当前位置:网站首页>Realizing deep learning framework from zero -- Introduction to neural network
Realizing deep learning framework from zero -- Introduction to neural network
2022-07-02 03:55:00 【Angry coke】
introduction
In line with “ Everything I can't create , I can't understand ” Thought , This series The article will be based on pure Python as well as NumPy Create your own deep learning framework from zero , The framework is similar PyTorch It can realize automatic derivation .
Deep understanding and deep learning , The experience of creating from scratch is very important , From an understandable point of view , Try not to use an external complete framework , Implement the model we want . This series The purpose of this article is through such a process , Let us grasp the underlying realization of deep learning , Instead of just being a switchman .
This series is first official account of WeChat public. :JavaNLP
In our last article, we learned about the concept of neuron , In this article, let's learn about neural networks (Neural Network) Basic knowledge of .
Exclusive or questions
Let's first look at the famous XOR problem , This problem has led to the decade low point of neural network research .
The following pictures in this article are from nlp3
Exclusive or questions (XOR problem): Enter two Boolean values (0 or 1), When the two values are different, the output is 1, Otherwise, the output is 0.

Pictured above , Suppose the input is x1、x2, The output is y.
Before introducing Neural Networks , Let's first look at the perceptron (perceptron), The perceptron can be likened to a neuron , But it doesn't have a nonlinear activation function .
Perceptron is a binary classifier ( With weight w w w And offset b b b), Put the input x x x( Real valued vector ) Map to binary output . The output can be recorded as 0 or 1, Or rather, -1 and +1. The calculation method of the perceptron is as follows :
y = { 0 , if w ⋅ x + b ≤ 0 1 , if w ⋅ x + b > 0 (1) y= \begin{cases} 0, & \text {if $w \cdot x + b \leq 0$ } \\ 1, & \text{if $w \cdot x + b > 0$ } \end{cases} \tag 1 y={ 0,1,if w⋅x+b≤0 if w⋅x+b>0 (1)
We can easily build a system that can calculate and calculate (AND) And or operation (OR) Our perceptron :
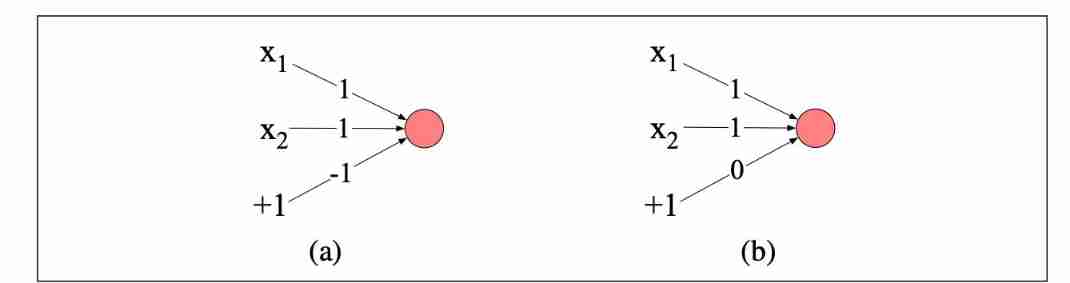
The figure above shows the implementation and (a) And or (b) The perceptron of computation . The inputs are x 1 , x 2 x_1,x_2 x1,x2. The value on the line above represents the weight or offset .
such as (a) by x 1 + x 2 − 1 x_1 + x_2 -1 x1+x2−1, Input is 1 , 1 1,1 1,1 when , The result is 1 > 0 1 > 0 1>0, So the output y = 1 y=1 y=1.
Addition and operation (AND) and Or operations (OR), XOR operation is also important .
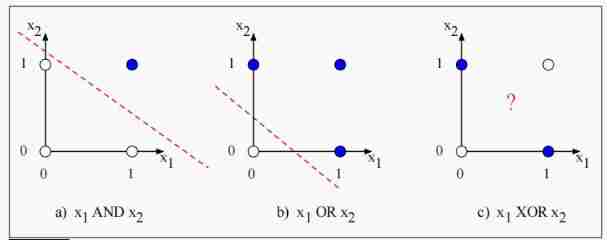
But we can't realize XOR operation through a perceptron . Because the perceptron is a linear classifier , For 2D input x 1 x_1 x1 and x 2 x_2 x2, Perceptron equation w 1 x 1 + w 2 x 2 + b = 0 w_1x_1 + w_2x_2 + b =0 w1x1+w2x2+b=0 It's an equation of a straight line , This line serves as the decision boundary in two-dimensional space , One side represents output 0 0 0, The output of the other side is 1 1 1.
The following figure shows the possible logic inputs (00、01、10 and 11), And by AND and OR A line drawn by a set of possible parameters of the classifier . But we can't draw a line that will XOR The true example of (01 and 10) And negative examples (00 and 11) Distinguish . We said XOR Not a linearly separable function .
Solution : neural network
Although the XOR function cannot be represented by a single perceptron , But it can be represented by a hierarchical network based on perceptron units . Let's see how to use two layers ReLU Unit computation XOR problem .

