当前位置:网站首页>Personalized online cloud database hybrid optimization system | SIGMOD 2022 selected papers interpretation
Personalized online cloud database hybrid optimization system | SIGMOD 2022 selected papers interpretation
2022-07-06 08:01:00 【Tencent cloud database】
SIGMOD The International Conference on data management is an international conference with the highest academic status in the field of database , Ranked first in the top conference of database direction . In recent days, , The latest research results of Tencent cloud database team were selected SIGMOD 2022 Research Full Paper( Long articles on research ), The selected papers are entitled “HUNTER: An Online Cloud Database Hybrid Tuning System for Personalized Requirements”. It indicates that Tencent cloud database team is working in the database AI Make further breakthroughs in intelligence , Achieve performance leadership .
Automatic tuning of database parameters has been studied in academia and industry , But the existing methods are in the lack of historical data or in the face of new load parameter tuning , It often takes too long to tune ( Can reach several days ). In this paper , The team proposed a hybrid tuning system Hunter, That is, the improved CDBTune+, Mainly solved ⼀ A question : How to significantly reduce the tuning time while ensuring the tuning effect . Through experiments, the optimization effect is obvious : With the increase of concurrency, the tuning time decreases quasi linearly , In the single concurrency scenario, the tuning time only needs 17 Hours , stay 20 In the concurrency scenario, the tuning time is reduced to 2 Hours .
working principle ( Analysis of technical principles )
This is a CDB/CynosDB The third research achievement paper of the database team was SIGMOD Included . Following 2019 In, the database team first proposed based on deep reinforcement learning (DRL) End to end cloud database parameter tuning system CDBTune, The research paper “An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning” Included in the SIGMOD 2019 Research Full Paper( Long articles on research ).
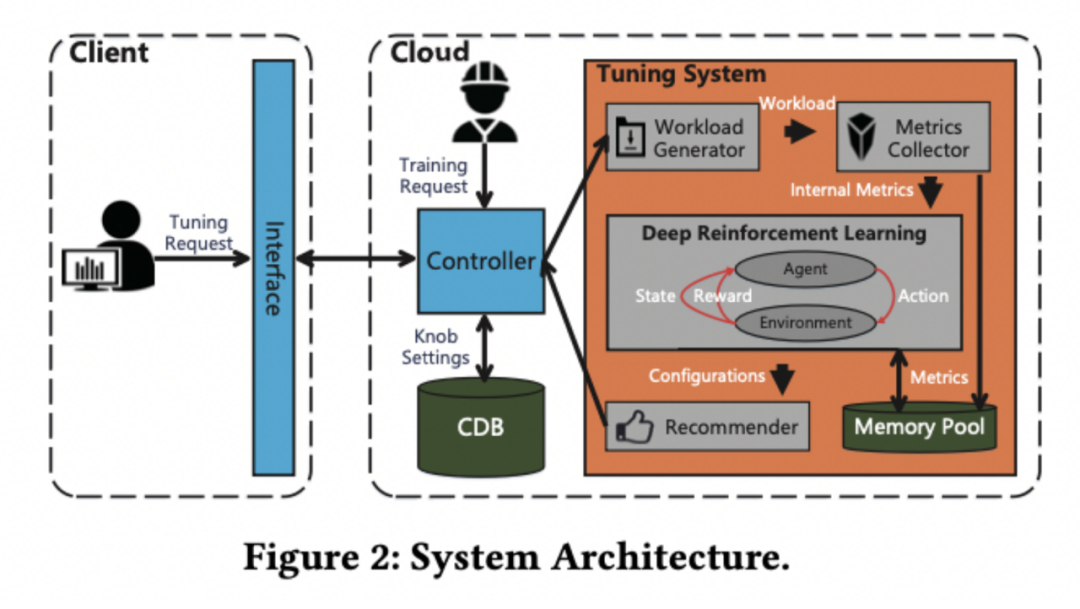
although CDBTune The effect of parameter adjustment has been achieved ⼀ A fairly high level , But we also found that ,CDBTune It takes a long time to achieve high performance through self-learning .
Regarding this , The improvement is proposed in this collected paper CDBTune+, It can greatly reduce the tuning time on the premise of ensuring the tuning effect .
