当前位置:网站首页>CVPR 2022 | common 3D damage and data enhancement
CVPR 2022 | common 3D damage and data enhancement
2022-07-05 20:21:00 【3D vision workshop】
Thesis link :https://arxiv.org/abs/2203.01441
Title of thesis :3D Common Corruptions and Data Augmentation(CVPR2022[Oral])
Project address :https://3dcommoncorruptions.epfl.ch/
Abstract
We introduce a set of image transformations , The training mechanism is used to evaluate the robustness of the neural network and the availability of the training data . The main difference between the proposed transformation is , Compared with existing methods ( Such as common damage [27]) Different , The geometry of the scene is included in the transformation - This leads to damage that is more likely to occur in the real world . We also introduced a set of semantic corruptions ( For example, natural object occlusion .)
We show that these transformations are “ efficient ”( It can be calculated immediately )、“ Scalable ”( It can be applied to most image data sets )、 Expose the vulnerability of existing models , And used as “3D” Data enhancement mechanism that can effectively make the model more robust . The evaluation of several tasks and data sets shows , take 3D The incorporation of information into benchmarking and training opens up a promising direction for robustness research .
Introduce
Computer vision models deployed in the real world will encounter naturally occurring distribution offsets from their training data . These changes range from lower levels of distortion , Such as motion blur and illumination change , To semantic distortion , If objects block . Each of them represents a possible failure mode of a model , And often proved to lead to extremely unreliable predictions [15, 23, 27, 31, 67]. therefore , Before deploying these models in the real world , It is crucial to systematically test the vulnerability of these transformations .
This work proposes a set of distributed transformations , To test the robustness of the model . Compared with the previously proposed offset of unified two-dimensional modification on the image , Such as Common Corruptions (2DCC) [27], Our offset combines three-dimensional information to produce an offset consistent with the geometry of the scene . This leads to changes that are more likely to occur in the real world ( See the picture 1).

The resulting set includes 20 Damage , Each represents a distribution shift from training data , We express it as 3D Common damage (3DCC).3DCC It involves several aspects of the real world , Such as camera movement 、 The weather 、 Occlusion 、 Depth of field and lighting . chart 2 Provides an overview of all damage . Pictured 1 Shown , With the only 2D Methods compared ,3DCC The damage phenomenon in is more diversified and realistic .

We are the first 5 It is shown in section , Methods to improve robustness , Including those methods with diversified data enhancement , stay 3DCC The performance will drop sharply . Besides , We observed that ,3DCC The exposed robustness problems are closely related to the damage caused by realistic synthesis . therefore ,3DCC It can be a challenge .
Inspired by this , Our framework also introduces new 3D data enhancement . Compared with 2D enhancement , They take into account the geometry of the scene , Thus, the model can establish invariance against more real damage . We are the first 5.3 It is shown in section , They greatly improve the robustness of the model to these damages , Including those damages that cannot be solved by two-dimensional enhancement .
The suggested damage is generated programmatically , Its parameters are public , Fine grained analysis of robustness can be carried out , For example, by increasing the blur of three-dimensional motion . Their computational efficiency is very high , It can be used as data enhancement for real-time calculation during training , And the increase of calculation cost is very small . They are also scalable , That is, they can be applied to standard visual data sets , for example ImageNet[12], These datasets do not have 3D labels .
Related work
This work proposes a data centric robustness approach [52, 63]. In the case of limited space , We outline some related topics .
Robustness benchmark based on damage : Some studies have proposed robustness benchmarks , To understand the vulnerability of the model to damage . A popular benchmark , Common damage (2DCC)[27], Generate synthetic damage on real images , Exposed the sensitivity of image recognition model . It leads to a series of work , Or create new damage , Or apply similar corruption to other data sets for different tasks [7,32,43,45,66,80] . Compared with these works ,3DCC Use 3D Information modifies the real image , To produce real damage . The resulting image is compared with the two-dimensional corresponding image , It is different in sense , Different failure modes are exposed in the model prediction ( See the picture 1 and 8). Other work is to create and capture damage in the real world , for example ObjectNet[3]. Although it is realistic , But it requires a lot of manual work , And it can't scale . A more scalable approach is to use a three-dimensional simulator based on computer graphics to generate corrupted data [38], This may lead to generalization problems .3DCC Designed to generate damage as close to the real world as possible , While maintaining scalability .
