当前位置:网站首页>Introduction to spark core components
Introduction to spark core components
2022-07-04 06:51:00 【A program ape with wet writing】
Spark core Component is introduced
1、RDD Introduce
Spark The core of is to build on a unified elastic distributed data set (Resilient Distributed Datasets,RDD) Above , This makes Spark The components of can be seamlessly integrated , Be able to complete big data processing in the same application .
RDD It is actually an abstraction of a distributed data set , In terms of physical storage , A dataset may be divided into multiple partitions , Each partition may be stored in different storage / On calculation node , and RDD Is an abstraction on the dataset , Represents the entire data set , But this RDD It doesn't physically put data together .
With RDD This abstraction , Users can easily operate a distributed data set from a portal .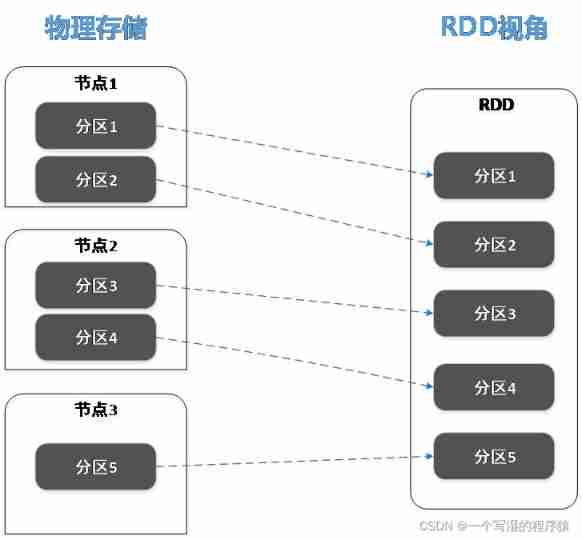
RDD With fault tolerance mechanism , And it is read-only and cannot be modified , You can perform certain conversion operations to create new RDD.
2、RDD Basic operation
RDD Provides a large number of API For users , There are two main categories :transformation and action.
(1)Transformation be used for RDD Deformation of (RDD Have no variability ), Every time transformation Will produce new RDD;
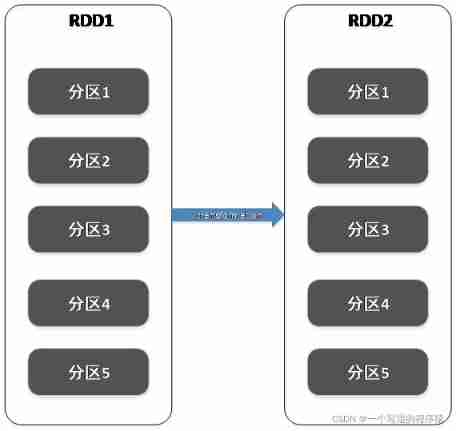
