## background Big data has developed so far , according to Google 2003 Released in 《The Google File System》 The first paper starts with , Have passed by 17 Years . It is a pity Google There was no open source technology ,“ Just ” Three technical papers have been published . So look back , It can only be regarded as opening the curtain of the era of big data . With Hadoop The birth of , Big data has entered an era of rapid development , The dividend and commercial value of big data are also being released . Nowadays, the demand for big data storage and processing is becoming more and more diversified , After Hadoop Time , How to build a unified data Lake storage , And carry on various forms of data analysis on it , It has become an important direction for enterprises to construct big data ecology . How fast 、 Agreement 、 To construct atomically on the data Lake storage Data Pipeline, It has become an urgent problem to be solved . And with the advent of the cloud age , The cloud's inherent ability to automate deployment and delivery is also catalyzing this process . This article mainly introduces how to use [Iceberg](https://iceberg.apache.org/) And Kubernetes Create a new generation of cloud data lake . ## What is Iceberg > Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table. [Apache Iceberg](https://github.com/apache/iceberg) By Netflix Open source development , As for 2018 year 11 month 16 The day enters Apache The incubator , yes Netflix Company data warehouse basis .Iceberg It's essentially a tabular standard designed for massive analysis , It can be a mainstream computing engine such as Presto、Spark To provide efficient read-write and meta data management capabilities .Iceberg Don't care about the underlying storage ( Such as HDFS) And table structure ( Business definition ), It provides an abstraction layer between the two , Organizing data and meta data . Iceberg Key features include : - ACID: Have ACID Ability , Support row level update/delete; Support serializable isolation And multiple concurrent writers - Table Evolution: Support inplace table