Improved hybrid tuning system CDBTune+, It mainly includes sample generation 、 Search space optimization 、 There are three stages of in-depth recommendation . In the sample generation stage, genetic algorithm is used for initial optimization , Get high-quality samples quickly ; Search space optimization stage utilization ⼀ The sample information of the stage reduces the solution space , Reduce the cost of learning ; In the deep recommendation stage, the information of the previous stage is used to optimize the dimension and strengthen the pre training of learning , Ensure the tuning effect and significantly reduce the tuning time .
In order to enter ⼀ Step to accelerate the tuning process , We make the most of CDB The technology of cloning , Use multiple database instances to realize parallelization , Make the whole tuning time better ⼀ Step by step .
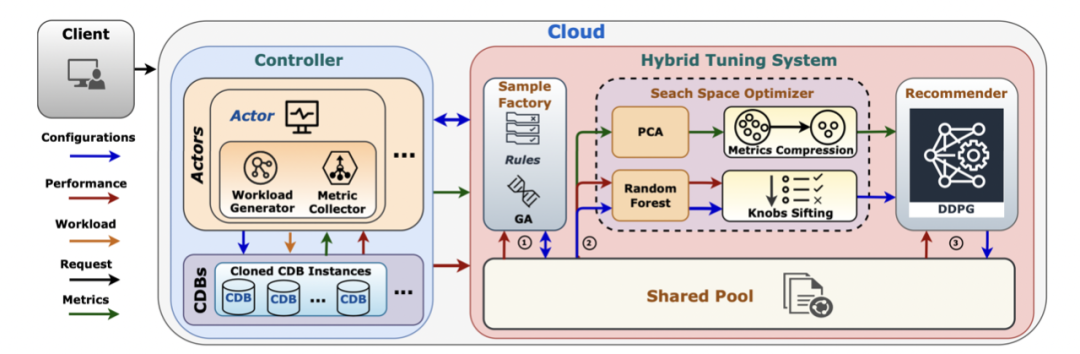
Sample generation
As shown in the figure below , Because the learning based tuning method has poor tuning effect in the early stage of training 、 The convergence speed is slow ( We call it the cold start problem ).
We believe that these methods face the problem of cold start mainly because :
1、 Small number of samples, poor quality , It is difficult for the Internet to quickly learn the right direction of exploration . 2、 Big search space , The network structure is complex , Slow learning .
In order to alleviate the above problems , We adopt a heuristic method with faster convergence ( Such as : Genetic algorithm (ga) (GA)) Perform initial tuning , In order to quickly obtain high-quality samples .
Pictured 5 Shown , Different methods 300 Secondary parameter recommendation , In the picture is this 300 Database performance distribution corresponding to secondary parameters . You can see , Compared with other methods ,GA It can collect more high-performance parameters .
Although it has a faster learning speed , however GA But it may be easier to converge to the suboptimal solution , Pictured 6 Shown .
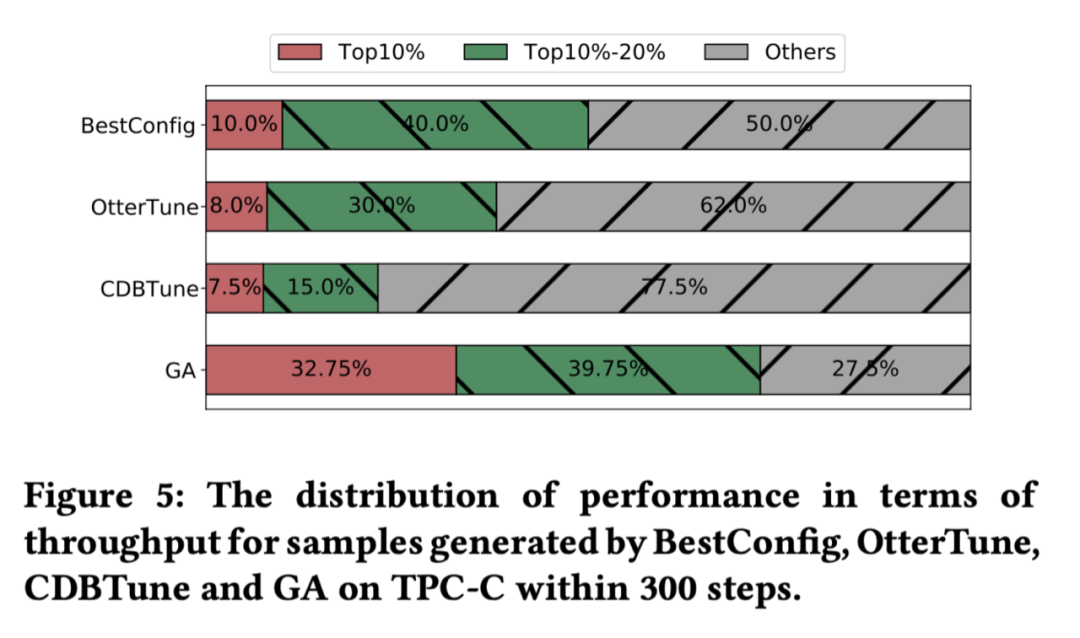
Although the heuristic method has a faster convergence speed , But it is easy to converge to local optimization , Resulting in poor tuning results .
