当前位置:网站首页>Sort according to a number in a string in a column of CSV file
Sort according to a number in a string in a column of CSV file
2022-07-06 08:24:00 【Don't seek great wealth, just seek wealth to rival the country】
**
The file is shown below :
**
Sort according to the size of the fourth number in the first column ( Please note that “ Chinese characters ” The sequence needs to correspond to the previous video sequence )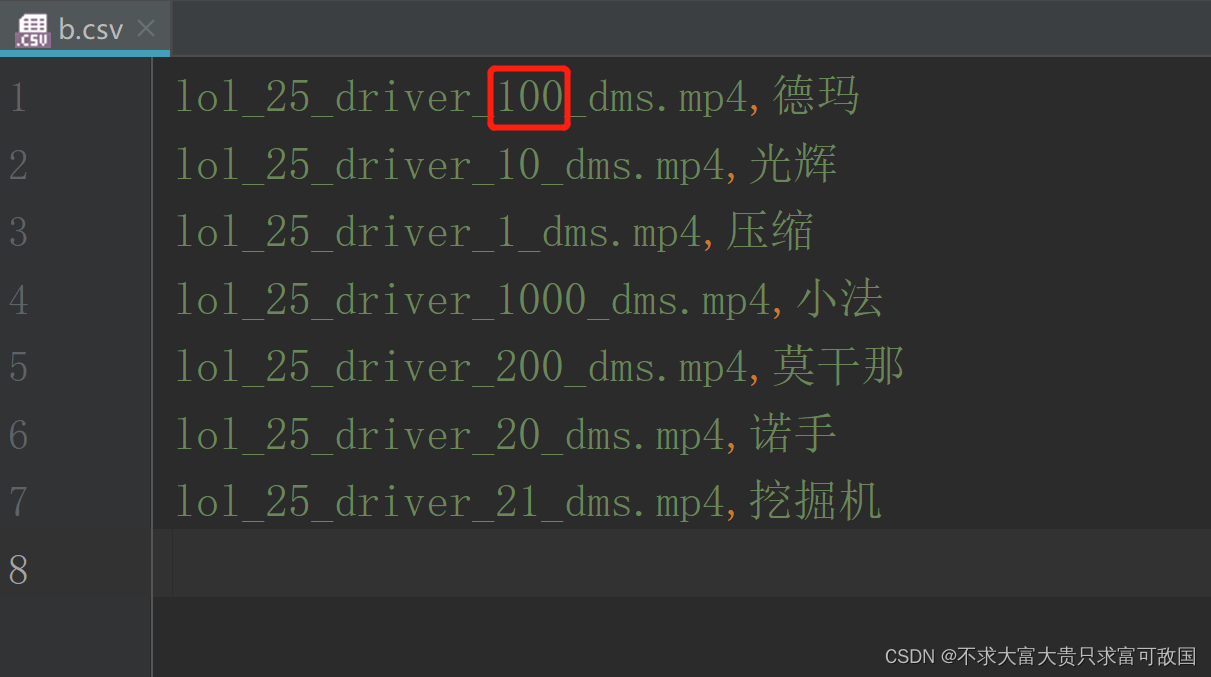
**
Solutions :
**
1、 Extract the data
2、 Put the first column split Make a list
3、zip Combine : The split list and the second column , because key Is hashable and cannot be a list , and value It can be modified , So take the first column as value, Second row Dang key, dict Convert to dictionary
4、 basis value, Use sorted Sort
5、 adopt for: The result after cyclic sorting , Split the data join After combination , Append to two empty lists respectively , Again zip that will do ( In order to reverse the order of the two columns )( There may be questions : Why not use “ Key value pair ” Reverse form , And make it so troublesome , In the second step , Dictionary key It can't be a list , Therefore, it cannot be solved by reversing key value pairs )
**
The specific code is as follows :
**
import os
import pandas as pd
path=r"C:\Users\jam96\PycharmProjects\all_module\pandas_test\a"
dir_path=os.path.dirname(os.path.abspath(__file__))
result_path=os.path.join(dir_path,"data")
if not os.path.exists(result_path):
os.mkdir(result_path)
files=os.listdir(path)
print(files)
num=1
for i in files:
res=pd.read_csv(filepath_or_buffer=os.path.join(path,i),header=None)
a=res.values[:,0]
b=res.values[:,1]
d=[]
for i in a:
c=i.split("_")
d.append(c)
new=dict(zip(b,d))
#sorted Back to the list
new1=sorted(new.items(),key=lambda x:int(x[1][3]))
k=[]
j=[]
for i in new1:
k.append(i[0])
j.append("_" .join(i[1]))
result=zip(j,k)
pd1=pd.DataFrame(data=result)
pd1.to_csv(result_path+os.path.sep+"C00"+str(num)+".csv",index=False,header=None)
num+=1
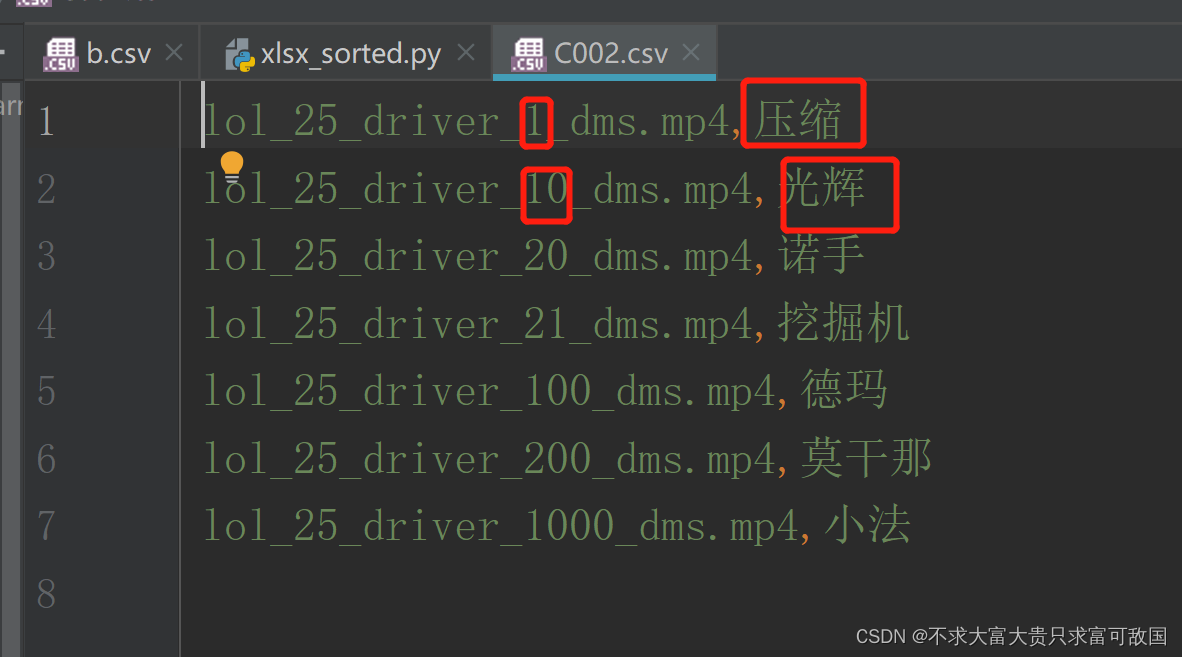
The operation results are as follows :
Optimize the code
Later, I found that the above code is redundant , Actually, it doesn't need to be so complicated , On the other hand, it is due to the lack of proficiency in dictionaries , The optimized code is as follows :
import pandas as pd
#csv File path
path=r"D:\TestSet\csv\dms\abc.csv"
# read csv file
res=pd.read_csv(path,encoding="gbk",header=None)
# Get the first and second columns
a=res.values[:,0]
b=res.values[:,1]
# Combine the data in the first column with the data in the second column
c=dict(zip(a,b))
# according to key Size of the fourth item , Please pay attention to the use of “int” The result is cast to integer
d=sorted(c.items(),key=lambda x:int(x[0].split("_")[3]))
# Write the sorted results into the new csv
e=pd.DataFrame(data=d)
e.to_csv(path_or_buf=r"C:\Users\xdjiang6\PycharmProjects\ Log results batch modify annotation set \data\a.csv",index=False,header=None)
边栏推荐
- Leetcode question brushing (5.31) string
- 使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储
- 升级 TiDB Operator
- Artcube information of "designer universe": Guangzhou implements the community designer system to achieve "great improvement" of urban quality | national economic and Information Center
- The resources of underground pipe holes are tight, and the air blowing micro cable is not fragrant?
- [2022 Guangdong saim] Lagrange interpolation (multivariate function extreme value divide and conquer NTT)
- 远程存储访问授权
- [t31zl intelligent video application processor data]
- [research materials] 2021 China online high growth white paper - Download attached
- The Vice Minister of the Ministry of industry and information technology of "APEC industry +" of the national economic and information technology center led a team to Sichuan to investigate the operat
猜你喜欢

