当前位置:网站首页>爬虫练习题(三)
爬虫练习题(三)
2022-07-06 23:52:00 【InfoQ】
'''
1.分析网页:
https://www.6pian.cn/
https://www.6pian.cn/xq.html
https://www.6pian.cn/xq/1/0.html
https://www.6pian.cn/xq/2/0.html
https://www.6pian.cn/xq/3/0.html
'''
import urllib.request
start = int(input("请输入起始页"))
end = int(input("请输入结束页"))
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'
}
for n in range(start, end + 1):
url = 'https://www.6pian.cn/xq/{}/0.html'.format(n)
print(url)
q = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(q)
with open(f'第{n}页.html','w',encoding='utf-8')as f:
f.write(response.read().decode('utf-8'))
边栏推荐
- 4. Object mapping Mapster
- Where is NPDP product manager certification sacred?
- 京东商品详情页API接口、京东商品销量API接口、京东商品列表API接口、京东APP详情API接口、京东详情API接口,京东SKU信息接口
- Mysql database learning (8) -- MySQL content supplement
- Educational Codeforces Round 22 B. The Golden Age
- Use, configuration and points for attention of network layer protocol (taking QoS as an example) when using OPNET for network simulation
- CVE-2021-3156 漏洞复现笔记
- K6EL-100漏电继电器
- Pinduoduo product details interface, pinduoduo product basic information, pinduoduo product attribute interface
- Phenomenon analysis when Autowired annotation is used for list
猜你喜欢
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
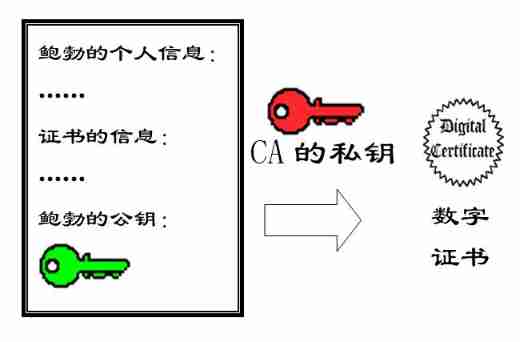
Getting started with DES encryption

导航栏根据路由变换颜色

Common skills and understanding of SQL optimization
sql优化常用技巧及理解

4. Object mapping Mapster

Dj-zbs2 leakage relay
Record a pressure measurement experience summary
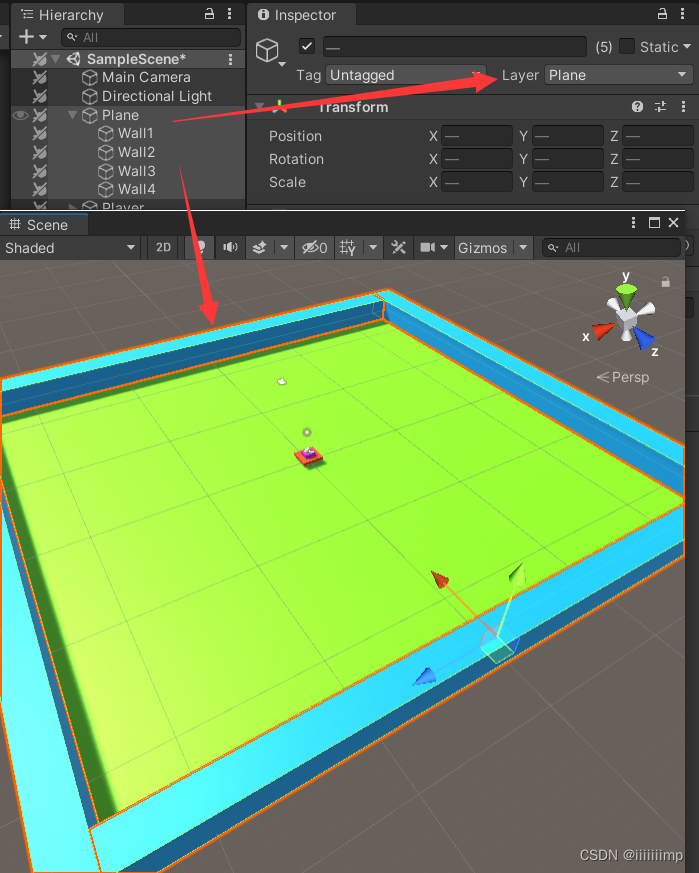
Unity keeps the camera behind and above the player
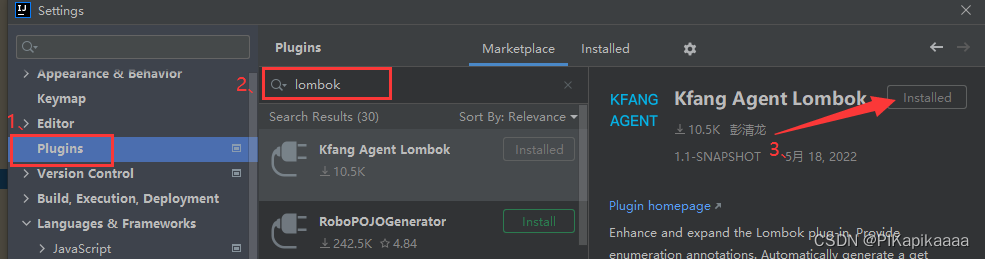
Lombok plug-in
随机推荐
Use, configuration and points for attention of network layer protocol (taking QoS as an example) when using OPNET for network simulation
架构设计的五个核心要素
【js组件】date日期显示。
LabVIEW is opening a new reference, indicating that the memory is full
Cve-2021-3156 vulnerability recurrence notes
论文阅读【MM21 Pre-training for Video Understanding Challenge:Video Captioning with Pretraining Techniqu】
Unity让摄像机一直跟随在玩家后上方
DOM-节点对象+时间节点 综合案例
利用OPNET进行网络指定源组播(SSM)仿真的设计、配置及注意点
app clear data源码追踪
论文阅读【Semantic Tag Augmented XlanV Model for Video Captioning】
Codeforces Round #416 (Div. 2) D. Vladik and Favorite Game
说一说MVCC多版本并发控制器?
5. 数据访问 - EntityFramework集成
In memory, I moved from CSDN to blog park!
How can professional people find background music materials when doing we media video clips?
English语法_名词 - 所有格
EGR-20USCM接地故障继电器
Photo selector collectionview
Reading the paper [sensor enlarged egocentric video captioning with dynamic modal attention]