Robustness analysis : The work uses existing benchmarks to detect the robustness of different methods , Such as data enhancement or self-monitoring training , Under several distribution changes . Recent work has investigated the relationship between synthesis and natural distribution transformation [14,26,44,68] And the effectiveness of architectural progress [5,48,64]. We have chosen several popular methods to illustrate 3DCC It can be used as a challenging benchmark ( chart 6 and 7).
Improve robustness : Many methods have been proposed to improve the robustness of the model , Such as data enhancement with damaged data [22, 40, 41, 60], Texture change [24, 26], Image synthesis [82, 85] And transformation [29, 81]. Although these methods can be summarized into some unseen examples , But the performance improvement is uneven [22, 61]. Other methods include self training [76]、 Preliminary training [28, 50]、 Structural changes [5, 64] And a diverse collection [33, 51, 78, 79]. ad locum , We adopt a data centric robustness approach , namely :i. Provide a large set of realistic distribution offsets ;ii. Introduce new 3D data enhancements , Improve robustness to real-world damage (5.3 section ).
Realistic image synthesis : It involves the technology of generating realistic images . Some of these techniques have recently been used to create corrupted data . These technologies are generally aimed at a single real-world damage . Examples include adverse weather conditions [19, 30, 62, 69, 70], Motion blur [6, 49], The depth of field [4, 17, 53, 71, 72], lighting [25, 77], And noise [21, 74]. They can be used for purely artistic purposes , It can also be used to create training data . Some of our three-dimensional transformations are instantiations of these methods , Its downstream goal is to test and improve the robustness of the model within a unified framework , And there is extensive damage .
Image restoration : The purpose is to use classical signal processing technology [18, 20, 35,42] Or a learning based approach [1,8,46,47,57,86,87] To eliminate damage in the image . What distinguishes us from these works is , We generated corrupted data , Instead of eliminating it , Use them as benchmarks or data additions . therefore , In the latter , We use these damaged data for training , To encourage the model not to be damaged , Instead of training the model as a preprocessing step to remove damage .
Antagonistic damage : An imperceptible worst-case offset is added to the input to deceive the model [11,36,41,67]. Most failure cases of models in the real world are not the result of antagonistic damage , It is a naturally occurring distribution shift . therefore , Our focus in this article is to generate damage that may occur in the real world .
Generate common 3D damage
3.1. Damage type
We define different types of damage , Depth of scene 、 Camera motion 、 The light 、 video 、 The weather 、 View changes 、 Semantics and noise , stay 3DCC There is 20 Kind of damage . Most damage requires RGB Image and scene depth , And some need to 3D grid ( See the picture 3). We use a set of methods using three-dimensional synthesis technology or image forming model to produce different damage types , It will be explained in detail below . Further details are provided in the supplementary documents .
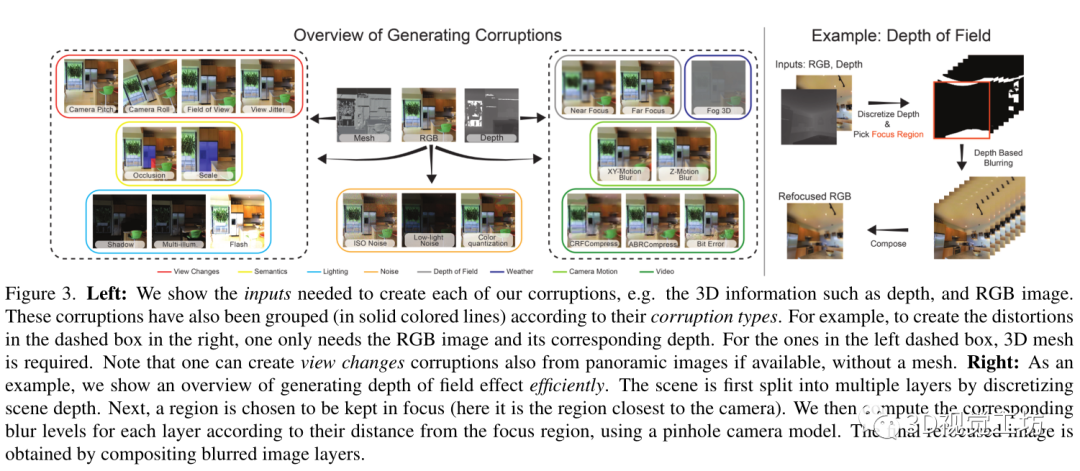
The depth of field : Damage will produce a refocused image . They keep a part of the image in focus , And the rest becomes blurred . We consider a layered approach [4,17], Divide the scene into multiple levels . For each layer , Use the pinhole camera model to calculate the corresponding degree of blur . Then the fuzzy layer is synthesized by alpha mixing method . chart 3( Right ) Shows an overview of this process . We randomly change the focus area to the near or far of the scene to produce near focus and far focus damage .
