当前位置:网站首页>Cut off 20% of Imagenet data volume, and the performance of the model will not decline! Meta Stanford et al. Proposed a new method, using knowledge distillation to slim down the data set
Cut off 20% of Imagenet data volume, and the performance of the model will not decline! Meta Stanford et al. Proposed a new method, using knowledge distillation to slim down the data set
2022-07-05 09:59:00 【QbitAl】
bright and quick From the Aofei temple
qubits | official account QbitAI
These two days , The reward offered on twitter was a mess .
a AI The company offers 25 ten thousand dollar ( Renminbi equivalent 167 Ten thousand yuan ), Offer a reward for what task can make the model bigger 、 The worse the performance .
There has been a heated discussion in the comment area .
But it's not just a whole job , But to further explore the big model .
After all , In the past two years, everyone has become more and more aware of ,AI The model cannot simply compare “ Big ”.
One side , As the scale of the model grows , The cost of training began to increase exponentially ;
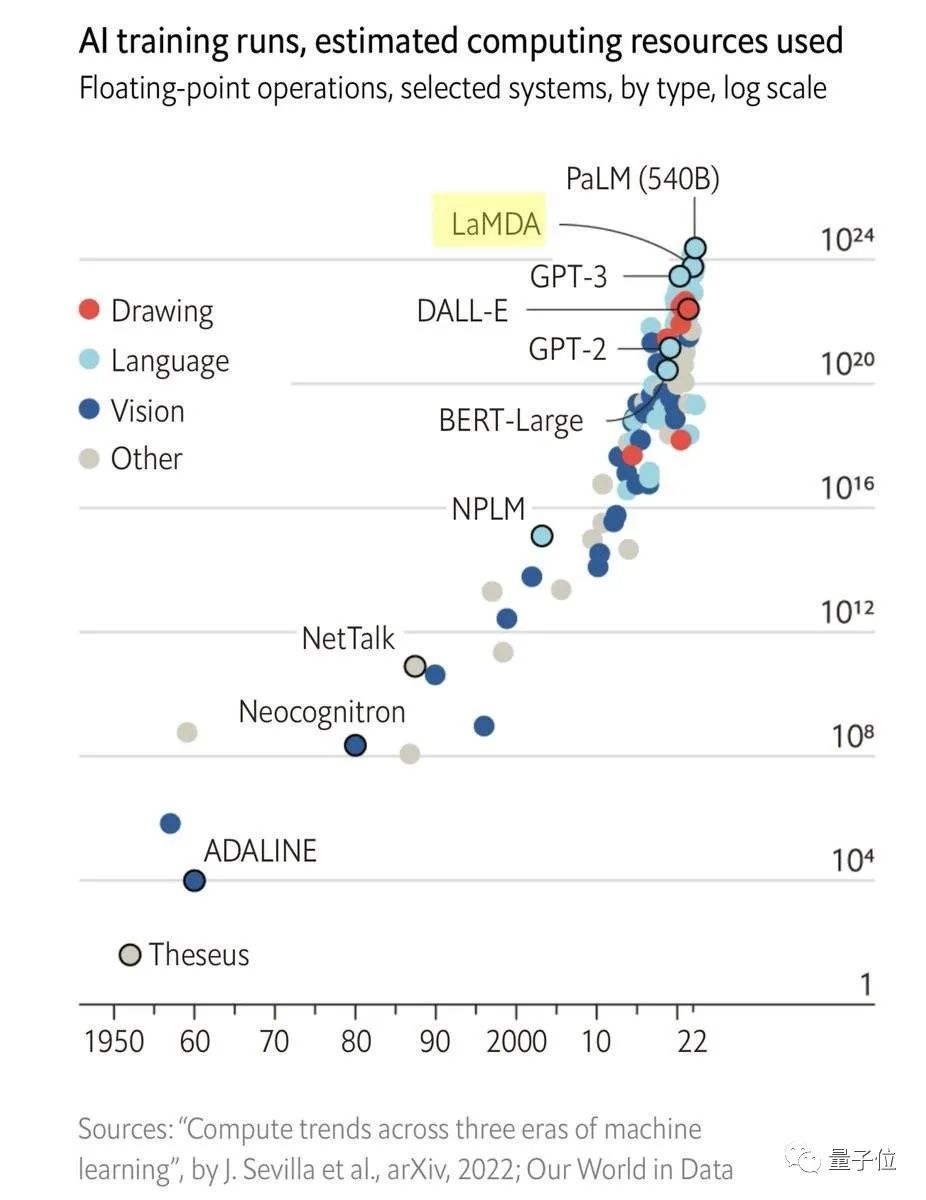
On the other hand , The improvement of model performance has gradually reached the bottleneck , Even if you want to reduce the error again 1%, Need more data set increments and calculation increments .