However, the learning based method can get higher performance after a long tuning time , But it takes a long time to train , Slower . We combine the two methods , That is, the tuning speed is accelerated , It also ensures the quality of parameters .
Search space optimization
Simply splicing the two is difficult ⼀ Fixed performance improvement ( Save about 20% Time for ), But we expect more .
More high-quality samples can be obtained by using the sample generation stage , But it did not give full play to its effect . We make use of PCA Reduce the dimension of state space ,Random Forests Sort the importance of parameters .
PCA yes ⼀ Three commonly used dimensionality reduction methods , High dimensional data can be reduced to low dimensional data while retaining most of the information . We use the cumulative variance contribution rate to measure the retention of information ,⼀ In general , When the cumulative variance contribution rate > 90% It can be considered that the information has been completely retained .
We choose the two components that contribute the most , And take it as x、y Axial tracing point , Take its corresponding database performance as the color of the point ( The darker the color, the lower the performance ), It can be seen that , Low performance points can be clearly distinguished by two components , thus it can be seen ,PCA Can help DRL Learn better .
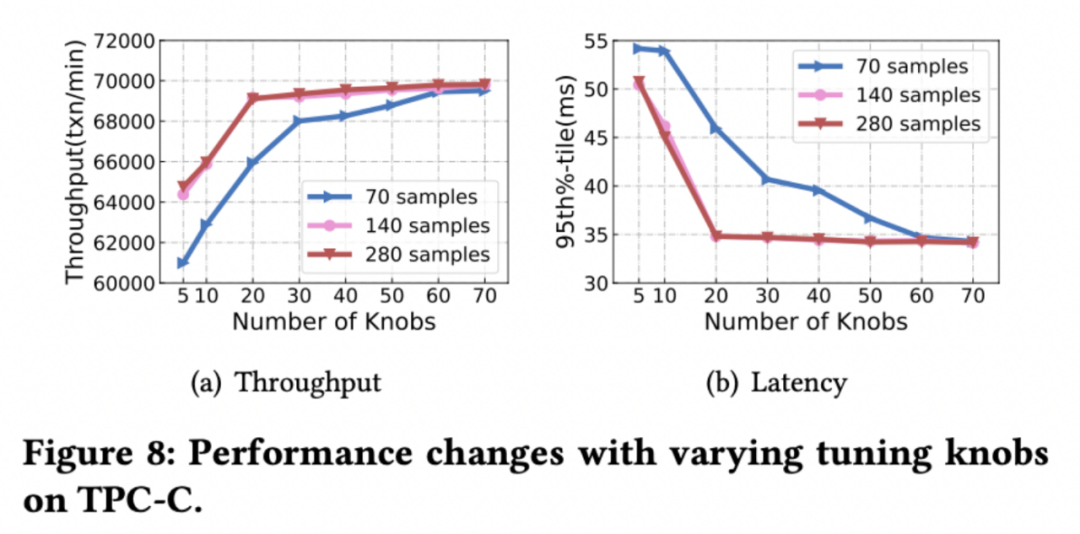