evolution(schema & partition), Iconicity SQL Same operation table schema; Support hidden partitioning, The user does not need to display the specified - Interface generalization : Provide rich table operation interface for upper data processing engine ; Mask underlying data storage format differences , To provide for Parquet、ORC and Avro Format support Depending on the above features ,Iceberg It can help users achieve low cost T+0 Level data Lake . ## Iceberg on Kubernetes In the traditional way , Users usually use manual or semi-automatic methods when deploying and maintaining large data platforms , This often takes a lot of manpower , Stability is not guaranteed .Kubernetes The emergence of , Revolutionized the process .Kubernetes It provides application deployment and operation and maintenance standardization capabilities , The user business is being implemented Kubernetes After transformation , Can be implemented in all other standards Kubernetes Conglomeration . In the field of big data , This capability can help users quickly deploy and deliver large data platforms ( The deployment of large data components is particularly complex ). Especially in the big data computing storage separation architecture ,Kubernetes Cluster provides Serverless Ability , It can help users to perform computing tasks on the fly . And then with the off-line mixed part scheme , In addition to unified management and control of resources to reduce complexity and risk , Cluster utilization will be further improved , Cut costs dramatically . We can base on Kubernetes Build Hadoop Big data platform : 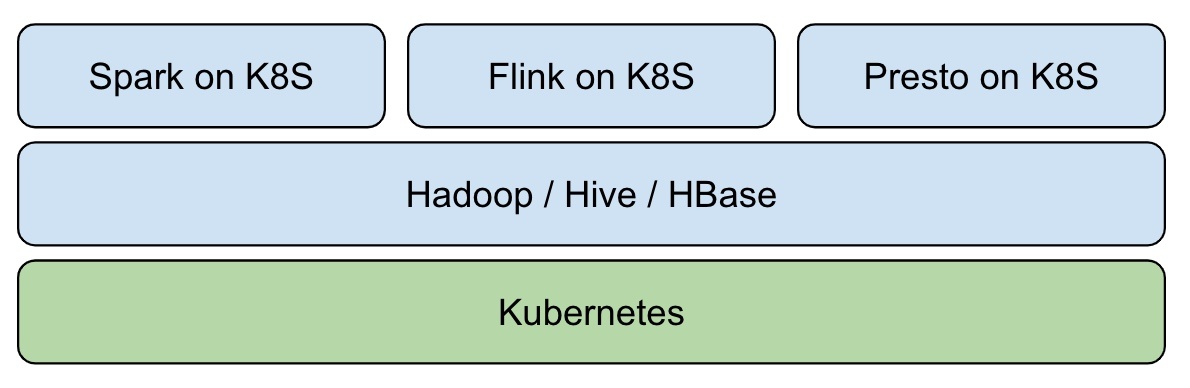 In the field of data lake which has been hot in recent years , Through tradition Hadoop Ecological construction real-time data Lake , Subject to component positioning and Design , More complicated and difficult .Iceberg The emergence of open source technology makes it possible to build a real-time data Lake quickly , This is also the future development direction of big data - Real time analysis 、 Canghu Lake integration and cloud origin . introduce