Camera motion : Blurred images are produced due to the movement of the camera during exposure . In order to produce this effect , We first use the depth information to transform the input image into a point cloud . then , We define a trajectory ( Camera motion ) And render the new view along this track . Because the point cloud is composed of a single RGB Image generation , When the camera moves , Its information about the scene is incomplete . therefore , The rendered view will have an incomplete illusion . To alleviate the problem , We used [49] The painting method in . then , The generated views are combined to obtain parallax consistent motion blur . When the main motion of the camera is along the image XY- Flat or Z Axial time , We define XY- Motion blur and Z- Motion blur .
lighting : Damage changes the lighting of the scene by adding new light sources and modifying the original lighting . We use Blender[10] To place these new lights , And calculate the corresponding illumination of a specific angle of view in the three-dimensional grid . For flash damage , The light source is placed in the position of the camera , And for shadow damage , It is placed in randomly different positions outside the camera shell . Again , For multiple light damage , We calculate the illuminance of a group of random light sources with different positions and brightness .
video : In the process of video processing and streaming media, there will be damage . Use scene 3D , We define the trajectory , Use multiple frames of a single image to create a video , Similar to motion blur . suffer [80] Inspired by the , We generate an average bit rate (ABR) And constant rate factor (CRF) As H.265 Compression artifact of codec , And bit error to capture the damage caused by imperfect video transmission channel . After damaging the video , We choose a single frame as the final damaged image .
The weather : Damage reduces visibility by masking part of the scene due to interference in the media . We define a single damage , And express it as fog 3D, Distinguish from 2DCC Fog damage in . We use the standard optical model of fog [19, 62, 70].
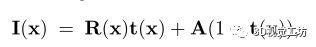
among I(x) It's pixels x Fog image generated at ,R(x) It's a clean image ,A It's atmospheric light ,t(x) Is a transfer function that describes the amount of light reaching the camera . When the medium is homogeneous , Transmission depends on the distance from the camera ,t(x)= exp (-βd(x)) among d(x) Is the depth of the scene ,β Is the attenuation coefficient that controls the fog thickness .
Change of perspective : It is caused by the external factors of the camera and the change of focal length . Our framework can use Blender Rendering is conditional on several variations RGB Images , Such as field of view 、 Camera roll and camera pitch . This enables us to analyze the sensitivity of the model to various view changes in a controllable way . We also generate images with view jitter , It can be used to analyze whether the model prediction will flicker due to the slight change of viewing angle .
semantics : Except for the change of view , We also render the image by selecting an object in the scene and changing its occlusion degree and scale . In shielding damage , We generate a view of an object blocked by other objects . This is different from the unnatural occlusion effect caused by random two-dimensional occlusion of pixels , For example, in [13,48] in ( See the picture 1). The occlusion rate can be controlled , To detect the robustness of the model to occlusion changes . similarly , In scale damage , We render a view of an object at different distances from the camera position . Please note that , These damages require a grid with semantic annotations , And it is automatically generated , Be similar to [2]. This is related to [3] contrary , The latter requires tedious manual operation . Objects can be selected by randomly selecting a point in the scene or using semantic annotation .
noise : The damage came from faulty camera sensors . We introduced the previous 2DCC New noise damage that does not exist in the benchmark . For low light noise , We reduced the pixel intensity and increased Poisson - Gaussian noise , To reflect the low light imaging environment [21].ISO Noise also follows Poisson - Gaussian distribution , There is fixed photon noise ( Take Poisson as the model ), And changing electronic noise ( Take Gauss as the model ). We also use color quantization as another reduction RGB Damage of image bit depth . Only our damaged subset is not based on 3D information .
