptive spatiotemporal fusion scheme (ASTF), The motive is Refine EnhanceNet1 Good at restoring texture details ,Refine EnhanceNet2 Good at restoring smooth areas , These are the two trade-off models we all need . say concretely , The spatiotemporal mask generation module is used to generate spatiotemporal masks , To represent the non smooth area of the video , And will Refine EnhanceNet2 The result as input . We used 3×3×3 Space time block of pixels .
It is used for fusion Refine EnhanceNet1 and Refine EnhanceNet2 Output :


Intuitively speaking , When the area is smooth , Its local variance is small , otherwise , Its local variance is large . therefore , Smooth areas will be more dependent on EnhanceNet2 Output , The rich texture area will be from EnhanceNet1 Get more details about recovery . Use time sliding window , It can also eliminate the time flicker effect .
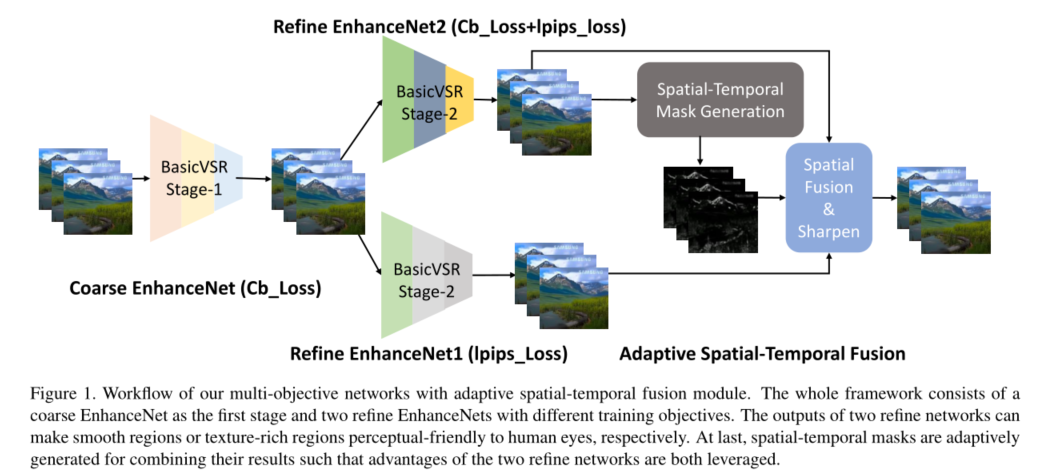
Workflow of multi-target network with adaptive spatio-temporal fusion module . The whole framework includes a coarse reinforcement network as the first stage and two refined reinforcement networks with different training objectives . The output of the two thinning networks makes the smooth region and the texture rich region perceptually friendly to the human eye . Last , Spatiotemporal masks are generated adaptively to combine their results , So as to make full use of the advantages of the two optimized networks
4. Experiments
4.1. Datasets
We use high compressed video quality to enhance the challenge ( The trajectory 2 Fix QP, perception )[30] The training video and test video of . The total training data is 200 For compressed and uncompressed video . The test data are 10 A compressed video . say concretely , We divide training videos into training data (190 A video ) And validation data (10 A video ,“001”、“021”、“041”、“061”、“081”、“101”、“121”、“141”、“161”、“181). Be careful , We use the official code to convert the original 、 Compress ( And enhanced ) Video to RGB Domain
4.2. Implementation Details
We use the one without pixel shuffle layer BasicVSR As our basic model . For these two stages of training , We randomly crop from the original video and the corresponding compressed video 64×64 Clips as training samples . Further use data to enhance ( That is, rotate or flip ) To make better use of these training samples . The learning rate is initially set to 2e−4 And in the whole training process , The learning scheme is set to CosineAnnealingLR_Restart.β1=0.9、β2=0.99 and  =1e-10 Of Adam Optimizer . In the 1 In phase , We train from the beginning EnhanceNet, And with it Charbonnier Loss [17]. In the second phase , We use the result of the first stage as the input of the second stage . We use them separately lpips Loss [35] And trade-off loss function training EnhanceNet1 and EnhanceNet2. We use PSNR、SSIM、lpips[35] and FID[11,21] To evaluate us 10 Verify the quality enhancement performance of video .
=1e-10 Of Adam Optimizer . In the 1 In phase , We train from the beginning EnhanceNet, And with it Charbonnier Loss [17]. In the second phase , We use the result of the first stage as the input of the second stage . We use them separately lpips Loss [35] And trade-off loss function training EnhanceNet1 and EnhanceNet2. We use PSNR、SSIM、lpips[35] and FID[11,21] To evaluate us 10 Verify the quality enhancement performance of video .
