当前位置:网站首页>Mongodb persistence
Mongodb persistence
2022-06-29 09:19:00 【amateur12】
The default is persistent
stay 1.8 Support after version journal, That's what we often say redo log, For fault recovery and persistence
stay 2.0 Later versions ,journal It's all on by default , To ensure data security
The illustration :

The write operation records journal journal , Record the disk address and bytes specifically changed by the write operation ( If the server suddenly crashes , Startup time ,journal Will replay writes that were not flushed to disk before crash )
Data files every 60s Refresh to disk ,journal Just hold 60s Write data in .journal Several empty files are pre allocated for this purpose , be located /data/db/journal, Name it _j.0,_j.1 etc. .
MongoDB Running for a long time , stay journal Under the table of contents , You'll see something like _j.6217,_j.6218 and _j.6219 file . These files are current journal file , If MongoDB Has been running , These figures will continue to increase . When normally closed MongoDB when , These files will be cleared , Because these logs are no longer required for normal shutdown .
If the server crashes or kill -9, mongodb On restart , Will replay journal file , It will output long and difficult inspection lines , This indicates that in normal recovery .
mongod.lock file , When running in disabled journal Under the circumstances , It is very important .
When normally closed mongod when , Will clear mongod.lock file , The next time you start, you know that the last time was completely closed . contrary , If lock The file was not purged ,mongod No normal shutdown .
If mongod No normal shutdown detected , You need to copy a copy of the data . However , Some people have realized that , You can delete this lock File to bypass this check . however , Don't do that . Delete at startup lock Files mean that you don't know or care if your data has been corrupted . Except in this case , Please respect lock file .
After the write command in memory reaches a certain time or space , Write to the log file in the log system , Then the contents in the log file reach a certain time , Sync to data file , So as to ensure the persistence of data
Sync from memory to hard disk , If strong persistence is guaranteed , This will reduce the writing capacity ; If you do not set strong persistence , The possibility of data loss ; Only balance between the two , The time interval between synchronizing the write command to the log should be minimized
Implement a more durable approach :
1. adopt getLastError Pass on j Options , The diary will only wait for 30 millisecond , Not the default 100 millisecond
db.one.insert({title:'123',content:'456'})
db.runCommand({"getLastError":1,'j':true})Log writes are asynchronous , By default, it will not return until the data is written , It is successful to return to the client, but its writing is not necessarily successful , By using getLastError Command to ensure that writing is successful
notes : If used getLastError Medium j The options are true, Is actually limited to writes per second 33 Time .(1 Time /30 millisecond )* (1000 millisecond / second ) = 33.3 Time / second . If allowed mongodb Bulk write to most of the data , Instead of committing each write individually , be mongodb Performance will be better .
So with optimization
Commit a write operation , All previous operations will be submitted
namely : Corresponding 50 Write operations , front 49 Use getLastError in ”j”=false Normal operation of , Last use getLastError in j=true The operation of , If it works , You know 50 Write times have been safely written to the disk
2. Set the log submission interval
every other 10 MS writes the write data to the log file
db.adminCommand({"setParameter":1,"journalCommitInterval":10});journalCommitInterval The value range of the parameter is 2-500 millisecond ; The smaller the value , The less data you lose ;
No matter how much time interval is set , use ”j”:true Option getLastError The command will reduce the value to the original value 1/3
The only case where client write operations are restricted :
If the write speed of the client exceeds the refresh speed of the log ,mongodb Will restrict write operations , Know that the journal finishes writing to the disk
Add :
When the system starts , Will map the data file to a memory area , be called Shared view, In an open journal In the system , Data is written directly to shared view, Then return , Every time the system 60s Refresh this memory to disk , such , If there is a power failure or down machine , You lose a lot of data that is not persistent in memory .
When the system is turned on journal function , The system will map another memory area for journal Use , be called private view,mongodb The default for each 100ms Refresh privateView To journal, in other words , Power down or down , It's possible to lose this 100ms data , It's generally tolerable , If you can't stand it , Then program it log Well . That's why it turns on journal after mongod Use twice as much virtual memory as before .
Mongodb The isolation level is read_uncommitted, Use it or not journal, Are based on the data in memory , It's just , Don't open journal, Data from shared view Read , Turn on journal, Data from private view Read .
In the open journal In the system , The write operation goes through from request to writing to disk 5 A step , stay serverStatus() The time consumed by each step has been listed in .
①、Write to privateView
②、prepLogBuffer
③、WritetoJournal
④、WritetoDataFile
⑤、RemaptoPrivateView
summary :
Use journal after , Backup , Disaster recovery is guaranteed , Batch commit also makes writing faster . We also need to choose advanced file systems, disks and more memory to ensure journal Good operation of .
边栏推荐
猜你喜欢

H5软键盘问题

AugFPN:改进多尺度特征学习用于目标检测

Unity C # e-learning (12) -- protobuf generation protocol
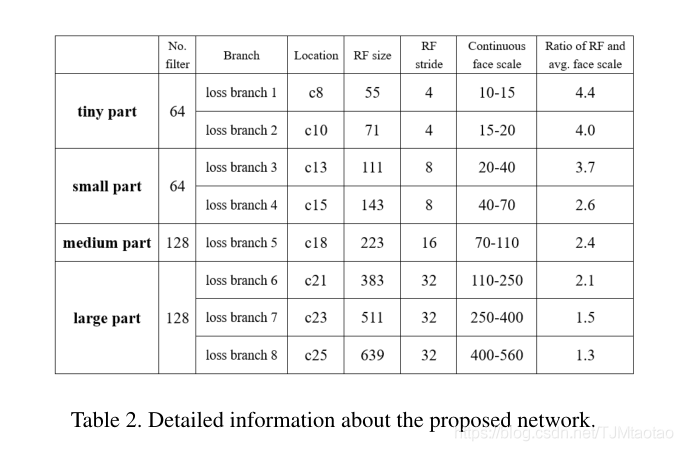
LFFD:一种用于边缘检测的轻量化快速人脸检测器

NPM common commands
调试H5页面-weinre及spy-debugger真机调试

Open3d farthest point sampling (FPS)

First electric shock, so you are such a dragon lizard community | dragon lizard developer said that issue 8

来个小总结吧
记自定义微信小程序顶部导航栏
随机推荐
Verilog reduction operator
mysql insert 时出现Deadlock死锁场景分析
YOLACT实时实例分割
Keras to tf Vgg19 input in keras_ shape
npm常用命令
Open3d hidden point removal
Detailed version of two-stage target detection principle
Working for many years, recalling life -- three years in high school
什么是超融合?与传统架构有什么区别?.
HB5470民用飞机机舱内部非金属材料燃烧测试
深卷积神经网络时代的目标检测研究进展
MySQL virtual column
微信小程序自定义多项选择器
Did you really make things clear when you were promoted or reported?
Analysis of c voice endpoint detection (VAD) implementation process
MYSQL虚拟列
Mqtt second session -- emqx high availability cluster implementation
What is hyperfusion? What is the difference with traditional architecture
记微信小程序setData动态修改字段名
train_on_batch保存一下loss函数变化的图像