今天我们来剖析一篇经典的论文:Practial Lessons from Predicting Clicks on Ads at Facebook。从这篇paper的名称当中我们可以看得出来,这篇paper的作者是Facebook的广告团队。这是一篇将GBDT与LR模型结合应用在广告点击率预测的方法,虽然距今已经有好几年了,但是文中的方法仍然没有完全过时,至今依然有一些小公司还在使用。
这篇paper非常非常经典,可以说是推荐、广告领域必读的文章,说是业内的常识也不为过。这篇文章的质量很高,内容也比较基础,非常适合作为大家的入门paper。
本文有点长,建议先马后看。
简介
paper开头的部分简单介绍了一下当时互联网行业当中广告的地位以及当时Facebook的规模,当时Facebook有着7.5亿的日活(日活跃用户daily active users),超过一百万有效的广告商,因此对于Facebook来说选择合适有效的广告投放给用户的重要性是非常巨大的。在此基础上引出了Facebook的创新性做法,即将GBDT与逻辑回归模型进行组合,在真实的数据场景当中获得了超过3%的收益。
在2007年的时候Google和Yahoo就提出了在线竞价的广告收费机制,但是Facebook和搜索引擎的场景不一样,在搜索引擎的场景当中,用户会有明确的搜索意图。引擎会先根据用户的搜索意图去筛选广告,所以候选的广告集不会很大。但是Facebook不存在这样的强意图信息,所以Facebook候选的广告数量要大得多,因此对于系统的压力以及要求也要更高。
但是本文(paper)并不会讨论系统相关的内容,仅仅关注最后一部分排序模型的做法。虽然paper里没说,但是我们看得出来,Google和Yahoo这类搜索引擎当中的广告是搜索广告,而Facebook当中的这些广告是推荐广告。后者和前者最大的区别就是召回广告的逻辑不一样,有点类似于推荐系统和搜索系统的区别。
这其中的核心是用户意图,虽然用户登录Facebook的时候没有强意图,但是根据用户之前的浏览行为以及习惯,我们是可以提取出一些弱意图的。比如用户在哪类商品上停留的时间最长,点击什么样的内容的次数最多,还有类似协同过滤的把用户的行为抽象成向量的做法。其实这里面的内容很多,也非常有价值,可见Facebook在写论文的时候是留了一手的。
具体做法
说完了废话我们来看具体的做法,具体的做法很多同学可能都有所耳闻也就是GBDT+LR的做法。说起来一句话好像就说完了,但是里面的细节很多。比如为什么要用GBDT,为什么GBDT能够起作用?这里面生效的机制是什么?paper里写的内容只是表面,这些细节的思考和分析才是关键。因为paper里的做法并不是普适的,但是其中蕴含的道理往往是通用的。
首先来说说模型评估,paper当中提供了两种新的评估模型的方法。一种是Normalized Entropy,另外一种是Calibration。我们先从模型评估说起。
Normalized Entropy
这个指标在实际场景当中算是蛮常用的,经常在各种大神的代码和paper当中看到。直译过来是归一化熵的意思,意思有点变了,可以理解成归一化之后的交叉熵。它是由样本的交叉熵均值和背景CTR的交叉熵的比值计算得到的。
背景CTR指的是训练样本集样本的经验CTR,可以理解成平均的点击率。但是这里要注意,不是正负样本的比例。因为我们在训练模型之前都会做采样,比如按照正负样本比1:3采样,这里的背景CTR应该定为采样之前的比例。我们假设这个比例是p,那么我们可以写出NE的公式:
这里的取值是
,也就是点击是+1,没有点击是-1。这个是paper里面的公式,在实际应用当中,我们一般吧click写成1,impression(没有click)写成是0。
Calibration
Calibration翻译过来是校准刻度的意思,但是这里我觉得应该理解成和基准线的偏差。这个指标是模型预测的平均CTR和背景CTR的比值,这个比值越接近1,说明我们的模型的基准偏差越小,越接近真实的情况。
这个公式可以写成:
AUC
AUC是老生常谈了,也是我们工业界最常用的指标,几乎没有之一。AUC我们在之前的文章当中介绍过,它表示的Aera-Under-ROC,也就是ROC曲线围成的面积。ROC曲线是TPR(true postive rate)和FPR(false positive rate)组成的曲线。这个曲线面积越接大表明模型区分正负样本的能力越强,在CTR排序场景当中,其实模型能否预测准确并不是最重要的,把正样本筛选出来的能力才是最重要的,这也是AUC如此重要的原因。

但是AUC也不是没有缺点,paper当中列举了一个缺点。比如说假如我们把模型预测的CTR全部x2,然后再给所有的预测结果乘上0.5来校准,这样AUC依然不会有变化。但是如果我们看NE的话,会发现NE上升了。
组合模型
终于到了重头戏了,虽然这篇paper当中讲了很多其他方面的内容,但是我们都知道GBDT+LR才是它的重点。GBDT和LR我们都很熟悉,但是它们两个怎么combine在一起呢?