(2)Action It is usually used for the summary or output of results ;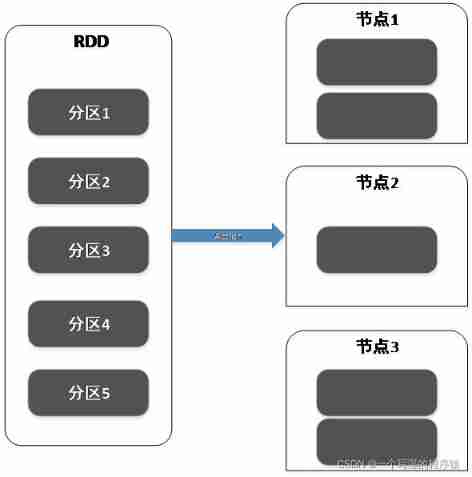
3、dependency Introduce
stay DAG In the figure ,RDD And RDD The connection between them is called dependency (dependency)
And dependencies are divided into narrow dependencies (Narrow Dependency) And wide dependence (Shuffle Dependency)
(1) In narrow dependence , Father RDD Every one of partition, Only quilt RDD One of the partition rely on 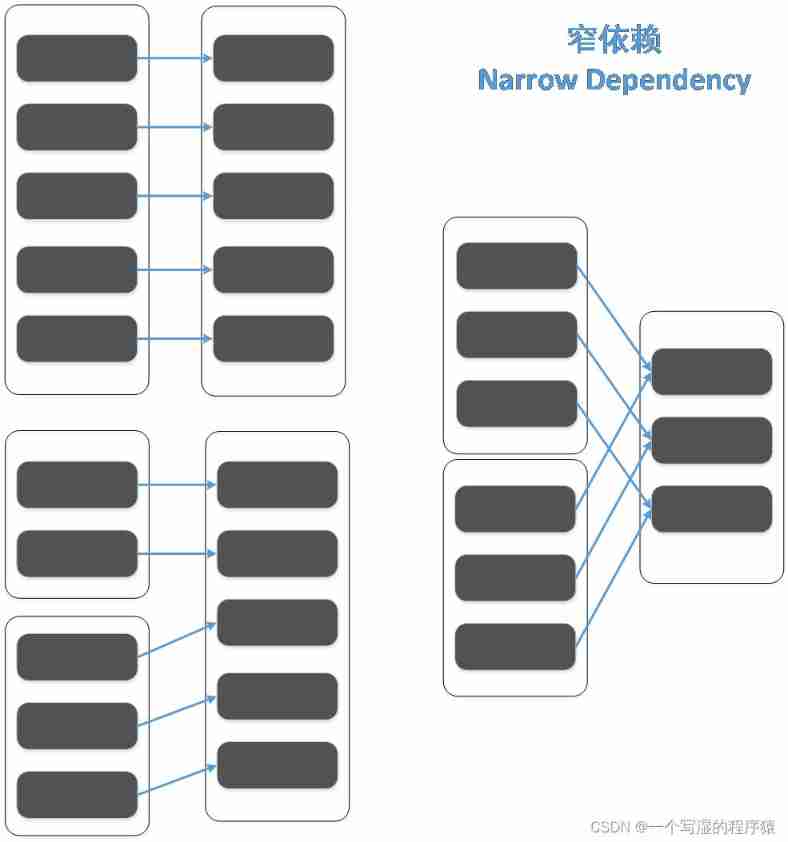
(2) In wide dependence , Father RDD One of the partition, The quilt RDD The multiple partition rely on 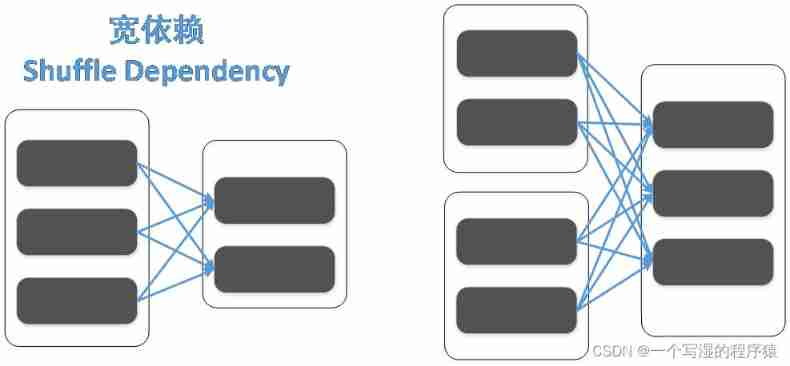
4、Job Introduce
stay Spark Every time action Will trigger the real computation , and transformation Just record the calculation steps , Not actually calculated . Will each time action The calculation triggered is called :Job

Every time transformation Will generate a new RDD, and action You can view it as Job Output
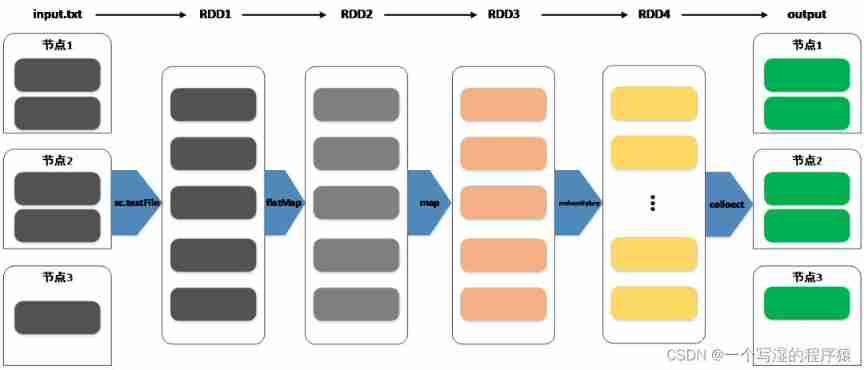
Spark Each of them Job, Can be seen as RDD After several deformations and then output
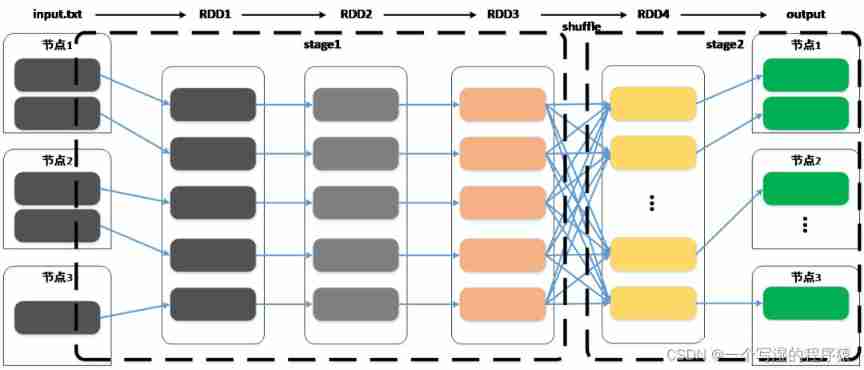
RDD In the process of deformation, many new RDD, To form a system of RDD Constitute the execution flow chart (DAG)

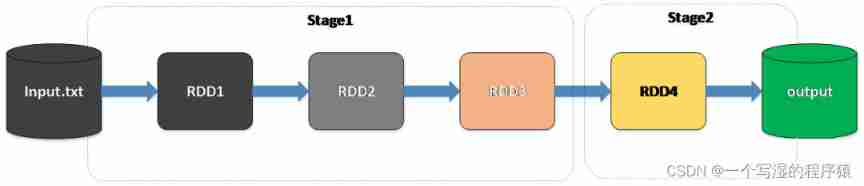
5、Stage Introduce
Spark On schedule DAG when , Instead of directly executing the operations of each node in turn , It's about putting the whole DAG Divide into different Stage