There are three in the two-tier network ReLU unit , Namely h 1 , h 2 h_1,h_2 h1,h2 and y 1 y_1 y1. The number on the edge represents the weight of each unit w w w, Gray directed edges represent offsets .
Assume that the input x = [ 0 , 0 ] x=[0,0] x=[0,0], We calculated

It's used here ReLU Activation function , therefore h 2 h_2 h2 The output of is 0 0 0, You can verify other inputs by yourself .
In this example, we fix the weight value , But in fact, the weight of neural network is automatically learned through back-propagation algorithm .
Now let me learn about the most common neural networks .
Feedforward neural networks
Feedforward neural networks ( Feedforward Neural Networks,FNN) It is a multi-layer network without circulation that spreads layer by layer . For historical reasons , Multilayer feedforward network , Also known as multilayer perceptron (multi-layer perceptron,MLP). But this is a technical misnomer , Because neurons in modern multi-layer networks are not perception machines ( The perceptron is purely linear , But neurons in modern networks have nonlinear activation functions ).
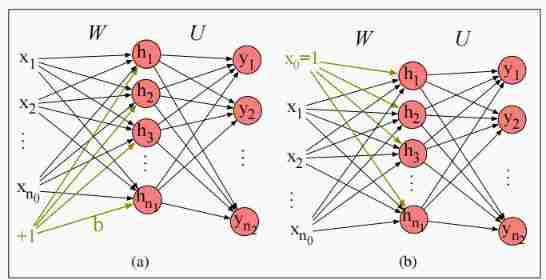
Simple ( Two layers of ) Feedforward networks have three types of nodes : input unit 、 Hidden units and output units , As shown in the figure below .