其实这个问题本身就是错的,所谓GBDT+LR并不是两个模型的结合,而是一种特征的转化。也就是说这个问题我们需要从特征的角度去思考而不是从模型。
paper当中先讲了两种常用的处理特征的方法,第一种是叫做bin,也就是分桶的意思。比如说收入,这是一个连续性特征。如果我们把它放入模型,模型学到的就是它的一个权重,也就说它是线性起作用的。然而在实际的场景当中,可能这完全不是线性的。比如有钱人喜欢的品牌和穷人可能完全不同,我们希望模型能够学到非线性的效果。一种比较好的办法就是人为将这个特征进行分桶,比如根据收入分成年收入3万以下的,3万到10万的,10万到50万的,和50万以上的。落到哪个桶里,哪个桶的值标为1,否则标为0。
第二种方法叫做特征组合,这个也很好理解,比如性别是一个类别,是否是高收入群体是个类别。那我们排列组合一下,就可以得到男_低收入,男_高收入,女_低收入和女_高收入这四个类别。如果是连续性特征,可以使用像是kd-tree这类的数据结构进行离散化。我们把类别特征两两交叉就可以得到更多的特征,但这些特征并不一定都是有用的,有些可能没用,还有些可能有用但是数据很稀疏。所以虽然这样可以产生大量特征,但是需要一一手动筛选,很多是无效的。
由于手动筛选特征的工作量实在是太大,收益也不高,所以工程师就开始思考一个问题:有没有办法可以自动筛选特征呢?现在我们都知道可以让神经网络来做自动的特征交叉和筛选,但是当时神经网络还没有兴起,所以还是只能手动进行。为了解决这个问题,当时的工程师们想到了GBDT。
这才是会有GBDT+LR的原因,我们来看这张图:
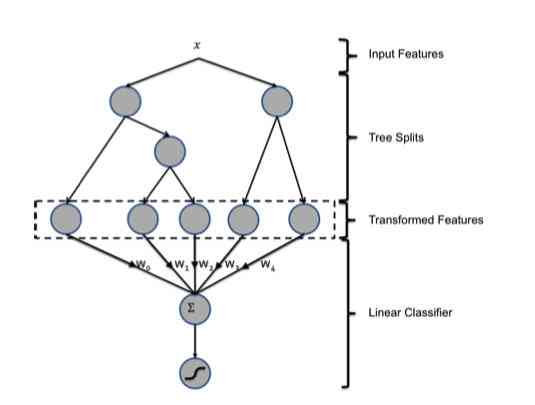
我们来简单回顾一下GBDT的模型,首先GBDT是由多棵树组成的森林模型。对于每一个样本,它在预测的时候都会落到每一棵子树的其中一个叶子节点上。这样我们就可以使用GBDT来进行特征的映射,我们来看个例子:
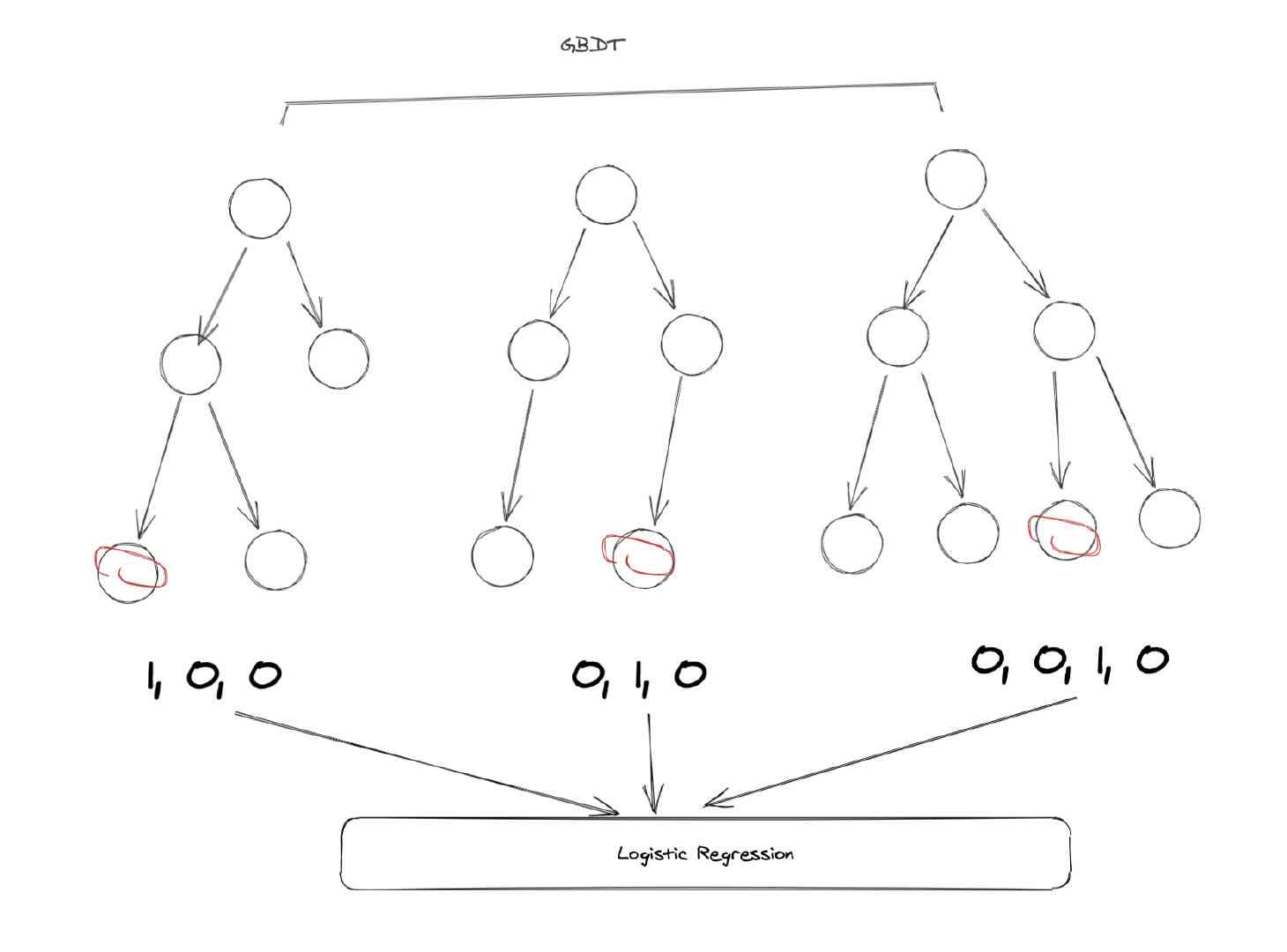
在上图这个例子当中,GBDT一共有3棵子树,第一棵子树有3个叶子节点。我们的样本落到了第一个,所以第一棵子树对应的one-hot结果是[1, 0, 0],第二棵子树也有3个节点,样本落到了第二个节点当中,所以one-hot的结果是[0, 1, 0],同理可以得到第三棵子树的结果是[0, 0, 1, 0]。
这样我们最后把这些树的向量合并在一起,就得到了一个新的向量:[1, 0, 0, 0, 1, 0, 0, 0, 1, 0],这个向量就是我们LR模型的输入。
我们来分析一下细节,首先明确一点,GBDT只是用来进行了特征转化和处理,它的预测结果并不重要。通过使用GBDT我们同时完成了刚才提到的两种操作,既把连续性特征转换成了离散型特征,也自动完成了特征的交叉。因为对于每一棵子树而言,其实本质上是一棵CART算法实现的决策树,也就是说从树根到叶子节点的链路代表了一种潜在的规则。所以我们可以近似看成使用了GBDT代替人工进行了规则的提取以及特征的处理。
结果
最后我们来看下结果,原paper当中进行了分别进行了三组实验,分别是仅有LR、仅有GBDT和GBDT+LR进行对比。衡量的标准是各自的NE,以NE最大的Trees-only作为参考,可以发现GBDT+LR组的NE下降了3.4%。
