当前位置:网站首页>淘宝分布式文件系统存储(二)
淘宝分布式文件系统存储(二)
2022-08-04 05:31:00 【小羊的预备程序员】
目录
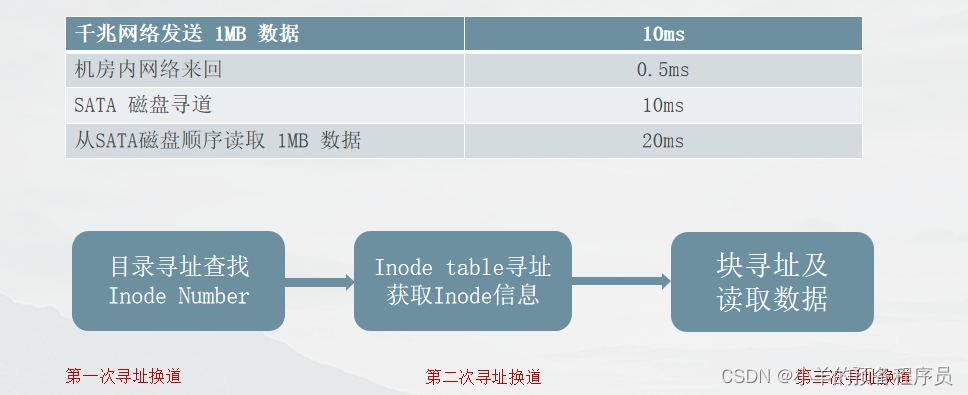
1. 大规模的小文件存取,磁头需要频繁的寻道和换道,因此在读取上容易带来 较长的延时。
2. 频繁的新增删除操作导致磁盘碎片,降低磁盘利用率和IO读写效率
淘宝网为什么不用普通文件存储海量小数据?
1. 大规模的小文件存取,磁头需要频繁的寻道和换道,因此在读取上容易带来 较长的延时。
2. 频繁的新增删除操作导致磁盘碎片,降低磁盘利用率和IO读写效率
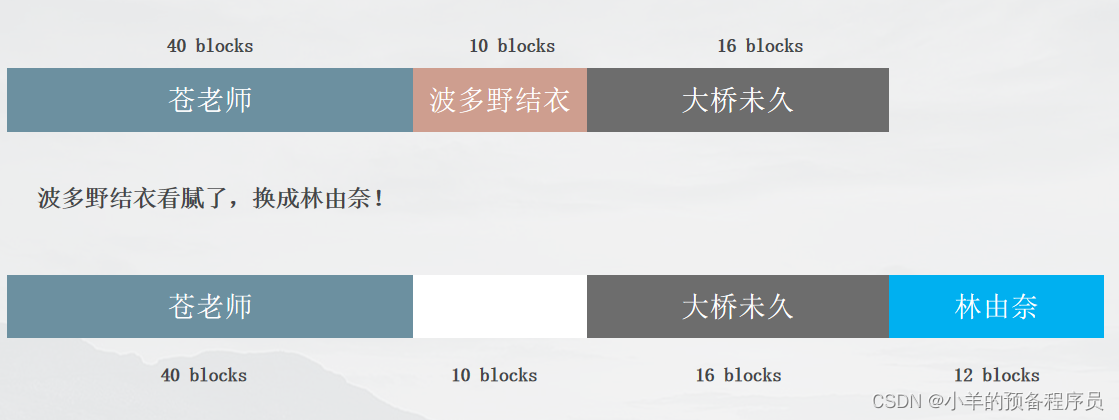
如果我以后想要存8个块的大小的文件,就会造成磁盘碎片

