当前位置:网站首页>Practice (9-12 Lectures)
Practice (9-12 Lectures)
2022-07-04 07:27:00 【Cool as the wind, wild as a dog】
09_ Common index and unique index , How to choose ?
In the previous basic article , I introduced you to the basic concept of index , I believe you already know the difference between a unique index and a normal index . Let's continue today , In different business scenarios , Normal index should be selected , Or the only index ?
Suppose you're maintaining a citizen system , Everyone has a unique ID number. , And business code has guaranteed that two duplicate ID number will not be written. . If the citizen system needs to check the name according to the ID number, , You're going to do something like this SQL sentence :
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz';
therefore , You will definitely consider id_card Index fields .
Because ID card number field is larger. , I do not recommend that you use the ID card as the primary key. , So now you have two choices , Or to id_card Fields create unique indexes , Or create a normal index . If the business code has guaranteed that the duplicate ID number will not be written , So these two choices are logically correct .
Now what I want to ask you is , In terms of performance , Do you choose a unique index or a normal index ?
What is the basis of the choice ? Simplicity , Let's still use the third 4 An article 《 Index in simple terms ( On )》 To illustrate , Hypothetical field k The values on do not repeat .
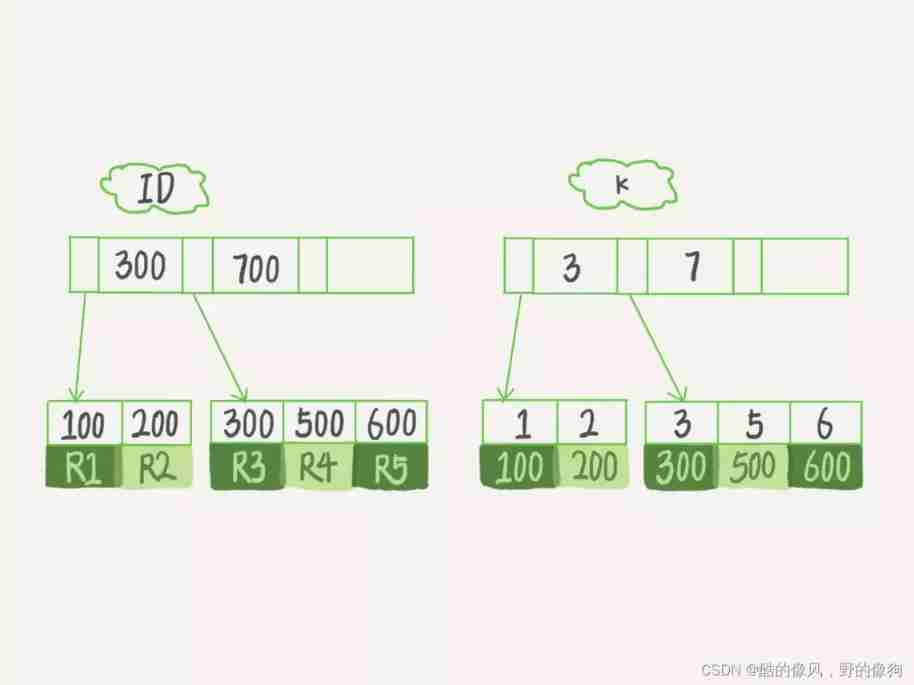
Next , We analyze the impact of these two indexes on the performance of query statements and update statements .
The query process
hypothesis , The statement to execute the query is select id from T where k=5. This query statement searches the index tree , First through B+ Trees start from the roots , Search leaf nodes by layer , This is the data page in the lower right corner of the figure , Then you can think of the data page inside through dichotomy to locate records .
- For a normal index , Find the first record that meets the criteria (5,500) after , Need to find the next record , Until I met the first one who was not satisfied k=5 Record of conditions .
- For a unique index , Because the index defines uniqueness , After finding the first record that meets the conditions , Will stop retrieving .
that , How much performance gap will this difference bring ? The answer is , very little .
You know ,InnoDB Data is read and written in data pages . in other words , When you need to read a record , It's not about reading the record itself out of the disk , It's in pages , Read it into memory as a whole . stay InnoDB in , The default size of each data page is 16KB.
Because the engine reads and writes page by page , So , When it finds k=5 At the time of recording , Its data pages are all in memory . that , For a normal index , One more time “ Find and judge the next record ” The operation of , Just one pointer search and one calculation .
Of course , If k=5 This record happens to be the last record on this data page , Then take down a record , The next data page must be read , This operation will be a little more complicated .
however , We calculated it before , For integer fields , One data page can hold nearly a thousand key, So the probability of this happening is very low . therefore , When we calculate the average performance difference , It can still be considered that the operating cost of the current CPU It can be ignored .
The update process
To illustrate the impact of common index and unique index on the performance of update statements , I need to introduce you first change buffer.
When you need to update a data page , If the data page is in memory, update it directly , And if the data page is not in memory , Without affecting data consistency ,InnoDB These updates will be cached in change buffer in , So you don't need to read this data page from disk . The next time the query needs to access this data page , Read data pages into memory , And then execute change buffer Operations related to this page in . In this way, we can guarantee the correctness of the data logic .
It should be noted that , Although the name is change buffer, It's actually data that can be persisted . in other words ,change buffer There are copies in memory , It will also be written to disk .
take change buffer The operations in apply to the original data page , The process of getting the latest results is called merge. In addition to accessing this data page will trigger merge Outside , There are background threads in the system that regularly merge. Shut down the database normally (shutdown) In the process of , Will perform merge operation .
obviously , If the update operation can be recorded in change buffer, Reduce read disk , Statement execution speed will be significantly improved . and , Data read into memory is required to occupy buffer pool Of , So this way can also avoid using memory , Improve memory utilization .
that , Under what conditions can I use change buffer Well ?
For a unique index , All update operations must first determine whether the operation violates the uniqueness constraint . such as , To insert (4,400) This record , It is necessary to judge whether there is already k=4 The record of , But this must read the data page into the memory to judge . If all of them have been read into memory , It's faster to update memory directly , There's no need to use it change buffer 了 .
therefore , Only index updates are not available change buffer, In fact, only ordinary indexes can be used .
change buffer It's using buffer pool In the memory , So it can't grow infinitely .change buffer Size , You can use the parameter innodb_change_buffer_max_size To set dynamically . This parameter is set to 50 When , Express change buffer The size of can only occupy at most buffer pool Of 50%.
Now? , You have understood change buffer The mechanism of , So let's take a look again If you want to insert a new record in this table (4,400) Words ,InnoDB What is the processing flow of .
The first is ,** The target page of this record to be updated is in memory .** At this time ,InnoDB The processing flow is as follows :
- For a unique index , find 3 and 5 Position between , Judge that there is no conflict , Insert this value , Statement execution ended ;
- For a normal index , find 3 and 5 Position between , Insert this value , Statement execution ended .
So it looks like , The difference between a normal index and a unique index in the performance of an update statement , It's just a judgment , It will only cost a little CPU Time .
but , This is not the point of our attention .
The second situation is ,** The target page of this record to be updated is not in memory .** At this time ,InnoDB The processing flow is as follows :
- For a unique index , Data pages need to be read into memory , Judge that there is no conflict , Insert this value , Statement execution ended ;
- For a normal index , Record the update in change buffer, Statement execution ends .
Reading data from disk into memory involves random IO The interview of , It is one of the most expensive operations in the database .change buffer Because it reduces random disk access , So the improvement of update performance will be obvious .
One thing happened to me before , There is one DBA My classmates gave me feedback , The library memory hit rate of a business he was responsible for suddenly changed from 99% Down to 75%, The whole system is blocked , All update statements are blocked . After exploring the reasons , I found a lot of data insertion operations in this business , The day before, he changed one of the ordinary indexes into a unique index .
change buffer Usage scenarios of
Through the above analysis , You already know how to use it change buffer Speed up the update process , It's also clear change buffer It is only used in the normal index scenario , It doesn't apply to unique indexes . that , Now there is a problem : All scenarios of the normal index , Use change buffer Can they all accelerate ?
because merge It's the time to actually update the data , and change buffer The main purpose is to cache the recorded changes , So on a data page merge Before ,change buffer The more changes are recorded ( That is, the more times this page needs to be updated ), The bigger the payoff .
therefore , For businesses that write more and read less , The probability that the page will be accessed immediately after writing is relatively small , here change buffer The best effect is . The common business model is Bill class 、 Log system .
In turn, , Suppose that the update mode of a business is to query immediately after writing , So even if the conditions are met , Record the update in change buffer, But after that, because we need to access this data page immediately , Will trigger immediately merge The process . So random access IO The number of times will not decrease , It increases change buffer The cost of maintenance . therefore , For this business model ,change buffer It's a side effect .
Index selection and practice
Back to the question at the beginning of our article , How to choose between normal index and unique index . Actually , There is no difference in query capability between these two types of indexes , The main consideration is the impact on update performance . therefore , I suggest that you try to choose a normal index .
If all the updates follow , All of them are accompanied by the query of this record , Then you should shut down change buffer. And in other cases ,change buffer Can improve the update performance .
In practical use , You'll find that , General index and change buffer In combination with , For large data table update optimization is still very obvious .
Specially , When using a mechanical hard disk ,change buffer The effect of this mechanism is remarkable . therefore , When you have a similar “ The historical data ” The library of , And for the sake of cost, when using mechanical hard disk , Then you should pay special attention to the indexes in these tables , Try to use a normal index , And then put change buffer Try to make it as big as possible , To make sure that “ The historical data ” Data write speed of table .
change buffer and redo log
I understand change buffer Principle , You may think of what I introduced to you in the previous article redo log and WAL.
In the comments of the previous article , I found some students confused redo log and change buffer.WAL The core mechanism to improve performance , It's also true to minimize random reading and writing , The two concepts are really confusing . therefore , Here I put them in the same process to illustrate , It's easy for you to distinguish the two concepts .
remarks : here , You can go back to 2 An article 《 Log system : One SQL How update statements are executed ?》 Related content in .
Now? , We want to execute this insert on the table :
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
here , Let's assume that at present k Index of the state tree , After finding the location ,k1 The data page is in memory (InnoDB buffer pool) in ,k2 The data page is not in memory . Pictured 2 Here is the band change buffer Update state diagram for .
