当前位置:网站首页>Why do we use UTF-8 encoding?
Why do we use UTF-8 encoding?
2022-07-07 14:54:00 【nsnsttn】
Why do we use it UTF-8 code ?
Computers can only recognize binary numbers , So the letters we use and see , Numbers , Chinese characters , Symbol ,emoji etc. All need to be converted into binary numbers in some way for storage , We need to convert it into corresponding letters when we use it , Numbers , Chinese characters , Symbol ,emoji etc.
ASCII code There is
Support :
0-9
a-z
A-Z
!"#$%^&*()
etc. 128 Characters
Each character has a corresponding code point , yes 0~127 Number between , A collection of all supported characters and their corresponding code points , Called character set , therefore ASCII The character set appears :
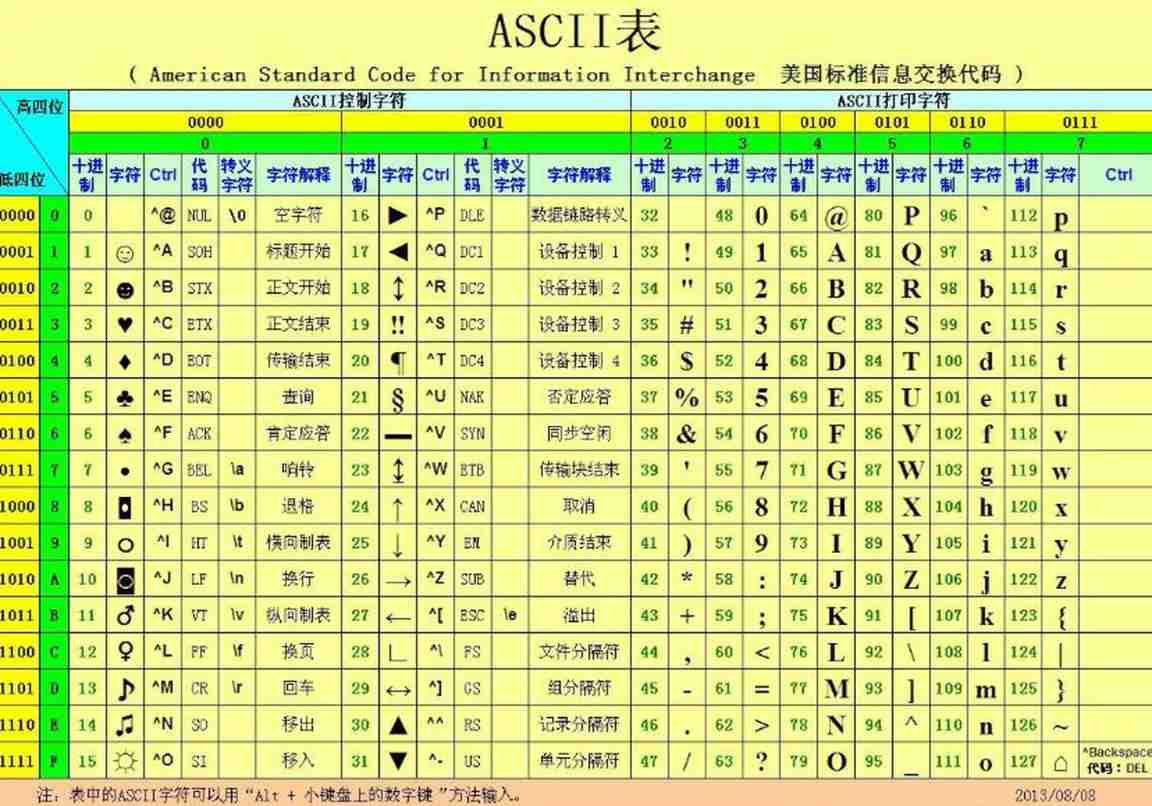
from character A To Binary system 01000001 The process is called coding
conversely
from Binary system 01000001 To character A The process is called decoding
however ASCII Only commonly used symbols and English letters are supported , Words and new symbols in other countries do not support , So other countries began to develop their own coding standards , For example, the mainland has GB2312, Hong Kong, Macao and Taiwan Big5, Later, the simplified Japanese and Korean characters were unified GBK, This leads to the same article , Writing and viewing are encoded differently , Causing confusion , To solve this problem , Unify all characters ,
Unicode Character set There is , At present, it has included more than 14w The characters of , It should be noted that , Character set is just a set of characters and their corresponding code points , It does not mean that characters will be stored in the computer with corresponding code points , Character coding really defines the mapping from characters to computer stored content
![[(img-BVphQVRp-1640626776070)(C:\Users\mi\AppData\Roaming\Typora\typora-user-images\image-20211228005726732.png)]](/img/2e/df8cbcfef455a369f8f394968fd6e9.jpg)
Of course , The simplest encoding method is to store the code point corresponding to the character directly in binary in the computer ,ASCII and UTF-32 That's what it does
ASCII Only 128 individual , Take up one byte , It is very convenient to use code point coding directly , however Unicode Character set Hundreds of thousands of characters are stored
For example, this character , stay Unicode in