【MySQL】日志
CISP-PTE实操练习讲解

"Designer universe" Guangdong responds to the opinions of the national development and Reform Commission. Primary school students incarnate as small community designers | national economic and Informa
Synchronized solves problems caused by sharing

化不掉的钟薛高,逃不出网红产品的生命周期

On the day of resignation, jd.com deleted the database and ran away, and the programmer was sentenced
What is the use of entering the critical point? How to realize STM32 single chip microcomputer?
Uibehavior, a comprehensive exploration of ugui source code
在 uniapp 中使用阿里图标
![[untitled]](/img/38/bc025310b9742b5bf0bd28c586ec0d.jpg)
[untitled]
随机推荐
【MySQL】数据库的存储过程与存储函数通关教程(完整版)
【MySQL】锁
从 TiDB 集群迁移数据至另一 TiDB 集群
[research materials] 2022 China yuancosmos white paper - Download attached
VMware 虚拟化集群
升级 TiDB Operator
Summary of phased use of sonic one-stop open source distributed cluster cloud real machine test platform
The State Economic Information Center "APEC industry +" Western Silicon Valley will invest 2trillion yuan in Chengdu Chongqing economic circle, which will surpass the observation of Shanghai | stable
在 uniapp 中使用阿里图标
Zhong Xuegao, who cannot be melted, cannot escape the life cycle of online celebrity products
Hcip day 16
Understanding of law of large numbers and central limit theorem
Hungry for 4 years + Ali for 2 years: some conclusions and Thoughts on the road of research and development
[MySQL] database stored procedure and storage function clearance tutorial (full version)
wincc7.5下载安装教程(Win10系统)
JS select all and tab bar switching, simple comments
Tidb backup and recovery introduction
让学指针变得更简单(三)
[t31zl intelligent video application processor data]
使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储