当前位置:网站首页>2020-08-17: how to solve data skew in detail?
2020-08-17: how to solve data skew in detail?
2020-11-06 21:55:00 【Fuda Dajia architect's daily question】
Fogo's answer 2020-08-17:
Data skew is an obstacle in the field of big data , When the amount of data you need to process reaches hundreds of millions or even hundreds of billions , Data skew will be a huge hurdle in front of you . It's possible that for weeks or even months, you'll have to worry about all kinds of weird problems caused by data skew .
Data skew means :mapreduce When the program is executed ,reduce The nodes are mostly executed , But there is one or several reduce Nodes run slowly , This results in a long processing time for the entire program , That's because of one key The number of bars of key A lot more ( Sometimes a hundred or a thousand times more ), This article key Where reduce Nodes handle much more data than other nodes , This causes a few nodes to run late .Hive The implementation of is staged ,map The difference in the amount of data processed depends on the last stage Of reduce Output , So how to distribute the data evenly to each reduce in , That's the key to data skew .
Here are some common data skew scenarios :
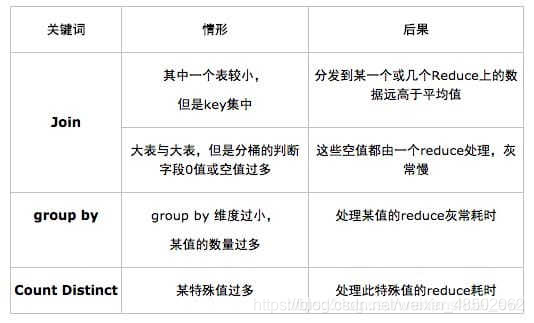
One 、Group by tilt
group by The resulting tilt is relatively easy to solve .hive Two parameters are provided to solve the problem :
1.1 hive.map.aggr
One is hive.map.aggr, The default value is already true, He means to do map aggregation, That is to say mapper There's aggregation in it . This method is different from writing directly mapreduce It can be achieved when combiner, But something like combiner The effect of . In fact, it's based on mr The framework of is pig,cascading Wait a minute. It's all map aggregation( Or call it partial aggregation) Instead of combiner The strategy of , That is to say mapper It is used to aggregate directly instead of output to buffer to combiner Do aggregation . about map aggregation,hive And I'll do a check , If aggregation The effect is not good , that hive Will automatically give up map aggregation. The basis for judging the effect is after processing a small batch of data , Check whether the aggregate data volume is reduced to a certain proportion , The default is 0.5, from hive.map.aggr.hash.min.reduction This parameter controls . So if you confirm that there are individual values in the data that are skewed , But most values are sparse , At this time, you can force the ratio to 1, Avoid extreme situations map aggr invalid .hive.map.aggr There are also some related parameters , such as map aggr And so on , Please refer to this article for details .
1.2 hive.groupby.skewindata
Another parameter is hive.groupby.skewindata. This parameter means to do reduce During operation , To get the key Not all the same values are given to the same reduce, It's random distribution , then reduce Do aggregation , Do another round when you're done MR, Take the aggregated data and calculate the result . So this parameter is actually the same as hive.map.aggr Doing something similar , Just get it reduce Come and do it , And an extra round to start job, So I don't recommend it , The effect is not obvious .
1.3 count distinct rewrite
Another thing to note count distinct Operations often need to be rewritten SQL, You can do this as follows :
/* Before rewriting */
select a, count(distinct b) as c from tbl group by a;
/* After rewriting */
select a, count(*) as c from (select a, b from tbl group by a, b) group by a; Two 、Join tilt
2.1 skew join
join The resulting tilt , It's common not to do map join The two tables ( Do map join It can basically avoid tilting ), One of them is the behavior table , The other should be a property sheet . For example, we have three watches , A user property sheet users, A list of product attributes items, There is also a user's operation behavior table log table for goods logs. Suppose you now need to associate a behavior table with a user table :
select * from logs a join users b on a.user_id = b.user_id;among logs There will be a special user in the table user_id = 0, On behalf of users who are not logged in , If this kind of user accounts for a considerable proportion , So individual reduce Will receive more than others reduce A lot more data , Because it's going to take in everything user_id = 0 To process the records of , The treatment effect will be very poor , other reduce It's been running for a long time .