当频繁的新增删除操作就会导致磁盘碎片很多,磁头想要寻址到文件就会造成很多不必要的开销,降低磁盘利用率和IO读写效率
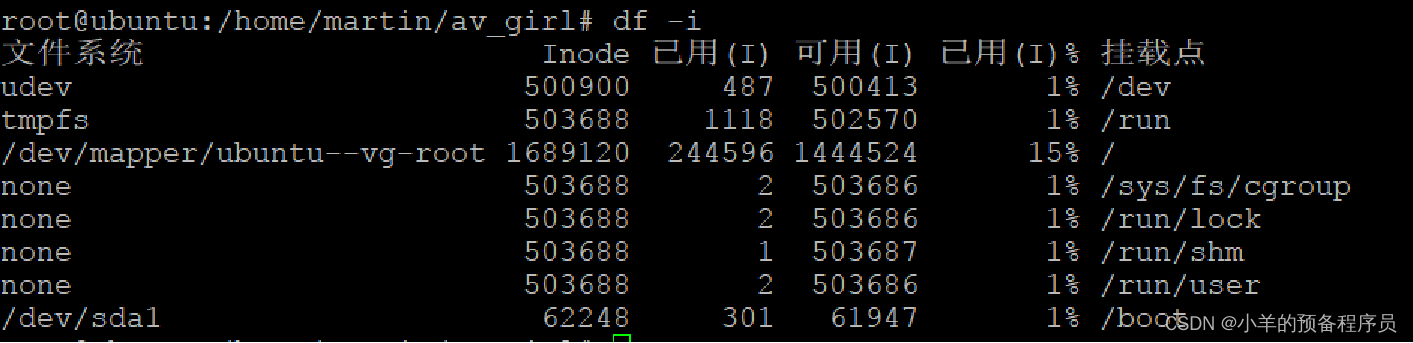
3、Inode占用大量磁盘空间,从而降低了缓存的效果
比如我有1T数据要存储,采用海量小文件存取,Inode信息就会占据至少128G内存,但是实际上是没有这么多内存给你使用的,就导致很多Inode信息我们要去磁盘去读,就会造成swap(内存的数据不断的移动到磁盘上,再次使用的时候又要将磁盘的数据导到内存,这一部分也是占用开销的)
4、设计思路
1、以block文件的形式存放数据文件(一般64M一个block),以下简称为“块”,每个块都有唯一的一个整数编号,块在使用之前所用到的存储空间都会预先分配和初始化。(避免磁盘碎片)
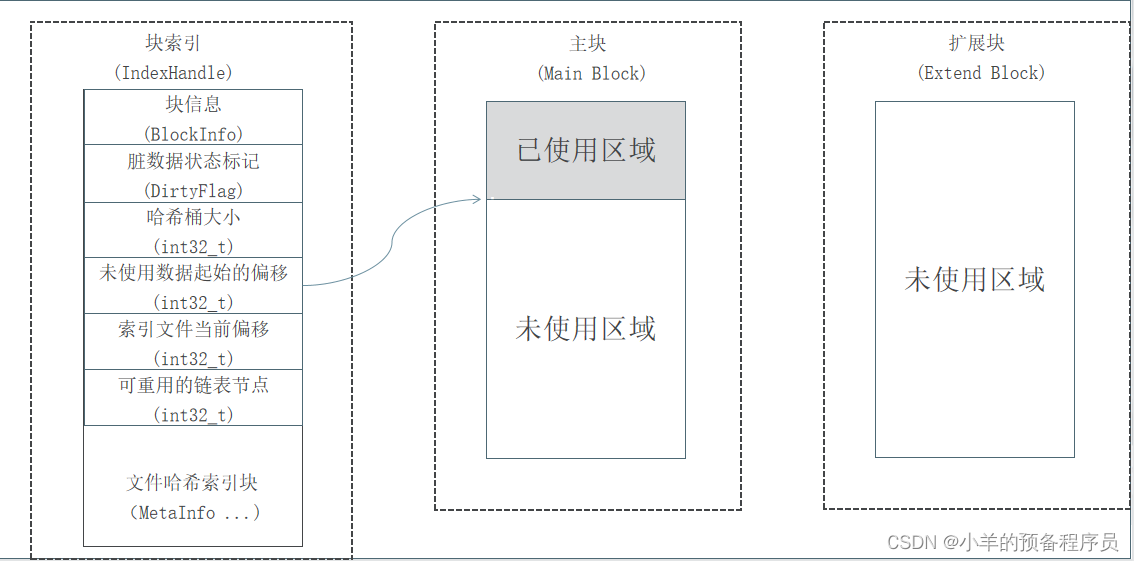
2、每一个块由一个索引文件、一个主块文件和若干个扩展块组成,“小文件”主要存放在主块中,扩展块主要用来存放溢出的数据。
3、每个索引文件存放对应的块信息和“小文件”索引信息,索引文件会在服务启动是映射(mmap)到内存,以便极大的提高文件检索速度。“小文件”索引信息采用在索引文件中的数据结构哈希链表来实现。
4、每个文件有对应的文件编号,文件编号从1开始编号,依次递增,同时作为哈希查找算法的Key 来定位“小文件”在主块和扩展块中的偏移量。文件编号+块编号按某种算法可得到“小文件”对应的文件名。
5、关键数据结构