3.2. The initialization of the 3D Common corrupt data sets
We released all the open source code of our pipeline , This allows us to use the implemented corruption on any data set . As the initial data set , We are 16k Taskonomy[84] Damage is applied to the test image . For all damage , Except for those views and semantics that change the scene , We followed 2DCC The agreement , And defined 5 Shift intensity , Produced about 100 Ten thousand damaged images (16k×14×5). Directly apply these methods to produce damage , It will lead to a conflict with 2DCC Compared to the uncalibrated shift intensity . therefore , In order to be able to communicate with 2DCC Make unified comparison on more uniform strength change , We carried out a calibration step . For in 2DCC Damage directly corresponding to , For example, motion blur , We are 3DCC The damage level is set in , Make the 2DCC Each displacement intensity in , Average of all images SSIM[73] The value is the same in both benchmarks . For in 2DCC There is no corresponding damage in , We adjust the deformation parameters to increase the displacement intensity , At the same time, keep it similar to others SSIM Within the scope of . For view changes and semantics , We render with smoothly varying parameters 32k Images , Such as rolling angle , Use Replica[65] Data sets . chart 4 Examples of damage with different displacement strengths are shown .

3.3. take 3DCC Applied to standard visual datasets
Although we use a dataset with complete geometric information of the scene , Such as Taskonomy[84], but 3DCC It can also be applied to standard datasets without 3D information . We are ImageNet[12] and COCO[39] Examples on the validation set , utilize MiDaS[55] Depth prediction of the model , This is a state-of-the-art depth estimator . chart 5 It shows that it has near focus 、 Examples of images with far focus and foggy three-dimensional damage . The generated image is physically reasonable , This shows that 3DCC It can be used by the community for other data sets , To generate a diverse set of image corruption . In the 5.2.4 In the festival , We quantitatively demonstrate the use of prediction depth to generate 3DCC The effectiveness of the .

Four 、3D Data to enhance
Although the benchmark uses damaged images as test data , But people can also use them as the enhancement value of training data , To establish invariance against these damages . That's what it is for us , Because with 2DCC Different ,3DCC Is designed to capture damage that is more likely to occur in the real world , Therefore, it also has a reasonable enhancement value .
therefore , Besides using 3DCC Perform robustness benchmarking , Our framework can also be seen as New data enhancement strategies , take 3D The geometry of the scene is taken into account . In our experiment , We use the following damage types for enhancement : The depth of field 、 Camera motion and lighting . These enhancements can be effectively generated by using parallel implementation in the training process . for example , The depth of field is enhanced in a single V100 GPU Upper needs 0.87 second ( Clock time ), Batch size is 128 Zhang 224×224 Resolution image . As a comparison , Applying two-dimensional defocus blur averaging requires 0.54 second . You can also pre calculate some selected parts of the enhancement process , For example, illumination enhanced illumination , To improve efficiency . We have incorporated these mechanisms into our implementation . We are the first 5.3 It is shown in section , These enhancements can Significantly improve robustness to the real world .
5、 ... and 、 experiment
We did an assessment , prove 3DCC It can expose 2DCC Unable to capture the model ( The first 5.2.1 section ) Loopholes in ( The first 5.2.2 section ). The generated damage is similar to expensive real-world synthetic damage ( The first 5.2.3 section ), It is applicable to datasets without 3D information ( The first 5.2.4 section ) And semantic tasks ( The first 5.2.5 section ). Last , The proposed 3D data enhancement improves robustness in terms of quality and quantity ( The first 5.3 section ). Please refer to the project page , Learn about real-time demonstrations and broader qualitative results .
5.1. preface
Evaluation task :3DCC It can be applied to any data set , Without considering the target task , For example, dense regression or low dimensional classification . ad locum , We mainly use surface normal and depth estimation as target tasks widely adopted by the community . We noticed that , Compared with classified tasks , The robustness of models for solving such tasks has not been fully explored ( See the first 5.2.5 Section on the results of panoramic segmentation and object recognition ). To evaluate robustness , We calculated the relationship between the predicted image and the real image on the ground L1 error .