hive The solution given is called skew join, The principle of this kind of user_id = 0 The special value of is not in reduce End count out , I'm going to say hdfs, And then start a round map join It's a special value calculation , It is expected to improve the processing speed of calculating this part of the value . Of course you have to tell hive This join It's a skew join, namely :set
hive.optimize.skewjoin = true;
And to tell hive How to judge the special value , according to hive.skewjoin.key Number of settings hive You can know , For example, the default value is 100000, So over 100000 The values of records are special values . Sum up ,skew join The process can be described in the following figure :
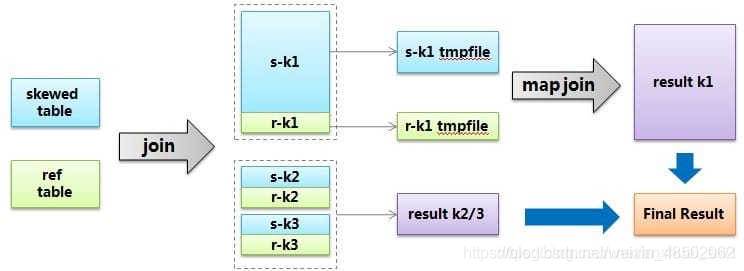
2.2 Special values are treated separately
however , The above method also needs to consider the threshold and so on , It's not universal enough . So for join The question of tilt , It's usually done by rewriting sql solve . For the above question , We already know user_id = 0 It's a special key, Then you can isolate the special values and do it alone join, So the special value will definitely be transformed into map join, The nonspecific value is normal without skew join 了 :
select
*
from
(
select * from logs where user_id = 0
)
a
join
(
select * from users where user_id = 0
)
b
on
a.user_id = b.user_id
union all
select * from logs a join users b on a.user_id <> 0 and a.user_id = b.user_id;2.3 Random number allocation
The above individual key The tilt situation is just a tilt situation . The most common skew is because the data distribution itself has a long tail , For example, we associate the log table with the product table :
select * from logs a join items b on a.item_id = b.item_id;This is the time , Assigned to hot items reducer It's going to be slow , Because the behavior logs of popular products are definitely the most , And it's hard for us to deal with special things like that user Deal with that item. At this time, we will use the method of adding random numbers , That is to say join Add a random number to it , The range of random numbers n Is equivalent to item To spread to n individual reducer:
select
a.*,
b.*
from
(
select *, cast(rand() * 10 as int) as r_id from logs
)
a
join
(
select *, r_id from items lateral view explode(range_list(1, 10)) rl as r_id
)
b
on
a.item_id = b.item_id
and a.r_id = b.r_idIn the above writing , Generate one for each record in the behavior table 1-10 Random integer of , about item Property sheet , Every item Generate 10 Bar record , Random key The difference is also 1-10, This ensures that the behavior table is associated with the property table . among range_list(1,10) For udf Implementation of a return 1-10 The method of integer sequence . This is a solution join Incline to a more fundamental general idea , It's how to use random numbers to make key Spread it out . Of course , You can simplify or change the implementation according to the specific business scenarios .
2.4 Business design
Except for the above two cases , There are also cases where problems are caused by business design , That is to say, even in the behavior log join key The data distribution itself is not significantly skewed , But business design leads to its tilt . For example, for commodities item_id The coding , Except for its own id Sequence , It's also artificial item The type of the code is also placed in the last two digits , So if the type 1( Electronic products, ) The code of is 00, type 2( Home products ) The code of is 01, And the type 1 Is the main commodity category , Will result in 00 For the end of the product overall tilt . At this time , If reduce The amount of is exactly 100 Integer multiple , Can cause partitioner hold 00 At the end of the item_id all hash To the same reducer, Detonating the problem . This special case can be simply set up the appropriate reduce Value to solve , But this kind of pit will be more hidden when you don't know the business .
3、 ... and 、 Typical business scenarios
3.1 Data skew caused by null value
scene : As in the journal , There is often the problem of information loss , Like in the log user_id, If you take one of them user_id and In the user table user_id relation , There's a data skew problem .
resolvent 1: user_id Empty do not participate in association
select
*
from
log a
join users b
on
a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a where a.user_id is null;resolvent 2 : To assign a new value to key value
select
*
from
log a
left outer join users b
on
case
when a.user_id is null
then concat(‘hive’, rand())
else a.user_id
end = b.user_id;Conclusion : Method 2 Comparison method 1 More efficient , Not only io Less , And there's less homework . resolvent 1 in log Read twice ,jobs yes 2. resolvent 2 job The number is 1 . This optimization is not valid id ( such as -99 , ’’, null etc. ) The resulting tilt problem . Put the null key It becomes a string plus a random number , You can divide the slanted data into different reduce On , Solve data skew .