Iceberg After , The overall architecture becomes : 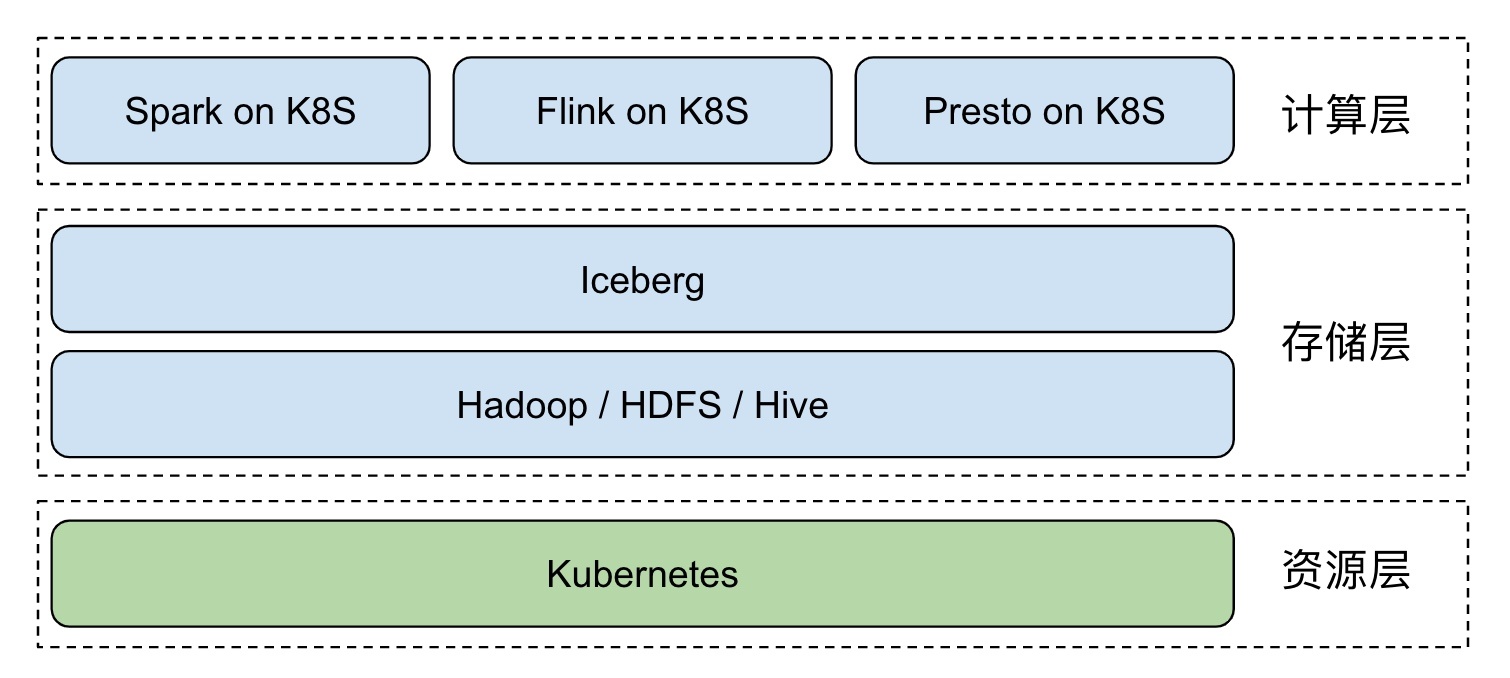 Kubernetes Responsible for application automation deployment and resource management scheduling , It obscures the complexity of the underlying environment for the upper layer .Iceberg + Hive MetaStore + HDFS It is realized on the basis of Hadoop Real time data lake of ecology , Providing data access and storage for big data applications .Spark、Flink Wait for the computing engine to native The way of execution in Kubernetes Conglomeration , Resources are available as soon as they are available . After mixing with online business , It can greatly improve the utilization of cluster resources . ## How to build cloud native real-time data Lake ## Architecture diagram 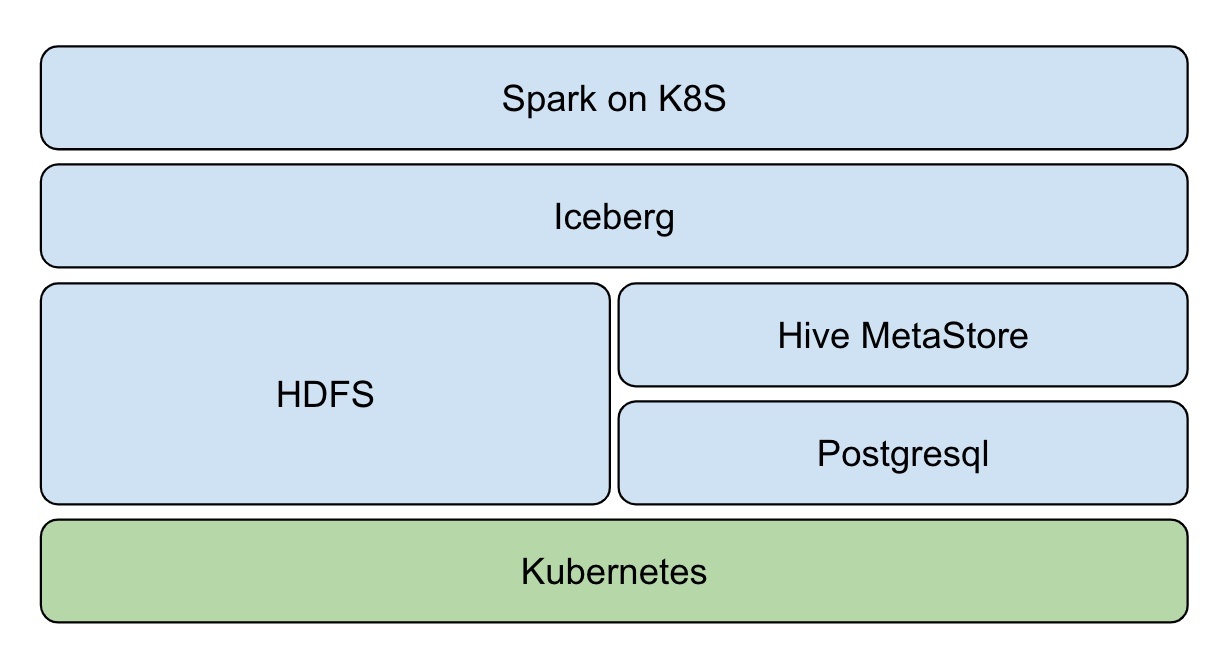 - Resource layer :Kubernetes Provide resource management capabilities - Data layer :Iceberg Provide ACID、table Data set access operation ability - Storage :HDFS Provide data storage capacity ,Hive MetaStore management Iceberg Meta data ,Postgresql As Hive MetaStore Storage back end - Computing layer :Spark native on Kubernetes, Provide streaming batch computing capability ### establish Kubernetes Cluster First, deploy through official binary or automated deployment tools Kubernetes Cluster , Such as [kubeadm](https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/), It is recommended to use Tencent cloud [TKE Cluster ](https://cloud.tencent.com/product/tke).  The recommended configuration is :3 Taiwan S2.2XLARGE16(8 nucleus 16G) For example ### Deploy Hadoop Cluster Open source Helm Plug in or custom image in Kubernetes Upper Department Hadoop Cluster , Main deployment HDFS、Hive MetaStore Components . In Tencent cloud TKE It is recommended to use [k8s-big-data-suite](https://github.com/tkestack/charts/tree/main/incubator/k8s-big-data-suite) Automatic deployment of big data applications Hadoop Cluster .  