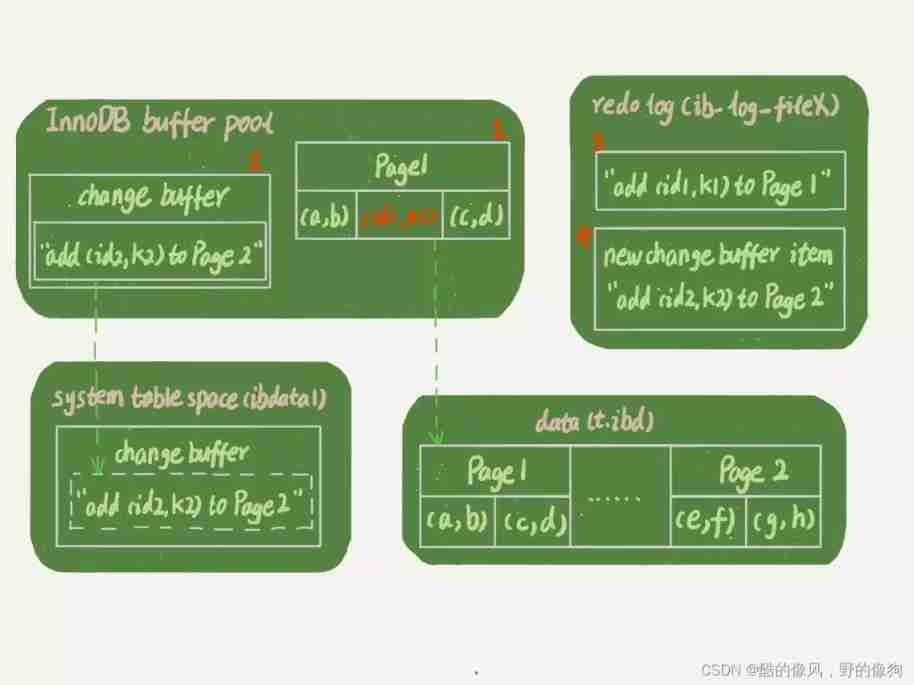
Analyze this update statement , You'll find that it involves four parts : Memory 、redo log(ib_log_fileX)、 Data table space (t.ibd)、 SYSTEM tablespace (ibdata1).
This update statement does the following operations ( In the order of numbers in the figure ):
- Page 1 In memory , Update memory directly ;
- Page 2 It's not in memory , It's in memory change buffer Area , Record “ I want to go Page 2 Insert a row ” This information
- Record the above two actions redo log in ( In the figure 3 and 4).
Finish the above , The transaction can be completed . therefore , You'll see , The cost of executing this update statement is very low , It's just writing two memories , And then I wrote a disk ( The two operations combined to write a disk ), And it's written in sequence .
meanwhile , Two dashed arrows in the picture , It's a background operation , Does not affect the response time for updates .
The reading request after this , How to deal with it ?
such as , We're going to implement select * from t where k in (k1, k2). here , I drew a flow chart of these two read requests .
If the read statement occurs shortly after the update statement , The data in memory is still there , Then these two read operations are related to the system table space (ibdata1) and redo log(ib_log_fileX) Has nothing to do . therefore , I didn't draw these two parts in the picture .
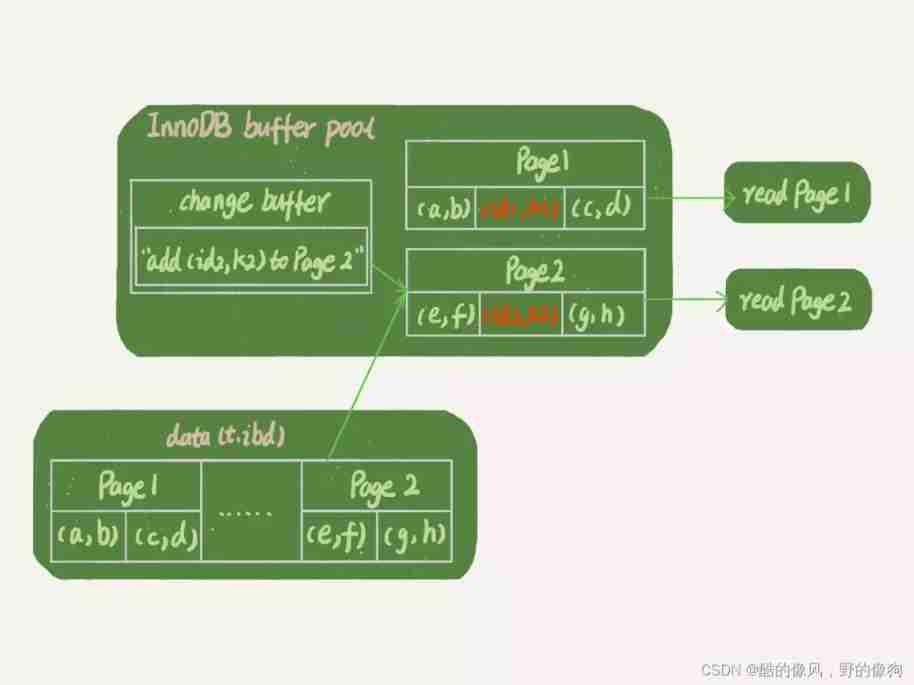
As you can see from the diagram :
- read Page 1 When , Back directly from memory . Several students asked in the comments of the previous article ,WAL And then if you read the data , Is it necessary to read the disk , Is it necessary to start from redo log The data can be updated later ? In fact, it's not necessary . You can take a look at the picture below 3 This state of , Although the data on the disk is still the same as before , But here the result is returned directly from memory , The result is correct .
- Read Page 2 When , Need to put Page 2 Read from disk into memory , Then apply change buffer The operation log inside , Generate a correct version and return the result .
You can see , Until you need to read Page 2 When , This data page will be read into memory .
therefore , If you want to simply compare the benefits of these two mechanisms in improving update performance ,redo log The main savings are random write disk IO Consume ( Write in order ), and change buffer The main savings are random read disk IO Consume .
Summary
today , I start with the choice of normal index and unique index , I shared the data query and update process with you , And then it explains change buffer The mechanism and application scenarios of , Finally, the practice of index selection is discussed .
Because the unique index cannot be referenced change buffer The optimization mechanism of , So if the business is acceptable , From a performance perspective, I recommend that you give priority to non unique indexes .
Last , It's time to think again .
Pass diagram 2 You can see ,change buffer In the beginning, it was written in memory , So if the machine power down and restart at this time , Will it lead to change buffer Lost ?change buffer Loss is no small matter , Then read in data from the disk and there's no more merge The process , It's like losing data . Will this happen ?
Add :
In the comments section, everyone is right “ Use unique index ” There was a lot of discussion , The main problem is that “ Business may not be able to ensure ” The situation of . here , Let me explain again :
- First , Business correctness first . The premise of this article is that “ The business code has been guaranteed not to write duplicate data ” Under the circumstances , Discuss performance issues . If the business cannot guarantee , Or the business is to require the database to do constraints , So there's no choice , You must create a unique index . In this case , The significance of this article lies in , If you encounter a large number of data insertion slow 、 When memory hit rate is low , Can provide you with a more investigation ideas .
- then , In some “ Archive ” Scene , You can consider using a common index . such as , Online data only needs to be retained for half a year , The historical data is then stored in the archive . Now , Archiving data is already ensuring that there are no unique key conflicts . To improve the efficiency of archiving , Consider changing the unique index in the table to a normal index .
Last issue time
The question in the last issue is : How to construct a “ Data cannot be modified ” Scene . Many students in the comment area have given correct answers , Here I will describe again .

such ,session A What you see is the effect of my screenshot . Actually , There's another scene , The students haven't mentioned it in the message area .

This sequence of operations runs out ,session A The content can also reproduce the effect of my screenshot . This session B’ The number of transactions started is greater than A Early , In fact, it is the colored egg left when we described the visibility rules of the transaction version in the previous issue , Because there's another one in the rules “ Judgment of active transactions ”, I'm going to leave it here to add .
When I try to talk about the complete rules here , Find the first 8 An article 《 Is the transaction isolated or not ?》 The explanation in introduces too many concepts , So that the analysis is very complex .
therefore , I rewrote number 8 piece , So when we judge the visibility manually , Will be more convenient . Analyze... In a new way session B’ Why is the update to session A Invisible is : stay session A The moment the view array is created ,session B’ Is active , Belong to “ Version not submitted , invisible ” This situation .
+++
10_MySQL Why sometimes you choose the wrong index ?
We introduced the index earlier , You already know that in MySQL In fact, a table can support multiple indexes . however , You write SQL At the time of statement , There is no active specification of which index to use . in other words , Which index is used by MySQL To determine the .
I don't know if you've ever been in this situation , A statement that could have been executed quickly , But due to the MySQL Wrong index , And the execution speed becomes very slow ?
Let's take a look at an example .
Let's start with a simple watch , There are a、b Two fields , And index them separately :
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
then , Let's watch t Insert 10 Ten thousand records , The value is incremented by an integer , namely :(1,1,1),(2,2,2),(3,3,3) until (100000,100000,100000).
I use stored procedures to insert data , I'll post it here for you to reproduce :
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
Next , Let's analyze one SQL sentence :
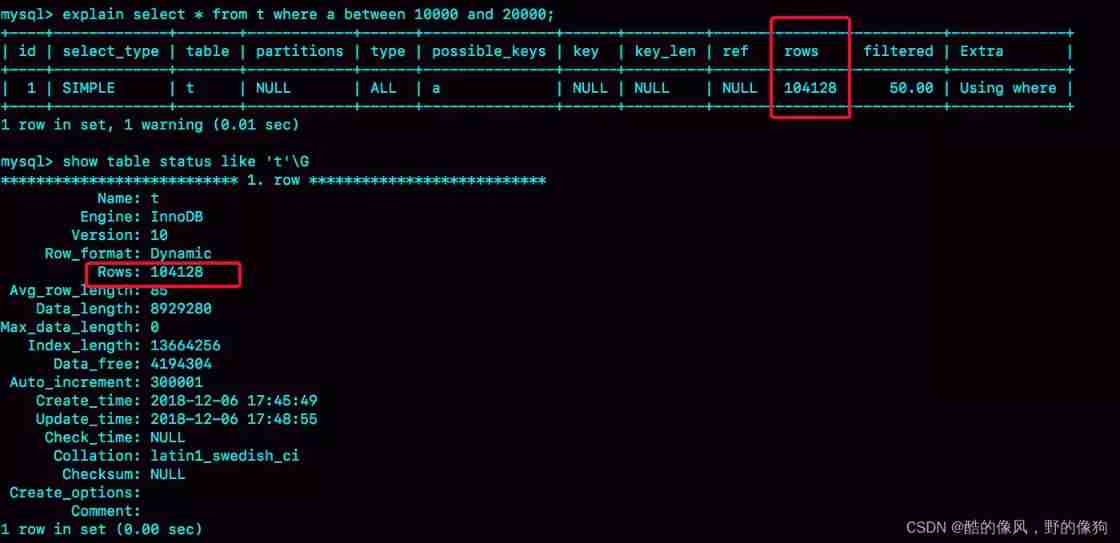
mysql> select * from t where a between 10000 and 20000;
You must say , Is this sentence still used for analysis , It's very simple. ,a There's an index on , You have to use the index a Of .
