当前位置:网站首页>Spark DF增加一列
Spark DF增加一列
2022-07-06 00:23:00 【南风知我意丿】
文章目录
方法一:利用createDataFrame方法,新增列的过程包含在构建rdd和schema中
val trdd = input.select(targetColumns).rdd.map(x=>{
if (x.get(0).toString().toDouble > critValueR || x.get(0).toString().toDouble < critValueL)
Row(x.get(0).toString().toDouble,"F")
else Row(x.get(0).toString().toDouble,"T")
})
val schema = input.select(targetColumns).schema.add("flag", StringType, true)
val sample3 = ss.createDataFrame(trdd, schema).distinct().withColumnRenamed(targetColumns, "idx")
方法二:利用withColumn方法,新增列的过程包含在udf函数中
val code :(Int => String) = (arg: Int) => {
if (arg > critValueR || arg < critValueL) "F" else "T"}
val addCol = udf(code)
val sample3 = input.select(targetColumns).withColumn("flag", addCol(input(targetColumns)))
.withColumnRenamed(targetColumns, "idx")
方法三:利用SQL代码,新增列的过程直接写入SQL代码中
input.select(targetColumns).createOrReplaceTempView("tmp")
val sample3 = ss.sqlContext.sql("select distinct "+targetColname+
" as idx,case when "+targetColname+">"+critValueR+" then 'F'"+
" when "+targetColname+"<"+critValueL+" then 'F' else 'T' end as flag from tmp")
方法四:以上三种是增加一个有判断的列,如果想要增加一列唯一序号,可以使用monotonically_increasing_id
//添加序号列新增一列方法4
import org.apache.spark.sql.functions.monotonically_increasing_id
val inputnew = input.withColumn("idx", monotonically_increasing_id)
边栏推荐
- How much do you know about the bank deposit business that software test engineers must know?
- FFT learning notes (I think it is detailed)
- Date类中日期转成指定字符串出现的问题及解决方法
- Codeforces gr19 D (think more about why the first-hand value range is 100, JLS yyds)
- 如何解决ecology9.0执行导入流程流程产生的问题
- Notepad + + regular expression replace String
- FPGA内部硬件结构与代码的关系
- GD32F4xx uIP协议栈移植记录
- XML Configuration File
