当前位置:网站首页>SLAM 01.人类识别环境&路径的模型建立
SLAM 01.人类识别环境&路径的模型建立
2022-07-05 09:51:00 【平原君2088】
我觉得一些人写的SLAM文章太复杂了,把场景、功能和技术混在一起。我就想很少谈技术,识图顺着人类的感知处理这个角度把问题讲清楚,所以写了此文。
# 场景
在现实中,假设我们第一次进入一个陌生的地下车库这种封闭环境中,这里无手机和wifi信号,电子地图和GPS导航无法使用,我们是如何找到地上超市的入口呢?
人们会首先通过观察周围的环境作出判断,例如地下车库的环境包括墙体、水泥柱子以及其他障碍物(例如栏杆)以及移动和汽车和其他行人。我们根据以往的经验知道那些物体能通过,那些不能通过。
接着我们会按照地面的道路指示标记和箭头行走,这样就可以大概知道到超市的入口了,这点类似现在通过在地面贴磁条进行导航的AGV机器人方式。人类还有一个大招:实在不行就找人打听。
人是一边行走一边观察周围的环境,一边在大脑中构建成三维的室内空间地图。同时我们根据走过步数、距离、方向变化,就知道大概走了多远以及走过的路径,最终到达目的地。
对于第一次来到一个陌生的地下车库,人类是在摸索中前进找到超市入口。但是一旦我们走过了一遍,那么当返回的时候,就能够根据大脑中的记忆恢复原先的地图和路线,找到自己停车的地方。如果下次进入地下车库,再次走就是轻车熟路了。之所以我们再次走能轻车熟路,是因为这个地方的地形地图已经被记录在我们大脑中了。
两种情况例外,例如一种是路盲,对道路和地形和方位感比较差,在构建三维地图的过程中出错太多,难于记住准确地图和行走路线。另外一种情况就是想隔时间久了,新记忆把旧记忆覆盖掉了,导致记忆模糊。
人类大脑经过长期的自然演化能完成这些复杂的功能,人类在工作时候根本意识不到我们大脑是如何工作的。我们一般也不知道这套内部实现机理,但是计算机要模拟人类,必须要知道其原理。
# 建图
首先要构建地图,重构3D地图有多种方式:
1、例如围绕着一个建筑物转一圈, 通过多个角度的连续拍照就可把这个建筑物的三维结构重构起来。
2、人们站在原地使用眼睛转一圈拍照,把周围环境的三维地图重构起来。
3、人们边走边用眼睛拍照,重构周围三维地图。
我们人类在建立环境地图的时候,通过眼睛这个双目摄像机得到外部的图像,然后构架外部环境的三维地图。一般是下车后先停下来向四周扫描一圈,得到一个大概的周围环境的地形地貌三维环境地图,然后边走边把新获得的信息更新到旧的地图中进行重构。人的眼睛是双目,也能测出深度,远处的物体和近处的物体很容易分辨出来,所以构造的是3D地图。当然了计算机视觉在双目的情况下也有一套算法能知道深度。
这里就存在图像融合和3D地图重构的问题。摄入的图像之间存在时序,需要把最新的图像和以前的图像融合连接起来,构成一个完整的三维地图。
一般计算机视觉里是通过图像的特征点匹配方式进行3D重构:找到两张图的特征点(一般是边缘或者角点)进行匹配,然后根据匹配点连线找到旋转角度和平移距离,把两幅图连接起来,这样就能构造出一个完整的3D地图。
# 位姿估计
知道了外部环境能找到了参考系,就可以反过来推算出自己在这个三维地图中的位置。例如边走边拍照周围环境的图片,然后根据不同图片之间的拍摄视觉、深度和平移距离就能反过来推算出自己当前的位姿(位置和姿态),把相机不同位置点连接起来就是运动轨迹,进而得到行走路径。
这在SLAM中就是视觉里程计(Visual Odometry,简称VO)。一般是要先找出每张图中特征点,然后把两张图的特征点进行匹配,再根据匹配点连线找到两幅图之间的旋转矩阵和平移距离,这样就能反推出自己的位姿。
# 避障
当重构出自己周围的三维地图,并且也知道了自己所在的位置,就要找出一条可行的路径。在寻找路径之前,需要知道那些东西是不可穿越的,那些是可以穿越的,这样才可能找到可行路径。