For example, for Transformer for , Cross entropy loss wants to start from 3.4 Knight lowered to 2.8 Knight , You need the original 10 times Amount of training data .
To address these issues ,AI Scholars have been looking for solutions in various directions .
Meta Stanford scholars , Recently, I thought of starting from Data sets Upper cut .
They put forward , Distill the data set , Make the data set small , But it can also keep the performance of the model from declining .
Experimental verification , Cutting ImageNet 20% After the amount of data ,ResNets There is little difference between the performance and the accuracy when using the original data .
The researchers say , This is also for AGI The realization has found a new way .

The efficiency of large data sets is not high
The method proposed in this paper , In fact, it is to optimize and simplify the original data set .
The researchers say , Many methods in the past have shown , Many training examples are highly redundant , In theory, the data set “ cut ” Smaller .
And recently, some studies have proposed some indicators , You can rank training examples according to their difficulty or importance , And by retaining some of these difficult examples , Data pruning can be completed .
Based on previous discoveries and research , This time, scholars further put forward some concrete methods .
First , They proposed a method of data analysis , The model can learn only part of the data , Can achieve the same performance .
Through data analysis , The researchers came to a preliminary conclusion :
How can a dataset be pruned best ? This is related to its own scale .
The more initial data , The more difficult examples should be kept ;
The less initial data , Then we should keep the examples with low difficulty .
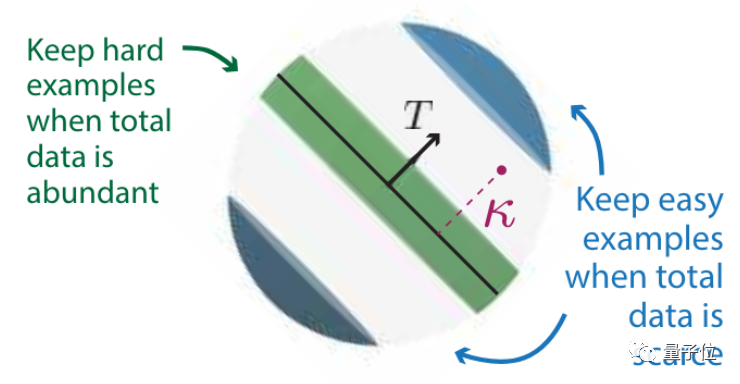
After retaining the difficult examples for data pruning , The corresponding relationship between model and data scale , Can break the power-law distribution .
The often mentioned 28 law is based on the power law .
namely 20% Will affect 80% Result .
And in this case , We can also find an extreme value under Pareto optimality .
Pareto optimality here refers to an ideal state of resource allocation .
It assumes a fixed group of people and allocable resources , Adjust from one allocation state to another , Without making anyone worse , At least make one person better .
In this paper , Adjusting the allocation status can be understood as , How much proportion of data set to trim .
then , Researchers conducted experiments to verify this theory .
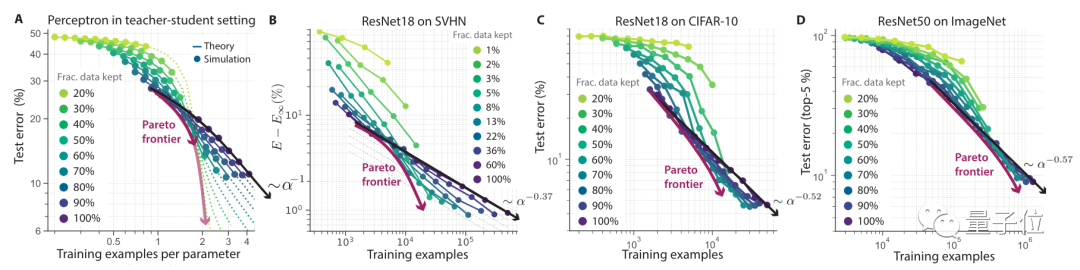
From the experimental results , When the data set is larger , The more obvious the effect after pruning .
stay SVHN、CIFAR-10、ImageNet On several datasets ,ResNet The overall error rate is inversely proportional to the pruning scale of the dataset .
stay ImageNet You can see up here , Data set size Retain 80% Under the circumstances , The error rate under the training of the original data set is basically the same .