Random forests can be used to calculate the importance of features , We take database parameters as input , The corresponding database performance is output training random forest model , Then calculate the importance of each database parameter , And sort . Use a different number of Top Parameter tuning can see the changes in the optimal performance of the database , stay ⼀ Under the guarantee of a certain number of samples ,TPC-C load regulation 20 High performance can be achieved with parameters . 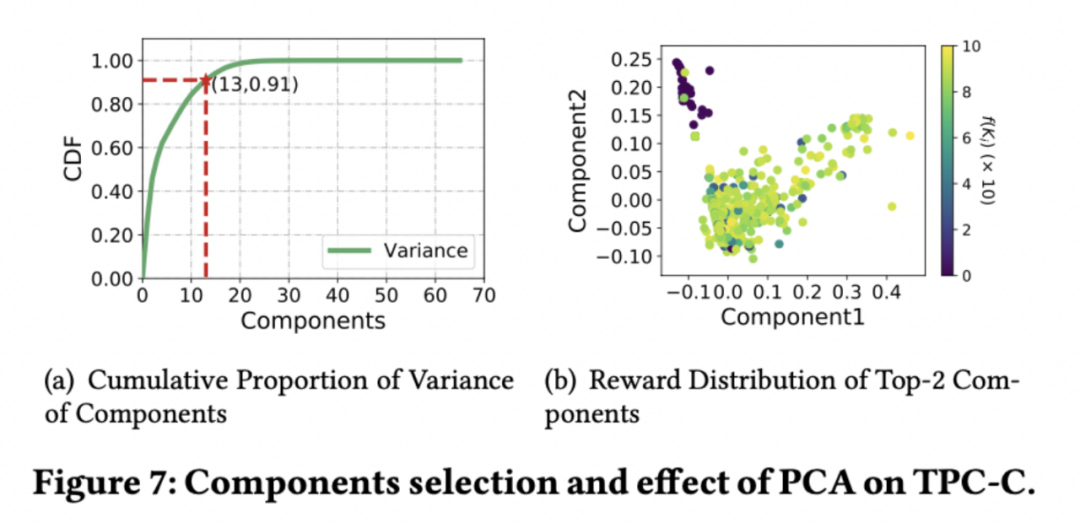
In depth recommendation
After sample generation and search space optimization , We use deep reinforcement learning in the deep recommendation stage (DRL) To recommend parameters .
First , The results of search space optimization will be right DRL Network optimization , Reduce the dimension of its input and output , Simplify network structure .
secondly , Samples in the sample generation phase will be added DRL Experience pool , from DRL Conduct ⼀ Pre training to a certain extent . Last ,DRL Parameters will be recommended based on the improved exploration strategy .
DRL The basic structure and CDBTune similar , In order to make full use of high-quality historical data , We revised its exploration strategy . action ( Database parameter configuration ) Yes ⼀ The fixed probability is explored near the historical optimal parameters , The specific calculation method is shown in the figure below . 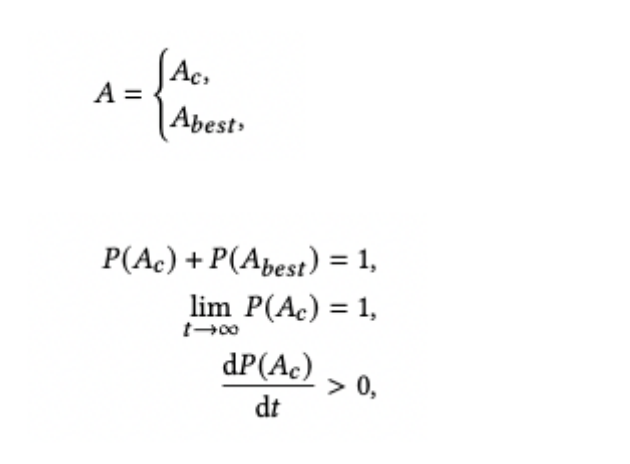 Ac Express DRL Result ,Abest Indicates the best in history , In the initial case Ac The probability of is 0.3.
Ac Express DRL Result ,Abest Indicates the best in history , In the initial case Ac The probability of is 0.3.