3.2 Data skew is generated by association of different data types
scene : In the user table user_id Field is int,log In the table user_id The fields already have string There are also types of int type . When according to user_id Make two tables Join In operation , default Hash Operation will press int Type id To distribute , This will lead to all string type id All of the records are assigned to a Reducer in .
resolvent : Convert numeric type to string type
select
*
from
users a
left outer join logs b
on
a.usr_id = cast(b.user_id as string)3.3 A small watch is not small , How to use it? map join Solve the tilt problem
Use map join Solve the small watch ( There are few records ) Data skew problem of associated large tables , This method is used very frequently , But if the small watch is big , As big as map join There will be bug Or abnormal , At this time, special treatment is needed . Following example :
select * from log a left outer join users b on a.user_id = b.user_id;users Table has 600w+ The record of , hold users Distribute to all map It's also a big expense , and map join I don't support such a small watch . If you use ordinary join, We will encounter the problem of data skew .
select
/*+mapjoin(x)*/
*
from
log a
left outer join
(
select
/*+mapjoin(c)*/
d.*
from
(
select distinct user_id from log
)
c
join users d
on
c.user_id = d.user_id
)
x on a.user_id = b.user_id;If ,log in user_id There are millions of , This is back to the original map join problem . Fortunately , Daily members uv Not too much , There won't be too many members with deals , There won't be too many members with clicks , There won't be too many members with commissions and so on . So this method can solve the data skew problem in many scenarios .
Four 、 summary
send map The output data of is more evenly distributed to reduce In the middle , It's our ultimate goal . because Hash Limitations of the algorithm , Press key Hash Will more or less cause data skew . A lot of experience shows that the data skew is due to human negligence in table building or business logic can be avoided . Here are some general steps :
1) sampling log surface , Which? user_id It's slanting , Get a result table tmp1. Because for the computational framework , All the data come here , He doesn't know the data distribution , So sampling is not rare .
2) The distribution of data conforms to the statistical rules of sociology , The gap between the rich and the poor . sloping key Not too much , It's like there are not many rich people in a society , There are not many strange people . therefore tmp1 There will be few records . hold tmp1 and users do map join Generate tmp2, hold tmp2 Read distribute file cache. This is a map The process .
3)map Read in users and log, If the record comes from log, Then check user_id Whether in tmp2 in , If it is , Output to local file a, Otherwise, it will generate key,value Yes , If the record comes from member, Generated key,value Yes , Get into reduce Stage .
4) Finally put a file , hold Stage3 reduce Stage output file merge from write hdfs.
If the business needs such slanting logic , Consider the following optimizations :
1) about join, In judging that the small watch is not greater than 1G Under the circumstances , Use map join
2) about group by or distinct, Set up hive.groupby.skewindata=true
3) Try to use the above SQL Statement tuning for optimization
5、 ... and 、 reference
Data analysis series (3): Data skew
版权声明
本文为[Fuda Dajia architect's daily question]所创,转载请带上原文链接,感谢
边栏推荐
- Ora-02292: complete constraint violation (midbjdev2.sys_ C0020757) - subrecord found
- 2020-08-20:GO语言中的协程与Python中的协程的区别?
- Flink's datasource Trilogy: direct API
- 2020-08-15:什么情况下数据任务需要优化?
- MRAM高速缓存的组成
- The native API of the future trend of the front end: web components
- The role of theme music in games
- Countdown | 2020 PostgreSQL Asia Conference - agenda arrangement of Chinese sub Forum
- Why is the LS command stuck when there are too many files?
- What grammar is it? ]
猜你喜欢

To teach you to easily understand the basic usage of Vue codemirror: mainly to achieve code editing, verification prompt, code formatting
Summary of front-end performance optimization that every front-end engineer should understand:
Erd-online free online database modeling tool
STM32F030K6T6兼容替换灵动MM32F031K6T6
Method of code refactoring -- Analysis of method refactoring
[forward] how to view UserData in Lua
Those who have worked in China for six years and a million annual salary want to share these four points with you
2020-09-04:函数调用约定了解么?
A small goal in 2019 to become a blog expert of CSDN
统计项目代码行数
随机推荐
Some operations kept in mind by the front end foundation GitHub warehouse management
Introduction to the development of small game cloud
实用工具类函数(持续更新)
Basic usage of Vue codemirror: search function, code folding function, get editor value and verify in time
Windows 10 蓝牙管理页面'添加蓝牙或其他设备'选项点击无响应的解决方案
The Interpreter pattern of behavior pattern
NAND FLASH的接口控制设计
2020-08-29:进程线程的区别,除了包含关系之外的一些区别,底层详细信息?
How to prepare for the system design interview
How to make characters move
递归、回溯算法常用数学基础公式
How about small and medium-sized enterprises choose shared office?
移动端像素适配方案
DC-1 target
How to play sortable JS vuedraggable to realize nested drag function of forms
Code generator plug-in and creator preform file analysis
2020 database technology conference helps technology upgrade
Nodejs中使用jsonwebtoken(JWT)生成token的场景使用
es创建新的索引库并拷贝旧的索引库 实践亲测有效!
Pn8162 20W PD fast charging chip, PD fast charging charger scheme