人类会根据以往的经验,知道那些物体是无法穿越的(例如在透明玻璃碰过壁),那些东西是可以穿越的。
在计算机视觉中就要结合深度学习技术进行目标识别,知道那些目标不可穿越,那些可以穿越。当然了如果采用深度相机,例如RGBD相机,就可根据反射回来的红外线知道了障碍物以及其深度距离。
机器人中采用的激光雷达技术就相对容易知道那些是障碍物:通过激光的反射回来的信号就能知道了周围的障碍物,进而知道可行通道。
知道了障碍物,就可根据可行通道的缝隙大小找到路径。
# 路径规划
可能到达目的地的路径有多条,这就需要路径规划。如果我们有室内的电子地图,也有GPS导航功能,那么规划道路就相对容易。但是大多数室内没有GPS信号和地图导航。
对于前面我们提到的情况,第一次站在地下车库找到去地面超市的入口,一般是按照地面的指示标记提供导航。所以受此启发,可以通过在地面贴磁条或者在天花板上贴上标志物来对机器人进行导航。
对于扫地机器人大多数是不需要找到目的地,只要把能进入的空间遍历到位,清扫一遍即可。扫地机器人可能唯一的目的地就是要回到充电底盘的位置。
一般情况,先让机器人在封闭空间里随机走一遍,例如让无人飞机飞一遍,构建出点云的三维地图,然后设置一个目的地,就可以让机器人规划出路径了。有专门的路径规划算法能解决这个问题,找到最优路径。
一旦找到了路径,就可以把一些路标标注并保存起来,这样下次导航的时候就能大大提高效率。
# 回环检测
还有一个问题就是环路检测,要能识别出这个地方就是以前曾经去过的地方,这样就减少很多重复操作了,也为了让定位更准确。
传感器
传感器就是机器人的耳目,我们把能感知自己状态和感知外部环境的都称为传感器:里程计数器、IMU、RGBD相机、激光雷达等。每种传感器适用场合不一样,精度误差不一样,需要把不同传感器信号融合统一起来,还要降噪,这样才能输入系统。
优化和校正
外部数据输入系统后,存在内参、外参以及噪音造成的偏差,并且偏差可能积累,就需要优化校正。根据实际运行的轨迹对软件系统计算出来的轨迹进行矫正,这样才能得到比较准确的结果。优化和矫正也是SLAM中一个重要的话题,一般会放在系统的后端实现。
========================================
以上基本涉及到了SLAM的主要技术点,下面讨论一些其他话题。
# 动态环境应对
前面提到的都是环境没有变化的情况,但是我们人类处在的环境却经常变化:例如可能一张桌子移动了位置,围栏发生了改变,空间进行了重装修,出现了汽车、行人、小动物以及其他移动机器人。那么机器人如何应对这种动态的变化呢?这也是当前SLAM以及自动驾驶面临的挑战。我们还是从人类大脑的处理方式来分析,以便找到解决思路。
遇到这种动态变化的情况,人类首先会和大脑中原先的构造的三维地图进行比较,发现出现了新的物体,然后把这个新物体更新到三维地图中。接着人类会根据先验知识进行目标识别:是否静止,是否在移动,是什么东西,并且根据其运动轨迹预测下一个位置,计算出躲避方案。
计算机技术应该如何实现呢?首先也是要扫描周围环境,和以前构造的地图进行比较,如果发现存在差异化部分则更新到地图中。同时对差异化部分进行目标识别,分辨是否为障碍物,是否是在移动,然后作出行动的预案。
只处理差异部分,计算量就很小,也能方便地分割出物体,然后进行物体的目标识别。物体目标识别可使用深度学习技术完成。
# 自动驾驶技术
SLAM应用在很多移动机器人场合:室内的移动机器人,到野外的自动驾驶汽车、空中的无人机、水下环境的探测机器人等等。SLAM只是自动驾驶技术的一部分,也是最基础最重要的部分。
SLAM主要应用在那些进入未知环境遇到的问题:没有电子地图,没有GPS导航等支撑的环境:例如火星探测器,例如现实中室内以及地下停车场,这里无线信号差,GPS导航信息无法到达,只能靠眼睛观察周围环境。另外对于电子地图+GPS导航因为精度不够的问题,无法适应例如自动泊车这种应用场合,这时SLAM就派上用场了!
