当前位置:网站首页>go-zero微服务实战系列(九、极致优化秒杀性能)
go-zero微服务实战系列(九、极致优化秒杀性能)
2022-07-04 13:35:00 【kevwan】
上一篇文章中引入了消息队列对秒杀流量做削峰的处理,我们使用的是Kafka,看起来似乎工作的不错,但其实还是有很多隐患存在,如果这些隐患不优化处理掉,那么秒杀抢购活动开始后可能会出现消息堆积、消费延迟、数据不一致、甚至服务崩溃等问题,那么后果可想而知。本篇文章我们就一起来把这些隐患解决掉。
批量数据聚合
在SeckillOrder这个方法中,每来一次秒杀抢购请求都往往Kafka中发送一条消息。假如这个时候有一千万的用户同时来抢购,就算我们做了各种限流策略,一瞬间还是可能会有上百万的消息会发到Kafka,会产生大量的网络IO和磁盘IO成本,大家都知道Kafka是基于日志的消息系统,写消息虽然大多情况下都是顺序IO,但当海量的消息同时写入的时候还是可能会扛不住。
那怎么解决这个问题呢?答案是做消息的聚合。之前发送一条消息就会产生一次网络IO和一次磁盘IO,我们做消息聚合后,比如聚合100条消息后再发送给Kafka,这个时候100条消息才会产生一次网络IO和磁盘IO,对整个Kafka的吞吐和性能是一个非常大的提升。其实这就是一种小包聚合的思想,或者叫Batch或者批量的思想。这种思想也随处可见,比如我们使用Mysql插入批量数据的时候,可以通过一条SQL语句执行而不是循环的一条一条插入,还有Redis的Pipeline操作等等。
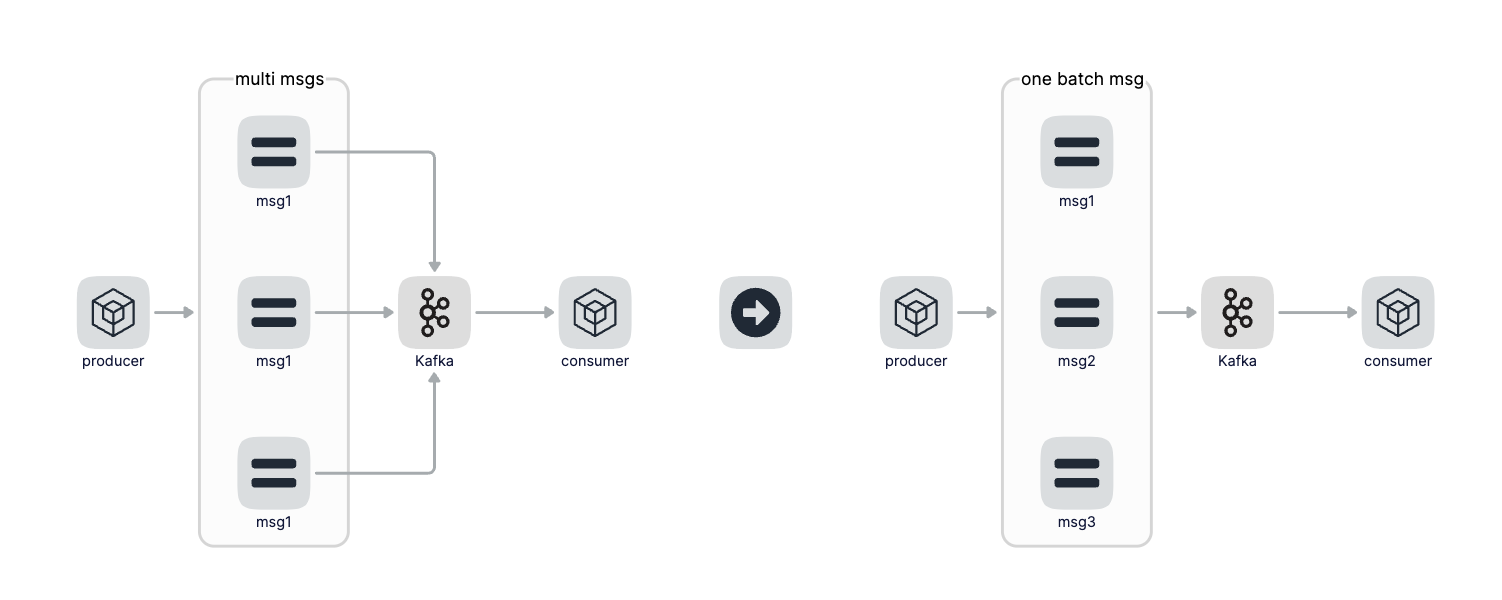
那怎么来聚合呢,聚合策略是啥呢?聚合策略有两个维度分别是聚合消息条数和聚合时间,比如聚合消息达到100条我们就往Kafka发送一次,这个条数是可以配置的,那如果一直也达不到100条消息怎么办呢?通过聚合时间来兜底,这个聚合时间也是可以配置的,比如配置聚合时间为1秒钟,也就是无论目前聚合了多少条消息只要聚合时间达到1秒,那么就往Kafka发送一次数据。聚合条数和聚合时间是或的关系,也就是只要有一个条件满足就触发。
在这里我们提供一个批量聚合数据的工具Batcher,定义如下
type Batcher struct { opts options Do func(ctx context.Context, val map[string][]interface{}) Sharding func(key string) int chans []chan *msg wait sync.WaitGroup}Do方法:满足聚合条件后就会执行Do方法,其中val参数为聚合后的数据
Sharding方法:通过Key进行sharding,相同的key消息写入到同一个channel中,被同一个goroutine处理
在merge方法中有两个触发执行Do方法的条件,一是当聚合的数据条数大于等于设置的条数,二是当触发设置的定时器
代码实现比较简单,如下为具体实现:
type msg struct { key string val interface{}}type Batcher struct { opts options Do func(ctx context.Context, val map[string][]interface{}) Sharding func(key string) int chans []chan *msg wait sync.WaitGroup}func New(opts ...Option) *Batcher { b := &Batcher{} for _, opt := range opts { opt.apply(&b.opts) } b.opts.check() b.chans = make([]chan *msg, b.opts.worker) for i := 0; i < b.opts.worker; i++ { b.chans[i] = make(chan *msg, b.opts.buffer) } return b}func (b *Batcher) Start() { if b.Do == nil { log.Fatal("Batcher: Do func is nil") } if b.Sharding == nil { log.Fatal("Batcher: Sharding func is nil") } b.wait.Add(len(b.chans)) for i, ch := range b.chans { go b.merge(i, ch) }}func (b *Batcher) Add(key string, val interface{}) error { ch, msg := b.add(key, val) select { case ch <- msg: default: return ErrFull } return nil}func (b *Batcher) add(key string, val interface{}) (chan *msg, *msg) { sharding := b.Sharding(key) % b.opts.worker ch := b.chans[sharding] msg := &msg{key: key, val: val} return ch, msg}func (b *Batcher) merge(idx int, ch <-chan *msg) { defer b.wait.Done() var ( msg *msg count int closed bool lastTicker = true interval = b.opts.interval vals = make(map[string][]interface{}, b.opts.size) ) if