当前位置:网站首页>pytorch总结—自动求梯度
pytorch总结—自动求梯度
2022-06-29 08:31:00 【TJMtaotao】
对函数求梯度(gradient)。PyTorch提供的autograd 包能够根据输⼊和前向传播过程自动构建计算图,并执⾏行反向传播。
Tensor 是这个包的核心类,如果将其属性 .requires_grad 设置为 True ,它将开始追
踪(track)在其上的所有操作(这样就可以利利⽤用链式法则进⾏行行梯度传播了了)。完成计算后,可以调
⽤用 .backward() 来完成所有梯度计算。此 Tensor 的梯度将累积到 .grad 属性中。
注意在 y.backward() 时,如果 y 是标量量,则不需要为 backward() 传⼊入任何参数;否则,需要
传⼊一个与 y 同形的 Tensor
如果不想要被继续追踪,可以调⽤ .detach() 将其从追踪记录中分离出来,这样就可以防⽌将来的计
算被追踪,这样梯度就传不过去了。此外,还可以用 with torch.no_grad() 将不不想被追踪的操作代
码块包裹起来,这种方法在评估模型的时候很常用,因为在评估模型时,我们并不需要计算可训练参数
( requires_grad=True )的梯度。
Function 是另外⼀个很重要的类。 Tensor 和 Function 互相结合就可以构建一个记录有整个计算过
程的有向无环图(DAG)。每个 Tensor 都有⼀一个 .grad_fn 属性,该属性即创建该 Tensor 的
Function , 就是说该 Tensor 是不是通过某些运算得到的,若是,则 grad_fn 返回⼀一个与这些运算相
关的对象,否则是None。
TENSOR
创建一个 Tensor 并设置 requires_grad=True :
x = torch.ones(2, 2, requires_grad=True)
print(x)
print(x.grad_fn)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
None
再做一下运算操作:
y = x + 2
print(y)
print(y.grad_fn)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward>)
<AddBackward object at 0x1100477b8>
注意x是直接创建的,所以它没有 grad_fn , 而y是通过⼀一个加法操作创建的,所以它有一个为
<AddBackward> 的 grad_fn 。像x这种直接创建的称为叶子节点,叶子节点对应的 grad_fn 是 None 。
print(x.is_leaf, y.is_leaf) # True False
再来点复杂度运算操作:
z = y * y * 3
out = z.mean()
print(z, out)
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward>) tensor(27., grad_fn=
<MeanBackward1>)
通过 .requires_grad_() 来用in-place的⽅式改变 requires_grad 属性:
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad) # False
a.requires_grad_(True)
print(a.requires_grad) # True
b = (a * a).sum()
print(b.grad_fn)
False
True
<SumBackward0 object at 0x118f50cc0>
梯度
因为 out 是⼀一个标量,所以调用 backward() 时不需要指定求导变量:
out.backward() # 等价于 out.backward(torch.tensor(1.))
我们来看看 out 关于 x 的梯度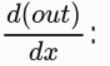
print(x.grad)
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
我们令 out 为o , 因为



而 torch.autograd 这个包就是用来计算⼀些雅克比矩阵的乘积的。
例例如,如果 v是⼀个标量函数的

那么根据链式法则我们有 ![]() 关于
关于![]() 的雅克⽐矩阵就为:
的雅克⽐矩阵就为:

注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运⾏行反向传播,梯度都会累
加之前的梯度,所以⼀般在反向传播之前需把梯度清零。
再来反向传播一次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
tensor([[5.5000, 5.5000],
[5.5000, 5.5000]])
tensor([[1., 1.],
[1., 1.]])
边栏推荐
猜你喜欢

YOLO Nano:一种高度紧凑的只看一次的卷积神经网络用于目标检测

Keras to tf Vgg19 input in keras_ shape

一般乘法器设计,verilog code
General multiplier design, verilog code

mysql insert 时出现Deadlock死锁场景分析

记微信小程序setData动态修改字段名

打印服务IP设置方案

【目标检测】|指标 A probabilistic challenge for object detection

Mqtt second session -- emqx high availability cluster implementation

笔试题“将版本号从大到小排列”
随机推荐
Handwritten virtualdom
NPM common commands
DevOps到底是什么意思?
15 things to learn in a year of internship in famous enterprises, so you can avoid detours.
Debugging H5 page -weinre and spy debugger real machine debugging
Macros, functions, and inline functions
Pointnet/pointnet++ training and testing
微信小程序跳转公众号图文内容
promise方法的简单使用
Verilog 拼接操作符号
General multiplier design, verilog code
PointNet/Pointnet++训练及测试
ThinkPHP 6 使用 mongoDB
Mysql使用union all统计多张表组合总数,并分别统计各表数量
keras转tf.keras中VGG19 input_shape
来个小总结吧
微信小程序最新canvas2d手写签名
[to.Net] C data model, from Entity Framework core to LINQ
Wechat applet jump to official account image and text content
Verilog size and +: Using