- 选择致敬持续奋斗背后的精神——对话威尔价值观【第四期】
猜你喜欢
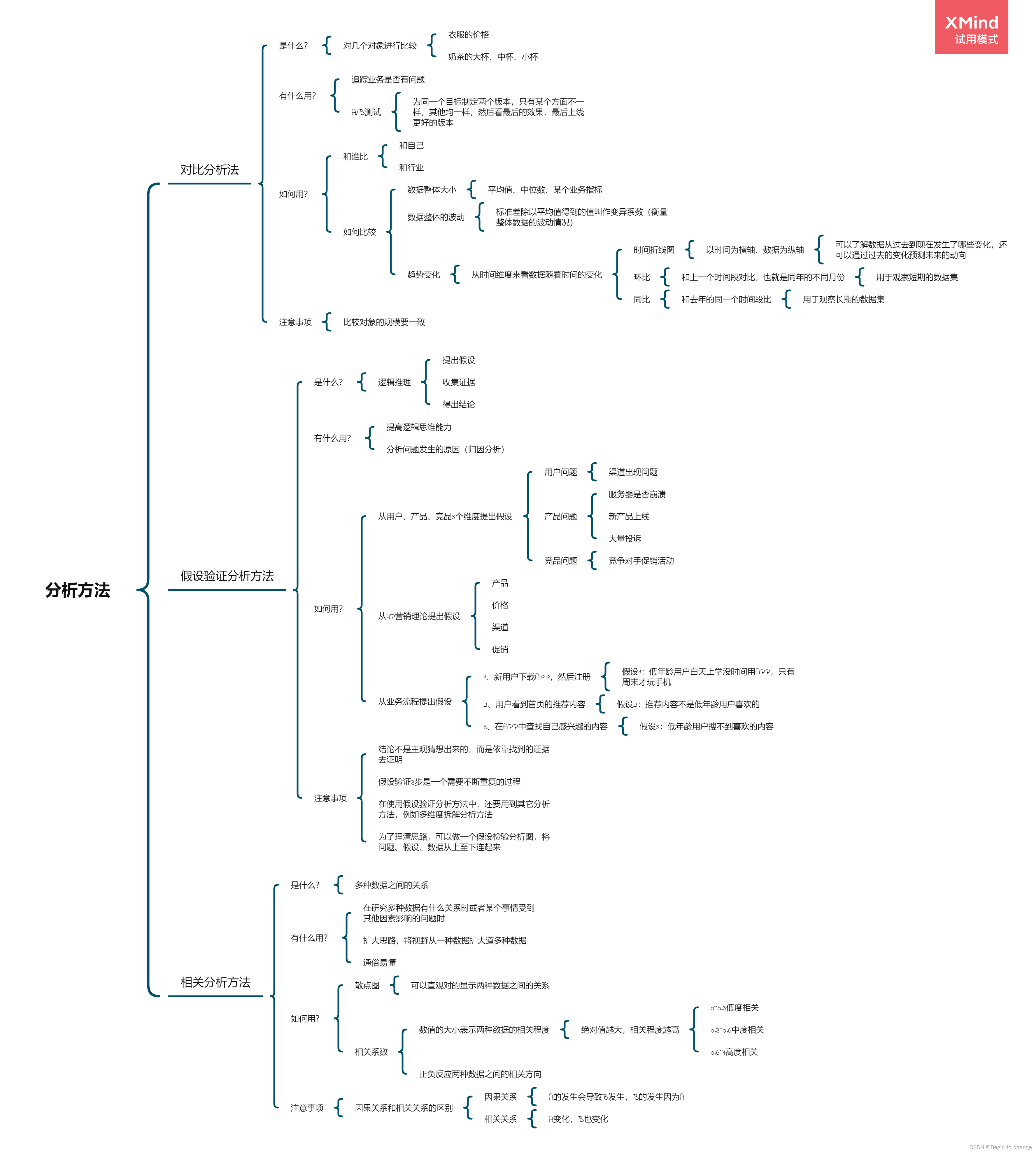
数据分析思维分析方法和业务知识——分析方法(二)
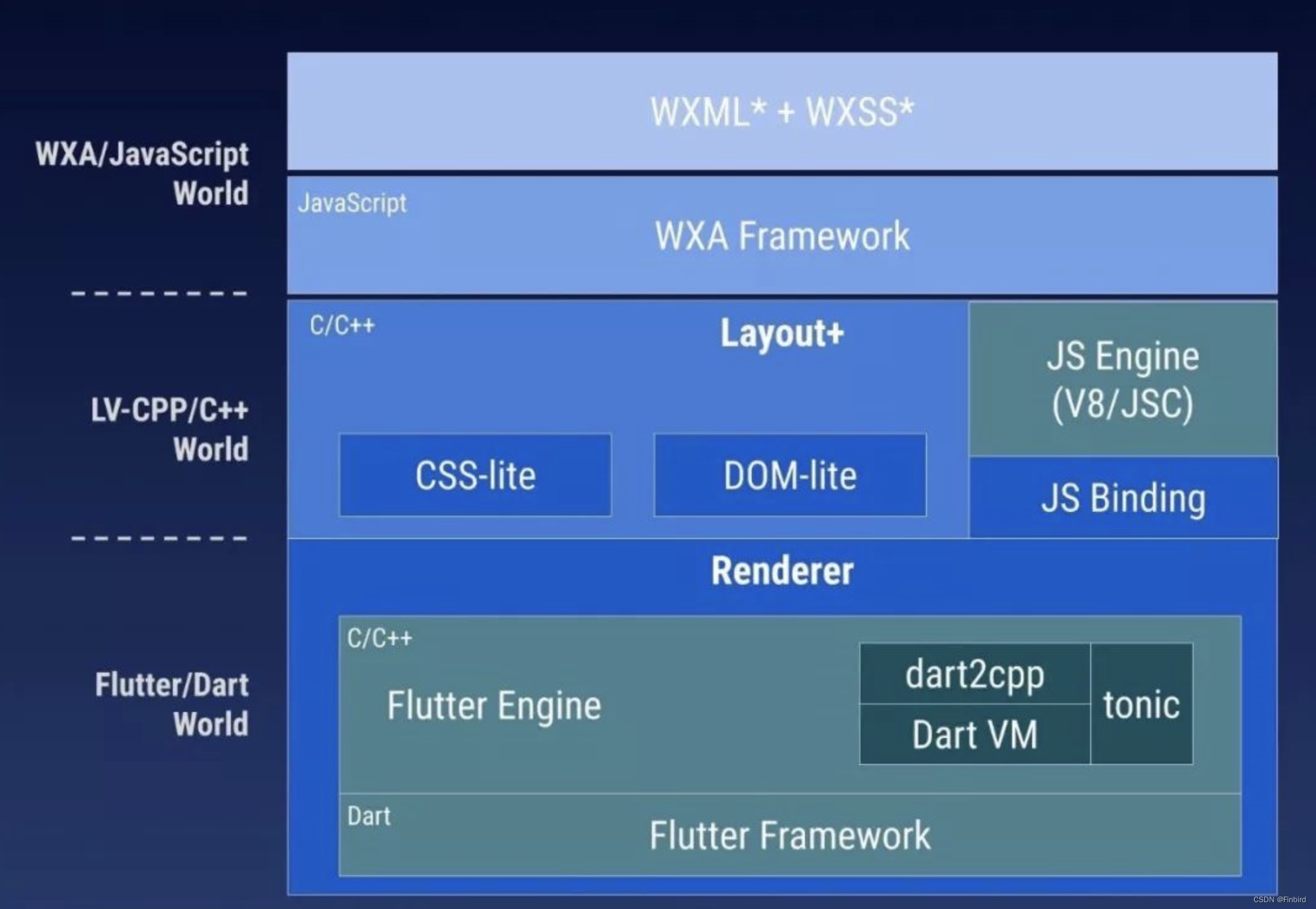
如何利用Flutter框架开发运行小程序
![N1 # if you work on a metauniverse product [metauniverse · interdisciplinary] Season 2 S2](/img/f3/8e237296f5948dd0488441aa625182.jpg)
N1 # if you work on a metauniverse product [metauniverse · interdisciplinary] Season 2 S2
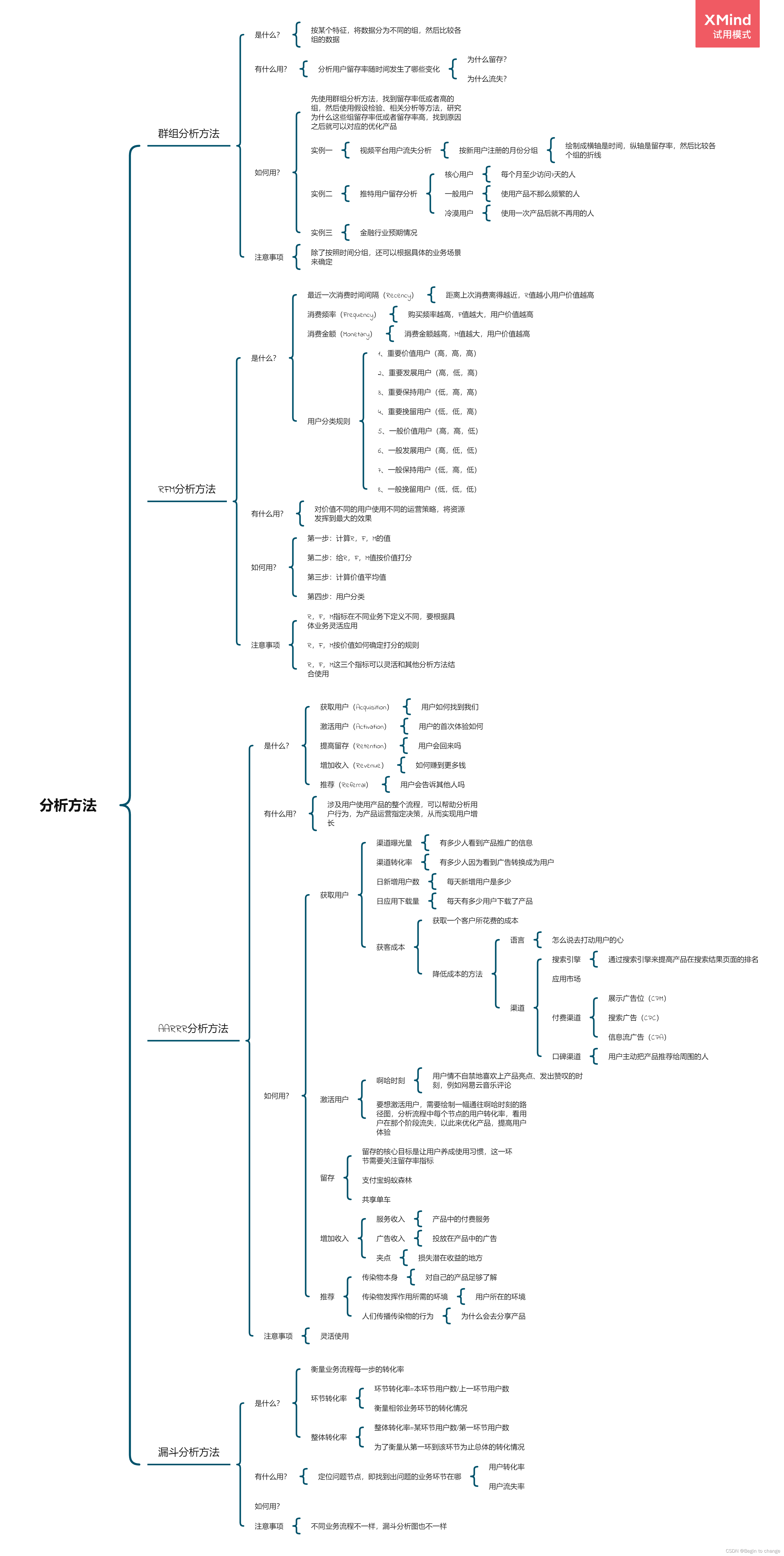
数据分析思维分析方法和业务知识——分析方法(三)

Transport layer protocol ----- UDP protocol
About the slmgr command
Data analysis thinking analysis methods and business knowledge - analysis methods (III)

AtCoder Beginner Contest 254【VP记录】

Browser local storage
FFT learning notes (I think it is detailed)
随机推荐
LeetCode 6005. The minimum operand to make an array an alternating array
2022.7.5-----leetcode. seven hundred and twenty-nine
DEJA_VU3D - Cesium功能集 之 055-国内外各厂商地图服务地址汇总说明
After summarizing more than 800 kubectl aliases, I'm no longer afraid that I can't remember commands!
Mathematical model Lotka Volterra
7.5 simulation summary
Global and Chinese markets of universal milling machines 2022-2028: Research Report on technology, participants, trends, market size and share
Data analysis thinking analysis methods and business knowledge -- analysis methods (II)
剖面测量之提取剖面数据
uniapp开发,打包成H5部署到服务器
How much do you know about the bank deposit business that software test engineers must know?
USB Interface USB protocol
行列式学习笔记(一)
FFMPEG关键结构体——AVCodecContext
Problems and solutions of converting date into specified string in date class
Go learning --- structure to map[string]interface{}
Codeforces round 804 (Div. 2) [competition record]
[designmode] adapter pattern
Power Query数据格式的转换、拆分合并提取、删除重复项、删除错误、转置与反转、透视和逆透视
7.5 装饰器