You're right , chart 1 It shows the use of explain The execution of this statement seen by the command .

From the picture 1 it seems , The execution of this query statement is also in line with the expectation ,key The value of this field is ’a’, Indicates that the optimizer has selected the index a.
But don't worry. , This case is not so simple . We are ready to include 10 Ten thousand rows of data on the table , Let's do the following again .

here ,session A You are already familiar with the operation of , It just opens up a business . And then ,session B After deleting all the data , Call again idata This stored procedure , Inserted 10 Ten thousand rows of data .
Now ,session B Query statement select * from t where a between 10000 and 20000 You won't choose the index again a 了 . We can query the log slowly (slow log) Let's take a look at the specific implementation .
To show whether the optimizer has chosen the right result , I added a control , namely : Use force index(a) To have the optimizer force the use of indexes a( This part , I'll also mention it in the second half of this article ).
The next three SQL sentence , This is the experimental process :
set long_query_time=0;
select * from t where a between 10000 and 20000; /*Q1*/
select * from t force index(a) where a between 10000 and 20000;/*Q2*/
- The first sentence , Is to set the threshold of slow query log to 0, Indicates that the next statement of this thread will be recorded in the slow query log ;
- The second sentence ,Q1 yes session B The original query ;
- The third sentence ,Q2 Yes, it is force index(a) Come and join us session B Compare the execution of the original query statement .
Pictured 3 Here are the three SQL Slow query log after statement execution .
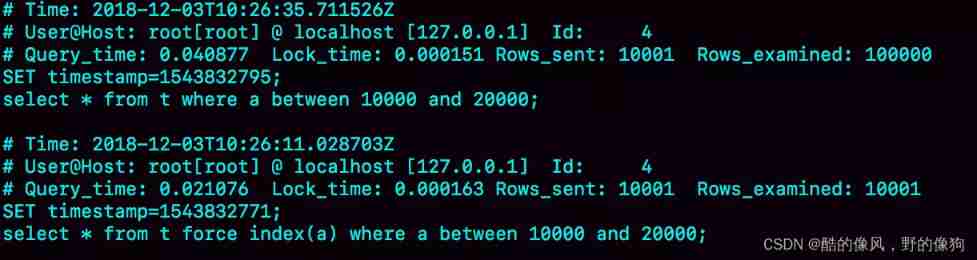
You can see ,Q1 Scanned 10 Line ten thousand , It's obviously a full scan , The execution time is 40 millisecond .Q2 Scanned 10001 That's ok , Yes 21 millisecond . in other words , We're not using it force index When ,MySQL Wrong index , It leads to longer execution time .
This example corresponds to the scenario where we usually delete historical data and add new data . At this time ,MySQL It's the wrong index , Isn't it a little strange ? today , Let's start with this strange result .
Optimizer logic
In the first article , We mentioned that , Choosing an index is the job of the optimizer .
The optimizer chooses the index for the purpose of , It's about finding an optimal execution plan , And execute the statement at the lowest cost . In the database , The number of scan lines is one of the factors that affect the execution cost . The fewer lines to scan , It means that the fewer times you access disk data , The consumption of CPU The less resources .
Of course , The number of scan lines is not the only criterion , The optimizer will also combine whether to use temporary tables 、 Whether to make a comprehensive judgment on sorting and other factors .
Our simple query statement does not involve temporary tables and sort , therefore MySQL The wrong index must be wrong when judging the number of scan lines .
that , The problem is : How to judge the number of scanning lines ?
MySQL Before you actually start executing statements , It's impossible to know exactly how many records satisfy this condition , Only statistics can be used to estimate the number of records .
This statistic is indexed “ Degree of differentiation ”. obviously , More different values on an index , The better the distinction of this index . And the number of different values on an index , We call it “ base ”(cardinality). in other words , The larger the base , The better the index is differentiated .
We can use show index Method , See the cardinality of an index . Pictured 4 Shown , It's a watch t Of show index Result . Although the values of the three fields in each row of this table are the same , But in the statistics , The base values of the three indexes are not the same , And it's not accurate .

that ,**MySQL How to get the cardinality of index ?** here , Let me give you a brief introduction to MySQL The method of sampling statistics .
Why sampling statistics ? Because take the whole table out one row and count , Although we can get accurate results , But the price is too high , So we can only choose “ Sampling statistics ”.
When sampling statistics ,InnoDB The default choice is N Data pages , Count the different values on these pages , Get an average of , Then multiply by the number of pages in this index , You get the cardinality of this index .
And the data table is constantly updated , Index statistics are not fixed . therefore , When the number of data lines changed exceeds 1/M When , It will automatically trigger the index statistics to be done again .
stay MySQL in , There are two ways to store index statistics , By setting the parameters innodb_stats_persistent To choose :
- Set to on When , Indicates that statistics are persisted . At this time , default N yes 20,M yes 10.
- Set to off When , Indicates that statistics are only stored in memory . At this time , default N yes 8,M yes 16.
Because it's sampling statistics , So no matter N yes 20 still 8, This base number is easy to be inaccurate .
but , This is not all .
You can see from the picture 4 see , The index statistics this time (cardinality Column ) It's not accurate enough , But it's almost the same , There must be other reasons for choosing the wrong index .
In fact, index statistics is just an input , For a specific statement , The optimizer also judges , How many lines to scan to execute the statement itself .
Next , Let's take a look at what the optimizer predicts , What are the scan lines of these two statements .
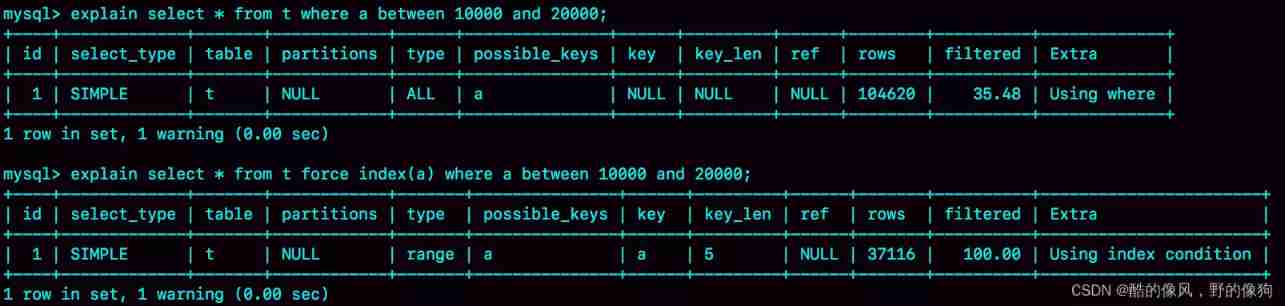
rows This field represents the expected number of scan lines .
among ,Q1 The results are still in line with expectations ,rows The value of is 104620; however Q2 Of rows The value is 37116, The deviation is big . Diagram 1 We use explain Command to see rows It's just 10001 That's ok , It is this deviation that misleads the optimizer's judgment .
Come here , Maybe your first question is not why not , It's about why the optimizer keeps scanning 37000 The execution plan of the line is not used , The number of scanning lines is selected 100000 What about the implementation plan of ?
This is because , If index is used a, Every time from the index a Get a value on , You have to go back to the primary key index to find the whole row of data , This cost optimizer also has to account for .
And if you choose to scan 10 Line ten thousand , It's scanned directly on the primary key index , There is no extra cost .
The two optimizers will choose the cost , As a result , The optimizer thinks it's faster to scan the primary key index directly . Of course , In terms of execution time , This choice is not optimal .
Using a normal index involves the cost of returning to the table , In the figure 1 perform explain When , Also consider the cost of this strategy , But the picture 1 The choice is right . in other words , There is no problem with this strategy .
So there's a head of injustice and a master of debt ,MySQL Wrong index , It's also due to not being able to accurately determine the number of scan lines . As for why you get the wrong number of scan lines , This is the reason for the problem after class , It's for you to analyze .
Since the statistics are wrong , Then amend it .analyze table t command , Can be used to re index information . Let's look at the execution effect .
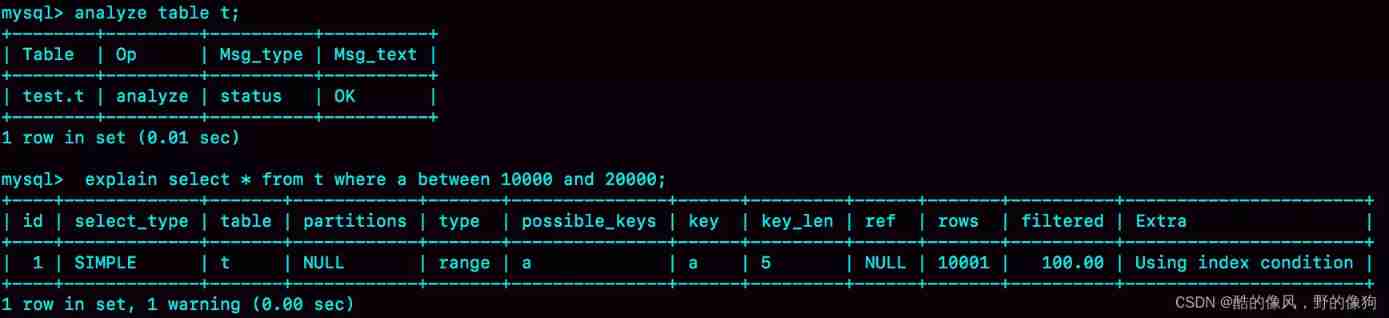
This time it's right .
So in practice , If you find that explain The result of the prediction rows There is a big gap between the value and the actual situation , This method can be used to deal with .
Actually , If only the index statistics are not accurate , adopt analyze Commands can solve many problems , We said before, but , The optimizer doesn't just look at the number of scan lines .
It's still based on this table t, Let's look at another sentence :
mysql> select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
In terms of conditions , There are no records for this query , So it returns an empty set .
Before you start executing this statement , You can imagine , If you choose the index , Which one will you choose ?
For the convenience of analysis , So let's see a、b The structure of these two indexes .