边栏推荐
- LeetCode_22_Apr_4th_Week
- FAREWARE ADDRESS
- 在AWS-EC2中安装Minikube集群
- LeetCode_Nov_5th_Week
- Machine Learning - Processing of Text Labels for Classification Problems (Feature Engineering)
- FAREWARE ADDRESS
- 指针的运算【C语言】
- Copy Siege Lion 5-minute online experience MindIR format model generation
- Deep Learning Theory - Overfitting, Underfitting, Regularization, Optimizers
- Shell脚本执行的三种方式
猜你喜欢
指针运算相关面试题详解【C语言】

arm-3-中断体系结构

安装Apache服务时出现的几个问题, AH00369,AH00526,AH00072....
第三章 标准单元库(上)
Pytest common plug-in
Completely remove MySQL tutorial
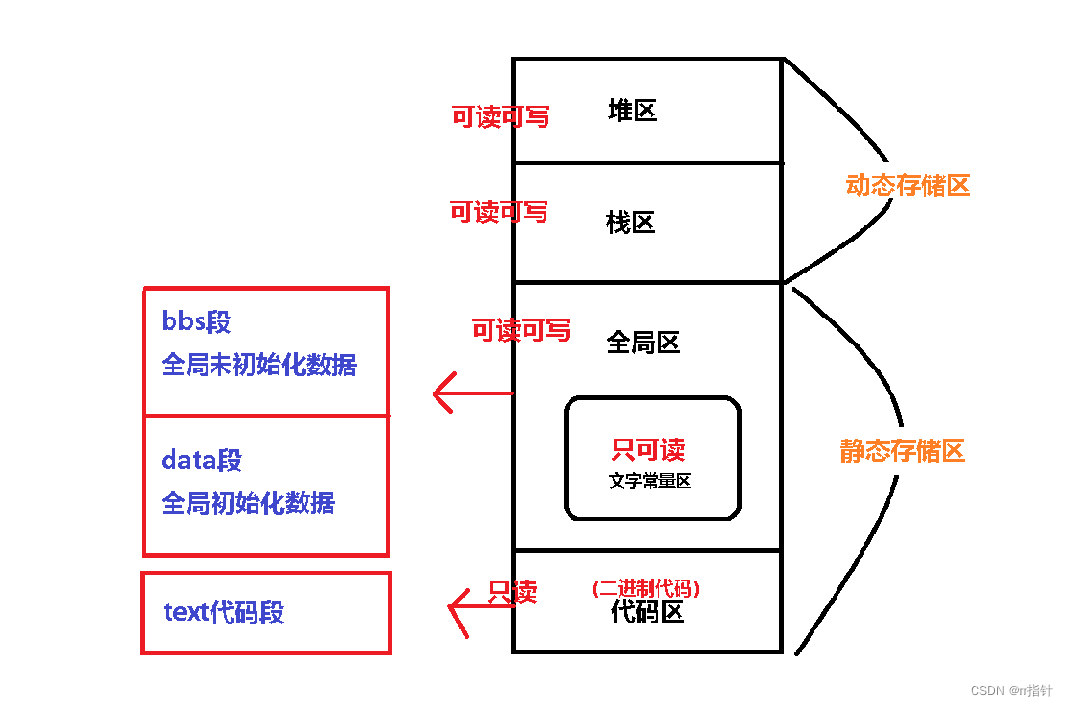
C语言静态变量static的分析
【五一专属】阿里云ECS大测评#五一专属|向所有热爱分享的“技术劳动者”致敬#

LeetCode_Dec_1st_Week

How to get started with MOOSE platform - an example of how to run the official tutorial
随机推荐
Rules.make - suitable for viewing in edit mode
Question 1000: Input two integers a and b, calculate the sum of a+b, this question is multiple sets of test data
bind()系统调用的用处
LeetCode_Nov_5th_Week
arm交叉编译
Code to celebrate the Dragon Boat Festival - Zongzi, your heart
AWS使用EC2降低DeepRacer的训练成本:DeepRacer-for-cloud的实践操作
MNIST手写数字识别 —— 从二分类到十分类
Install Minikube Cluster in AWS-EC2
LeetCode_Nov_5th_Week
MNIST手写数字识别 —— 从零构建感知机实现二分类
[English learning][sentence] good sentence
C语言数组的深度分析
Cut the hit pro subtitles export of essays
线程池原理
第三章 标准单元库(上)
IDEA中创建web项目实现步骤
理想的生活
arm学习-1-开发板
LeetCode_22_Apr_4th_Week