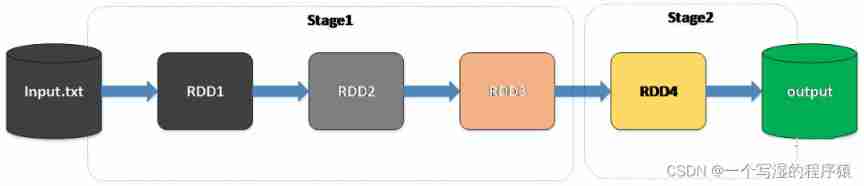
When scheduling , From the last Stage Start submission , If it's time to Stage The father of Stage Not completed , Then recursively submit its father Stage, Until there is no father Stage Or all fathers Stage Completed
6、Shuffle Introduce
Why? spark To divide Stage Instead of directly following the steps ?
Spark In dividing stage when , Every time we encounter a wide dependency , Then draw a new stage, Because whenever we encounter wide dependence , It has to be done once “ Data shuffle ” operation (shuffle)
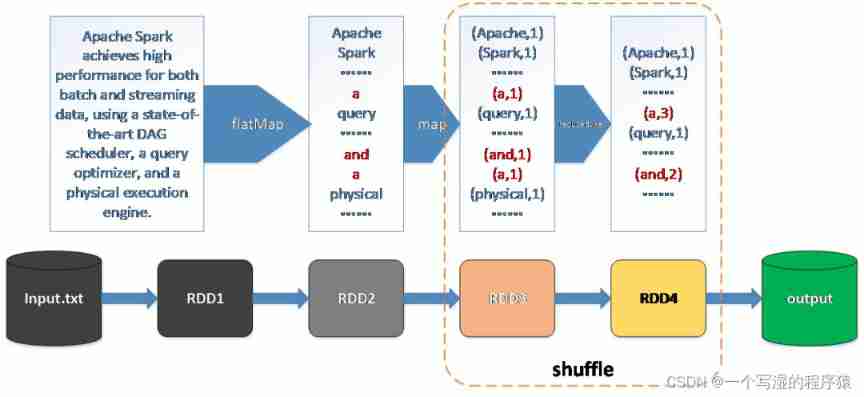
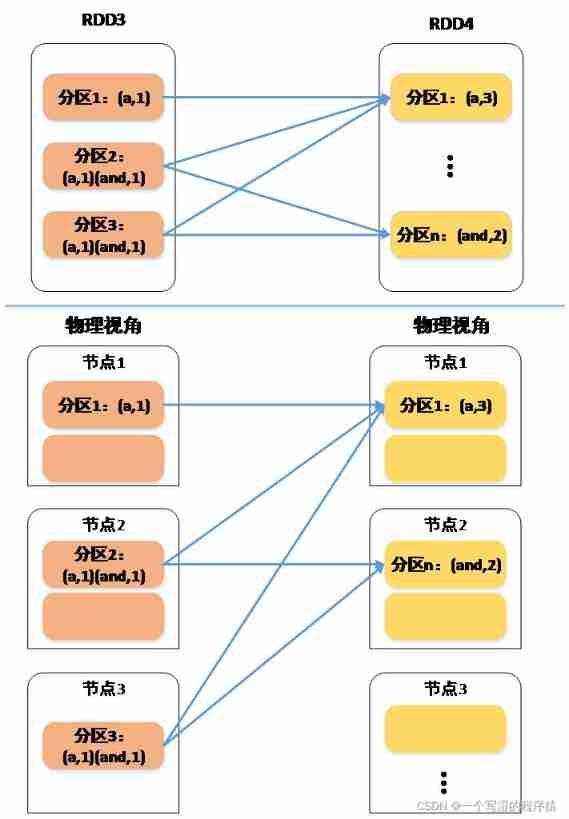
Shuffle occurs ( Wide dependence )
from RDD From the perspective of , Is the parent partition different key The data of is distributed to sub partitions , The parent partition has different key So there are different sub partitions that depend on it
From a physical point of view , Different partitions are distributed on different nodes , In this case, you need to move data from one node to another , Data movement has occurred ;
because shuffle The process involves data movement , therefore ,Spark Press to trigger shuffle Wide dependency partition of Stage, Divided by Stage,Stage We need to exchange data between them , It involves network transmission and disk IO, and Stage Internal operations , Then there is no need to drop the plate , Continuous calculation can be carried out directly in memory , It greatly accelerates the calculation speed , This is also spark The claim is based on “ Memory computing ” Important reasons .