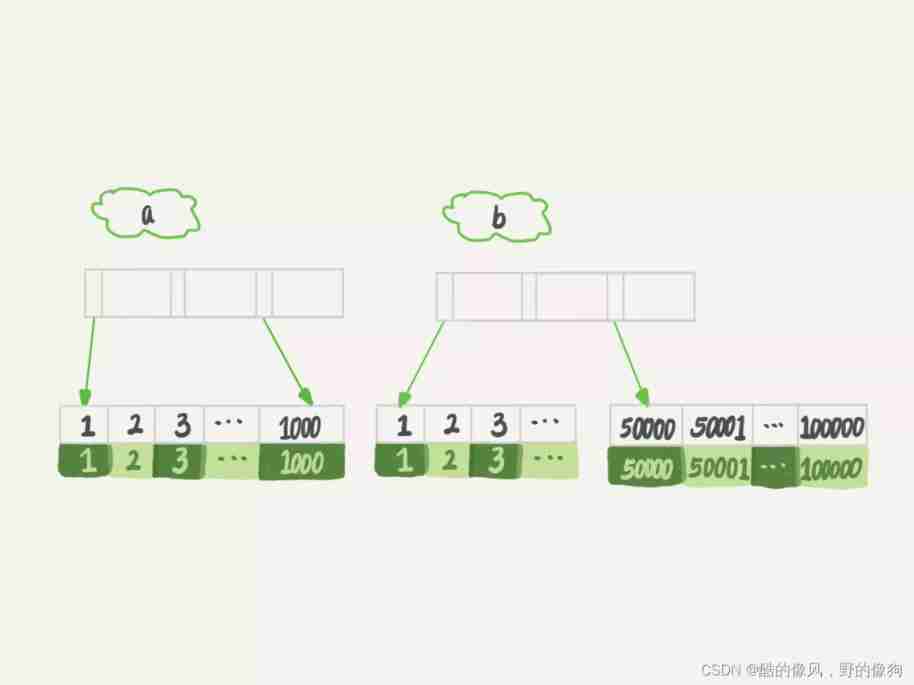
If index is used a The query , So scan the index a Before 1000 It's worth , And then get the corresponding id, Then go to the primary key index to find each row , And then according to the field b To filter . Obviously, this requires scanning 1000 That's ok .
If index is used b The query , So scan the index b Last 50001 It's worth , Same as the execution process above , It is also necessary to judge the value of the primary key again , So you need to scan 50001 That's ok .
So you must think , If index is used a Words , The execution speed will obviously be much faster . that , Now let's see if this is the case .
chart 8 Is to perform explain Result .
mysql> explain select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;

You can see , Return the result key Field shows , This time the optimizer selects the index b, and rows The field shows that the number of rows to scan is 50198.
From this result , You can come to two conclusions :
- The estimate of the number of scan lines is still inaccurate ;
- In this case MySQL Wrong index again .
Index selection exceptions and handling
Most of the time, the optimizer can find the right index , But once in a while, you'll come across the two situations that we've illustrated above : It could have been done very quickly SQL sentence , Execution is much slower than you expected , What should you do ?
** One way is , Like our first example , use force index Force an index .**MySQL According to the result of lexical analysis, the possible indexes can be used as candidates , Then, in the candidate list, determine how many rows each index needs to scan . If force index The specified index is in the candidate index list , Just select this index directly , The execution cost of other indexes is no longer evaluated .
Let's take a second example . At the beginning of the analysis , We think that selecting the index a Will be better . Now? , Let's take a look at the execution effect :

You can see , The original statement needs to be executed 2.23 second , And when you use force index(a) When , It only took 0.05 second , Faster than the optimizer selection 40 Many times .
in other words , The optimizer did not select the correct index ,force index Play a “ correct ” The role of .
But many programmers don't like to use force index, First of all, it's not beautiful to write like this , If we change the name index , This sentence has to be changed , It seems very troublesome . And if you migrate to another database later , This syntax may also be incompatible with .
But actually it uses force index The main problem is the timeliness of changes . Because the wrong index is still relatively rare , So when we develop, we usually don't write force index. It's about waiting until something goes wrong online , You're going to modify it SQL sentence 、 add force index. But after modification, it has to be tested and released , For production systems , This process is not agile enough .
therefore , The problem of database is best solved in the database itself . that , How to solve the problem in the database ?
Since the optimizer gave up using indexes a, explain a It's not enough , therefore ** The second way is , We can consider changing the statement , guide MySQL Use the index we expect .** such as , In this case , Obviously “order by b limit 1” Change to “order by b,a limit 1” , The logic of semantics is the same .
Let's take a look at the effect of the change :
Previously, the optimizer chose to use indexes b, It's because it thinks that using indexes b You can avoid sorting (b It's an index itself , It's already in order , If you select the index b Words , There's no need to sort again , Just traverse ), So even if there are a lot of scanning lines , It's also judged to be less costly .
Now? order by b,a This kind of writing , The requirements are as follows b,a Sort , This means that using both indexes requires sorting . therefore , The number of scanning lines becomes the main condition affecting the decision , So the optimizer chooses to scan 1000 Index of rows a.
Of course , This modification is not a general optimization method , It's just that there is limit 1, So if there is a record that meets the conditions , order by b limit 1 and order by b,a limit 1 Will return to b It's the smallest line , Logically consistent , To do this .
If you don't think it's good to modify the semantics , Here's another way to change it , chart 11 It's the execution effect .
mysql> select * from (select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 100)alias limit 1;

In this case , We use it limit 100 Make the optimizer aware of , Use b Indexing is expensive . In fact, we induced the optimizer according to the characteristics of the data , It's not universal .
The third way is , In some cases , We can create a more suitable index , To provide the optimizer with choices , Or delete the misused index .
however , In this case , I didn't find a way to change optimizer behavior by adding indexes . This kind of situation is actually less , Especially after DBA Index optimized Libraries , Come across this again bug, It is generally difficult to find a more suitable index .
If I say another way is to delete the index b, You may find it funny . But I've actually come across two such examples , In the end DBA After communicating with business development , It is not necessary to find the wrong index selected by the optimizer , So I deleted the index , The optimizer selects the right index again .
Summary
Today we talked about the update mechanism of index statistics , It also mentions the possibility that the optimizer may select the wrong index .
For problems caused by inaccurate index statistics , You can use it. analyze table To solve .
For other optimizer misjudgments , You can use force index To force the index to be specified , You can also modify the statement to guide the optimizer , You can also bypass this problem by adding or deleting indexes .
You might say , A couple of examples from the back of today's article , It's not expanded to explain its principle . What I want to tell you is , Today's topic , What we are facing is MySQL Of bug, Every deployment has to go down to a line of code to quantify , It's not really what we should do here .
therefore , I'll share with you the solutions I've used , I hope you're in a similar situation , Can have some ideas .
Last , I'll leave you a question to think about . In the process of constructing the first example , adopt session A With , Give Way session B Delete the data and insert it again , And then I found out explain In the end ,rows Fields from 10001 become 37000 many .
And if not session A With , It's just a separate execution delete from t 、call idata()、explain These three words , Will see rows The field is still 10000 about . You can verify the result yourself .
What's the reason for this ? Please analyze it .
Last issue time
The question I left you at the end of my last article is , If a write uses change buffer Mechanism , After that, the host restarts abnormally , Whether it will be lost change buffer And data .
The answer to this question is not to lose . Although only memory is updated , But when the transaction is committed , We put change buffer Also recorded redo log In the , So when it comes to recovery ,change buffer You can get it back .
In the comment area, a classmate asked ,merge Does the process write data directly back to disk , That's a good question . here , I'll analyze it for you again .
merge The execution process of is as follows :
- Read data pages from disk to memory ( Old version of data page );
- from change buffer Find out the change buffer Record ( There may be more than one ), Apply... In turn , Get the new data page ;
- Write redo log. This redo log It includes data changes and change buffer Changes .
Come here merge The process is over . Now , Data pages and in memory change buffer The corresponding disk locations have not been modified , It belongs to dirty page , After that, they will brush back their own physical data , It's another process .
+++
11_ How to index a string field ?
Now? , Almost all systems support email login , How to build a reasonable index on fields like mailbox , It's what we're going to discuss today .
hypothesis , You now maintain a system that supports email login , The user table is defined as :
mysql>
create table SUser(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
Because you want to log in using your email address , So there must be statements like this in the business code :
mysql> select f1, f2 from SUser where email='xxx';
From 4 And the 5 In an article on the index , We can know , If email There is no index on this field , Then this statement can only do a full table scan .
meanwhile ,MySQL Prefix index is supported , in other words , You can define a part of a string as an index . By default , If you create an index statement without specifying the prefix length , Then the index will contain the entire string .
such as , These two are in the email A statement that creates an index on a field :
mysql> alter table SUser add index index1(email);
or
mysql> alter table SUser add index index2(email(6));
Created by the first statement index1 In the index , Contains the entire string of each record ; The second statement creates index2 In the index , For each record, we only take the first record 6 Bytes .
that , What are the differences between these two definitions in data structure and storage ? Pictured 2 and 3 Shown , This is the schematic diagram of these two indexes .