Training details : We are Taskonomy[84] Training UNet[59] and DPT[54] Model , Use the learning rate 5×10-4 And weight attenuation 2×10-6. We use AMSGrad[56] Optimize the likelihood loss with Laplace prior , follow [79]. Unless otherwise specified , All models use the same UNet skeleton ( Pictured 6). We also tested in Omnidata[17] Trained on DPT Model , The model mixes diverse training data sets . according to [17], We use the learning rate 1×10-5、 Weight falloff 2×10-6 And angle &L1 Lose to train .
5.2. 3D Common damage benchmarks
5.2.1 3DCC Will expose loopholes
We compare the existing models with 3DCC Benchmarking , To understand its vulnerability . However , We noticed that , Our main contribution is not the analysis , It's the benchmark itself . The most advanced models may change over time , and 3DCC The purpose of is to identify robustness trends , Similar to other benchmarks .
Impact of robustness mechanism : chart 6 It shows that different robustness mechanisms are 3DCC Average performance on surface normals and depth estimation tasks . The performance of these mechanisms is better than the baseline , However, compared with the performance of cleaning data, there is still a big gap . This shows that 3DCC It exposes the problem of robustness , It can be used as a challenging test platform for the model .2DCC Enhance the... Returned by the model L1 The error is slightly lower , It shows that diversified two-dimensional data enhancement only partially helps combat three-dimensional damage .
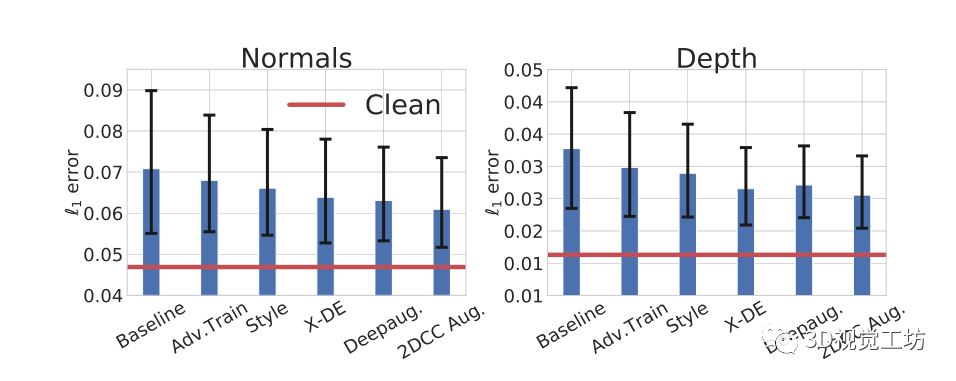
The existing robustness mechanism is found to be insufficient to solve the problem caused by 3DCC Approximate real-world damage problems . Displayed in 3DCC Models with different robustness mechanisms under surface normals ( Left ) And depth ( Right ) Estimate performance in the task . All models here are UNets, And with Taskonomy Data training . Each bar chart shows all 3DCC Average damage L1 error ( The lower the better ). The black error bar shows the error under the lowest and highest displacement intensity . The red line indicates that the baseline model is clean ( Undamaged ) Data performance . This represents the existing robustness mechanism , Including those mechanisms with different enhancements , stay 3DCC Poor performance under .
The impact of data sets and architectures : We are in the picture 7 Chinese vs 3DCC The performance of is decomposed in detail . We first observed that , stay Taskonomy The baseline of last training UNet and DPT The model has similar performance , Especially in view change damage . By using Omnidata It's bigger 、 More diverse data for training ,DPT Has been improved . Similar observations have been made on the visual converter used for classification [5, 16]. This improvement is obvious when the view changes , For other damages , The error is from 0.069 Down to 0.061. This shows that , Combine the progress of architecture with a variety of large-scale training data , Can be in confrontation 3DCC Plays an important role in robustness . Besides , When combined with 3D enhancement technology , They can improve the robustness against damage in the real world ( The first 5.3 section ).