Shuffle The process will DAG Divided into a number of Stage, bring Spark When scheduling , We can use Stage Scheduling at the same granularity ,
Such a scheduling mode , Can make the same Stage Continuously on the same computing node ,Stage Internal can exchange data in memory for efficient calculation , and Stage Between them, through Shuffle Exchange data .
On the other hand ,Spark By abstracting computation into task, To unify api, Realized with RDD Different operations of data and shuffle The process .
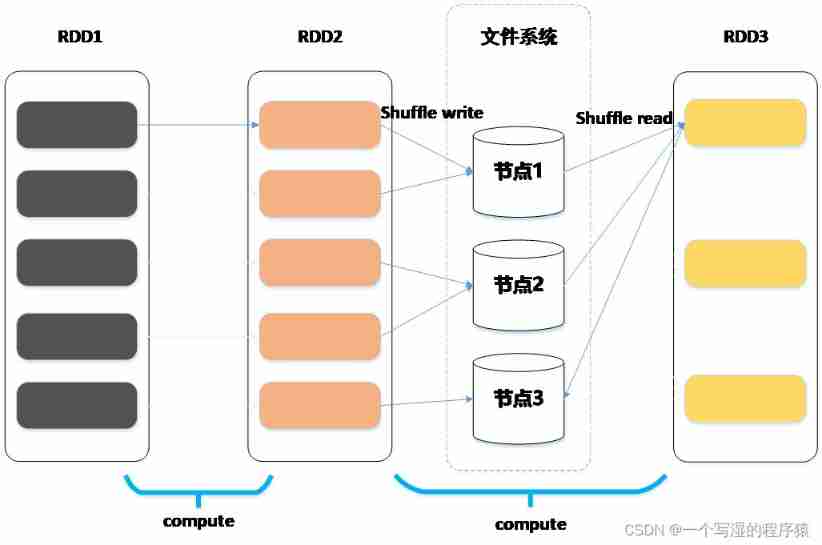
7、Task Introduce
The real calculation takes place in Executor Implemented in Task, Every Task Only responsible for one partition The calculation of , Every RDD All must be realized compute Method , This method defines how to calculate a single partition.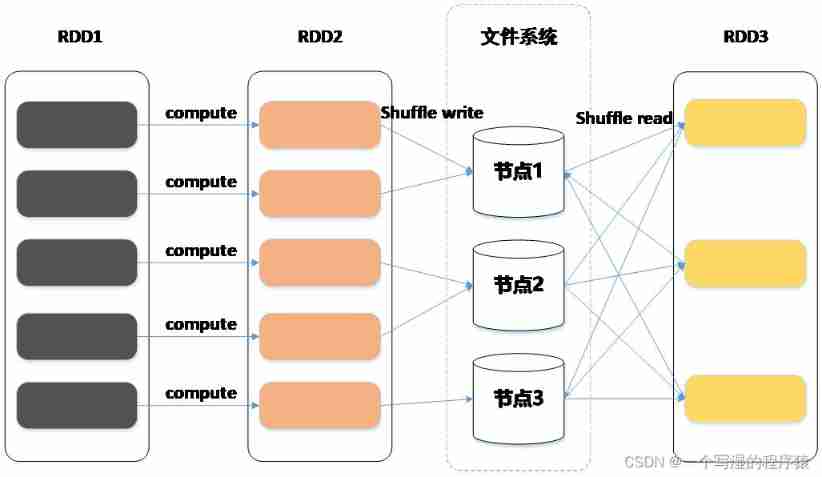
(1)Task Implementation
By multiple RDD Of compute The method forms the whole calculation chain , stay shuffle when , Father RDD Of compute Method will complete shuffle write operation , Son RDD Of compute Method will complete shuffle read operation , The cooperation between the two has been completed shuffle operation
such Spark Just through RDD Unified compute Method , Completed the whole calculation chain .
