当前位置:网站首页>Flink learning notes (VIII) multi stream conversion
Flink learning notes (VIII) multi stream conversion
2022-07-03 09:34:00 【Did Xiao Hu get stronger today】
List of articles
8. Multi stream conversion
Whether it's basic simple transformation or aggregation , Or window based computing , We all deal with the data on one stream . In practice , You may need to combine data connections from different sources for processing , It may also be necessary to One stream is separated , Therefore, there are often scenes of processing multiple streams .
8.1 shunt
So-called “ shunt ”, Is to split a data stream into two completely independent 、 Even multiple streams .
stay Flink 1.13 In the version , It has been abandoned .split() Method , Instead, use the handler function directly (process function) Side output stream (side output). Marking and extraction of side output stream , all You can't do without one “ Output label ”(OutputTag), It's equivalent to split() When shunting “ stamp ”, Specifies the of the side output stream id And type .
8.2 Confluence
8.2.1 union (Union)
The simplest confluence operation , Is to directly combine multiple streams , Called flow “ union ”(union), The union operation requires that the data types in the stream must be the same , The merged new flow will include all the elements in the flow , The data type remains unchanged .
In the code , We just have to be based on DataStream Call directly .union() Method , Introduction to others DataStream As a reference Count , The union of flows can be realized ; What we get is still a DataStream:
stream1.union(stream2, stream3, ...)
In the event time semantics , The water mark is the progress sign of time ; Different streams may The progress of the water line is completely different , If they merge together , Which water level shall prevail ? Consider the essential meaning of the water mark , yes “ All the previous data have arrived ”; So for the confluence Waterline , The smallest one shall prevail , In this way, we can ensure that all streams will not transmit the previous data . That is, the timeliness of processing when merging multiple streams is based on the slowest stream .
8.2.2 Connect (Connect)
1. Connection flow (ConnectedStreams)
In order to be more flexible , The connection operation allows different data types of streams . But a DataStream Medium Data can only have unique types , So the connection is not DataStream, It is a “ Connection flow ” (ConnectedStreams). The connection flow can be regarded as two flows in the form of “ Unified ”, Put in the same stream ; In fact, the internal data form remains unchanged , They are independent of each other . To get new DataStream, A further definition is needed “ Deal with ”(co-process) Conversion operation , Used to illustrate that for different sources 、 Different types of The data of , How to process and convert separately 、 Get a unified output type . So on the whole , The connection of two streams is like “ "One country, two systems" ”, Two streams can maintain their own data types 、 The treatment can also be different , However, it will eventually be unified to The same DataStream in .