4.3. Quantitative Results
In the table 1 in , We provide PSNR and SSIM. It can be seen that , The results of the first stage have the highest PSNR and SSIM value .EnhanceNet2(cb+lpips) The results of ∆PSNR And EnhanceNet( The first 1 Stage ) Comparison of results , by -0.08 dB.EnhanceNet1(lpips) The results of ∆PSNR And EnhanceNet( The first 1 Stage ) Comparison of results , by -1.15 dB. After our space-time fusion module , Space time fusion (fuse) The results of  PSNR And EnhanceNet( The first 1 Stage ) Comparison of results , by -0.14 dB. Adaptive spatiotemporal fusion (fuse) The result is just EnhanceNet1 and EnhanceNet2 Of trade-off. We also provide the results of image sharpening PSNR and SSIM, This is the lowest value . Although it is the lowest peak signal-to-noise ratio in all our stages , But it has better human perception , We will discuss later .
PSNR And EnhanceNet( The first 1 Stage ) Comparison of results , by -0.14 dB. Adaptive spatiotemporal fusion (fuse) The result is just EnhanceNet1 and EnhanceNet2 Of trade-off. We also provide the results of image sharpening PSNR and SSIM, This is the lowest value . Although it is the lowest peak signal-to-noise ratio in all our stages , But it has better human perception , We will discuss later .
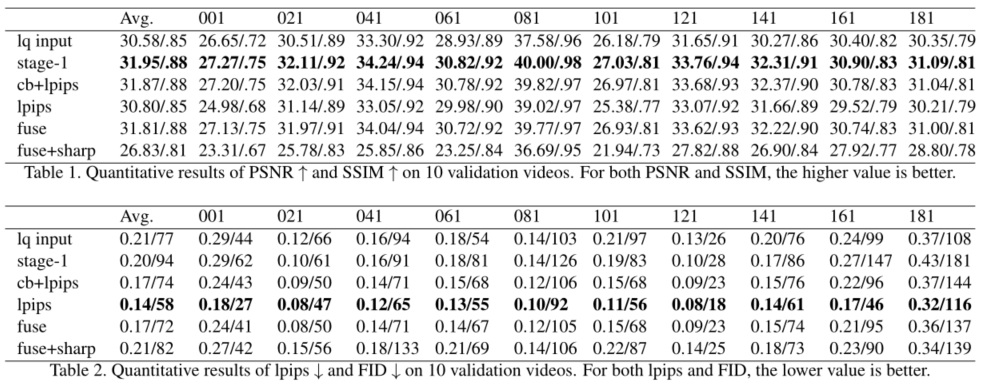
In the table 2 in , We provide LPIP[35] and FID[11,21]. It can be seen that ,EnhanceNet1(lpips) The value of the result is the lowest , The best result is obtained by using image perception measurement . However , Enhance the network 1(EnhanceNet1,lpips) As a result, there is a problem of time flicker , This is very important for human perception and judgment of video . We use EnhanceNet2(cb+lpips) To reduce time blinking , And generate lpips and FID Greater than EnhanceNet1(lpips) The result of the result . In order to use space-time information , We use our proposed ASTF The fusion EnhanceNet1(lpips) Results and EnhanceNet2(cb+lpips) result , It can generate a result enhancer subnetwork with a value of 1 And enhancer subnetworks 2(cb+lpips) Between values lpips and FID. We also provide the image sharpened LPIP and FID result . And PSNR and SSIM similar , The result after image sharpening is not better than that before image sharpening , But whether it has better human perception , We will discuss later . In the testing phase of the challenge , The method we proposed ( The team VUE) To obtain the 60 branch , Ranked fifth . according to 15 Average opinion score of subjects (MOS) Value to sort the scores . Scores range from s=0( Worst quality ) To s=100( Best quality ). Ground live video in s=100 Provide the standard to the subjects , But the subjects were asked to rate the video according to the visual quality rather than the similarity with the ground reality . See the report document for more details [31].
4.4. Qualitative Results
chart 2 Provides qualitative results of the validation and testing framework . The first column is compressed frames . The second column is our enhanced frame . The first two lines are verification frames . The last two lines are test frames . It can be seen that , Compressed frame distortion 、 Fuzzy , Lack of text details . And our enhanced frame can reduce these artifacts , And have more text details .