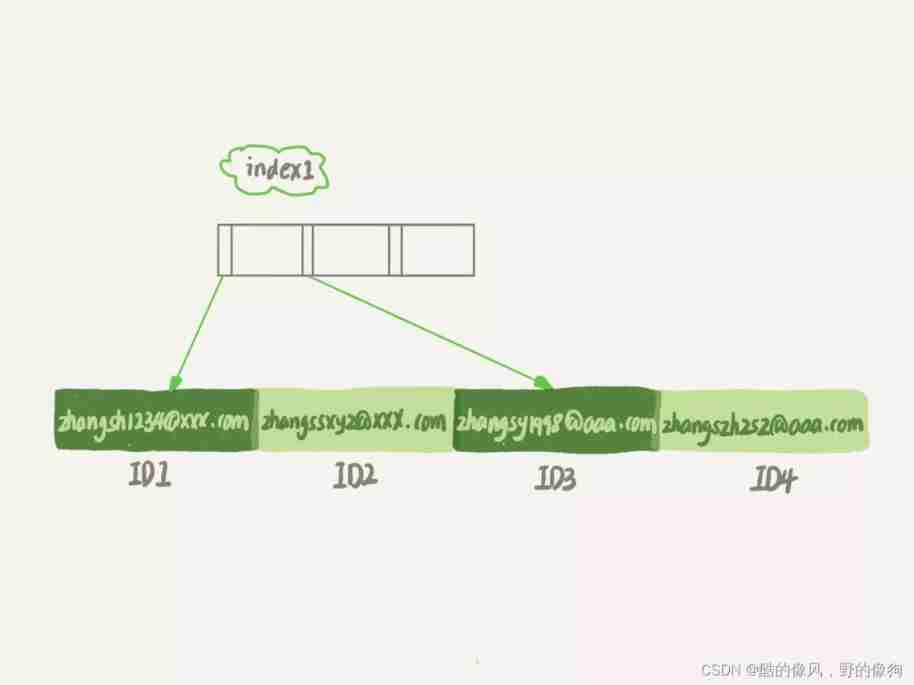
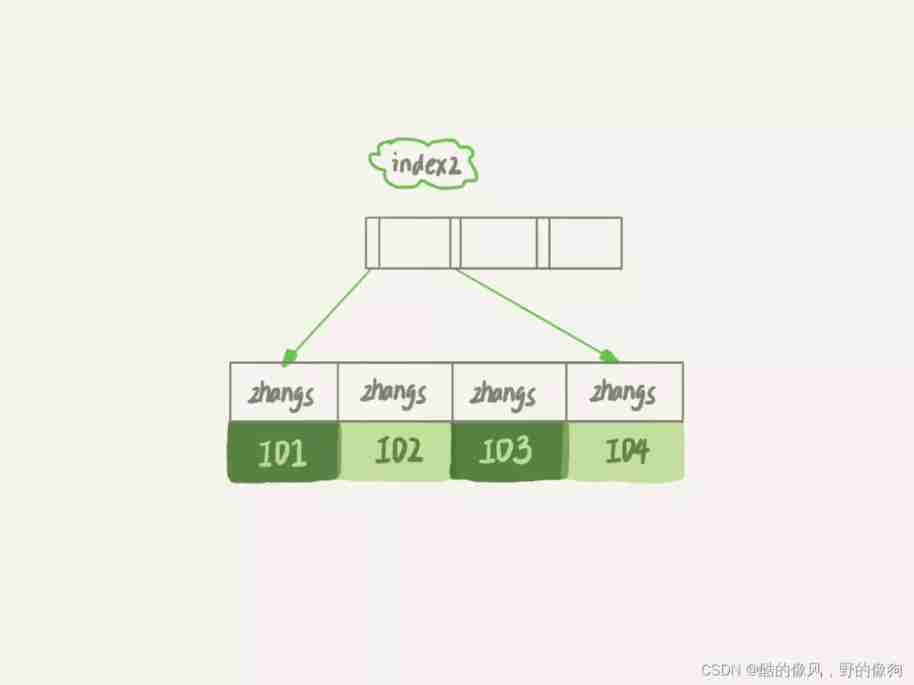
You can see from the picture , because email(6) In this index structure, each mailbox field is taken first 6 Bytes ( namely :zhangs), So it takes less space , This is the advantage of using prefix indexes .
but , The loss that this brings at the same time is , May increase the number of additional record scans .
Next , Let's look at the following statement , How to execute the two index definitions .
select id,name,email from SUser where email='[email protected]';
If you are using index1( namely email The index structure of the entire string ), This is the order of execution :
- from index1 The index tree is found to satisfy the index value ’[email protected]’ This record of , obtain ID2 Value ;
- The primary key value is found on the primary key ID2 The line of , Judge email The value of is correct , Add this line of record to the result set ;
- take index1 The next record of the location just found in the index tree , The discovery is not satisfied email='[email protected]’ The condition of the , The loop ends .
In the process , You only need to retrieve data from the primary key index once , So the system thinks it only scanned one line .
If you are using index2( namely email(6) Index structure ), This is the order of execution :
- from index2 The index tree is found to satisfy the index value ’zhangs’ The record of , The first one we found was ID1;
- The primary key value is found on the primary key ID1 The line of , Determine the email The value is not ’[email protected]’, This record is discarded ;
- take index2 The next record on the location just found , The discovery is still ’zhangs’, Take out ID2, Until then ID Round the row on the index and judge , This time it was right , Add this line of record to the result set ;
- Repeat the previous step , Until idxe2 The value taken up is not ’zhangs’ when , The loop ends .
In the process , To retrieve the primary key index 4 Time data , That's scanning 4 That's ok .
By contrast , You can easily find out , After using prefix index , It can cause query statements to read data more times .
however , For this query statement , If you define index2 No email(6) It is email(7), That is to say, take email First... Of the field 7 To build an index , The prefix is satisfied ’zhangss’ There is only one record for , It can also be found directly ID2, Just scan one line and it's over .
in other words Use prefix index , Define the length , You can save space , There is no need to add too much query cost .
therefore , You have a question : When you want to create a prefix index for a string , What can I do to determine how long I should use the prefix ?
actually , We focus on discrimination when building indexes , The higher the discrimination, the better . Because the higher the discrimination , Means fewer duplicate key values . therefore , We can determine how many prefixes to use by counting how many different values are on the index .
First , You can use the following statement , Figure out how many different values there are in this column :
mysql> select count(distinct email) as L from SUser;
then , Select prefixes of different lengths in turn to see this value , Let's take a look 4~7 Prefix index of bytes , You can use this statement :
mysql>
select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
Of course , Using prefix indexes is likely to lose discrimination , So you need to set an acceptable loss ratio in advance , such as 5%. then , In the returned L4~L7 in , Find out not less than L * 95% Value , Suppose here L6、L7 All satisfied with , You can choose a prefix length of 6.
The influence of prefix index on overlay index
We said that using prefix indexes may increase the number of scan rows , This can affect performance . Actually , The impact of prefix indexing goes beyond that , Let's look at another scene .
Look at this first SQL sentence :
select id,email from SUser where email='[email protected]';
In the previous example SQL sentence
select id,name,email from SUser where email='[email protected]';
comparison , This statement only requires a return id and email Field .
therefore , If you use index1( namely email The index structure of the entire string ) Words , You can use the overlay index , from index1 We got the results and we went back , There's no need to go back ID Check the index again . And if you use index2( namely email(6) Index structure ) Words , I had to go back ID Index to judge email Value of field .
Even if you will index2 The definition of email(18) Prefix index of , At this time, though index2 It already contains all the information , but InnoDB Or go back to id Check the index again , Because the system is not sure whether the definition of prefix index truncates the full information .
in other words , Using prefix index can't optimize query performance with covering index , This is also a factor to consider when choosing whether to use prefix index or not .
The other way
For fields like mailbox , Using a prefix index might work well . however , When the discrimination of prefix is not good enough , What are we going to do ?
such as , Our country's ID number , altogether 18 position , The top 6 Bits are address codes , So the identity card number of the same county is before. 6 Bits are usually the same .
Suppose you maintain a database that is a city's citizen information system , At this time, if the ID number is made to be length. 6 The prefix index of the words , The index has a very low discrimination .
According to the method we mentioned earlier , Maybe you need to create a length of 12 Prefix index above , In order to meet the requirements of discrimination .
however , The longer the index is selected , The more disk space it takes , The less index values the same data page can drop , The less efficient the search will be .
that , If we can determine that only the business needs are equivalent inquiry according to ID card , Is there any other way to deal with it ? This method , It can take up less space , It can also achieve the same query efficiency .
The answer is , yes , we have .
** The first way is to use reverse storage .** If you store your ID card number in reverse , Every time I check , You can write like this :
mysql> select field_list from t where id_card = reverse('input_id_card_string');
Due to the end of the ID number. 6 Bits have no repetition logic such as address codes , So at the end of the day 6 Bits probably provide enough discrimination . Yes, of course , Don't forget to use it in practice count(distinct) Method to do a verification .
** The second way is to use hash Field .** You can create another integer field on the table , To save the verification code of ID card , Also create an index on this field .
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
And then every time you insert a new record , All at the same time crc32() This function gets the check code and fills in the new field . Due to the possible conflict of parity check codes , That is to say, two different ID number passes. crc32() The result of the function may be the same , So your query statement where Some to judge id_card Is the value of exactly the same .
mysql>
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
such , The length of the index becomes 4 Bytes , Much smaller than before .
Next , Let's have a look again Use reverse storage and use hash The similarities and differences between the two methods .
First , What they have in common is , Range queries are not supported . Indexes created on the fields stored in reverse order are sorted in the form of inverted strings , There is no way to find out the ID number by index [ID_X, ID_Y] All the citizens of . similarly ,hash Field can only support equivalent query .
The difference between them , Mainly reflected in the following three aspects :
- In terms of the extra space occupied , The reverse storage mode is on the primary key index , No additional storage is consumed , and hash Field method needs to add a field . Of course , Use of reverse storage mode 4 The prefix length of bytes should not be enough , If it's a little longer , This cost and the extra one hash The fields are almost offset .
- stay CPU Consumption , In reverse order, every time you write and read , All need to be called once more reverse function , and hash The method of the field requires an additional call crc32() function . If only from the complexity of the two functions ,reverse Function extra consumption CPU Resources will be smaller .
- From the perspective of query efficiency , Use hash The query performance of field mode is relatively stable . because crc32 The calculated values have the probability of conflict , But the probability is very small , It can be considered that the average number of scan lines per query is close to 1. And the reverse storage method is still the way of prefix index , In other words, it will increase the number of scanning lines .
Summary
In today's article , I talked to you about the scene of creating indexes in string fields . Let's review , There are ways you can use it :
- Create a full index directly , This may take up more space ;
- Create prefix index , Save a space , But it will increase the number of query scans , And the overlay index cannot be used ;
- Backward storage , Then create a prefix index , The problem of not enough indexing to bypass the prefix of the string itself ;
- establish hash Field index , Query performance is stable , There's extra storage and computing consumption , Like the third way , Range scanning is not supported .
in application , You have to choose which way to use based on the characteristics of the business field .
Okay , It's time for the last question .
If you are maintaining a school student information database , The unified format of student login name is ” Student number @gmail.com", And the rules for student numbers are : Fifteen digit number , The first three digits are the city number 、 The fourth to sixth digit is the school number 、 The tenth to the seventh year of enrollment 、 The last five digits are sequential numbers .
When the system logs in, students are required to enter login name and password , Verify the correctness before continuing to use the system . If we only consider the behavior of login verification , How would you design the index for this login ?
You can write your analysis ideas and design results in the message area , I'll discuss this with you at the end of the next article . Thank you for listening , You are also welcome to share this article with more friends .
Last issue time
The first example in the previous article , Some students in the comment area said that there was no repetition , We need to check if the isolation level is RR(Repeatable Read, Repeatable ), Create a table t Is it right? InnoDB engine . I made the reproduction process into a video , For your reference .
At the end of the last article , My question for you is , Why go through this sequence of operations ,explain The result is wrong ? here , Let me analyze the reason for you .
delete Statement to delete all the data , And then through call idata() Inserted 10 Ten thousand rows of data , It seems to cover the original 10 Line ten thousand .
however ,session A The transaction is enabled and not committed , So what I inserted earlier 10 Ten thousand rows of data cannot be deleted . such , The previous data has two versions for each row of data , The old version was delete Previous data , The new version is marked as deleted The data of .
such , Indexes a There are actually two copies of the data on .