Input layer x x x It usually represents a vector composed of multiple scalars ; The core of neural network is hidden layer h h h, By hidden cells h i h_i hi form , Each hidden unit is the neuron we learned earlier , The hidden layer calculates the weighted sum of its input and applies a nonlinear function . In the standard architecture , Each layer is fully connected ( Every neuron is connected to every input ).
Why is this a two-layer neural network , Because when we describe the number of layers , The input layer is usually ignored .
Note that each hidden cell has a weight parameter and an offset . We do this by putting each unit i i i The weight vector and deviation of are combined into the weight matrix of the whole layer W W W And the bias vector B B B To represent the parameters of the entire hidden layer . Weight matrices W W W Every element in W j i W_{ji} Wji Says from the first i i i Input units x i x_i xi To the first j j j Hidden units h j h_j hj The weight of the connection .
Use a matrix W W W The advantage of representing the weight of the entire layer is , Now through simple matrix operation , The hidden layer calculation of feedforward network can be completed very effectively . actually , There are only three steps to calculate : Multiply the weight matrix by the input vector x x x, Add the offset vector b b b, Then apply the activation function g g g( such as Sigmoid、tanh or ReLU etc. ).
Hidden layer output , vector h h h, Therefore, it can be calculated as follows ( Let's suppose we use Sigmoid As an activation function ):
h = σ ( W x + b ) (2) h = \sigma(Wx+b) \tag 2 h=σ(Wx+b)(2)
Sometimes , We also use σ \sigma σ It generally refers to any activation function , Not just Sigmoid.
W x + b Wx+b Wx+b The result is a vector , therefore σ \sigma σ Apply to this vector .
Now let's introduce some commonly used marks , To better describe the following content .
In this case , We call the input layer the... Of the network 0 0 0 layer (layer 0), n 0 n_0 n0 Indicates the number of inputs in the input layer , therefore x x x The dimension is n 0 n_0 n0 Real vector of , Or formally x ∈ R n 0 x \in \Bbb R^{n_0} x∈Rn0 The column vector [ n 0 × 1 ] [n_0 \times 1] [n0×1]; We call the hidden layer 1 1 1 layer (layer 1), The output layer is 2 2 2 layer (layer 2); Dimensions of hidden layers ( The number of cells in the hidden layer ) yes n 1 n_1 n1, therefore h ∈ R n 1 h \in \Bbb R^{n_1} h∈Rn1, meanwhile b ∈ R n 1 b \in \Bbb R^{n_1} b∈Rn1( Because each hidden cell has an offset ); Then the weight matrix W W W The dimension of is W ∈ R n 1 × n 0 W \in \Bbb R^{n_1\times n_0} W∈Rn1×n0( Combine the formula ( 2 ) (2) (2)).
So the formula ( 2 ) (2) (2) An output in h j h_j hj, It can be expressed as h j = σ ( ∑ i = 0 n 0 W j i x i + b j ) h_j = \sigma(\sum_{i=0}^{n_0} W_{ji}x_i + b_j) hj=σ(∑i=0n0Wjixi+bj).
Through the hidden layer , We set the dimension as n 0 n_0 n0 The input vector of is expressed as dimension n 1 n_1 n1 The hidden vector of , Then it is passed to the output layer to calculate the final output . The dimension of the output depends on the actual problem , For example, the regression problem is a real value ( Only one output ). But the common problem is classification . If it is a second category , Then the dimension of the output layer is 2 2 2, Output unit ( Output node ) Only two. ; If it's multi classification , Then there are multiple output units .
Let's look at what happened in the output layer , The output layer also has a weight matrix ( U U U),( There is no weight except for the input layer , This is one of the reasons why the input layer does not calculate the number of layers ), But some model output layers are not biased b b b Of , So the weight matrix U U U Directly with its input vector h h h Multiply to get intermediate output z z z:
z = U h (3) z = Uh \tag 3 z=Uh(3)
The output layer has n 2 n_2 n2 Output nodes , therefore z ∈ R n 2 z \in \Bbb R^{n_2} z∈Rn2, Weight matrices U ∈ R n 2 × n 1 U \in \Bbb R^{n_2 \times n_1} U∈Rn2×n1, among U i j U_{ij} Uij Is from the hidden layer j j j Units to output layer i i i Weight of units .
Be careful , there z z z It's a real vector , Usually not the final output , For the classification model , We need to convert it into a probability distribution .
There is a very convenient function to normalize the vector of real numbers (normalizing) Is the probability distribution , The function is Softmax. Suppose the given dimension is d d d Vector z z z,Softmax Defined as :
softmax ( z i ) = exp ( z i ) ∑ j = 1 d exp ( z j ) 1 ≤ i ≤ d (4) \text{softmax}(z_i) = \frac{\exp(z_i)}{\sum_{j=1}^d \exp(z_j)} \quad 1 \leq i \leq d \tag 4 softmax(zi)=∑j=1dexp(zj)exp(zi)1≤i≤d(4)