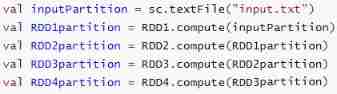
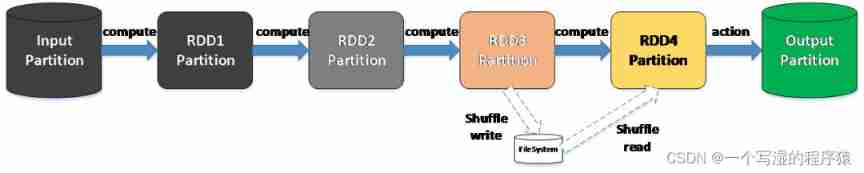
Horizontal perspective -partition The calculation of
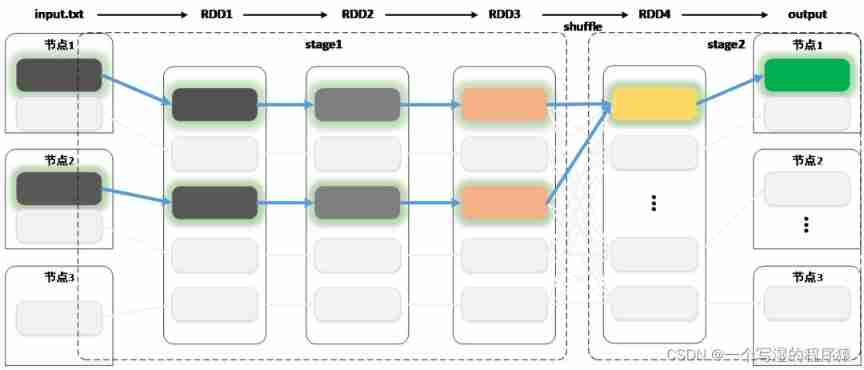
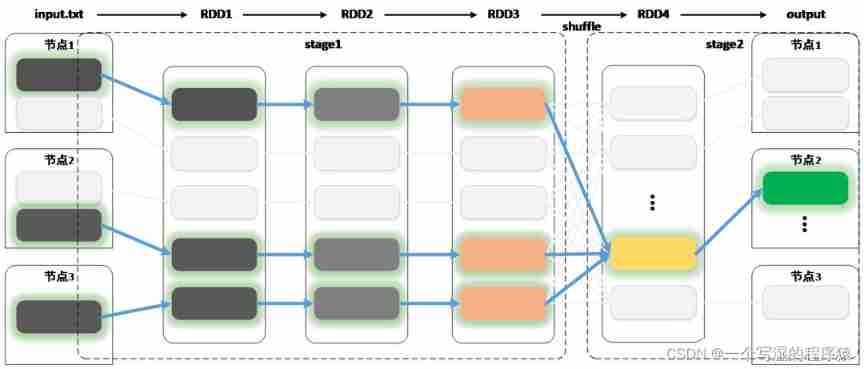
Summary
Look vertically , Every calculation process , Will form a RDD, all RDD And dependencies make up DAG,Shuffle The process will DAG Divided into... One by one Stage
Look horizontally , every last partition Calculation of data , It depends on the last RDD( Or document ) Corresponding partition Calculated as input data , The whole data calculation process , Every partition Its dependence constitutes the whole computing chain
Horizontal perspective provides RDD Unified high-level abstract features , Users don't have to worry about whether there is shuffle This kind of operation , Just care RDD Data transformation of , Greatly simplifies the programming model
The vertical perspective provides stage Level scheduling , Make unified stage There is no need to drop all calculations in , Greatly improve the calculation speed
边栏推荐
- GoogleChromePortable 谷歌chrome浏览器便携版官网下载方式
- 测试用例的设计
- 【网络数据传输】基于FPGA的百兆网/兆网千UDP数据包收发系统开发,PC到FPGA
- The final week, I split
- Latex中的单引号,双引号如何输入?