And then you say , Not ah , The data on the primary key cannot be deleted , That didn't use force index The sentence of , Use explain Why is the number of scan lines seen by the command still 100000 about ?( Subtext , If this doubles , Maybe the optimizer also thinks that the selection field a It's better to be an index )
Yes , But this is the primary key , The primary key is estimated directly according to the number of rows in the table . And the number of rows in the table , The optimizer uses show table status Value .
How this value is calculated , I'll give you a detailed explanation in the following article .
+++
12_ Why my MySQL Meeting “ Shaking, ” once ?
In normal work , I don't know if you have ever come across such a scene , One SQL sentence , It's very fast when it comes to normal execution , But sometimes I don't know what's going on , It gets really slow , And it's hard to reproduce this kind of scene , It's not just random , And the duration is short .
it seems , It's like a database “ Shaking, ” For a moment . today , Let's take a look at why .
Yours SQL Why does the sentence change “ slow ” 了
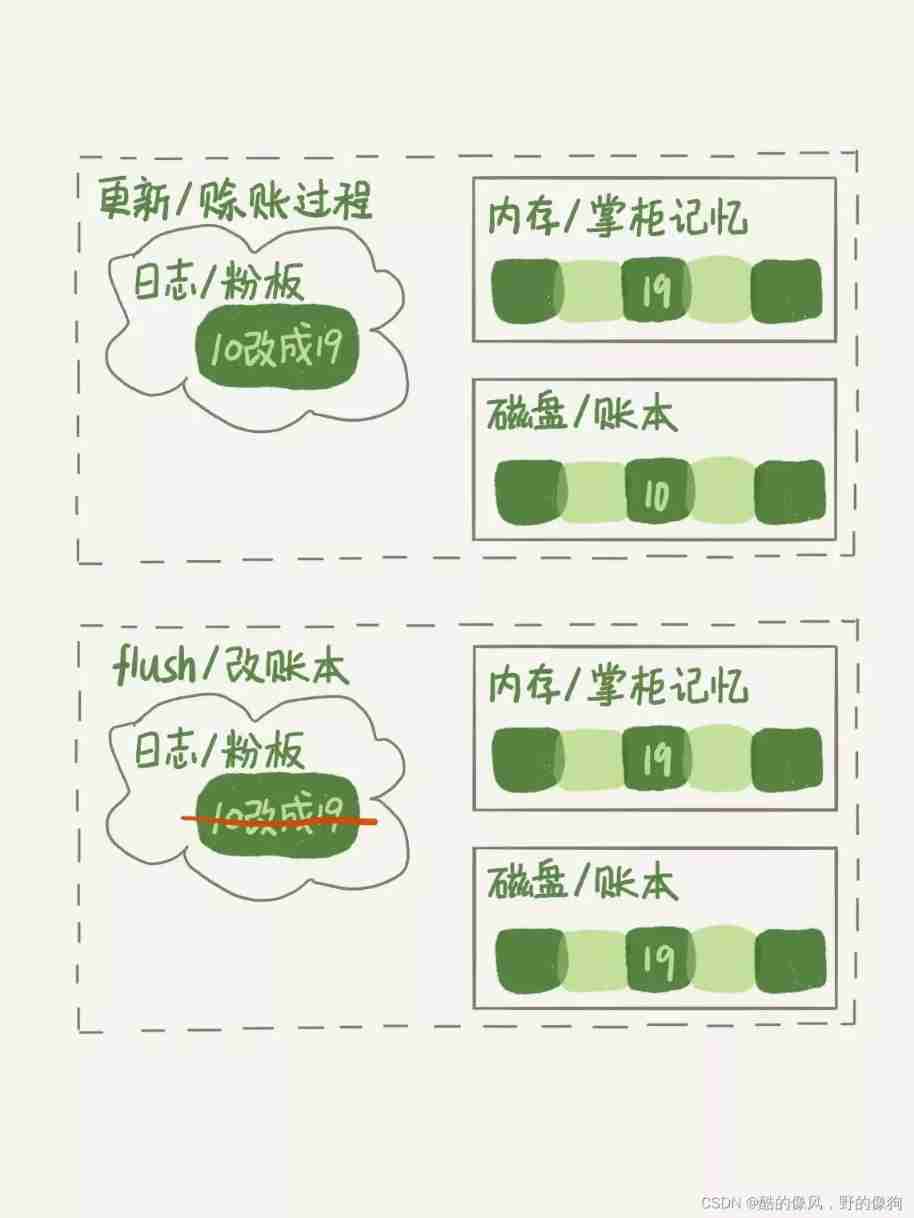
At the front of 2 An article 《 Log system : One SQL How update statements are executed ?》 in , I introduced you to WAL Mechanism . Now you know ,InnoDB When dealing with update statements , I only did the disk operation of writing log . This log is called redo log( Redo log ), That is to say 《 Kong Yiji 》 The powder board used by the shopkeeper of lixianheng hotel for account keeping , After updating the memory redo log after , It's back to the client , This update is successful .
To make an analogy , The bookkeeper's account book is a data file , The powder board used for bookkeeping is a log file (redo log), The manager's memory is memory .
The shopkeeper always needs time to update the account book , This corresponds to the process of writing data from memory to disk , The term is flush. In this flush Before the operation is executed , Kong Yiji's total credit amount , In fact, it is inconsistent with the records in the manager's account book . Because Kong Yiji's credit amount today is only on the powder board , And the records in the books are old , I haven't counted in today's credit .
When the contents of memory data page and disk data page are inconsistent , We call this memory page “ Dirty page ”. After memory data is written to disk , The contents of data pages on memory and disk are the same , be called “ Clean pages ”.
Whether it's dirty or clean , It's all in memory . In this case , Memory corresponds to the manager's memory .
Next , Let's use a diagram to show “ Kong Yiji is on credit ” The whole operation process of . Suppose Kong Yiji is in debt 10 writing , This time I'm going to get credit again 9 writing .
Back to the question at the beginning of the article , You can imagine , Usually perform a quick update operation , It's actually writing memory and logs , and MySQL Once in a while “ Shaking, ” The moment after , Maybe it's a dirty page (flush).
that , What will trigger the database flush How about the process ?
Let's continue to use the example of the manager of the Xianheng Hotel , Think about it : Under what circumstances will the shopkeeper change the credit record on the powder board to the account book ?
- The first scenario is , The powder board is full of , I can't remember . At this time, if someone comes to credit again , The shopkeeper had to put down his work , Erase some of the record on the powder board , Make room for the bookkeeping . Of course, before you wipe it off , He has to record the correct account in the book first . This scene , The corresponding is InnoDB Of redo log It's full. . At this time, the system will stop all update operations , hold checkpoint Push forward ,redo log Make room to continue writing . I drew one in the second lecture redo log Schematic diagram , Here I change it to a ring , So that you can understand .
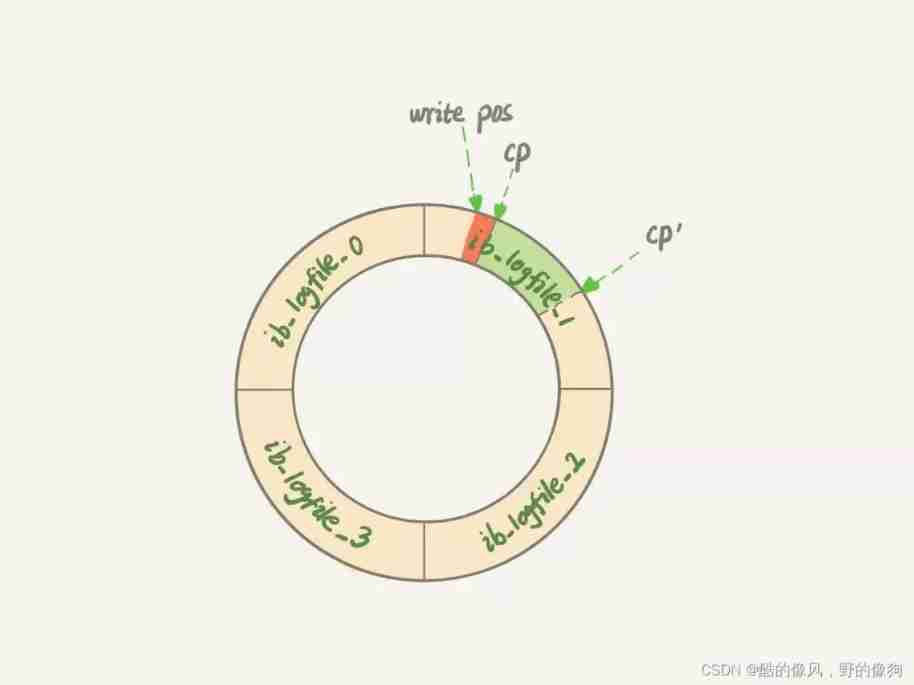
checkpoint It's not just a matter of changing your position . For example 2 in , hold checkpoint Location slave CP Advance to CP’, You need to log between two points ( Light green part ), All the corresponding dirty pages flush To disk . after , From write pos To CP’ Between is can write again redo log Region .
The second scenario is , Business is so good this day , There are too many things to remember , The shopkeeper found that he couldn't remember , Quickly find out the account book and add Kong Yiji's account first .
This scenario , The corresponding is that the system is out of memory . When new memory pages are needed , And when there's not enough memory , We're going to eliminate some data pages , Free up memory for other data pages . If the elimination is “ Dirty page ”, Write dirty pages to disk first .
You must say , Can't we just eliminate the memory at this time , The next time you need a request , Read data pages from disk , Then take redo log Just come out and apply it ? In fact, performance is considered here . If you brush dirty pages, you will write the disk , This ensures that each data page has two states :
- One is the existence of memory , In memory, it must be the right result , Go straight back to ;
- The other is that there is no data in memory , You can be sure that the data file is the correct result , Read into memory and return . This is the most efficient .
The third scenario is , When business is not busy , Or after closing . The counter is fine at this time , The shopkeeper is idle too , It's better to update the account book .
This scenario , The corresponding is MySQL Think of the system as “ Free ” When . Of course ,MySQL“ The hotel ” Our business is going well, but we will soon be able to fill up the powder board , therefore “ manager ” Arrange the time reasonably , Even if it's “ Business is good ” When , We need to find the right time , Just brush a little if you have a chance “ Dirty page ”.