This curve also approximates Pareto optimality .
Next , Researchers focused on ImageNet On , Yes 10 Large scale benchmarking has been carried out in different cases .
It turns out that , Random pruning and some pruning indicators , stay ImageNet The performance is not good enough .
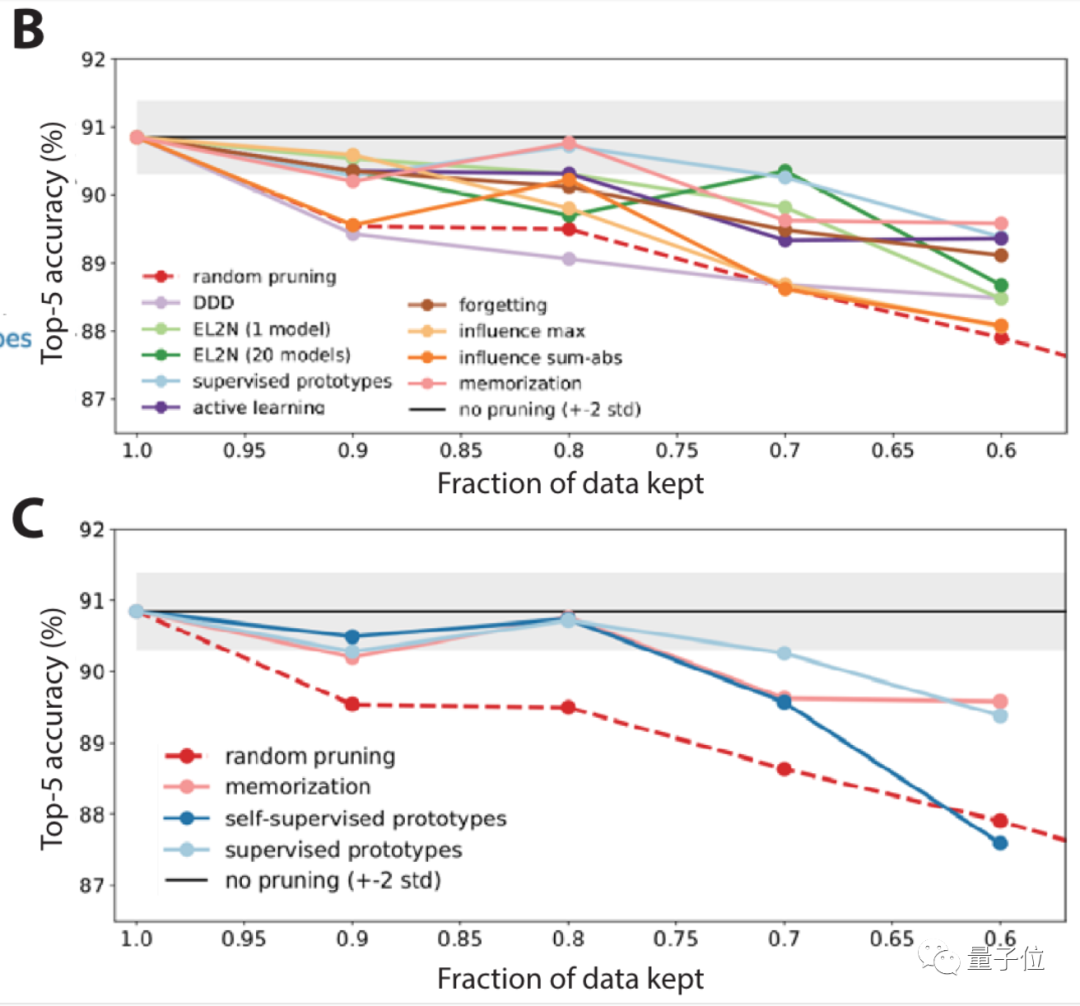
So go further , Researchers also proposed a self-monitoring method to prune data .
That is, knowledge distillation ( Teacher student model ), This is a common method of model compression .