That is, we can regard a neural network classifier with a hidden layer as building a vector h h h, It is a vector representation of the input , Then on the network h h h Multiple logistic regression of running Standards . by comparison , Features in logistic regression are mainly designed manually through feature templates . So neural networks are like Softmax Logical regression , But the advantage is :(a) There can be more layers , Because deep neural networks are like layer after layer of logistic regression classifiers ;(b) There are many optional activation functions in the middle tier (tanh,ReLU,sigmoid) Not just sigmoid( Although we may use σ \sigma σ To represent any activation function ); Features are not formed through feature templates , The layer in front of the network forms its own feature representation .
We can get the two-layer feedforward network in this example , Also known as single hidden layer feedforward network , The final expression of :
h = σ ( W x + b ) z = U h y = softmax ( z ) (5) \begin{aligned} h &= \sigma(Wx + b) \\ z &= Uh \\ y &= \text{softmax}(z) \end{aligned} \tag{5} hzy=σ(Wx+b)=Uh=softmax(z)(5)
among x ∈ R n 0 , h ∈ R n 1 , b ∈ R n 1 , W ∈ R n 1 × n 0 , U ∈ R n 2 × n 1 x \in \Bbb R^{n_0}, h \in \Bbb R^{n_1}, b \in \Bbb R^{n_1}, W \in \Bbb R^{n_1 \times n_0}, U \in \Bbb R^{n_2 \times n_1} x∈Rn0,h∈Rn1,b∈Rn1,W∈Rn1×n0,U∈Rn2×n1, Then output the vector y ∈ R n 2 y \in \Bbb R^{n_2} y∈Rn2. We call this network a two-layer neural network . therefore , So to speak , Logistic regression is a layer of network . When resources can support , We can freely deepen the number of layers of the feedforward network , In this way, we can get the real deep neural network .
A more common notation indicates
Let's introduce some more common marks ,Andrew Ng This set of representation is also used . say concretely , Use the superscript in square brackets to indicate the number of layers , From the input layer 0 Start .
therefore , W [ 1 ] W^{[1]} W[1] Express ( first ) Weight matrix of hidden layer , b [ 1 ] b^{[1]} b[1] Express ( first ) The offset vector of the hidden layer ; n j n_j nj Will denote the second j j j Number of units in the layer ; g ( ⋅ ) g(\cdot) g(⋅) To represent the activation function , The middle tier often uses ReLU or tanh Activation function , The output layer is often softmax; a [ i ] a^{[i]} a[i] To represent the i i i Layer output , z [ i ] z^{[i]} z[i] Express W [ i ] a [ i − 1 ] + b [ i ] W^{[i]}a^{[i-1]}+b^{[i]} W[i]a[i−1]+b[i]; The first 0 Layer is the input layer , So we will enter more generally x x x be called a [ 0 ] a^{[0]} a[0].
In this way, we rephrase the above single hidden layer feedforward network as :
z [ 1 ] = W [ 1 ] a [ 0 ] + b [ 1 ] a [ 1 ] = g [ 1 ] ( z [ 1 ] ) z [ 2 ] = W [ 2 ] a [ 1 ] + b [ 2 ] a [ 2 ] = g [ 2 ] ( z [ 2 ] ) y ^ = a [ 2 ] (6) \begin{aligned} z^{[1]} &= W^{[1]}a^{[0]} + b^{[1]} \\ a^{[1]} &= g^{[1]}(z^{[1]}) \\ z^{[2]} &= W^{[2]}a^{[1]} + b^{[2]} \\ a^{[2]} &= g^{[2]}(z^{[2]}) \\ \hat y &= a^{[2]}\\ \end{aligned} \tag{6} z[1]a[1]z[2]a[2]y^=W[1]a[0]+b[1]=g[1](z[1])=W[2]a[1]+b[2]=g[2](z[2])=a[2](6)
Replace the offset unit mark
In order to simplify the description of the network , We can omit the explicit description of bias b b b. So , We add a virtual node to each layer a 0 a_0 a0, Its value will always be 1 1 1. therefore , Input layer 0 0 0 The layer will have virtual nodes a 0 [ 0 ] = 1 a^{[0]}_0=1 a0[0]=1, layer 1 1 1 Will have a 0 [ 1 ] = 1 a^{[1]}_0=1 a0[1]=1, And so on . This virtual node still has an associated weight , This weight represents the deviation value b b b, For example, take the following equation :
h = σ ( W x + b ) h = \sigma(Wx+ b) h=σ(Wx+b)
Replace with :
h = σ ( W x ) (7) h = \sigma(Wx) \tag{7} h=σ(Wx)(7)
But now x x x Vectors are not n 0 n_0 n0 It's worth , Turned into n 0 + 1 n_0+1 n0+1 It's worth , Include fixed values x 0 = 1 x_0=1 x0=1, This becomes x = x 0 , ⋯ , x n 0 x= x_0,\cdots,x_{n_0} x=x0,⋯,xn0. We can change the calculation h j h_j hj The way , from :
h j = σ ( ∑ i = 1 n 0 W j i x i + b j ) (8) h_j = \sigma \left( \sum_{i=1}^{n_0} W_{ji}x_i + b_j \right) \tag{8} hj=σ(i=1∑n0Wjixi+bj)(8)
Turned into :
h j = σ ( ∑ i = 0 n 0 W j i x i ) (9) h_j = \sigma \left( \sum_{i=0}^{n_0} W_{ji}x_i \right) \tag{9} hj=σ(i=0∑n0Wjixi)(9)
Among them W j 0 W_{j0} Wj0 To replace the b j b_j bj, We can also simplify the drawing :
From the left of the above figure ( a ) (a) (a) Simplified to the right ( b ) (b) (b).
References
- Speech and Language Processing
边栏推荐
- It took me only 3 months to jump out of the comfort zone and become an automated test engineer for 5 years
- Imageai installation
- 整理了一份ECS夏日省钱秘籍,这次@老用户快来领走
- Visual slam Lecture 3 -- Lie groups and Lie Algebras
- 手撕——排序
- 【人员密度检测】基于形态学处理和GRNN网络的人员密度检测matlab仿真
- 蓝桥杯单片机省赛第十一届
- What is the logical structure of database file
- What kind of interview is more effective?
- 《动手学深度学习》(二)-- 多层感知机
猜你喜欢