The fourth scenario is , The Xianheng hotel will be closed for a few days at the end of the year , We need to settle the account . At this time, the shopkeeper should record all the accounts in the account book , When it reopens after the new year , We can make clear the account situation from the account book . This scenario , The corresponding is MySQL Normal shut-down conditions . Now ,MySQL Will put all the dirty pages in memory flush To disk , So next time MySQL When it starts , You can read data directly from disk , The start-up speed will be very fast .
Next , You can analyze the performance impact of the above four scenarios .
among , The third case belongs to MySQL Idle operation , There's no pressure on the system , The fourth scenario is that the database is going to be shut down . In both cases , You don't pay too much attention to “ performance ” problem . So here , We will mainly analyze the performance problems in the first two scenarios .
The first is “redo log It's full. , want flush Dirty page ”, In this case InnoDB Try to avoid . Because when this happens , The whole system can no longer accept updates , All updates must be blocked . If you look at the surveillance , At this time, the update number will drop to 0.
The second is “ There's not enough memory , First write dirty pages to disk ”, This is the normal situation .InnoDB Use a buffer pool (buffer pool) Manage memory , Memory pages in the buffer pool have three states :
- The first is , Not yet in use ;
- The second is , Used and clean page ;
- The third is , Used and dirty pages .
InnoDB The strategy is to use memory as much as possible , So for a long-running Library , There are very few unused pages .
And when the data page to be read is not in memory , You have to apply for a data page in the buffer pool . At this time, only the longest unused data page can be eliminated from memory : If it's a clean page to be eliminated , Just release it and reuse it ; But if it's a dirty page , You have to brush the dirty pages to disk first , It can only be reused after it becomes a clean page .
therefore , It's normal to brush dirty pages , But there are two situations , It will obviously affect the performance :
- There are too many dirty pages to be eliminated in a query , The response time of the query will be significantly longer ;
- The log is full of , All updates are blocked , Writing performance has dropped to 0, For sensitive businesses , It is unacceptable .
therefore ,InnoDB There needs to be a mechanism to control the proportion of dirty pages , To try to avoid the above two situations .
InnoDB Control strategy of brushing dirty pages
Next , I'll tell you about it InnoDB Control strategy of dirty pages , And the parameters associated with these policies .
First , You have to tell... Correctly InnoDB Of the host IO Ability , such InnoDB To know when you need to brush dirty pages with all your strength , How fast can I brush .
That's what we need innodb_io_capacity This parameter , It will tell InnoDB Your disk capabilities . I suggest you set this value to disk IOPS. On disk IOPS Can pass fio This tool is used to test , The following statement is the command I use to test random read and write on disk :
fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest
Actually , Because it's not set correctly innodb_io_capacity Parameters , And the resulting performance problems are everywhere . Before , I've been asked by the development director of other companies to see the performance of a library , say MySQL The writing speed of is very slow ,TPS Very low , But the database host IO Not much pressure . After some investigation , The main culprit is that there is a problem with the setting of this parameter .
His host disk uses SSD, however innodb_io_capacity The value of is set to 300. therefore ,InnoDB I think the system's capabilities are so poor , So it's very slow to brush dirty pages , Even slower than dirty page generation , This leads to the accumulation of dirty pages , Affect query and update performance .
Although we have now defined “ Try to brush the dirty pages ” act , But you can't always brush with all your strength ? After all, disk power can't just be used to brush dirty pages , You also need to service user requests . So next , Let's see InnoDB How to control the engine according to “ All out ” Percentage to brush dirty pages .
According to the knowledge I mentioned earlier , Just imagine , If you design strategies to control the speed of dirty pages , What factors will be referred to ?
This question can be thought of as follows , If the brush is too slow , What happens ? First of all, there are too many dirty pages in memory , The second is redo log Write full .
therefore ,InnoDB The speed of the brush disk should refer to these two factors : One is the proportion of dirty pages , One is redo log Write disk speed .
InnoDB According to these two factors, two numbers will be calculated separately .\
Parameters innodb_max_dirty_pages_pct It's the upper limit of dirty pages , The default value is 75%.InnoDB According to the current dirty page ratio ( Assuming that M), Work out a range in 0 To 100 Number between , The pseudo code for calculating this number is like this :
F1(M)
{
if M>=innodb_max_dirty_pages_pct then
return 100;
return 100*M/innodb_max_dirty_pages_pct;
}
InnoDB Every time the log is written, there is a sequence number , The serial number currently written follows checkpoint The difference between the corresponding serial numbers , We assume that N.InnoDB According to this N Work out a range in 0 To 100 Number between , This formula can be written as F2(N).F2(N) The algorithm is complex , You just need to know N The bigger it is , The bigger the value, the better .
then , According to the above calculation F1(M) and F2(N) Two values , Take the larger value and mark it as R, Then the engine can follow innodb_io_capacity The defined ability is multiplied by R% To control the speed of the dirty page .
The above calculation process is more abstract , Not easy to understand , So I drew a simple flow chart . In the picture F1、F2 That's what we did with the dirty page ratio and redo log Two values calculated from the write speed .
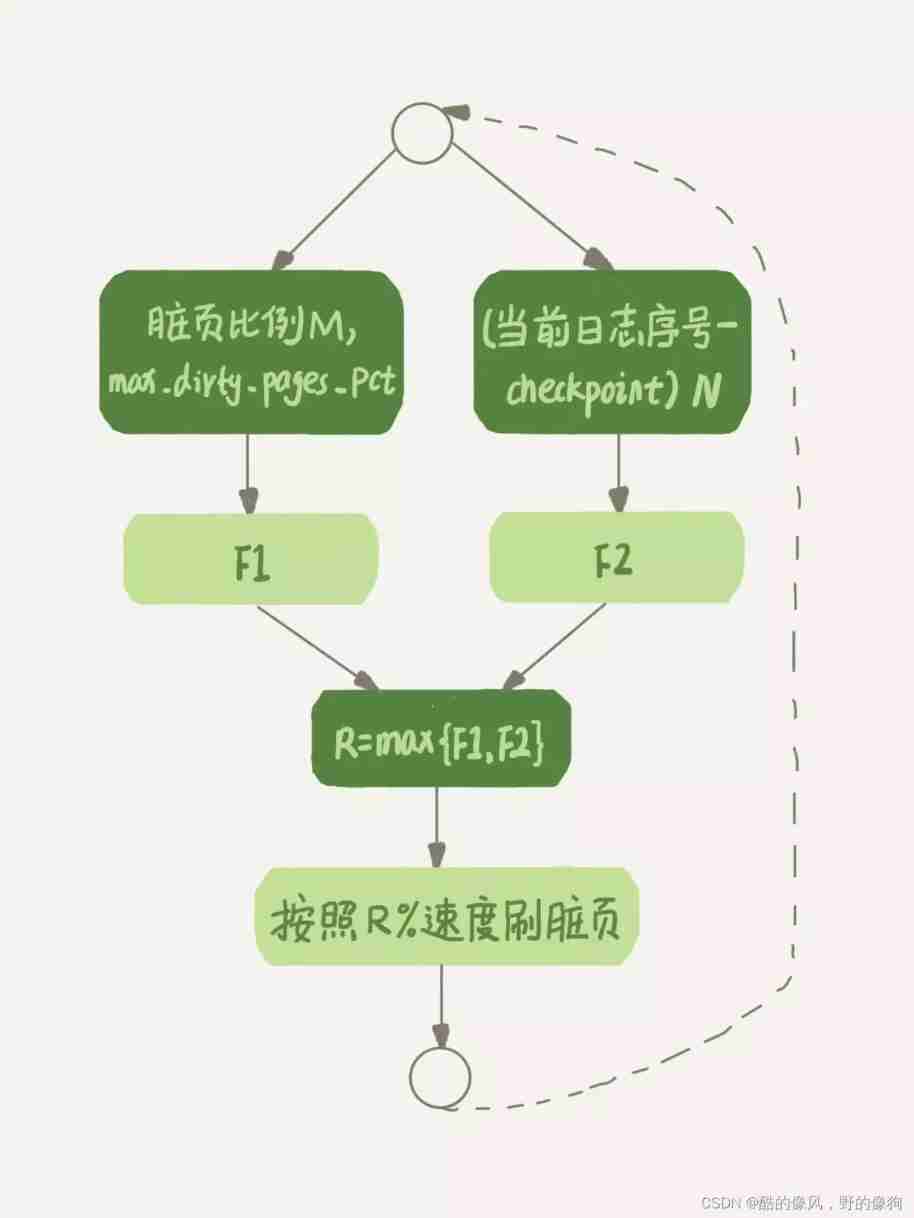
Now you know ,InnoDB Will brush dirty pages in the background , The process of brushing dirty pages is to write memory pages to disk . therefore , Whether your query statement needs memory, it may require that a dirty page be eliminated , Or because the logic of brushing dirty pages will occupy IO Resources and may affect your update statements , It may cause you to perceive from the business side that MySQL“ Shaking, ” The reason for that .
Try to avoid this situation , You have to set up innodb_io_capacity Value , also Usually pay more attention to the proportion of dirty pages , Don't let it get close to 75%.
among , The dirty page ratio is through Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total Got , Refer to the following code for specific commands :
mysql>
select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty';
select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total';
select @a/@b;
Next , Let's look at another interesting strategy .
Once a query request needs to be executed first flush When you drop a dirty page , This query may be slower than usual . and MySQL One of the mechanisms in , It may make your query slower : When you are going to brush a dirty page , If the data page next to this data page happens to be a dirty page , It will “ neighbor ” Take it with you and brush it off ; And this one “ neighbor ” The logic of dragging water can continue to spread , That is, for each neighbor data page , If the data page adjacent to it is still dirty , And they'll be put together to brush .
stay InnoDB in ,innodb_flush_neighbors Parameters are used to control this behavior , The value is 1 There will be the above “ Continuous sitting ” Mechanism , The value is 0 When you don't look for a neighbor , Paint your own .
look for “ neighbor ” This optimization is very meaningful in the era of mechanical hard disk , Can reduce a lot of randomness IO. Mechanical hard disk random IOPS Usually only a few hundred , The same logical operation reduces randomness IO It means that the system performance is greatly improved .
And if you use SSD This kind of IOPS If the equipment is relatively high , I suggest you put innodb_flush_neighbors The value of is set to 0. Because at this time IOPS It's not a bottleneck , and “ Just brush yourself ”, You can quickly perform the necessary operations to brush dirty pages , Reduce SQL Statement response time .
stay MySQL 8.0 in ,innodb_flush_neighbors The default value of the parameter is already 0 了 .