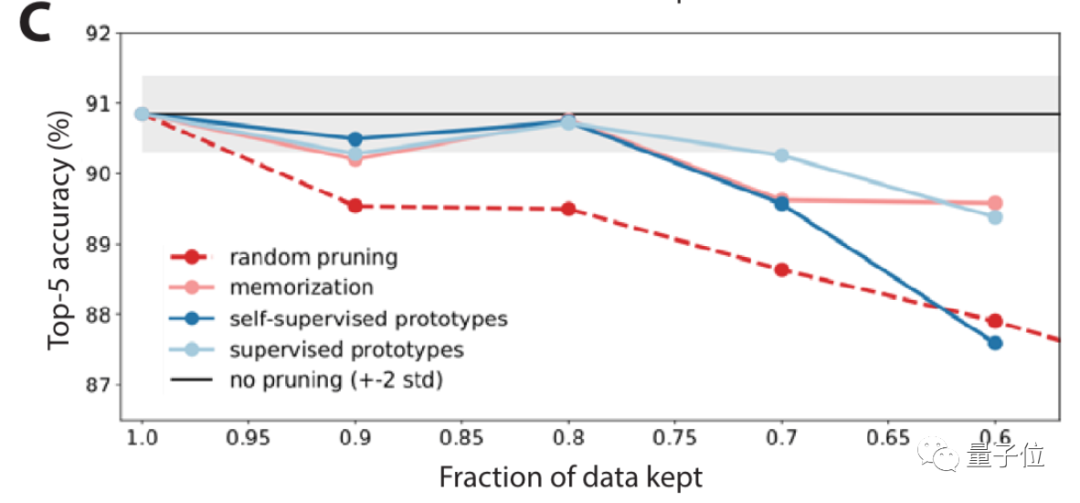
Results show , Under the self-monitoring method , It's looking for data sets that are simple / The performance of difficult examples is good .

After pruning data with self-monitoring method , The accuracy is significantly improved ( chart C Medium light blue line ).
There are still some problems
But in the paper , Researchers also mentioned , Although the data set can be pruned without sacrificing performance through the above method , But some problems still deserve attention .
For example, after the data set is reduced , Want to train a model with the same performance , It may take longer .
therefore , When pruning data sets , We should balance the factors of reducing the scale and increasing the training time .
meanwhile , Prune the dataset , It is bound to lose some samples of groups , This may also cause the model to have drawbacks in a certain aspect .
In this respect, it will easily cause moral and ethical problems .
Research team
One of the authors of this article Surya Ganguli, Is a quantum neural network scientist .

before , During his undergraduate study at Stanford , At the same time, I learned computer science 、 Mathematics and Physics , After that, I got a master's degree in electrical engineering and computer science .
Address of thesis :
https://arxiv.org/abs/2206.14486
边栏推荐
- Officially launched! Tdengine plug-in enters the official website of grafana
- [NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution
- LeetCode 503. Next bigger Element II
- 百度智能小程序巡檢調度方案演進之路
- QT event filter simple case
- Application of data modeling based on wide table
- Analysis on the wallet system architecture of Baidu trading platform
- First understanding of structure
- Solve the problem of no all pattern found during Navicat activation and registration
- 【OpenCV 例程200篇】219. 添加数字水印(盲水印)
猜你喜欢
Node の MongoDB Driver
基于宽表的数据建模应用

On July 2, I invite you to TD Hero online press conference

90%的人都不懂的泛型,泛型的缺陷和应用场景
Kotlin Compose 多个条目滚动
如何正确的评测视频画质

Roll up, break 35 - year - old Anxiety, animation Demonstration CPU recording Function call Process
Officially launched! Tdengine plug-in enters the official website of grafana
Tdengine can read and write through dataX, a data synchronization tool
Develop and implement movie recommendation applet based on wechat cloud
随机推荐
Application of data modeling based on wide table
[object array A and object array B take out different elements of ID and assign them to the new array]
TDengine × Intel edge insight software package accelerates the digital transformation of traditional industries
分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
观测云与 TDengine 达成深度合作,优化企业上云体验
【el-table如何禁用】
Tongweb set gzip
Six simple cases of QT
TDengine ×英特尔边缘洞见软件包 加速传统行业的数字化转型
Charm of code language
[how to disable El table]
H. 265 introduction to coding principles
解决Navicat激活、注册时候出现No All Pattern Found的问题
搞数据库是不是越老越吃香?
SQL learning alter add new field
Go 语言使用 MySQL 的常见故障分析和应对方法
Uncover the practice of Baidu intelligent testing in the field of automatic test execution
Flutter development: a way to solve the problem of blank space on the top of listview
解决idea调试过程中liquibase – Waiting for changelog lock….导致数据库死锁问题
Design and exploration of Baidu comment Center