Performance analysis of tuning effect
Effect analysis
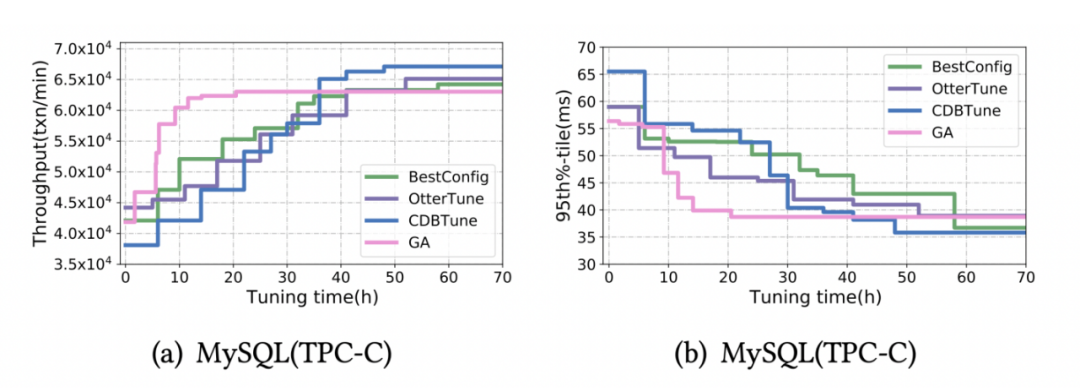
In order to test the effect of different tuning methods on parameter tuning from scratch , We tested under different loads . In the test , All methods have no pre training . among HUNTER-20 Said to 20 Instances for concurrent tuning HUNTER.
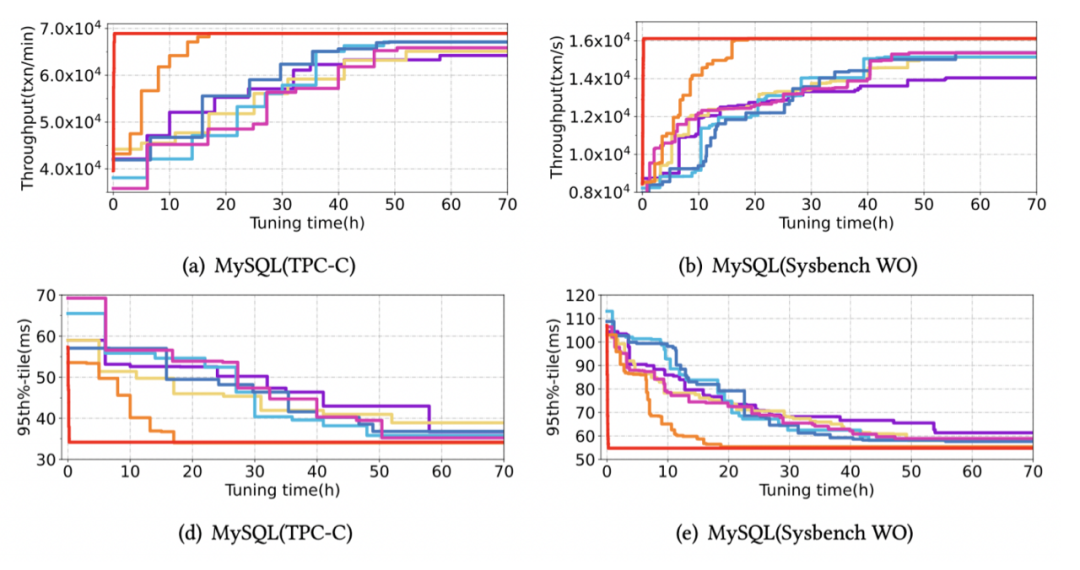
As shown in the figure below , Although only our method provides concurrency , But concurrency acceleration itself is universal , therefore , We have made progress in different methods under real load ⼀ Step test . Although most methods can achieve high enough performance with a long tuning time , however , At the same cost ( Time * Number of instances ),HUNTER Is the best . 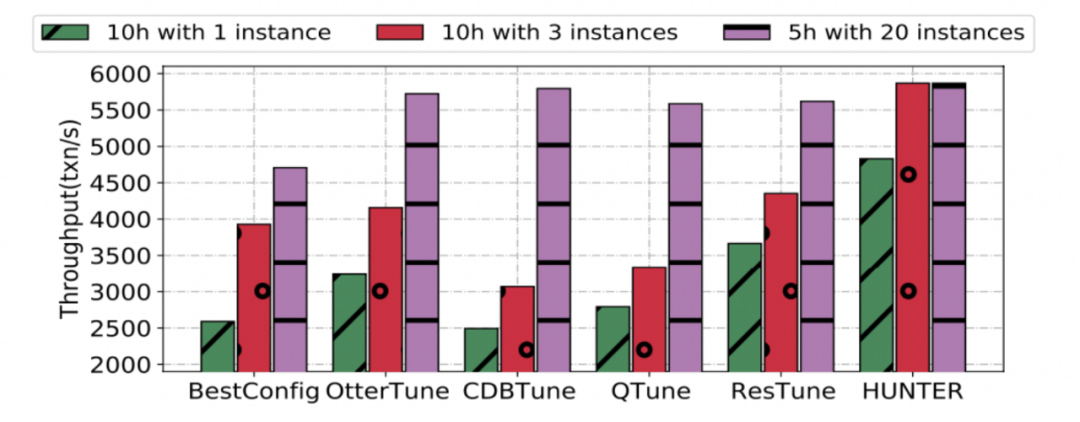
The following figure shows HUNTER-N Tuning to achieve the best performance that can be found serially takes time , You can see the effect of tuning speed , As concurrency increases , Tuning time is significantly reduced . 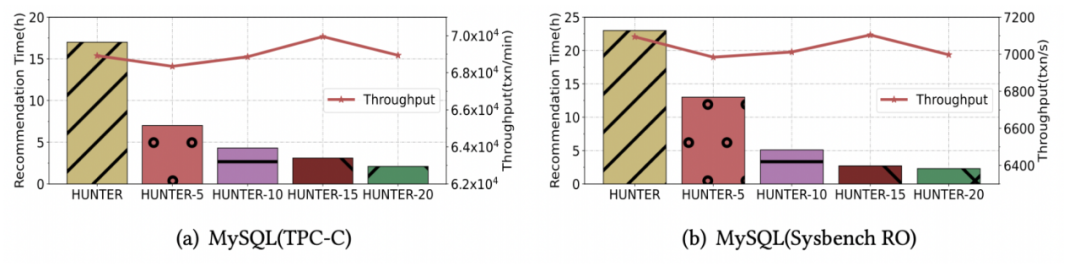
Insufficient
about DBA Come on , The simpler the load, the shorter the tuning time should be , But the automatic tuning method has no such characteristics , As shown in our above experimental diagram , Sometimes , Simple loads may take more time to achieve higher performance . More importantly , At present, it is difficult for us to quickly judge whether the performance has reached “ The optimal ”, This leads us to spend extra time to observe whether the tuning system can improve the database performance again .
at present
Through technical interpretation and effect analysis , We can see the improved Hunter Greatly improve the tuning effect , At the same time, it shows that the paper has a high possibility of landing the actual database problems , It has guiding significance .
In the next study , We hope to solve the problems mentioned above by combining expert experience , Improve the interpretability of parameter tuning and further compress the tuning time , At the same time, we also hope to find a method to estimate the optimal performance , Thus reducing additional tuning time .
CDBTune+ It aims to reduce the complexity of database parameter tuning , Realize zero operation and maintenance of parameter tuning , Tencent cloud database AI Another leap forward and Realization of intelligent transformation . The first phase of intelligent tuning has been launched in Tencent cloud MySQL Product launch , In the future, it will be applied to more Tencent cloud database products , Bring more contributions and services to academia and industry .