k8s-big-data-suite It is a large data package developed by US based on our production experience , It can support mainstream big data elements in Kubernetes Last click to deploy . Please follow the requirements before cluster initialization : ``` # Identify the storage node , At least three $ kubectl label node xxx storage=true ``` After successful deployment , Link in TKE Cluster view component status : ``` $ kubectl get po NAME READY STATUS RESTARTS AGE alertmanager-tkbs-prometheus-operator-alertmanager-0 2/2 Running 0 6d23h cert-job-kv5tm 0/1 Completed 0 6d23h elasticsearch-master-0 1/1 Running 0 6d23h elasticsearch-master-1 1/1 Running 0 6d23h flink-operator-controller-manager-9485b8f4c-75zvb 2/2 Running 0 6d23h kudu-master-0 2/2 Running 2034 6d23h kudu-master-1 2/2 Running 0 6d23h kudu-master-2 2/2 Running 0 6d23h kudu-tserver-0 1/1 Running 0 6d23h kudu-tserver-1 1/1 Running 0 6d23h kudu-tserver-2 1/1 Running 0 6d23h prometheus-tkbs-prometheus-operator-prometheus-0 3/3 Running 0 6d23h superset-init-db-g6nz2 0/1 Completed 0 6d23h thrift-jdbcodbc-server-1603699044755-exec-1 1/1 Running 0 6d23h tkbs-admission-5559c4cddf-w7wtf 1/1 Running 0 6d23h tkbs-admission-init-x8sqd 0/1 Completed 0 6d23h tkbs-airflow-scheduler-5d44f5bf66-5hd8k 1/1 Running 2 6d23h tkbs-airflow-web-84579bc4cd-6dftv 1/1 Running 2 6d23h tkbs-client-844559f5d7-r86rb 1/1 Running 6 6d23h tkbs-controllers-6b9b95d768-vr7t5 1/1 Running 0 6d23h tkbs-cp-kafka-0 3/3 Running 2 6d23h tkbs-cp-kafka-1 3/3 Running 2 6d23h tkbs-cp-kafka-2 3/3 Running 2 6d23h tkbs-cp-kafka-connect-657bdff584-g9f2r 2/2 Running 2 6d23h tkbs-cp-schema-registry-84cd7cbdbc-d28jk 2/2 Running 4 6d23h tkbs-grafana-68586d8f97-zbc2m 2/2 Running 0 6d23h tkbs-hadoop-hdfs-dn-6jng4 2/2 Running 0 6d23h tkbs-hadoop-hdfs-dn-rn8z9 2/2 Running 0 6d23h tkbs-hadoop-hdfs-dn-t68zq 2/2 Running 0 6d23h tkbs-hadoop-hdfs-jn-0 2/2 Running 0 6d23h tkbs-hadoop-hdfs-jn-1 2/2 Running 0 6d23h tkbs-hadoop-hdfs-jn-2 2/2 Running 0 6d23h tkbs-hadoop-hdfs-nn-0 2/2 Running 5 6d23h tkbs-hadoop-hdfs-nn-1 2/2 Running 0 6d23h tkbs-hbase-master-0 1/1 Running 3 6d23h tkbs-hbase-master-1 1/1 Running 0 6d23h tkbs-hbase-rs-0 1/1 Running 3 6d23h tkbs-hbase-rs-1 1/1 Running 0 6d23h tkbs-hbase-rs-2 1/1 Running 0 6d23h tkbs-hive-metastore-0 