Summary
Today's article , I continue with the first 2 The article introduces WAL The concept of , And you explained the mechanism of the subsequent need to brush dirty page operation and execution timing . utilize WAL technology , The database converts random writes to sequential writes , Greatly improve the performance of the database .
however , This also brings about the problem of dirty pages in memory . Dirty pages will be automatically flush, It's also triggered by data page obsolescence flush, And the process of brushing dirty pages will occupy resources , May make your update and query statement response time longer . In the article , I also introduced the method of controlling the dirty page and the corresponding monitoring method .
At the end of the article , Let me leave you a question to think about .
One memory configuration is 128GB、innodb_io_capacity Set to 20000 Example of a large specification of , Normal would suggest that you will redo log Set to 4 individual 1GB The file of .
But if you accidentally configure it, you will redo log Set up a 1 individual 100M The file of , What's going to happen ? Why does this happen ?
Last issue time
The question I left you in the last issue is , Create an index for a student number field , What are the methods .
Because of the rules of this student number , Whether it is a forward or reverse prefix index , The repeatability is relatively high . Because the maintenance is only a school , So the front 6 position ( among , The first three digits are the city number 、 The fourth to sixth digit is the school number ) It's fixed , The suffixes are all @gamil.com, Therefore, only the academic year shares can be stored with serial numbers , They are the length 9 position .
In fact, on this basis , You can use a number type to store this 9 Digit number . such as 201100001, This only needs to occupy 4 Bytes . In fact, this is a kind of hash, It's just that it uses the simplest conversion rules : Rules for converting strings to numbers , And that's exactly the background we set , It can guarantee the uniqueness of the transformed result .
Comment area , There are also some other good ideas .
Comment users @ Feudal wind say , The total number of people in a school ,50 Only then 100 Ten thousand students , This watch must be a small watch . For business simplicity , Save the original string directly . This reply contains “ Optimize costs and benefits ” Thought , I think it's worth it at come out .
@ Pan The student proposed another extreme direction . If you encounter a scenario with a large amount of table data , The benefits of this way are very good .
Comment area message and praise board :
@lttzzlll , Mentioned using integer storage “ Four years + Five digit number ” Methods ; Because the value of the whole student ID exceeds int ceiling ,@ Comrade Lao Yang Also mentioned the use of 8 Bytes of bigint The way to save .
边栏推荐
- notepad++如何统计单词数量
- Su Weijie, a member of Qingyuan Association and an assistant professor at the University of Pennsylvania, won the first Siam Youth Award for data science, focusing on privacy data protection, etc
- 电子协会 C语言 1级 34 、分段函数
- Rhcsa day 3
- 电脑通过Putty远程连接树莓派
- Unity opens the explorer from the inspector interface, selects and records the file path
- Finishing (III) - Exercise 2
- [Flink] temporal semantics and watermark
- Novel website program source code that can be automatically collected
- [FreeRTOS] FreeRTOS learning notes (7) - handwritten FreeRTOS two-way linked list / source code analysis
猜你喜欢

Used on windows Bat file startup project
How to share the source code anti disclosure scheme
What is industrial computer encryption and how to do it

Valentine's Day is coming! Without 50W bride price, my girlfriend was forcibly dragged away...
System architecture design of circle of friends

The number of patent applications in China has again surpassed that of the United States and Japan, ranking first in the world for 11 consecutive years
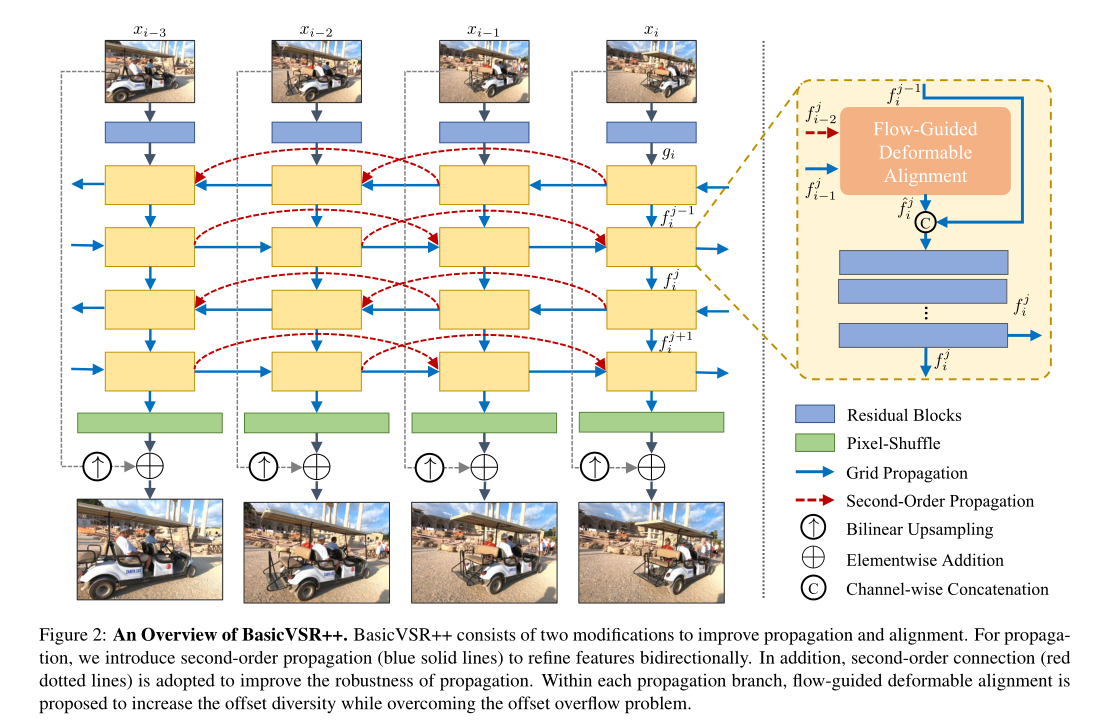
BasicVSR++: Improving Video Super-Resolutionwith Enhanced Propagation and Alignment
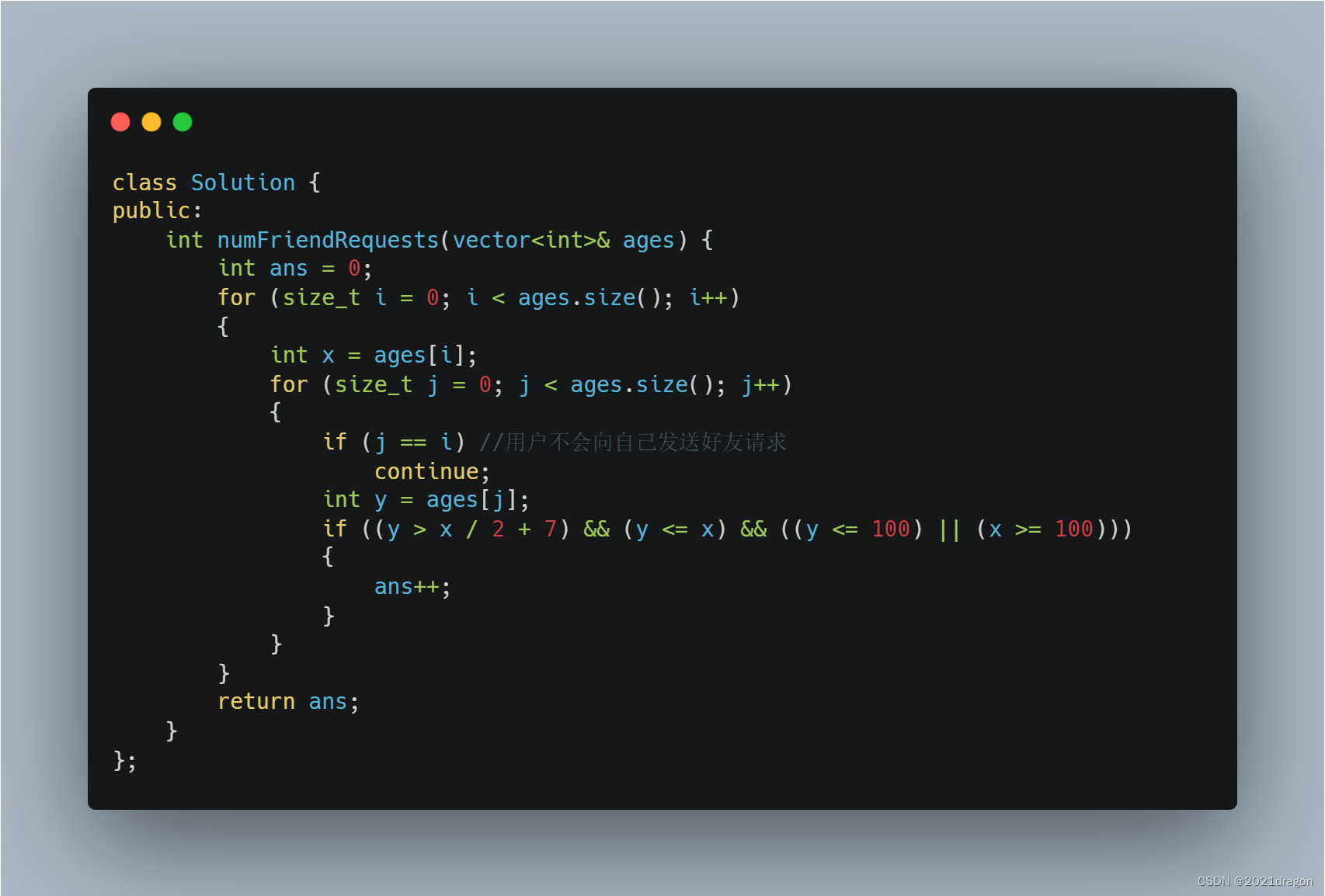
leetcode825. Age appropriate friends
大厂技术专家:架构设计中常用的思维模型

Master-slave replication principle of MySQL database
随机推荐
在所有SwiftUI版本(1.0-4.0)中原生实现Charts图表视图之思路
Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and
Pangu open source: multi support and promotion, the wave of chip industry
The most effective futures trend strategy: futures reverse merchandising
博客停更声明
Zephyr 学习笔记2,Scheduling
The number of patent applications in China has again surpassed that of the United States and Japan, ranking first in the world for 11 consecutive years
Basic DOS commands
The crackdown on Huawei prompted made in China to join forces to fight back, and another enterprise announced to invest 100 billion in R & D
the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
There is no Chinese prompt below when inputting text in win10 Microsoft Pinyin input method
Oceanbase is the leader in the magic quadrant of China's database in 2021
Campus network problems
Blue Bridge Cup Quick sort (code completion)
Boast about Devops
2022-021ARTS:下半年開始
NLP literature reading summary
大学阶段总结
[untitled] notice on holding "2022 traditional fermented food and modern brewing technology"
[Chongqing Guangdong education] National Open University spring 2019 770 real estate appraisal reference questions