5.2.2 3DCC and 2DCC Damaged redundancy in
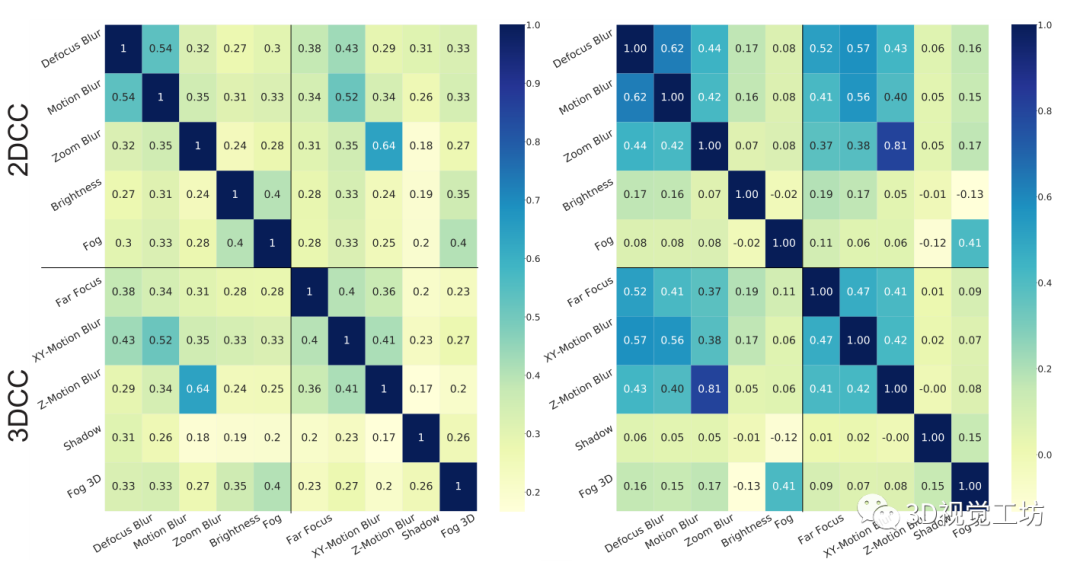
In the figure 1 in , Yes 3DCC and 2DCC A qualitative comparison is made . The former produces more real damage , The latter does not take into account the three-dimensional nature of the scene , Instead, the image is modified uniformly . In the figure 8 in , We aim to quantify 3DCC and 2DCC Similarity between . In the figure 8 Left side , We calculate the baseline model for a corrupted subset ( The whole set is in the supplementary documents ) Between cleaning done and damage prediction L1 Correlation of errors .3DCC Within the benchmark and with 2DCC It produces less correlation than both (2DCC-2DCC The average correlation of 0.32,3DCC-3DCC by 0.28, and 2DCC-3DCC by 0.30). A similar conclusion is obtained for depth estimation ( In the supplementary document ). On the right , We calculate the difference between the clean image and the damaged image L1 error , Yes RGB The same analysis is carried out for the domain , Again 3DCC The resulting correlation is low .
therefore ,3DCC There is a diverse set of damages , These damages are related to 2DCC There is no obvious overlap .
5.2.3 sanity :3DCC With expensive synthetic technology
3DCC The purpose of is to expose the vulnerability of the model in some real-world damage . This requires that 3DCC The generated damage is similar to the real damage data . Because the data that generates this tag is expensive , And there are few , As a proxy evaluation , Instead, we will 3DCC The authenticity of Adobe After Effects(AE) The synthesis of , The latter is a commercial product , Used to generate high-quality realistic data , Often rely on expensive manual processes . To achieve this , We used Hypersim[58] Data sets , It has high resolution z-depth label . And then we use 3DCC and AE Generated 200 A close-up and long-range image . chart 9 The image samples generated by two methods are shown , They are similar in perception . Next , We calculated when the input comes from 3DCC or AE when , Prediction error of baseline normal model . chart 10 given '1' Scatter plot of error , It shows that there is a strong correlation between the two methods , by 0.80. For calibration and control , We also provide information from 2DCC To show the importance of Correlation . They are associated with AE Phase of 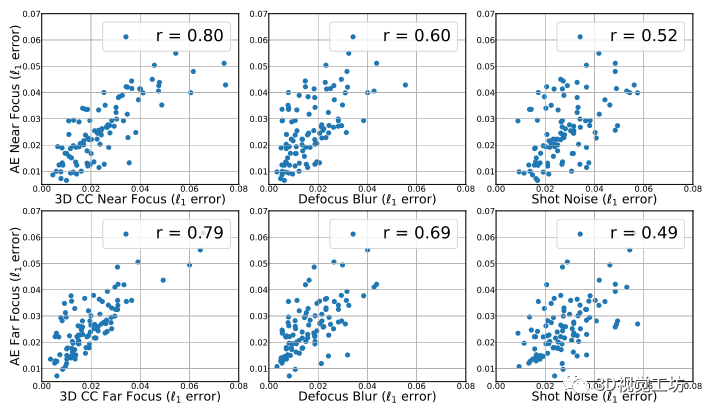
 The relevance is obviously low , Show pass 3DCC The depth of field effect produced is similar to AE The resulting data matches well .