蓝桥杯单片机省赛第九届

整理了一份ECS夏日省钱秘籍,这次@老用户快来领走

Opencv learning example code 3.2.4 LUT
![[untitled]](/img/53/cb61622cfcc73a347d2d5e852a5421.jpg)
[untitled]
高性能 低功耗Cortex-A53核心板 | i.MX8M Mini

软件测试人的第一个实战项目:web端(视频教程+文档+用例库)
Hands on deep learning (II) -- multi layer perceptron
【leetcode】74. Search 2D matrix

蓝桥杯单片机省赛第五届
Learn more about materialapp and common attribute parsing in fluent
随机推荐
go 变量与常量
【leetcode】81. Search rotation sort array II
Unity脚本的基础语法(8)-协同程序与销毁方法
Blue Bridge Cup single chip microcomputer sixth temperature recorder
The first game of the 12th Blue Bridge Cup single chip microcomputer provincial competition
【无线图传】基于FPGA的简易无线图像传输系统verilog开发,matlab辅助验证
The first game of the 11th provincial single chip microcomputer competition of the Blue Bridge Cup
[mv-3d] - multi view 3D target detection network
5G時代全面到來,淺談移動通信的前世今生
集成底座方案演示说明
How about Ping An lifetime cancer insurance?
Hands on deep learning (II) -- multi layer perceptron
Haute performance et faible puissance Cortex - A53 Core Board | i.mx8m mini
Suggestions on settlement solution of u standard contract position explosion
Influence of air resistance on the trajectory of table tennis
【直播回顾】战码先锋首期8节直播完美落幕,下期敬请期待!
Oracle 常用SQL
Unity脚本的基础语法(6)-特定文件夹
【DesignMode】原型模式(prototype pattern)
Blue Bridge Cup SCM digital tube skills