我们贴上paper当中的结果:
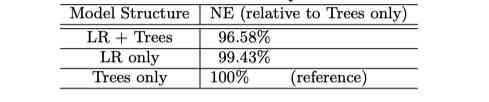
怎么说呢,这个结果挺取巧的,因为对比的是NE,也就是说交叉熵下降了。但是AUC的情况不知道,paper当中没有说。并且这个下降是以NE最大的结果作为参考的,有一点点人为夸大了的感觉。当然这也是paper的常用手段,我们心里有数就好。
数据的实时性
除了模型和特征的创新之外,这篇paper还探讨了数据时效性的作用。
为了验证数据新鲜程度和模型表现之间的关系,paper选择了一条的数据用来训练了trees-only和GBDT+LR这两个模型,然后用这两个模型分别去预测之后1天到6天的数据,将整体的情况绘制成图表:
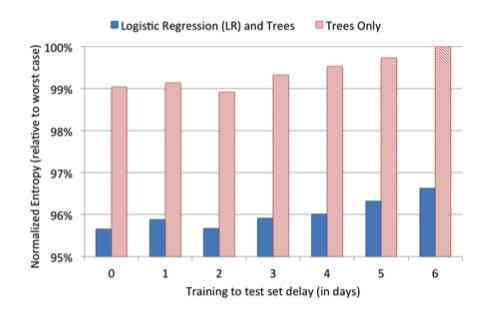
在这张图当中,横轴是预测数据距离训练数据的天数,纵轴是模型的NE。NE越低表示模型的效果越好,从上图我们可以发现第六天的结果和第0天的NE要相差大约1%。这也就意味着单纯是维持数据的新鲜度,我们就可以获得1%的提升。这也是为什么各大公司要做online-learning的原因。
online learning
在接下来的内容当中,paper还为我们介绍了一些online learning的细节性问题。其中有一些已经过时了,或者是普适性不强,我挑选了几个比较典型的有代表性的列举一下。
时间窗口
在我们搜集训练数据的过程当中,点击是比较明确的,因为点击有一个具体的行为,但是impression(曝光)不是。因为用户没点击这并不是一个行为,所以我们没办法确定用户到底是不想点还是等一会再点。比较常规的做法是维护一个定时窗口,规定一个时间,如果用户看到了广告在规定时间内没有点击,那么就认为这是一个非点击事件。