mport org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class ConnectTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<Integer> stream1 = env.fromElements(1,2,3);
DataStream<Long> stream2 = env.fromElements(1L,2L,3L);
ConnectedStreams<Integer, Long> connectedStreams = stream1.connect(stream2);
SingleOutputStreamOperator<String> result = connectedStreams.map(new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer value) {
return "Integer: " + value;
}
@Override
public String map2(Long value) {
return "Long: " + value;
}
});
result.print();
env.execute();
}
}
The connection of two streams (connect), With the United (union) Operation comparison , The biggest advantage is that it can handle different types Merge of flows , More flexible use 、 More widely used . Of course, it also has limitations , That is, the number of merged streams can only be 2, and union Multiple streams can be merged at the same time . It's also very easy to understand :union Restricted type invariance , Therefore, direct merger does not problem ; and connect yes “ "One country, two systems" ”, The interface for subsequent processing only defines two conversion methods , If the extension needs to be repeated Newly defined interface , So we can't “ One country with multiple systems ”.
2. CoProcessFunction
For connection flow ConnectedStreams Processing operation of , You need to define the processing and transformation of the two streams separately , So interface There will be two identical methods to be implemented , Use numbers “1”“2” distinguish , When the data in the two streams arrives, they are adjusted respectively use . We call this interface “ Collaborative processing function ”(co-process function). And CoMapFunction similar , Such as The result is to call .flatMap() You need to pass in a CoFlatMapFunction, Need to achieve flatMap1()、flatMap2() Two Method ; And call .process() when , What comes in is a CoProcessFunction.
abstract class CoProcessFunction In the source code, it is defined as follows :
public abstract class CoProcessFunction<IN1, IN2, OUT> extends AbstractRichFunction {
...
public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;
public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception {
}
public abstract class Context {
...}
...
}
CoProcessFunction It's also “ Processing function ” A member of the family , The usage is very similar like . What it needs to achieve is processElement1()、processElement2() Two methods , When every data comes , One of the methods will be called according to the source stream for processing .CoProcessFunction You can also use context ctx Come on visit timestamp、 Waterline , And pass TimerService Register timer ; It also provides .onTimer() Method , use It is used to define the processing operations triggered by timing .
3. Broadcast connection flow (BroadcastConnectedStream)
This connection method is often used in scenarios where some rules or configurations need to be dynamically defined . Because the rules change in real time , the So we can use a separate stream to get rule data ; These rules or configurations are globally valid for the entire application , the So you can't just pass this data to a downstream parallel subtask for processing , But to “ radio broadcast ”(broadcast) Give all and Line subtask . And the downstream task receives the broadcast rules , Will save it in a state , That's what's called “ radio broadcast state ”(broadcast state).
The bottom layer of broadcast state is a “ mapping ”(map) Structure to preserve . In code implementation , Can be called directly DataStream Of .broadcast() Method , Pass in a “ Mapping state descriptor ”(MapStateDescriptor) Description status The name and type of , You can get the rule data “ Broadcast stream ”(BroadcastStream):
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
Next, you can process the data flow , Connect to this broadcast stream (connect), What you get is It means “ Broadcast connection flow ”(BroadcastConnectedStream). be based on BroadcastConnectedStream call .process() Method , You can get rules and data at the same time , Dynamic processing .
DataStream<String> output = stream
.connect(ruleBroadcastStream)
.process( new BroadcastProcessFunction<>() {
...} );
BroadcastProcessFunction And CoProcessFunction similar , It is also an abstract class , Need to implement two The method is called .processElement() and .processBroadcastElement(). The source code is defined as follows :
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends
BaseBroadcastProcessFunction {
...
public abstract void processElement(IN1 value, ReadOnlyContext ctx,
Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx,
Collector<OUT> out) throws Exception;
...
}
8.3 Time based confluence
For the merging of two streams , In many cases, we don't simply put all the data together , But hope according to some The values of the fields join them ,“ pairing ” To do the processing . This requirement is related to the of tables in relational databases join The operation is very similar .
8.3.1 Window connection (Window Join)
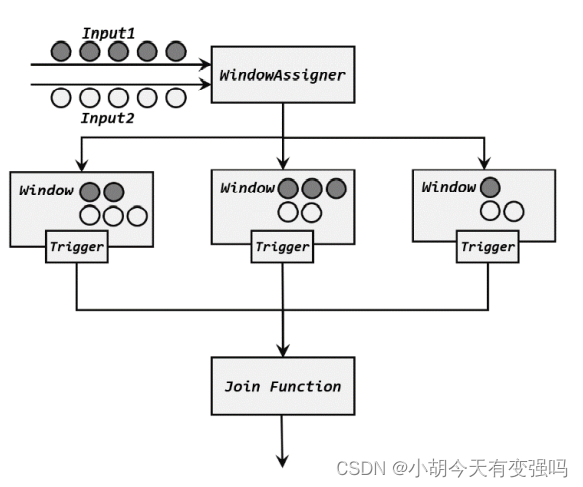
Window connection (window join) operator , You can define the time window , and Share a common key between the two streams (key) Put the data in the window for pairing processing .
- Call of window connection
Implementation of window connection in code , First you need to call DataStream Of .join() Method to merge two streams , Get one individual JoinedStreams; Then passed .where() and .equalTo() Method to specify the join in two streams key; Then pass too .window() Open the window , And call .apply() Pass in the join window function for processing and calculation .
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
Incoming JoinFunction It is also a function class interface , When using, you need to implement internal .join() Method . This method There are two parameters , Respectively represent the paired matching data in the two streams .JoinFunction The definition in the source code is as follows :
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {
OUT join(IN1 first, IN2 second) throws Exception;
}
- Processing flow of window connection
8.3.2 Interval connection (Interval Join)
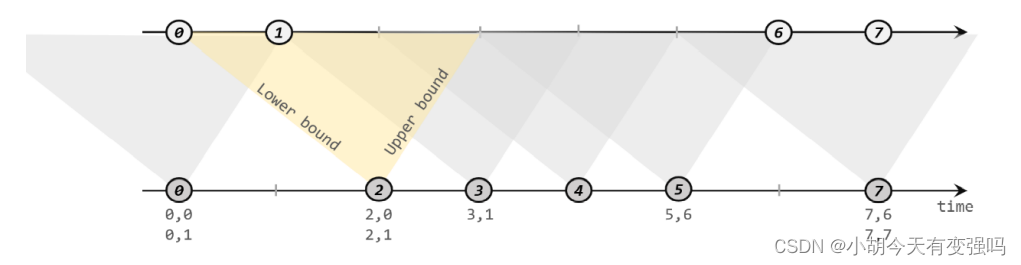
- The principle of interval connection
The idea of interval connection is for each data of a stream , Open up a time interval before and after its timestamp , See if there is data matching from another stream during this period .
The matching condition is : a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound , We need to pay attention to , Two streams connected at intervals A and B, Must also be based on the same key; Lower bound lowerBound Should be less than or equal to the upper bound upperBound, Both can be positive or negative ; Interval join currently only supports event time semantics .
- Call of interval connection
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(left + "," + right);
}
});
8.3.3 The window is connected with the group (Window CoGroup)
Window CoGroup Usage and follow up window join Very similar , After merging the two streams, the matching elements are processed by windowing , Invocation time Only need to .join() Replace with .coGroup().
stream1.coGroup(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction>)
summary
Multi stream conversion is a common requirement of stream processing in practical applications , It mainly includes diversion and confluence . The most basic way to merge is to combine (union) And connections (connect), The main difference between the two is union It can be done to Merge multiple streams , Data types must be consistent ; and connect Only two streams can be connected , Data types can be different .Flink Several built-in connections are also provided (join) operation , They are both based on a certain period of time Merge , It is the high-level after demand specialization API. It mainly includes window connection (window join)、 Interval connection (interval join) Join with window group (window coGroup). among window join and coGroup It's all based on the time window .
边栏推荐
- Installation and uninstallation of pyenv
- LeetCode每日一题(2109. Adding Spaces to a String)
- Hudi 快速体验使用(含操作详细步骤及截图)
- Using Hudi in idea
- Spark 集群安装与部署
- Overview of database system
- Jestson nano downloads updated kernel and DTB from TFTP server
- Spark structured stream writing Hudi practice
- [kotlin learning] control flow of higher-order functions -- lambda return statements and anonymous functions
- [CSDN]C1训练题解析_第三部分_JS基础
猜你喜欢
Flink学习笔记(九)状态编程