对于室外,除了依靠自身传感器基础上重构地图的SLAM技术,也可以依靠电子地图和GPS,同时要使用计算机视觉的目标识别:识别出交通信号灯以及信号(红黄绿)、道路、房子和马路牙子等障碍物,还要进行道路规划和避障。尤其对于动态避障:汽车、行人、小动物,以及移动的其他无人移动机器人等设备,首先就是要精确识别出来,然后才能作出避障的决策,这在当前难度还是很高的,因为形形色色的各种物体,千奇百怪。而这些技术又是SLAM无法解决。
# 总结
我们就记住,SLAM就是根据自身的传感器感知到环境信息来重构环境三维地图,然后画出自己的位置和运行路径,根据地标规划出路径并避障。
至于SLAM里面各种算法和复杂的数学公式,都是为了解决上面提到的任务。我们只有在了解整体框架情况下才可理解这些算法是为了达到什么目的,要解决什么问题,否则会一头雾水。
同时也要清楚,SLAM需要和以深度学习为代表的计算机视觉技术结合才能取得较好的效果。
边栏推荐
- 程序员如何活成自己喜欢的模样?
- 面试:List 如何根据对象的属性去重?
- Single chip microcomputer principle and Interface Technology (esp8266/esp32) machine human draft
- Energy momentum: how to achieve carbon neutralization in the power industry?
- Tianlong Babu TLBB series - single skill group injury
- IDEA新建sprintboot项目
- Swift set pickerview to white on black background
- Hard core, have you ever seen robots play "escape from the secret room"? (code attached)
- 学习笔记4--高精度地图关键技术(下)
- Events and bubbles in the applet of "wechat applet - Basics"
猜你喜欢
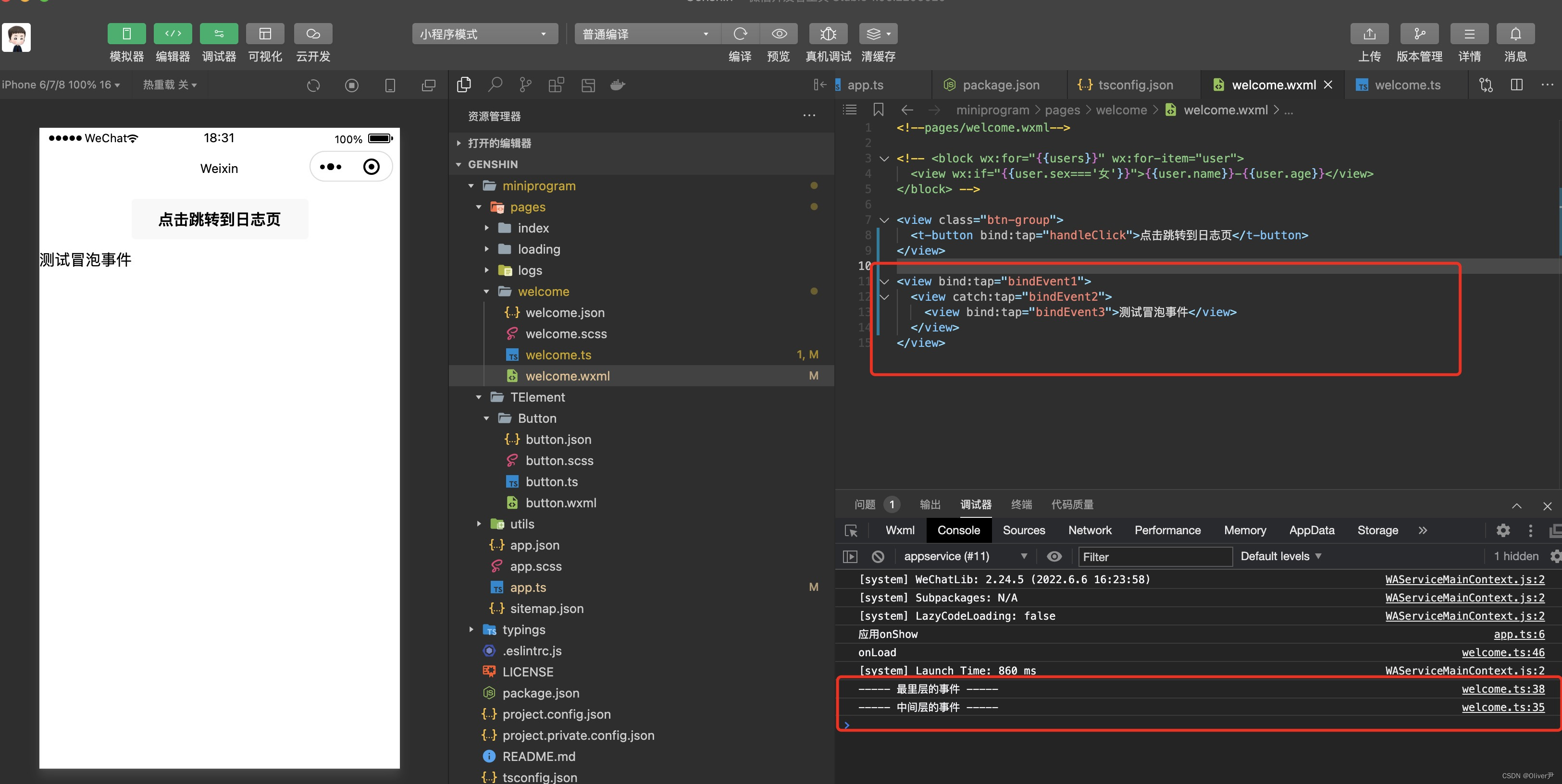
《微信小程序-基础篇》小程序中的事件与冒泡
![[NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution](/img/f3/782246100bca3517d95869be80d9c5.png)
[NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution

伪类元素--before和after
Mysql80 service does not start
QT event filter simple case

A large number of virtual anchors in station B were collectively forced to refund: revenue evaporated, but they still owe station B; Jobs was posthumously awarded the U.S. presidential medal of freedo