2/2 Running 0 6d23h tkbs-hive-metastore-1 2/2 Running 0 6d23h tkbs-hive-server-8649cb7446-jq426 2/2 Running 1 6d23h tkbs-impala-catalogd-6f46fd97c6-b6j7b 1/1 Running 0 6d23h tkbs-impala-coord-exec-0 1/1 Running 7 6d23h tkbs-impala-coord-exec-1 1/1 Running 7 6d23h tkbs-impala-coord-exec-2 1/1 Running 7 6d23h tkbs-impala-shell-844796695-fgsjt 1/1 Running 0 6d23h tkbs-impala-statestored-798d44765f-ffp82 1/1 Running 0 6d23h tkbs-kibana-7994978d8f-5fbcx 1/1 Running 0 6d23h tkbs-kube-state-metrics-57ff4b79cb-lmsxp 1/1 Running 0 6d23h tkbs-loki-0 1/1 Running 0 6d23h tkbs-mist-d88b8bc67-s8pxx 1/1 Running 0 6d23h tkbs-nginx-ingress-controller-87b7fb9bb-mpgtj 1/1 Running 0 6d23h tkbs-nginx-ingress-default-backend-6857b58896-rgc5c 1/1 Running 0 6d23h tkbs-nginx-proxy-64964c4c79-7xqx6 1/1 Running 6 6d23h tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 6d23h tkbs-postgresql-ha-pgpool-5cbf85d847-v5dsr 1/1 Running 1 6d23h tkbs-postgresql-ha-postgresql-0 2/2 Running 0 6d23h tkbs-postgresql-ha-postgresql-1 2/2 Running 0 6d23h tkbs-prometheus-node-exporter-bdp9v 1/1 Running 0 6d23h tkbs-prometheus-node-exporter-cdrqr 1/1 Running 0 6d23h tkbs-prometheus-node-exporter-cv767 1/1 Running 0 6d23h tkbs-prometheus-node-exporter-l82wp 1/1 Running 0 6d23h tkbs-prometheus-node-exporter-nb4pk 1/1 Running 0 6d23h tkbs-prometheus-operator-operator-f74dd4f6f-lnscv 2/2 Running 0 6d23h tkbs-promtail-d6r9r 1/1 Running 0 6d23h tkbs-promtail-gd5nz 1/1 Running 0 6d23h tkbs-promtail-l9kjw 1/1 Running 0 6d23h tkbs-promtail-llwvh 1/1 Running 0 6d23h tkbs-promtail-prgt9 1/1 Running 0 6d23h tkbs-scheduler-74f5777c5d-hr88l 1/1 Running 0 6d23h tkbs-spark-history-7d78cf8b56-82xg7 1/1 Running 4 6d23h tkbs-spark-thirftserver-5757f9588d-gdnzz 1/1 Running 4 6d23h tkbs-sparkoperator-f9fc5b8bf-8s4m2 1/1 Running 0 6d23h tkbs-sparkoperator-f9fc5b8bf-m9pjk 1/1 Running 0 6d23h tkbs-sparkoperator-webhook-init-m6fn5 0/1 Completed 0 6d23h tkbs-superset-54d587c867-b99kw 1/1 Running 0 6d23h tkbs-zeppelin-controller-65c454cfb9-m4snp 1/1 Running 0 6d23h tkbs-zookeeper-0 3/3 Running 0 6d23h tkbs-zookeeper-1 3/3 Running 