Crawler career from scratch (II): crawl the photos of my little sister ② (the website has been disabled)

全球KYC服务商ADVANCE.AI 活体检测产品通过ISO国际安全认证 产品能力再上一新台阶

LeetCode每日一题(1162. As Far from Land as Possible)

Hudi learning notes (III) analysis of core concepts

【Kotlin疑惑】在Kotlin类中重载一个算术运算符,并把该运算符声明为扩展函数会发生什么?

PolyWorks script development learning notes (I) - script development environment
Spark cluster installation and deployment
![[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)](/img/fd/c0f885cdd17f1d13fdbc71b2aea641.jpg)
[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)
There is no open in default browser option in the right click of the vscade editor
随机推荐
CATIA automation object architecture - detailed explanation of application objects (I) document/settingcontrollers
Modify idea code
Construction of simple database learning environment
The rise and fall of mobile phones in my perspective these 10 years
[set theory] order relation (eight special elements in partial order relation | ① maximum element | ② minimum element | ③ maximum element | ④ minimum element | ⑤ upper bound | ⑥ lower bound | ⑦ minimu
[solution to the new version of Flink without bat startup file]
一款开源的Markdown转富文本编辑器的实现原理剖析
LeetCode每日一题(1024. Video Stitching)
Global KYC service provider advance AI in vivo detection products have passed ISO international safety certification, and the product capability has reached a new level
1922. Count Good Numbers
[kotlin learning] operator overloading and other conventions -- overloading the conventions of arithmetic operators, comparison operators, sets and intervals
Send mail using WP mail SMTP plug-in
Jestson Nano自定义根文件系统创建(支持NVIDIA图形库的最小根文件系统)
ERROR: certificate common name “www.mysql.com” doesn’t match requested host name “137.254.60.11”.
文件系统中的目录与切换操作
Find all possible recipes from given supplies
基于opencv实现桌面图标识别
解决Editor.md上传图片获取不到图片地址问题
WARNING: You are using pip ; however. Later, upgrade PIP failed, modulenotfounderror: no module named 'pip‘
【Kotlin学习】类、对象和接口——定义类继承结构