idx > 0 { interval = time.Duration(int64(idx) * (int64(b.opts.interval) / int64(b.opts.worker))) } ticker := time.NewTicker(interval) for { select { case msg = <-ch: if msg == nil { closed = true break } count++ vals[msg.key] = append(vals[msg.key], msg.val) if count >= b.opts.size { break } continue case <-ticker.C: if lastTicker { ticker.Stop() ticker = time.NewTicker(b.opts.interval) lastTicker = false } } if len(vals) > 0 { ctx := context.Background() b.Do(ctx, vals) vals = make(map[string][]interface{}, b.opts.size) count = 0 } if closed { ticker.Stop() return } }}func (b *Batcher) Close() { for _, ch := range b.chans { ch <- nil } b.wait.Wait()}使用的时候需要先创建一个Batcher,然后定义Batcher的Sharding方法和Do方法,在Sharding方法中通过ProductID把不同商品的聚合投递到不同的goroutine中处理,在Do方法中我们把聚合的数据一次性批量的发送到Kafka,定义如下:
b := batcher.New( batcher.WithSize(batcherSize), batcher.WithBuffer(batcherBuffer), batcher.WithWorker(batcherWorker), batcher.WithInterval(batcherInterval),)b.Sharding = func(key string) int { pid, _ := strconv.ParseInt(key, 10, 64) return int(pid) % batcherWorker}b.Do = func(ctx context.Context, val map[string][]interface{}) { var msgs []*KafkaData for _, vs := range val { for _, v := range vs { msgs = append(msgs, v.(*KafkaData)) } } kd, err := json.Marshal(msgs) if err != nil { logx.Errorf("Batcher.Do json.Marshal msgs: %v error: %v", msgs, err) } if err = s.svcCtx.KafkaPusher.Push(string(kd)); err != nil { logx.Errorf("KafkaPusher.Push kd: %s error: %v", string(kd), err) }}s.batcher = bs.batcher.Start()在SeckillOrder方法中不再是每来一次请求就往Kafka中投递一次消息,而是先通过batcher提供的Add方法添加到Batcher中等待满足聚合条件后再往Kafka中投递。
err = l.batcher.Add(strconv.FormatInt(in.ProductId, 10), &KafkaData{Uid: in.UserId, Pid: in.ProductId})if err!= nil { logx.Errorf("l.batcher.Add uid: %d pid: %d error: %v", in.UserId, in.ProductId, err)}降低消息的消费延迟
通过批量消息处理的思想,我们提供了Batcher工具,提升了性能,但这主要是针对生产端而言的。当我们消费到批量的数据后,还是需要串行的一条条的处理数据,那有没有办法能加速消费从而降低消费消息的延迟呢?有两种方案分别是:
- 增加消费者的数量
- 在一个消费者中增加消息处理的并行度
因为在Kafka中,一个Topci可以配置多个Partition,数据会被平均或者按照生产者指定的方式写入到多个分区中,那么在消费的时候,Kafka约定一个分区只能被一个消费者消费,为什么要这么设计呢?我理解的是如果有多个Consumer同时消费一个分区的数据,那么在操作这个消费进度的时候就需要加锁,对性能影响比较大。所以说当消费者数量小于分区数量的时候,我们可以增加消费者的数量来增加消息处理能力,但当消费者数量大于分区的时候再继续增加消费者数量就没有意义了。

不能增加Consumer的时候,可以在同一个Consumer中提升处理消息的并行度,即通过多个goroutine来并行的消费数据,我们一起来看看如何通过多个goroutine来消费消息。
在Service中定义msgsChan,msgsChan为Slice,Slice的长度表示有多少个goroutine并行的处理数据,初始化如下:
func NewService(c config.Config) *Service { s := &Service{ c: c, ProductRPC: product.NewProduct(zrpc.MustNewClient(c.ProductRPC)), OrderRPC: order.NewOrder(zrpc.MustNewClient(c.OrderRPC)), msgsChan: make([]chan *KafkaData, chanCount), } for i := 0; i < chanCount; i++ { ch := make(chan *KafkaData, bufferCount) s.msgsChan[i] = ch s.waiter.Add(1) go s.consume(ch) } return s}从Kafka中消费到数据后,把数据投递到Channel中,注意投递消息的时候按照商品的id做Sharding,这能保证在同一个Consumer中对同一个商品的处理是串行的,串行的数据处理不会导致并发带来的数据竞争问题
func (s *Service) Consume(_ string, value string) error { logx.Infof("Consume value: %s\n", value) var data []*KafkaData if err := json.Unmarshal([]byte(value), &data); err != nil { return err } for _, d := range data { s.msgsChan[d.Pid%chanCount] <- d } return nil}我们定义了chanCount个goroutine同时处理数据,每个channel的长度定义为bufferCount,并行处理数据的方法为consume,如下:
func (s *Service) consume(ch chan *KafkaData) { defer s.waiter.Done() for { m, ok := <-ch if !ok { log.Fatal("seckill rmq exit") } fmt.Printf("consume msg: %+v\n", m) p, err := s.ProductRPC.Product(context.Background(), &product.ProductItemRequest{ProductId: m.Pid}) if err != nil { logx.Errorf("s.ProductRPC.Product pid: %d error: %v", m.Pid, err) return } if p.Stock <= 0 { logx.Errorf("stock is zero pid: %d", m.Pid) return } _, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid}) if err != nil { logx.Errorf("CreateOrder uid: %d pid: %d error: %v", m.Uid, m.Pid, err) return } _, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1}) if err != nil { logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", m.Uid, m.Pid, err) } }}怎么保证不会超卖
当秒杀活动开始后,大量用户点击商品详情页上的秒杀按钮,会产生大量的并发请求查询库存,一旦某个请求查询到有库存,紧接着系统就会进行库存的扣减。然后,系统生成实际的订单,并进行后续的处理。如果请求查不到库存,就会返回,用户通常会继续点击秒杀按钮,继续查询库存。简单来说,这个阶段的操作就是三个:检查库存,库存扣减、和订单处理。因为每个秒杀请求都会查询库存,而请求只有查到库存有余量后,后续的库存扣减和订单处理才会被执行,所以,这个阶段中最大的并发压力都在库存检查操作上。
为了支撑大量高并发的库存检查请求,我们需要使用Redis单独保存库存量。那么,库存扣减和订单处理是否都可以交给Mysql来处理呢?其实,订单的处理是可以在数据库中执行的,但库存扣减操作不能交给Mysql直接处理。因为到了实际的订单处理环节,请求的压力已经不大了,数据库完全可以支撑这些订单处理请求。那为什么库存扣减不能直接在数据库中执行呢?这是因为,一旦请求查到有库存,就意味着该请求获得购买资格,紧接着就会进行下单操作,同时库存量会减一,这个时候如果直接操作数据库来扣减库存可能就会导致超卖问题。
直接操作数据库扣减库存为什么会导致超卖呢?由于数据库的处理速度较慢,不能及时更新库存余量,这就会导致大量的查询库存的请求读取到旧的库存值,并进行下单,此时就会出现下单数量大于实际的库存量,导致超卖。所以,就需要直接在Redis中进行库存扣减,具体的操作是,当库存检查完后,一旦库存有余量,我们就立即在Redis中扣减库存,同时,为了避免请求查询到旧的库存值,库存检查和库存扣减这两个操作需要保证原子性。
我们使用Redis的Hash来存储库存,total为总库存,seckill为已秒杀的数量,为了保证查询库存和减库存的原子性,我们使用Lua脚本进行原子操作,让秒杀量小于库存的时候返回1,表示秒杀成功,否则返回0,表示秒杀失败,代码如下:
const ( luaCheckAndUpdateScript = `local counts = redis.call("HMGET", KEYS[1], "total", "seckill")local total = tonumber(counts[1])local seckill = tonumber(counts[2])if seckill + 1 <= total then redis.call("HINCRBY", KEYS[1], "seckill", 1) return 1endreturn 0`)func (l *CheckAndUpdateStockLogic) CheckAndUpdateStock(in *product.CheckAndUpdateStockRequest) (*product.CheckAndUpdateStockResponse, error) { val, err := l.svcCtx.BizRedis.EvalCtx(l.ctx, luaCheckAndUpdateScript, []string{stockKey(in.ProductId)}) if err != nil { return nil, err } if val.(int64) == 0 { return nil, status.Errorf(codes.ResourceExhausted, fmt.Sprintf("insufficient stock: %d", in.ProductId)) } return &product.CheckAndUpdateStockResponse{}, nil}func stockKey(pid int64) string { return fmt.Sprintf("stock:%d", pid)}对应的seckill-rmq代码修改如下:
func (s *Service) consume(ch chan *KafkaData) { defer s.waiter.Done() for { m, ok := <-ch if !ok { log.Fatal("seckill rmq exit") } fmt.Printf("consume msg: %+v\n", m) _, err := s.ProductRPC.CheckAndUpdateStock(context.Background(), &product.CheckAndUpdateStockRequest{ProductId: m.Pid}) if err != nil { logx.Errorf("s.ProductRPC.CheckAndUpdateStock pid: %d error: %v", m.Pid, err) return } _, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: m.Uid, Pid: m.Pid}) if err != nil { logx.Errorf("CreateOrder uid: %d pid: %d error: %v", m.Uid, m.Pid, err) return } _, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: m.Pid, Num: 1}) if err != nil { logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", m.Uid, m.Pid, err) } }}到这里,我们已经了解了如何使用原子性的Lua脚本来实现库存的检查和扣减。其实要想保证库存检查和扣减的原子性,还有另外一种方法,那就是使用分布式锁。
分布式锁的实现方式有很多种,可以基于Redis、Etcd等等,用Redis实现分布式锁的文章比较多,感兴趣的可以自行搜索参考。这里给大家简单介绍下基于Etcd来实现分布式锁。为了简化分布式锁、分布式选举、分布式事务的实现,etcd社区提供了一个名为concurrency的包来帮助我们更简单、正确的使用分布式锁。它的实现非常简单,主要流程如下:
- 首先通过concurrency.NewSession方法创建Session,本质上是创建了一个TTL为10的Lease
- 得到Session对象后,通过concurrency.NewMutex创建一个mutex对象,包括了Lease、key prefix等信息
- 然后听过mutex对象的Lock方法尝试获取锁
- 最后通过mutex对象的Unlock方法释放锁
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})if err != nil { log.Fatal(err)}defer cli.Close()session, err := concurrency.NewSession(cli, concurrency.WithTTL(10))if err != nil { log.Fatal(err)}defer session.Close()mux := concurrency.NewMutex(session, "lock")if err := mux.Lock(context.Background()); err != nil { log.Fatal(err)}if err := mux.Unlock(context.Background()); err != nil { log.Fatal(err)}结束语
本篇文章主要是针对秒杀功能继续做了一些优化。在Kafka消息的生产端做了批量消息聚合发送的优化,Batch思想在实际生产开发中使用非常多,希望大家能够活灵活用,在消息的消费端通过增加并行度来提升吞吐能力,这也是提升性能常用的优化手段。最后介绍了可能导致超卖的原因,以及给出了相对应的解决方案。同时,介绍了基于Etcd的分布式锁,在分布式服务中经常出现数据竞争的问题,一般可以通过分布式锁来解决,但分布式锁的引入势必会导致性能的下降,所以,还需要结合实际情况考虑是否需要引入分布式锁。
希望本篇文章对你有所帮助,谢谢。
每周一、周四更新
代码仓库: https://github.com/zhoushuguang/lebron
项目地址
