当前位置:网站首页>Thesis reading_ Chinese NLP_ LTP
Thesis reading_ Chinese NLP_ LTP
2022-07-05 17:41:00 【xieyan0811】
English title :N-LTP: An Open-source Neural Language Technology Platform for Chinese
Chinese title : Open source Chinese neural network language technology platform N-LTP
Address of thesis :https://arxiv.org/pdf/2009.11616v4.pdf
field : natural language processing
Time of publication :2021
author :Wanxiang Che etc. , Harbin Institute of technology
Source :EMNLP
Quantity cited :18+
Code and data :https://github.com/HIT-SCIR/ltp
Reading time :22.06.20
Journal entry
It is based on Pytorch For chinese Of Offline tools , Take the trained model , Minimum model only 164M. Directly support word segmentation , Six tasks such as named entity recognition , The six tasks basically revolve around word segmentation 、 Determine the composition of the word 、 Relationship .
Actually measured : Better than expected , If used to identify a person's name , The effect is OK , Directly used in vertical fields , Results the general , Further fine tuning may be required .
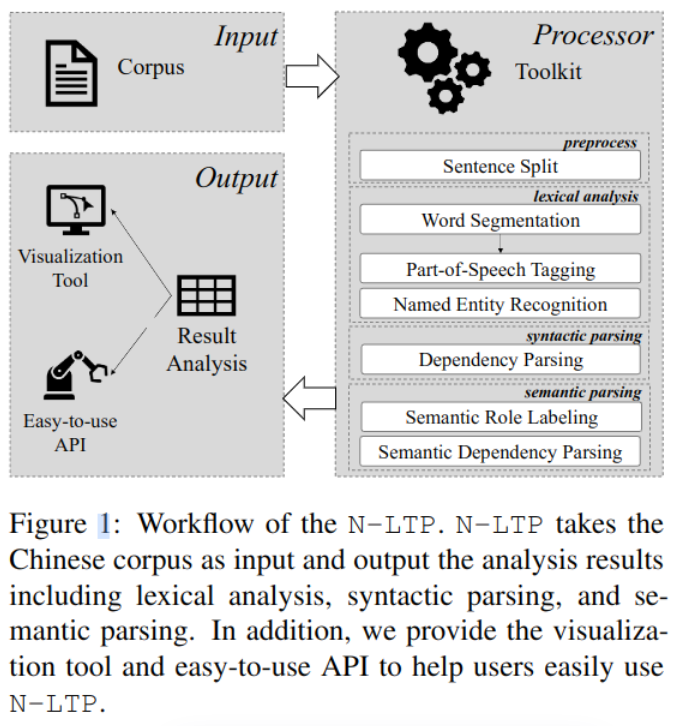
Article contribution
- Support six Chinese natural language tasks .
- be based on Multitasking framework , Sharing knowledge , Reduce memory usage , Speed up .
- High scalability : Support Introduced by users BERT Class model .
- Easy to use : Support Multilingual interface C++, Python, Java, Rust
- Achieve better results than the previous model
Design and Architecture
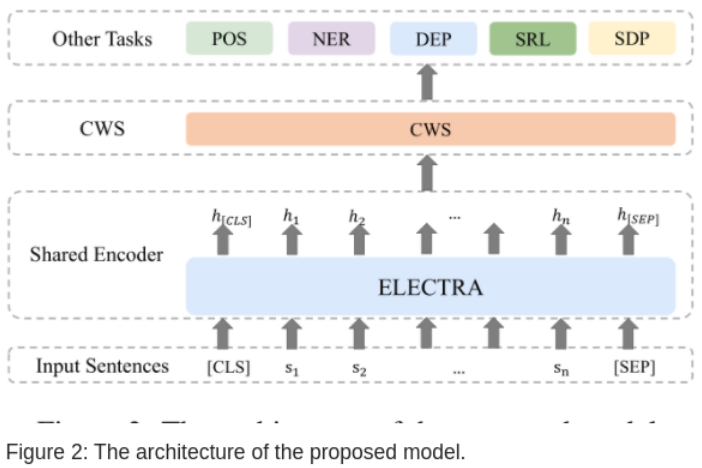
chart -2 Shows the software architecture , It consists of a coding layer shared by multiple tasks and a decoding layer implemented by each task .
Shared coding layer
Use pre trained models ELECTRA, The input sequence is s=(s1,s2,…,sn), Add symbols to make it s = ([CLS], s1, s2, . . . , sn, [SEP]), Please see BERT principle , The output is the corresponding hidden layer code
H = (h[CLS],h1, h2, . . . , hn, h[SEP]).
Chinese word segmentation CWS
After coding H Substitute linear decoder , Classify each character :
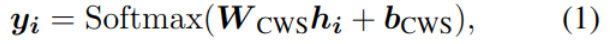
y Is the probability that each character category is each label .
Position marking POS
Location marking is also NLP An important task in , For further parsing . At present, the mainstream method is to treat it as a sequence annotation problem . It will also be encoded H As input , Label of output position :
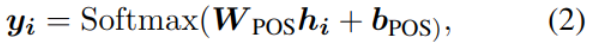
y Is the probability that the character in this position belongs to a label , among i It's location information .
Named entity recognition NER
The goal of named entity recognition is to find the starting and ending positions of entities , And the category of the entity . Use in tools Adapted-Transformer Method , Add direction and distance features :