边栏推荐
- Machine learning - decision tree
- [untitled]
- ROS learning (IX): referencing custom message types in header files
- Pangolin Library: control panel, control components, shortcut key settings
- Secure captcha (unsafe verification code) of DVWA range
- Webrtc series-h.264 estimated bit rate calculation
- Golang DNS write casually
- 数据治理:元数据管理篇
- National economic information center "APEC industry +": economic data released at the night of the Spring Festival | observation of stable strategy industry fund
- Codeforces Global Round 19(A~D)
猜你喜欢
A Closer Look at How Fine-tuning Changes BERT

"Designer universe": "benefit dimension" APEC public welfare + 2022 the latest slogan and the new platform will be launched soon | Asia Pacific Financial Media
Nft智能合约发行,盲盒,公开发售技术实战--合约篇
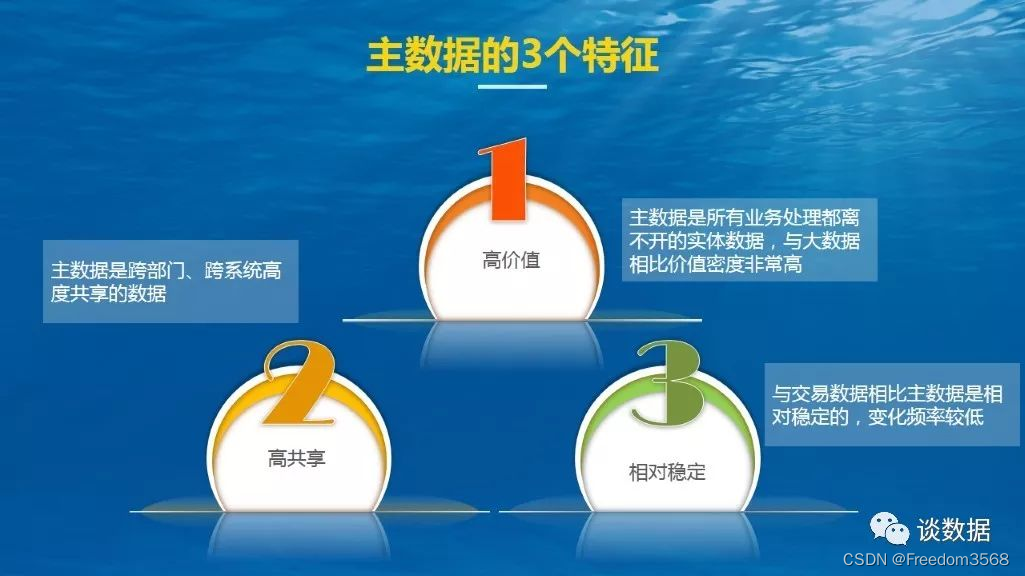
数据治理:主数据的3特征、4超越和3二八原则
![[nonlinear control theory]9_ A series of lectures on nonlinear control theory](/img/a8/03ed363659a0a067c2f1934457c106.png)
[nonlinear control theory]9_ A series of lectures on nonlinear control theory
Secure captcha (unsafe verification code) of DVWA range
22. Empty the table
Uibehavior, a comprehensive exploration of ugui source code
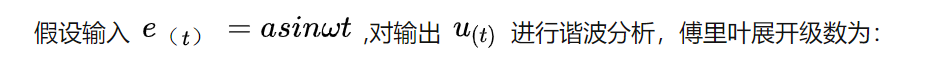
Parameter self-tuning of relay feedback PID controller

【Redis】NoSQL数据库和redis简介
随机推荐
Nft智能合约发行,盲盒,公开发售技术实战--拼图篇
Common functions for PHP to process strings
2.10transfrom attribute
MEX有关的学习
861. Score after flipping the matrix
使用 BR 备份 TiDB 集群数据到兼容 S3 的存储
Description of octomap averagenodecolor function
Pangolin Library: control panel, control components, shortcut key settings
备份与恢复 CR 介绍
Analysis of Top1 accuracy and top5 accuracy examples
(lightoj - 1410) consistent verbs (thinking)
使用 TiDB Lightning 恢复 S3 兼容存储上的备份数据
On why we should program for all
Leetcode question brushing record | 203_ Remove linked list elements
TiDB备份与恢复简介
Asia Pacific Financial Media | designer universe | Guangdong responds to the opinions of the national development and Reform Commission. Primary school students incarnate as small community designers
[factorial inverse], [linear inverse], [combinatorial counting] Niu Mei's mathematical problems
数据治理:元数据管理篇
使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储
Oracle time display adjustment