https://github.com/zeromicro/go-zero
https://gitee.com/kevwan/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
边栏推荐
- remount of the / superblock failed: Permission denied
- A collection of classic papers on convolutional neural networks (deep learning classification)
- PLC模拟量输入 模拟量转换FC S_ITR (CODESYS平台)
- Is it safe to open an account online for stock speculation? Will you be cheated.
- Programmer turns direction
- C language small commodity management system
- 关于FPGA底层资源的细节问题
- Openresty current limiting
- 微博、虎牙挺进兴趣社区:同行不同路
- 如何配和弦
猜你喜欢
![[local differential privacy and random response code implementation] differential privacy code implementation series (13)](/img/fe/f6a13dcf31ac67633ee5a59d95149d.jpg)
[local differential privacy and random response code implementation] differential privacy code implementation series (13)
flutter 报错 No MediaQuery widget ancestor found.
Guitar Pro 8win10最新版吉他学习 / 打谱 / 创作

Deep learning neural network case (handwritten digit recognition)
Quick introduction to automatic control principle + understanding

为什么国产手机用户换下一部手机时,都选择了iPhone?
![Leetcode 1200 minimum absolute difference [sort] the way of leetcode in heroding](/img/4a/6763e3fbdeaf9de673fbe8eaf96858.png)
Leetcode 1200 minimum absolute difference [sort] the way of leetcode in heroding
Opencv learning notes - linear filtering: box filtering, mean filtering, Gaussian filtering

内存管理总结
【C语言】指针笔试题
随机推荐
Five minutes of machine learning every day: why do we need to normalize the characteristics of numerical types?
Combined with case: the usage of the lowest API (processfunction) in Flink framework
LVGL 8.2 Line wrap, recoloring and scrolling
Partial modification - progressive development
LVGL 8.2 Line wrap, recoloring and scrolling
PLC Analog input analog conversion FC s_ ITR (CoDeSys platform)
LVGL 8.2 Sorting a List using up and down buttons
When synchronized encounters this thing, there is a big hole, pay attention!
03 storage system
Memory management summary
[local differential privacy and random response code implementation] differential privacy code implementation series (13)
Ali was laid off employees, looking for a job n day, headhunters came bad news
Yyds dry goods inventory # solve the real problem of famous enterprises: continuous maximum sum
浮点数如何与0进行比较?
Ffprobe common commands
Why do domestic mobile phone users choose iPhone when changing a mobile phone?
Preliminary exploration of flask: WSGI
各大主流编程语言性能PK,结果出乎意料
Redis 发布和订阅
Comment configurer un accord