Decimal system :
128169
Binary system :
11111010010101001
Binary has 17 The bit , And you can't let binary numbers directly follow the binary numbers of other characters , Because it is impossible to distinguish where each character starts , Where to end
therefore UTF-32 Let each character begin with 32 The bit , Four byte length to store , Fill zero for insufficient high position

32byte Enough to contain unicode Character set All the characters in , Fixed length , It can also help the computer recognize the truncation range of each character (4 byte ), But this causes English users , They used to use Ascii Character set , Each character is stored in only one byte , But now use UTF-32, Each character must use 4 Byte store , The file size directly expanded to 4 times
Chinese character users ,GBK One Chinese character only accounts for 2 Bytes , Now, too 4 Bytes , The file size has expanded to 2 times , This is obviously unacceptable , To save space efficiency
UTF-8 code The birth of ,UTF-8 Is aimed at Unicode Variable length coding of , For different characters , It can be used 1~4 Bytes of storage
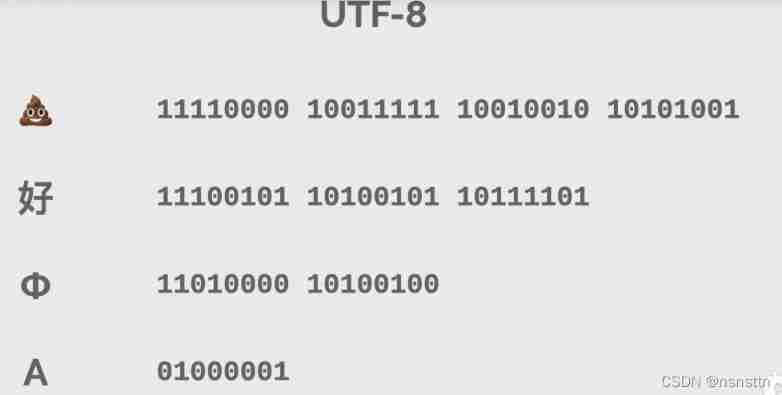
The specific rules are :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-LLfAqDFj-1640626663955)(C:\Users\mi\AppData\Roaming\Typora\typora-user-images\image-20211228011742196.png)]](/img/e7/5c84bd40054832b6ac7102ac159a70.jpg)
Simply put, see
0 start , Just look back for a byte
110 start , Just look back for two bytes
1110 start , Just look back for three bytes
11110 start , Just look back for four bytes
The following bytes are 10 start
Range calculation :
2 Of (8-1) Time - 1 = 127
2 Of (16-5) Time - 1= 2047
2 Of (24-8) Time - 1= 65535
2 Of (32-11) Time - 1= 1114111
advantage :
compatible ASCII
Variable length , Save space
Good scalability , I'm not afraid of more characters in the future
shortcoming :
Chinese characters need 3 Bytes , Not as good as GBK2 Bytes
Calculate the byte length of a character , inconvenient
Welcome to add ~
边栏推荐
- leetcode:648. 单词替换【字典树板子 + 寻找若干前缀中的最短符合前缀】
- How does the database perform dynamic custom sorting?
- IDA pro逆向工具寻找socket server的IP和port
- Cvpr2022 | backdoor attack based on frequency injection in medical image analysis
- Ian Goodfellow, the inventor of Gan, officially joined deepmind as research scientist
- Webrtc audio anti weak network technology (Part 1)
- The method of parsing PHP to jump out of the loop and the difference between continue, break and exit
- AWS learning notes (III)
- 6、Electron无边框窗口和透明窗口 锁定模式 设置窗口图标
- 安恒堡垒机如何启用Radius双因素/双因子(2FA)身份认证
猜你喜欢
Niuke real problem programming - Day11

Xiaomi's path of chip self-development
asp.netNBA信息管理系统VS开发sqlserver数据库web结构c#编程计算机网页源码项目详细设计
华为云数据库DDS产品深度赋能
IDA pro逆向工具寻找socket server的IP和port
CTFshow,信息搜集:web1

CTFshow,信息搜集:web7

Cvpr2022 | backdoor attack based on frequency injection in medical image analysis

MicTR01 Tester 振弦采集模块开发套件使用说明

广州开发区让地理标志产品助力乡村振兴
随机推荐
CTFshow,信息搜集:web5
ES日志报错赏析-- allow delete
Summary on adding content of background dynamic template builder usage
What is cloud primordial? This time, I can finally understand!
6、Electron无边框窗口和透明窗口 锁定模式 设置窗口图标
Apache多个组件漏洞公开(CVE-2022-32533/CVE-2022-33980/CVE-2021-37839)
PG基础篇--逻辑结构管理(锁机制--表锁)
What is the process of ⼀ objects from loading into JVM to being cleared by GC?
Data connection mode in low code platform (Part 2)
Used by Jetson AgX Orin canfd
数据库如何进行动态自定义排序?
Cocos creator direction and angle conversion
Niuke real problem programming - day13
华为云数据库DDS产品深度赋能
PLC:自动纠正数据集噪声,来洗洗数据集吧 | ICLR 2021 Spotlight
因员工将密码设为“123456”,AMD 被盗 450Gb 数据?
Ascend 910 realizes tensorflow1.15 to realize the Minist handwritten digit recognition of lenet network
Small game design framework
Deformable convolutional dense network for enhancing compressed video quality
Data Lake (IX): Iceberg features and data types