但是我们很容易发现,这么做是有问题的,因为用户可能反应迟钝,或者是暂时还没反应过来导致没有点击。就可能出现时间已经过了,用户点击了的情况。在这种情况下impression已经被记录为一个负样本了,那么点击产生的正样本就找不到对应的impression了。我们可以计算一个比例,有多少点击可以找得到impression,这个比例称为click coverage,点击率的覆盖率。
那是不是窗口时间越长越好呢?其实也不是,因为窗口过长可能会导致把一些不是点击的认为是点击。举个例子,比如说一个商品,用户第一次浏览的时候觉得不满意,所以没有点。过了一会,用户回过来看的时候又改变了主意,发生了点击。那么按照道理,我们应该把第一次没有点的行为视作是负样本,把第二次的行为认为是正样本。如果我们时间窗口设置得很长,就会被认为是一个点击样本。所以时间窗口到底应该设置得多长,这是需要调整的一个参数,不可以拍脑袋决定。
架构
streaming是业内常用的一种数据处理手段,称为流式处理。可以简单理解成队列,也就是queue。但是当发生click的时候我们需要找到对应的impression样本,将它改成正样本,所以我们还需要查找的功能。也就是说我们还需要一个hashmap来记录队列当中的节点。
当我们搜集到了足够数据,或者是搜集了规定时间的样本数据之后,我们会把窗口内的数据用来训练模型。当模型完成训练之后,会被推送到排序系统当中,实时更新排序需要调用的模型文件,从而达到在线实时训练的目的。我们来看下它的架构图:
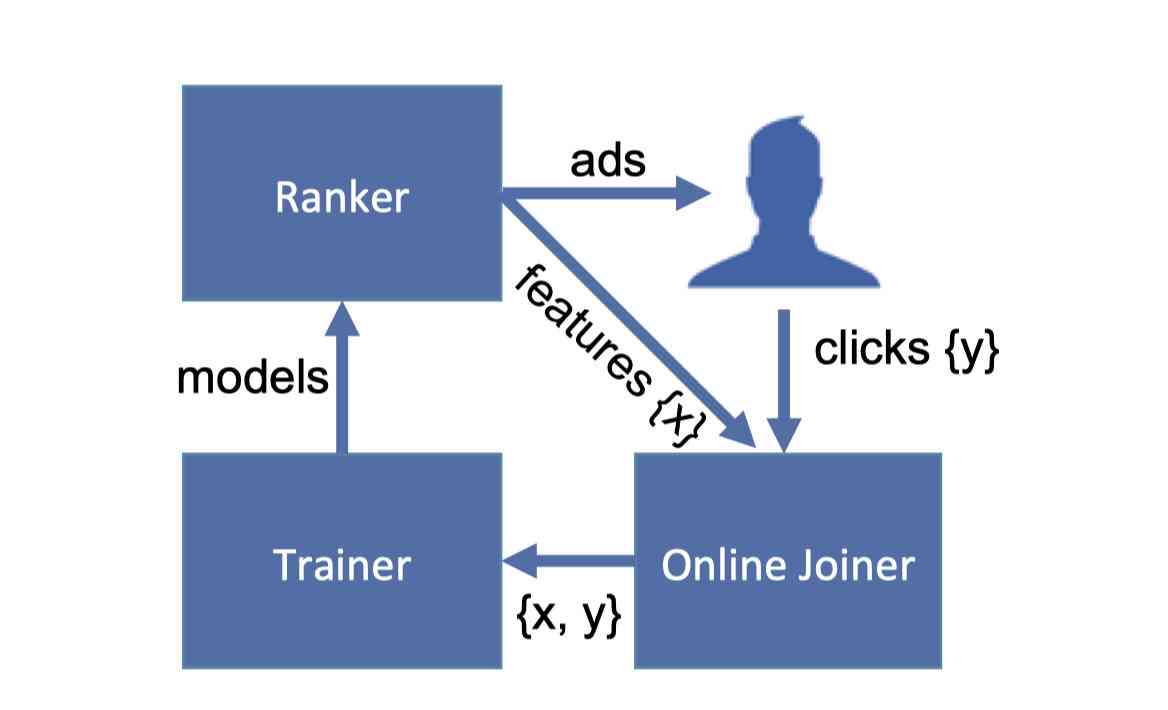
Ranker是排序系统,对候选的广告进行排序之后展示给用户,并且将这些广告的特征数据push给online joiner,也就是特征处理系统。当用户对广告进行点击之后,点击的数据也会被传入Joiner当中。Joiner会将用户的点击数据和Ranker传输来的数据进行关联,关联之后把数据传给Trainer系统进行模型的训练。
这里还涉及到一个细节,就是在joiner当中我们怎么关联呢?因为一个用户可能会有多次观看广告的数据,同一个广告也可能刷新观看多次。所以直接拿用户id或者是广告的id进行关联是不行的,我们还需要一个和时间有关的id。这个id叫做requestid,当用户每次刷新页面的时候,requestid都会刷新,这样我们就可以保证即使用户刷新网页,我们也可以正确地将数据关联上。
特征分析
最后,paper当中还附上了对特征的一些分析。虽然我们不知道它们到底都用了一些什么样的特征,但是这些分析的内容对我们依然有借鉴意义。
行为特征or上下文特征
在CTR预估的场景当中,特征主要可以分为两种,一种是上下文特征,一种是用户历史行为特征。所谓的上下文特征,其实是一个很大的概念。像是展示的广告的信息,用户本身的信息,以及当时的时间、页面内的内容、用户所在的地点等等这些当下的和场景有关的信息都可以被认为是上下文信息。历史行为特征也很好理解,也就是用户之前在平台内产生的行为。