- tars源码分析之9
- Tar source code analysis 4
- [problem record] 03 connect to MySQL database prompt: 1040 too many connections
- Mysql 45讲学习笔记(十一)字符串字段怎么加索引
- R statistical mapping - random forest classification analysis and species abundance difference test combination diagram
猜你喜欢
Selenium driver ie common problem solving message: currently focused window has been closed
R statistical mapping - random forest classification analysis and species abundance difference test combination diagram

ORICO ORICO outdoor power experience, lightweight and portable, the most convenient office charging station
the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
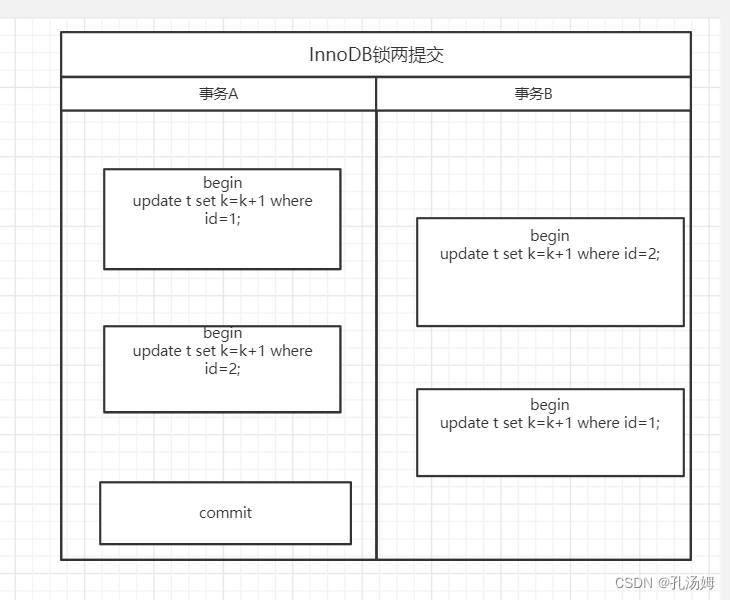
Mysql 45讲学习笔记(七)行锁

【MySQL】数据库视图的介绍、作用、创建、查看、删除和修改(附练习题)
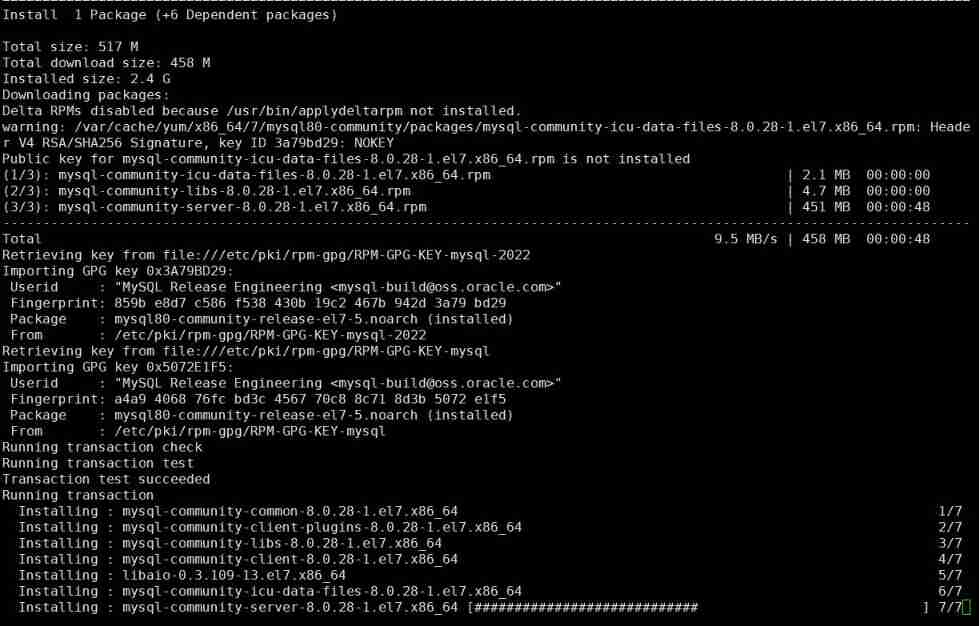
MySQL relearn 2- Alibaba cloud server CentOS installation mysql8.0
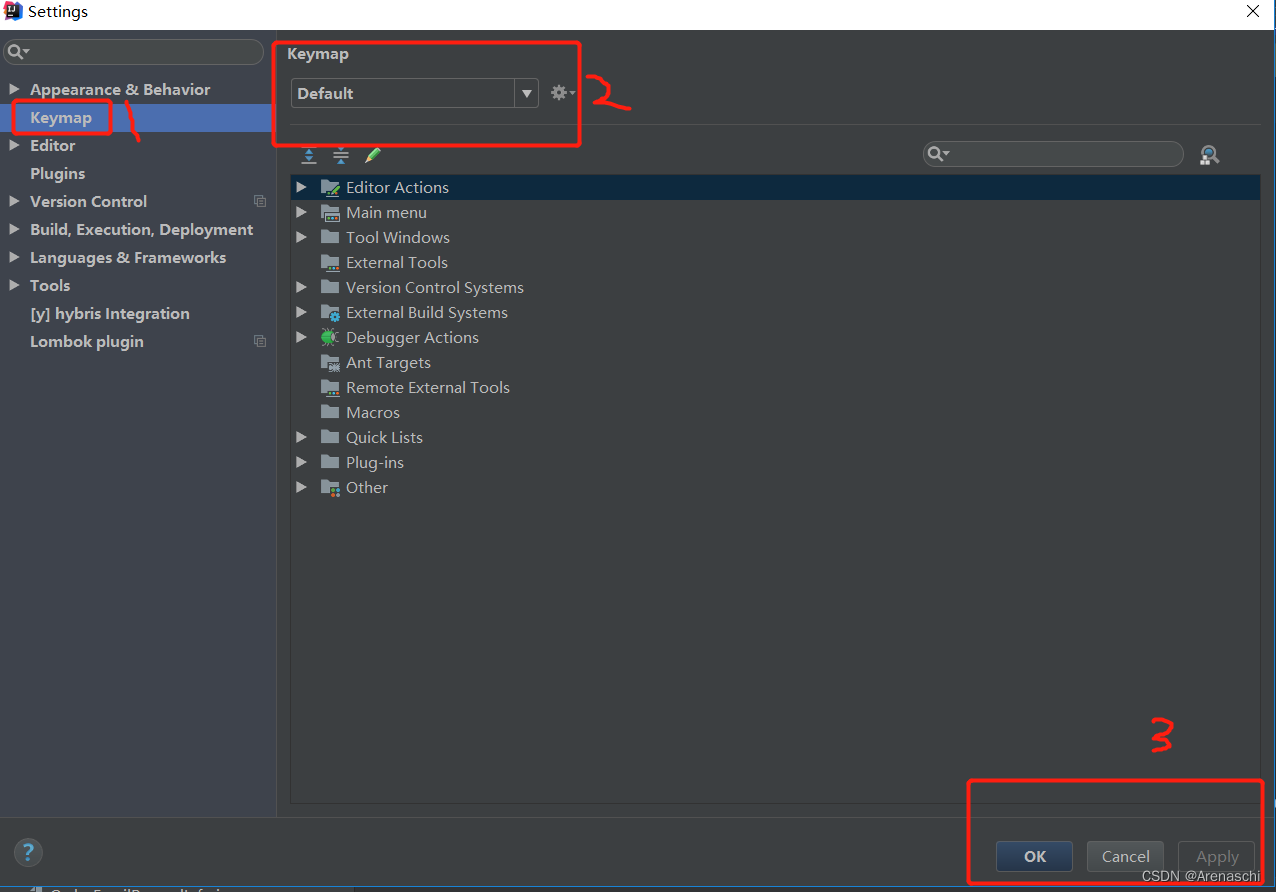
关于IDEA如何设置快捷键集
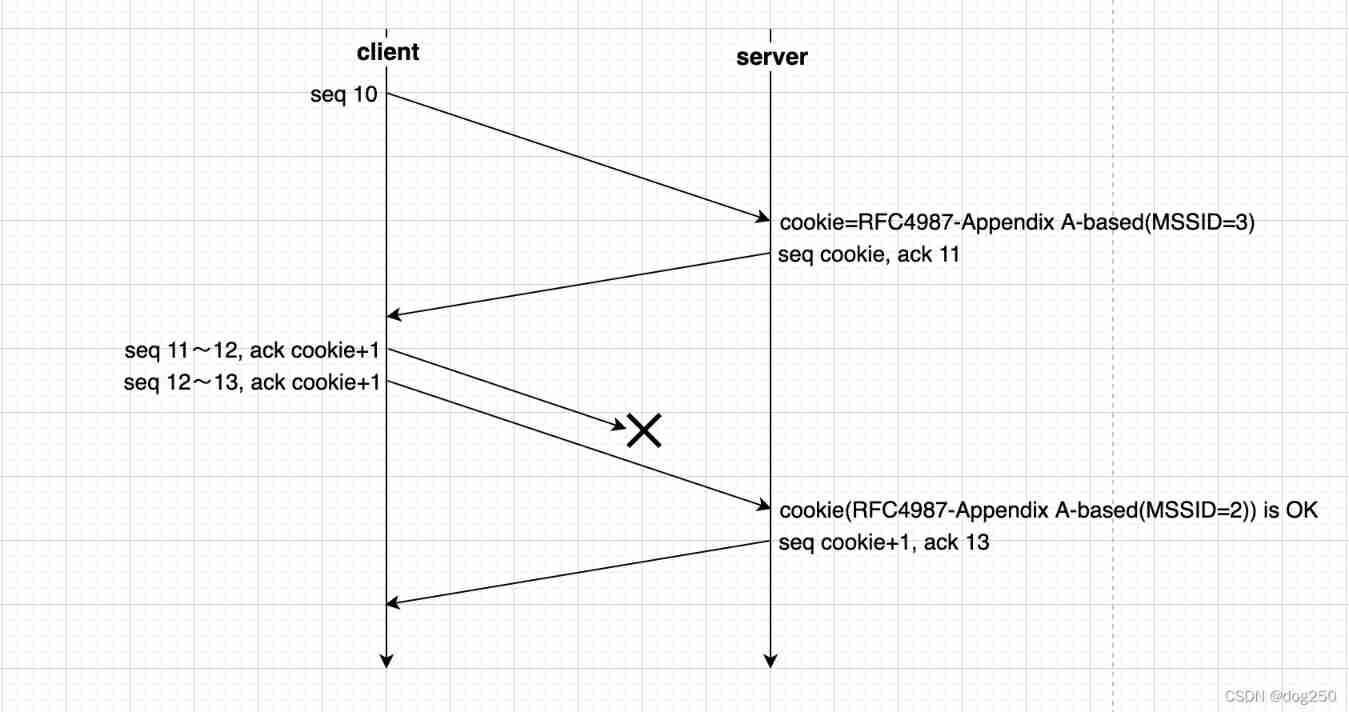
Can the out of sequence message complete TCP three handshakes

2022 where to find enterprise e-mail and which is the security of enterprise e-mail system?
随机推荐
centos8安装mysql.7 无法开机启动
tars源码分析之7
【网络数据传输】基于FPGA的百兆网/兆网千UDP数据包收发系统开发,PC到FPGA
MySQL 45 lecture learning notes (VII) line lock
Realize IIC data / instruction interaction with micro batg135
tars源码分析之1
Google Chrome Portable Google Chrome browser portable version official website download method
About how idea sets up shortcut key sets
Tar source code analysis 9
【GF(q)+LDPC】基于二值图GF(q)域的规则LDPC编译码设计与matlab仿真
Tar source code analysis Part 2
Selection (021) - what is the output of the following code?
what the fuck! If you can't grab it, write it yourself. Use code to realize a Bing Dwen Dwen. It's so beautiful ~!
Selection (023) - what are the three stages of event propagation?
leetcode825. 适龄的朋友
金盾视频播放器拦截的软件关键词和进程信息
Tar source code analysis 8
C # symmetric encryption (AES encryption) ciphertext results generated each time, different ideas, code sharing
Tar source code analysis Part 10
js 常用时间处理函数