Besides , chart 3 The results of each step of the verification frame are provided , Including compressed low-quality input frames 、 Stage 1 Of EnhanceNet result 、 Use lpips Loss of training EnhanceNet1 result 、 Trained using the trade-off loss function EnhanceNet2 result 、 The result of space-time fusion 、 Sharpening result of fusion 、 Space time mask and ground truth . It can be seen that , The first 1 The enhancement network of stage can reduce most of the distortion , But there is still the problem of over ambiguity .EnhanceNet1(lpips) The result has more text details , But it will cause some artifacts . And EnhanceNet and EnhanceNet1 comparison ,EnhanceNet2(cb+lpips) The result is the trade-off between smoothing and text detail . Use EnhanceNet2(cb+LPIP) The resulting spatio-temporal mask represents high-frequency regions with high pixel values . Space time fusion (fuse) The result also has an enhancer network 1(lpips) And enhancer subnetworks 2(cb+lpips) The advantages of , Smooth in low frequency areas , There are more text details in the high-frequency area . result ( The fusion + sharpening ) Process through image sharpening , To further enhance human perception . Please note that , result (fuse) It seems better than the result (fuse+ sharpening ) More similar to groundtruth. However , Regardless of the actual results on the ground ( The fusion + sharpening ) It has better human perception effect . therefore , We choose the result ( The fusion + sharpening ) As the final submission result , Submit to NTIRE 2021 High compressed video quality enhanced challenge track-2.
4.5. Analysis and Discussions
Compared with quantitative and qualitative results ,PSNR and SSIM The result with the highest value is not the best human perception result . We also conducted User Research , To evaluate time performance . For verifying and testing videos , Our results (fuse) And result (fuse+ sharpening ) Compared with EnhanceNet1(lpips) The result has better performance .Charbonnier Loss [17] Helps generate smooth areas ,lpips Loss [35] Help generate text details . We can see , Use only one loss function (Charbonnier Loss or lpips Loss ) No training model can achieve good enhanced video judged by human perception . It is necessary to consider both the flickering of time and the lack of text details . We propose adaptive spatiotemporal fusion (ASTF) Take advantage of the enhanced network 1(lpips) And enhance the network 2(cb+lpips) The advantages of , It has better human perception video enhancement performance .
5. Conclusion
We are NTIRE 2021 Our track is introduced in the re compressed video quality enhancement challenge 2 Fix QP Perception method . To meet this challenge , We propose an adaptive Fourier transform (ASTF) Enhancement results from adaptive fusion using a network trained with two different optimization objectives . Train with different loss functions BasicVSR Enhancement model , Restore smooth details and text details respectively . The fusion operation can combine the advantages of the two networks . Our method is a general method , Can be used for any other video enhancement backbone . Experiments show that , Our spatiotemporal fusion module can preserve both smooth and high-frequency details , So as to obtain better human perception effect .
边栏推荐
- Mysql 45讲学习笔记(十一)字符串字段怎么加索引
- 2022年,或许是未来10年经济最好的一年,2022年你毕业了吗?毕业后是怎么计划的?
- 【FPGA教程案例8】基于verilog的分频器设计与实现
- Can the out of sequence message complete TCP three handshakes
- MySQL 45 lecture learning notes (x) force index
- Explain in one sentence what social proof is
- tars源码分析之3
- Selection (022) - what is the output of the following code?
- Redis interview question set
- leetcode825. Age appropriate friends
猜你喜欢
List of top ten professional skills required for data science work

Shopping malls, storerooms, flat display, user-defined maps can also be played like this!
响应式移动Web测试题
Google Chrome Portable Google Chrome browser portable version official website download method

Splicing plain text into JSON strings - easy language method
Campus network problems

The crackdown on Huawei prompted made in China to join forces to fight back, and another enterprise announced to invest 100 billion in R & D
Introduction to deep learning Ann neural network parameter optimization problem (SGD, momentum, adagrad, rmsprop, Adam)
Selenium driver ie common problem solving message: currently focused window has been closed
Deep understanding of redis -- a new type of bitmap / hyperloglgo / Geo
随机推荐
Can the out of sequence message complete TCP three handshakes
期末周,我裂开
About how idea sets up shortcut key sets
Fundamentals of SQL database operation
MySQL 45 lecture learning notes (VII) line lock
MySQL 45 lecture learning notes (VI) global lock
Cervical vertebra, beriberi
2022, peut - être la meilleure année économique de la prochaine décennie, avez - vous obtenu votre diplôme en 2022? Comment est - ce prévu après la remise des diplômes?
Mysql 45讲学习笔记(十)force index
the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
The difference between synchronized and lock
tars源码分析之3
2022年,或許是未來10年經濟最好的一年,2022年你畢業了嗎?畢業後是怎麼計劃的?
tars源码分析之1
用于压缩视频感知增强的多目标网络自适应时空融合
由于dms升级为了新版,我之前的sql在老版本的dms中,这种情况下,如何找回我之前的sql呢?
Analysis of tars source code 1
Mysql 45讲学习笔记(十三)表数据删掉一半,表文件大小不变
the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
[network data transmission] FPGA based development of 100M / Gigabit UDP packet sending and receiving system, PC to FPGA