The relevance is obviously low , Show pass 3DCC The depth of field effect produced is similar to AE The resulting data matches well .
5.3. 3D data enhancement to improve robustness
We have proved the effectiveness of the proposed enhancement measures in terms of quality and quantity . We evaluated the situation in Taskonomy Trained on UNet and DPT Model (T+UNet, T+DPT) And in Omnidata Trained on DPT(O+DPT), To understand the impact of training data sets and model structures . The training process is as follows 5.1 Section . For other models , We from O+DPT Model initialization , And on this basis 2DCC enhance (O+DPT+2DCC) and 3D enhance (O+DPT+2DCC+3D) Training for , That is, our proposed model .
We also use from [83] Serial task consistency (X-TC) Constraints further train the proposed model , In the result, it is expressed as (Ours+X-TC). Last , We evaluated the use of data from [9] Of OASIS Training data training model (OASIS).
Qualitative evaluation : We have considered i. OASIS Verify the image [9],ii. 5.2.3 Section AE Corrupt data ,iii. Manually collected DSLR data , as well as iv. Wild Y ouTube video . chart 12 Show , Compared to the baseline , The prediction made by the proposed model is obviously more robust . We also recommend watching these clips and running the live demo on the project page .

Quantitative evaluation : In the table 1 in , We calculated the model in 2DCC、3DCC、AE and OASIS Verification set ( No trim ) The error on the surface . Again , The proposed model produces low errors on different data sets , Shows the enhanced effectiveness . Please note that , Without sacrificing field cleaning data ( namely OASIS) In the case of performance , The robustness to corrupted data is improved .

6、 ... and 、 Summary and deficiency
We introduce a framework to test and improve the robustness of the model to real-world distribution changes , Especially those distribution changes centered on three dimensions . Experiments show that , The proposed 3D Co damage is a challenging benchmark , It exposes the vulnerability of the model to credible damage in the real world . Besides , Compared to the baseline , The proposed data enhancements have led to stronger forecasts . We believe that this work demonstrates the role of three-dimensional damage in benchmarking and training , It opens up a promising direction for robustness research . Let's briefly discuss some limitations .
3D quality :3DCC suffer 3D Upper limit of data quality . As we have shown , current 3DCC It's for the real world 3D Damaged imperfect but useful approximation . With higher resolution sensory data and better depth prediction models , Fidelity is expected to improve .
Non exhaustive set : Our group 3D Damage and enhancement are not exhaustive . contrary , They are starting sets for researchers to experiment . The framework can be used to generate more domain specific distribution transformations , And with minimal human effort .
Large scale assessment : Although we have evaluated some recent robustness methods in our analysis , But our main goal is to show 3DCC Successfully exposed loopholes . therefore , A comprehensive robustness analysis is beyond the scope of this work . We encourage researchers to test their models against our damage .
Balance benchmark : We did not explicitly balance the types of damage in our benchmark , For example, there is the same amount of noise and fuzzy distortion . Our work can further benefit from weighting strategies that try to calibrate the average performance of the damaged benchmark , Such as [37].
Expanded use cases : Although we focus on robustness , But investigate their use in other applications , Such as self supervised learning , It may be worth it .