paper当中着重分析了用户行为特征的重要性,其中的做法是将特征按照重要性倒排,然后计算在topK重要的特征当中用户历史行为特征的占比。在LR模型当中,特征的重要性就等价于对应位置的权重,得到的结果如下图:
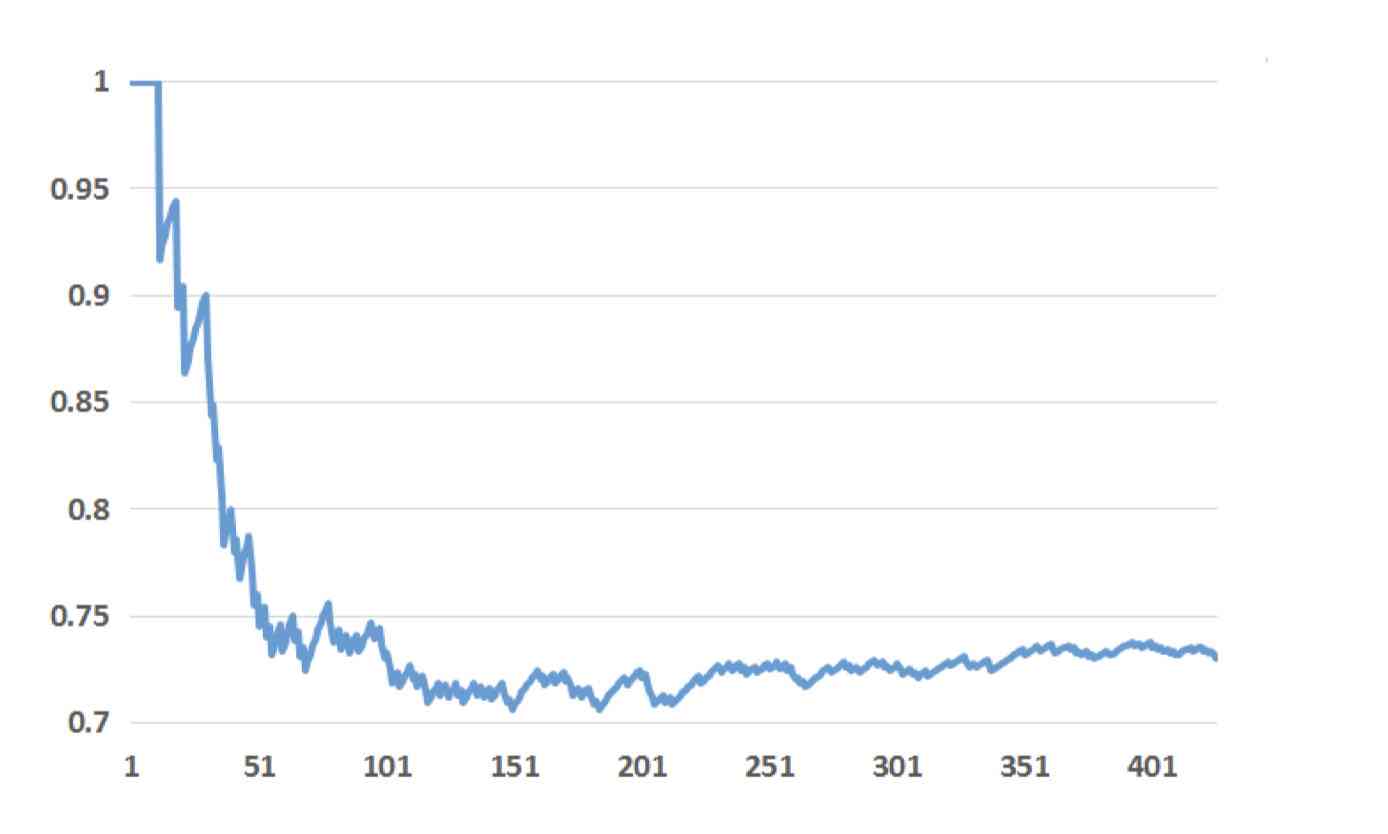
从上图的结果我们可以看到,用户的历史行为特征在整体当中占据到了非常大的权重。top20的feature当中,只有2个是上下文特征。这也很符合我们的认知,我们投放的内容的质量远远不如用户喜欢什么重要。而用户历史上产生过行为的数据非常好地可以体现用户喜好的情况。
重要性分析
除了分析了特征的重要性之外,paper当中还实验了只使用某一种类型的特征进行预测,对比模型的性能。实验的结果如下:
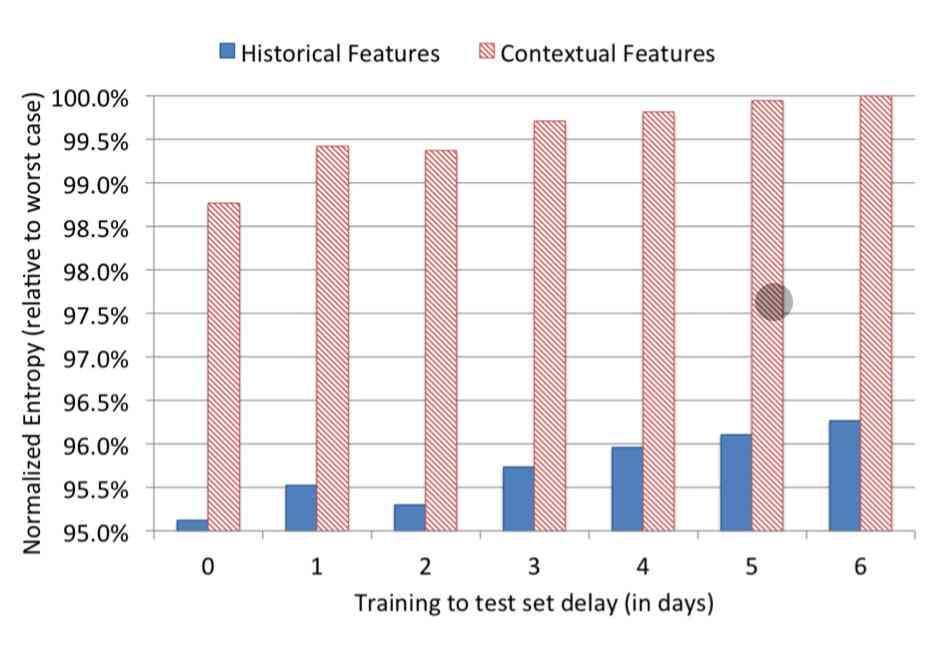
上图当中红柱展示的是只使用上下文特征的训练结果,深蓝色是只使用用户行为特征的训练结果。从这个结果上我们可以明显地看到,只使用行为特征训练出来的模型性能要比使用上下文特征的好至少3.5个点,这已经是非常大的差距了。所以我们也可以得出结论,相比于上下文特征,用户的行为特征更加有用。
除此之外,paper当中还探讨了negative down sampling(负采样)和subsampling(二次采样)对于模型性能的影响。其中二次采样证明训练数据量和模型效果总体呈正比,也就是说训练数据量越大,模型的效果越好。而负采样同样对于提升模型的效果有所帮助,这也是目前广告和推荐场景下的常规手段。
今天的文章就到这里,衷心祝愿大家每天都有所收获。如果还喜欢今天的内容的话,请来一个三连支持吧~(点赞、关注、转发)
本文使用 mdnice 排版