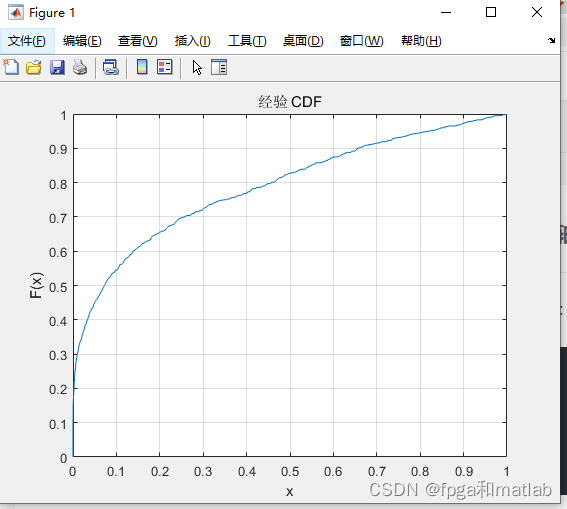
【小技巧】獲取matlab中cdfplot函數的x軸,y軸的數值
Cerebral Cortex:有向脑连接识别帕金森病中广泛存在的功能网络异常
How to get the STW (pause) time of GC (garbage collector)?
善用兵者,藏于无形,90 分钟深度讲解最佳推广价值作品
随机推荐
Advanced opencv:bgr pixel intensity map
MySQL字符类型学习笔记
如何獲取GC(垃圾回收器)的STW(暫停)時間?
> Could not create task ‘:app:MyTest.main()‘. > SourceSet with name ‘main‘ not found.问题修复
学习笔记4--高精度地图关键技术(下)
Swift set pickerview to white on black background
The king of pirated Dall · e? 50000 images per day, crowded hugging face server, and openai ordered to change its name
Using directive in angualr2 to realize that the picture size changes with the window size
WorkManager的学习二
Applet image height adaptation and setting text line height
Meitu lost 300 million yuan in currency speculation for half a year. Huawei was exposed to expand its enrollment in Russia. Alphago's peers have made another breakthrough in chess. Today, more big new
Six simple cases of QT
flink cdc不能监听mysql日志,大家遇到过这个问题吧?
How to get the STW (pause) time of GC (garbage collector)?
Swift saves an array of class objects with userdefaults and nssecurecoding
TypeError: Cannot read properties of undefined (reading ‘cancelToken‘)
The Alipay in place function can't be found, and the Alipay in place function is offline
Today in history: the first e-book came out; The inventor of magnetic stripe card was born; The pioneer of handheld computer was born
天龙八部TLBB系列 - 关于包裹掉落的物品
Matrix processing practice