The last step also uses a linear classifier to calculate the category of each word :
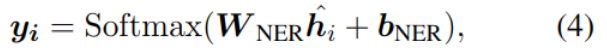
among y yes NER The probability of belonging to a tag .
Dependency resolution DEP
Dependency parsing mainly analyzes the semantic structure of sentences ( See online examples for details ), Look for the relationship between words . Double affine neural network and einser Algorithm .
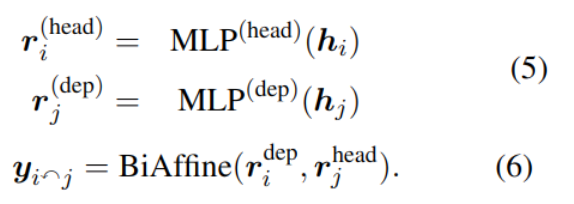
Semantic analysis SDP
Similar to dependency analysis , Semantic dependency analysis also captures the semantic structure of sentences . It parses sentences into a dependency syntax tree , Describe the dependencies between the words . That is to say, it points out the syntactic collocation relationship between words , This collocation is related to semantics . Specific include : Subject predicate relationship SBV, The verb object relationship VOB, Settle China relations ATT etc. , See :
from 0 To 1, Teach you how to use it hand in hand NLP Tools ——PyLTP
The specific method is to find semantically related word pairs , And find the predefined semantic relationship . The implementation also uses the double affine model .