0 6d23h tkbs-zookeeper-2 3/3 Running 0 6d23h ``` #### Be careful At present TKE k8s-big-data-suite 1.0.3 Initializing Postgresql When , Lack of the right to Hive transaction Support for , Which leads to Iceberg Table creation failed . Please execute the following command to manually repair : ``` $ kubectl get pod | grep postgresql tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d18h $ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "UPDATE pg_database SET datallowconn = 'false' WHERE datname = 'metastore';SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'metastore'"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "drop database metastore"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "create database metastore" $ kubectl get pod | grep client tkbs-client-844559f5d7-r86rb 1/1 Running 7 7d18h $ kubectl exec tkbs-client-844559f5d7-r86rb -- schematool -dbType postgres -initSchema ``` ### Integrate Iceberg At present Iceberg Yes Spark 3.0 There's better support , Contrast Spark 2.4 It has the following advantages : 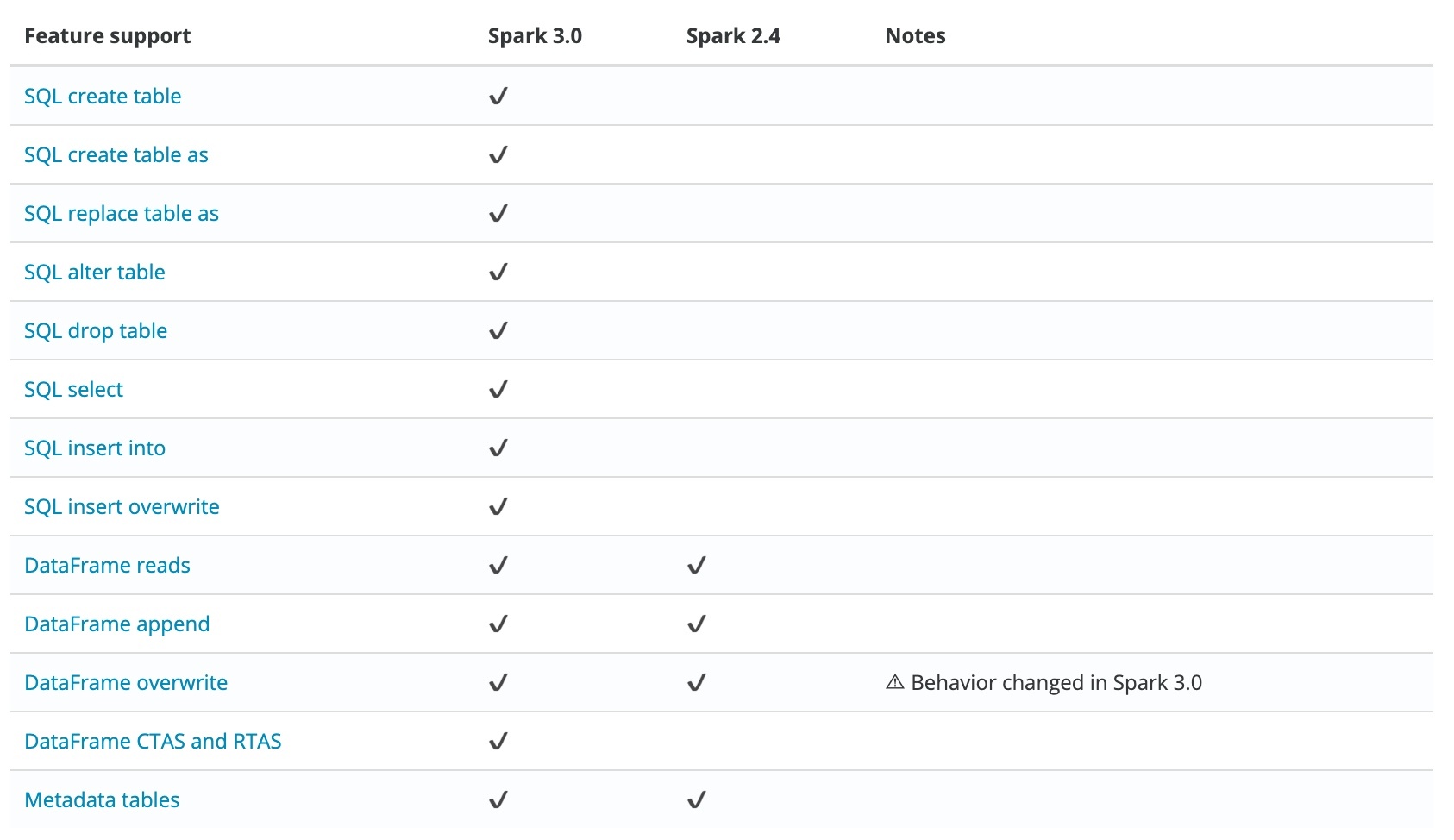 So we default to use Spark 3.0 As a computing engine .Spark Integrate Iceberg, The first thing to do is to introduce Iceberg jar Rely on . The user can manually specify , Or jar Packages are introduced directly Spark Installation directory . For the convenience of use , We choose the latter . The author has packed Spark 3.0.1 Mapping of , For user testing :ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1. We use Hive MetaStore management Iceberg Table information , Through Spark Catalog Access and use Iceberg surface . stay Spark Do the following configuration in : ``` spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog spark.sql.catalog.hive_prod.type = hive spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port ``` If you use TKE k8s-big-data-suite Suite deployment Hadoop Cluster , It can be done by Hive Service Visit Hive MetaStore: ``` $ kubectl get svc | grep hive-metastore tkbs-hive-metastore ClusterIP 172.22.25
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
