当前位置:网站首页>spark operator - map vs mapPartitions operator
spark operator - map vs mapPartitions operator
2022-08-05 06:11:00 【zdaiqing】
map vs mapPartitions
1.源码
1.1.map算子源码
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
1.2.mapPartitions算子源码
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
1.3.对比
相似
map算子和mapPartitionsThe bottom layer of the operator is the componentMapPartitionsRDD
区别
functional aspects
mapThe function of the function passed in by the operator,Is to process one element and return another element;
mapPartitionsThe function of the function passed in by the operator,is an iterator(一批元素)Returns another iterator after processing(一批元素);
function execution
map算子中,An iterator contains all the elements that the operator needs to process,有多少个元素,The incoming function is executed as many times as possible;
mapPartitions算子中,An iterator contains all elements in a partition,The function processes the data one iterator at a time,That is, one partition calls the function once;
1.4.Validation of execution times
代码
val lineSeq = Seq(
"hello me you her",
"hello you her",
"hello her",
"hello"
)
val rdd = sc.parallelize(lineSeq, 2)
.flatMap(_.split(" "))
println("===========mapPartitions.start==============")
rdd.mapPartitions(iter => {
println("mp+1")
iter.map(x =>
(x, 1)
)
}).collect()
println("===========map.start==============")
rdd.map(x => {
println("mp+2")
(x, 1)
}).collect()
执行结果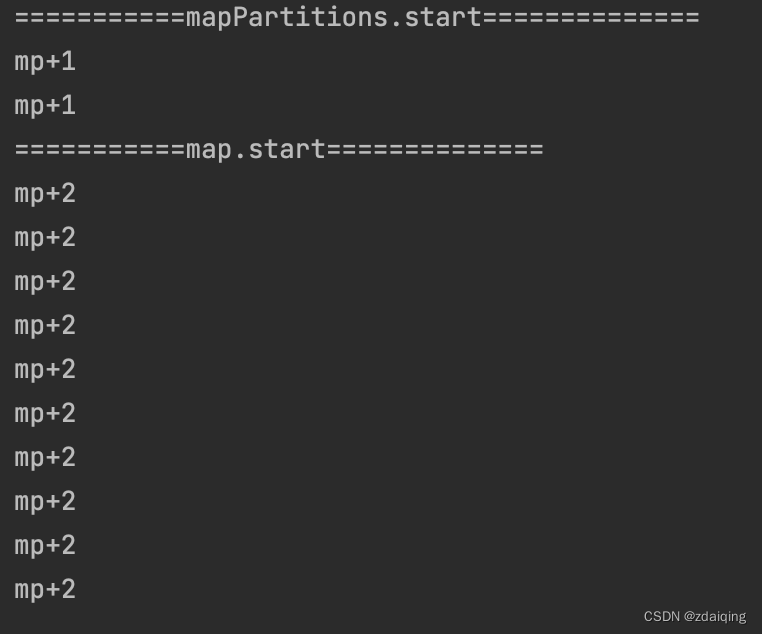
2.特点
map算子
有多少元素,How many times the function is executed
mapPartitions算子
有多少分区,How many times the function is executed
The function parameter is an iterator,返回的也是一个迭代器
3.使用场景分析
When performing simple element representation transformation operations,建议使用map算子,避免使用mapPartitions算子:
mapPartitionsThe function needs to return an iterator,When dealing with transformation operations on simple element representations,An intermediate cache is required to store the processing results,It is then converted to an iterator cache;这个情况下,The intermediate cache is stored in memory,If there are more elements to be processed in the iterator,容易引起OOM;
In scenarios of resource initialization overhead and batch processing in the case of large datasets,建议使用mapPartitions算子:
基于sparkCharacteristics of distributed execution operators,Each partition requires a separate resource initialization;mapPartitionsThe advantage of executing a function only once for a partition can realize that a partition needs only one resource initialization(eg:Scenarios that require database linking);
4.参考资料
Spark系列——关于 mapPartitions的误区
Spark—算子调优之MapPartitions提升Map类操作性能
Learning Spark——Spark连接Mysql、mapPartitions高效连接HBase
mapPartition
边栏推荐
- 【Day8】磁盘及磁盘的分区有关知识
- Getting Started Document 07 Staged Output
- Getting Started 05 Using cb() to indicate that the current task is complete
- 专有宿主机CDH
- 通过单总线调用ds18b20的问题
- 入门文档08 条件插件
- spark source code-RPC communication mechanism
- Introductory document 05-2 use return instructions the current task has been completed
- spark算子-wholeTextFiles算子
- 2020,Laya最新中高级面试灵魂32问,你都知道吗?
猜你喜欢



随机推荐
网站ICP备案是什么呢?
Cocos Creator小游戏案例《棍子士兵》
Contextual non-local alignment of full-scale representations
The spark operator - coalesce operator
【Day6】文件系统权限管理 文件特殊权限 隐藏属性
The problem of redirecting to the home page when visiting a new page in dsf5.0
账号与权限管理
spark源码-任务提交流程之-1-sparkSubmit
入门文档08 条件插件
js动态获取屏幕宽高度
硬盘分区和永久挂载
vim的三种模式
【Day1】(超详细步骤)构建软RAID磁盘阵列
One-arm routing and 30% switch
Spark source code-task submission process-6.1-sparkContext initialization-create spark driver side execution environment SparkEnv
Unity常用模块设计 : Unity游戏排行榜的制作与优化
CIPU,对云计算产业有什么影响
Mongodb查询分析器解析
lvm逻辑卷及磁盘配额
To TrueNAS PVE through hard disk