When p>0.5 when , They think that words i And j There is a connection between .
Semantic Role Labeling SRL
The main goal of semantic role tagging is to recognize the predicate centered structure of sentences , The specific method is to use end-to-end SRL Model , It combines double affine neural network and conditional random field as encoder , The conditional random field formula is as follows :
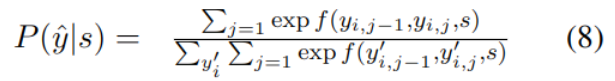
among f Used to calculate from yi,j-1 To yi,j The probability of transfer .
Distillation of knowledge
To compare individual training tasks with multi task training , Introduced BAM Method :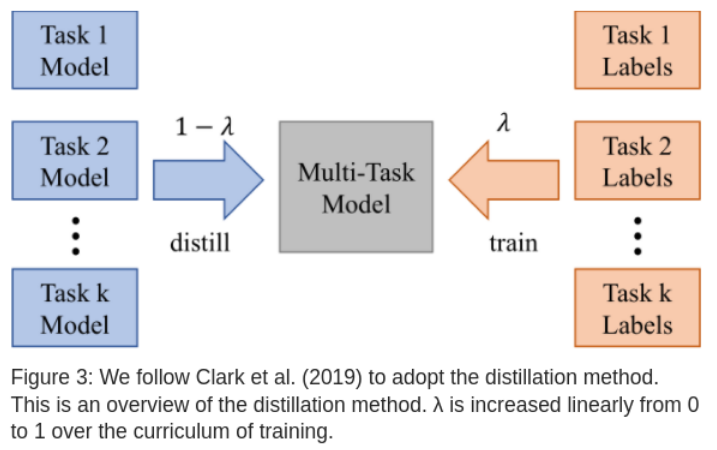
usage
install
$ pip install ltp
On-line demo
http://ltp.ai/demo.html
Sample code
from ltp import LTP
ltp = LTP()
seg, hidden = ltp.seg([" He asked Tom to get his coat ."])
pos = ltp.pos(hidden)
ner = ltp.ner(hidden)
srl = ltp.srl(hidden)
dep = ltp.dep(hidden)
sdp = ltp.sdp(hidden)
among seg Function implements word segmentation , And output the segmentation result , And the vector representation of each word .
Fine tuning model
Download the source code
$ git clone https://github.com/HIT-SCIR/ltp
In its ltp There is... In the catalog task_xx.py, Trainable and tuning model , Usage as shown in the py Internal example . Form like :
python ltp/task_segmention.py --data_dir=data/seg --num_labels=2 --max_epochs=10 --batch_size=16 --gpus=1 --precision=16 --auto_lr_find=lr
experiment
Stanza It supports a multilingual NLP Tools , The comparison of Chinese modeling effect is as follows :
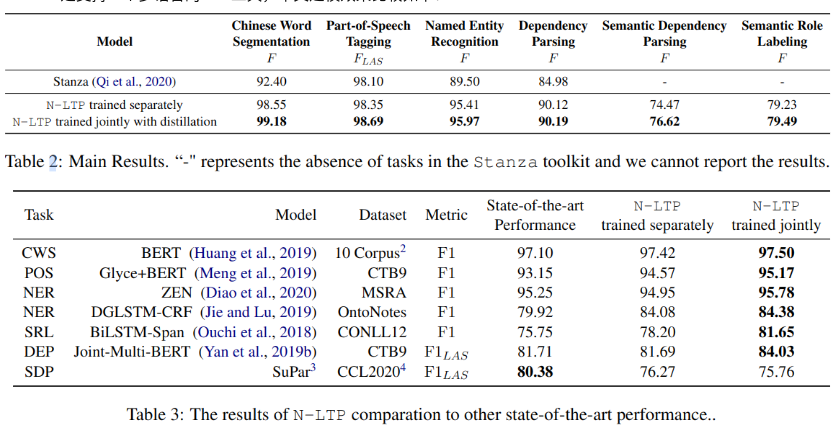
in addition , Experiments also prove that , Faster using federated models , Less memory .
Reference resources
边栏推荐
- 论文阅读_医疗NLP模型_ EMBERT
- Machine learning 02: model evaluation
- Cloud security daily 220705: the red hat PHP interpreter has found a vulnerability of executing arbitrary code, which needs to be upgraded as soon as possible
- 統計php程序運行時間及設置PHP最長運行時間
- Kafaka技术第一课
- 漏洞复现----48、Airflow dag中的命令注入(CVE-2020-11978)
- MATLAB查阅
- 使用QT设计师界面类创建2个界面,通过按键从界面1切换到界面2
- 哈趣K1和哈趣H1哪个性价比更高?谁更值得入手?
- C#实现水晶报表绑定数据并实现打印3-二维码条形码
猜你喜欢
统计php程序运行时间及设置PHP最长运行时间

网络威胁分析师应该具备的十种能力
Check the WiFi password connected to your computer
Machine learning 02: model evaluation

7 pratiques devops pour améliorer la performance des applications
統計php程序運行時間及設置PHP最長運行時間
Kafaka技术第一课
Complete solution instance of Oracle shrink table space
Design of electronic clock based on 51 single chip microcomputer

十个顶级自动化和编排工具
随机推荐
一文了解MySQL事务隔离级别
CVPR 2022最佳学生论文:单张图像估计物体在3D空间中的位姿估计
独立开发,不失为程序员的一条出路
mongodb(快速上手)(一)
Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
Disabling and enabling inspections pycharm
十个顶级自动化和编排工具
Cloud security daily 220705: the red hat PHP interpreter has found a vulnerability of executing arbitrary code, which needs to be upgraded as soon as possible
[binary tree] insufficient nodes on the root to leaf path
WR | Jufeng group of West Lake University revealed the impact of microplastics pollution on the flora and denitrification function of constructed wetlands
QT控制台打印输出
IDEA 项目启动报错 Shorten the command line via JAR manifest or via a classpath file and rerun.
How to save the trained neural network model (pytorch version)
flask接口响应中的中文乱码(unicode)处理
Knowledge points of MySQL (6)
Domain name resolution, reverse domain name resolution nbtstat
提高應用程序性能的7個DevOps實踐
Clickhouse (03) how to install and deploy Clickhouse
哈趣K1和哈趣H1哪个性价比更高?谁更值得入手?
Example tutorial of SQL deduplication