Assessment task : We experimented with intensive regression tasks . However ,3DCC It can be applied to different tasks , Including classification and other semantic tasks . Use our framework to investigate the failure cases of semantic models , For example, the smooth changing occlusion rate of several objects , Can provide useful insights .
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
16. be based on Open3D Introduction and practical tutorial of point cloud processing
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute

▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- 银河证券在网上开户安全吗?
- Leetcode brush question: binary tree 13 (the same tree)
- How to retrieve the root password of MySQL if you forget it
- CCPC 2021威海 - G. Shinyruo and KFC(组合数,小技巧)
- ROS2专题【01】:win10上安装ROS2
- 14、Transformer--VIT TNT BETR
- 【数字IC验证快速入门】1、浅谈数字IC验证,了解专栏内容,明确学习目标
- CVPR 2022 | 常见3D损坏和数据增强
- Leetcode skimming: binary tree 17 (construct binary tree from middle order and post order traversal sequence)
- 【数字IC验证快速入门】8、数字IC中的典型电路及其对应的Verilog描述方法
猜你喜欢

leetcode刷题:二叉树12(二叉树的所有路径)

Leetcode brush questions: binary tree 11 (balanced binary tree)

关于BRAM IP复位的优先级
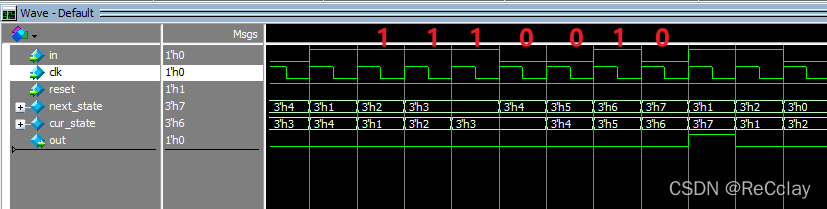
【数字IC验证快速入门】9、Verilog RTL设计必会的有限状态机(FSM)
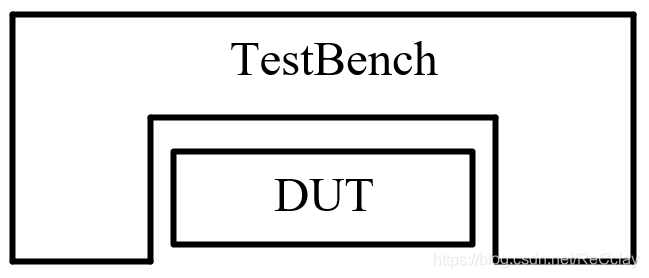
【数字IC验证快速入门】6、Questasim 快速上手使用(以全加器设计与验证为例)
Wechat applet regular expression extraction link
CTF逆向基础
CVPR 2022 | 常见3D损坏和数据增强
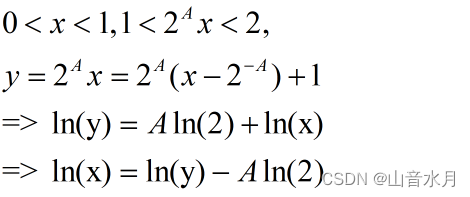
计算lnx的一种方式
PyTorch 1.12发布,正式支持苹果M1芯片GPU加速,修复众多Bug
随机推荐
Schema和Model
基金网上开户安全吗?去哪里开,可以拿到低佣金?
Go language | 02 for loop and the use of common functions
Introduction to dead letter queue (two consumers, one producer)
IC科普文:ECO的那些事儿
19 Mongoose模块化
处理文件和目录名
Notes on key vocabulary in the English original of the biography of jobs (12) [chapter ten & eleven]
Rainbow 5.7.1 supports docking with multiple public clouds and clusters for abnormal alarms
信息学奥赛一本通 1340:【例3-5】扩展二叉树
c語言oj得pe,ACM入門之OJ~
leetcode刷题:二叉树15(找树左下角的值)
1: Citation;
本季度干货导航 | 2022年Q2
Go language learning tutorial (16)
Leetcode: binary tree 15 (find the value in the lower left corner of the tree)
sun.misc.BASE64Encoder报错解决方法[通俗易懂]
[C language] merge sort
Process file and directory names
CVPR 2022 | 常见3D损坏和数据增强