当前位置:网站首页>Using Hudi in idea
Using Hudi in idea
2022-07-03 09:21:00 【Did Xiao Hu get stronger today】
Environmental preparation
- establish Maven project
- Create a server remote connection
Tools------Delployment-----Browse Remote Host
Set the following :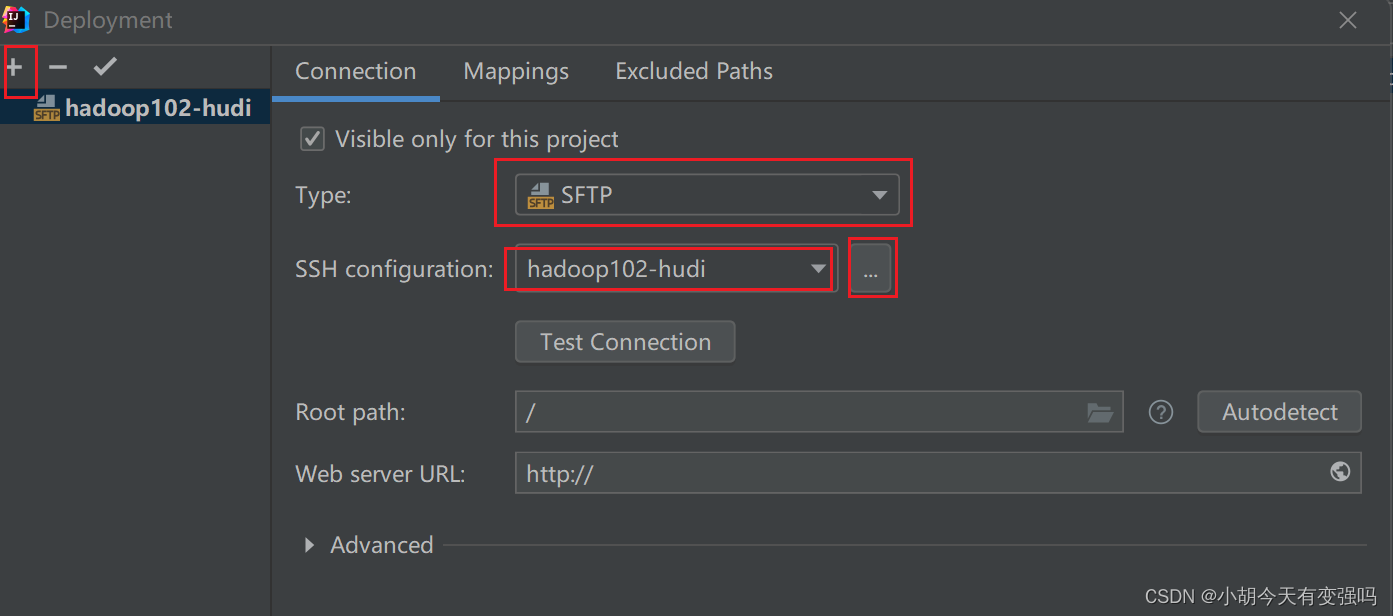
Enter the account and password of the server here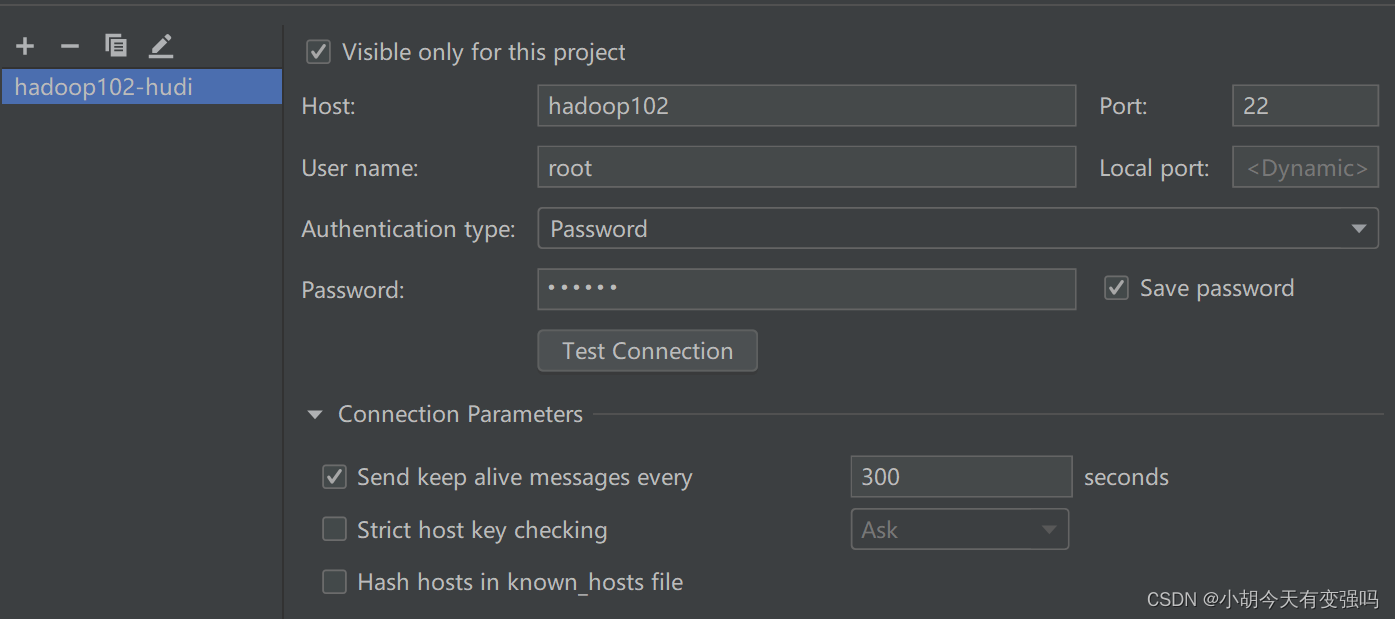
Click on Test Connection, Tips Successfully Words , The configuration is successful .
- Copy Hadoop Of core-site.xml、hdfs-site.xml as well as log4j.properties Three files copied to resources Under the folder .
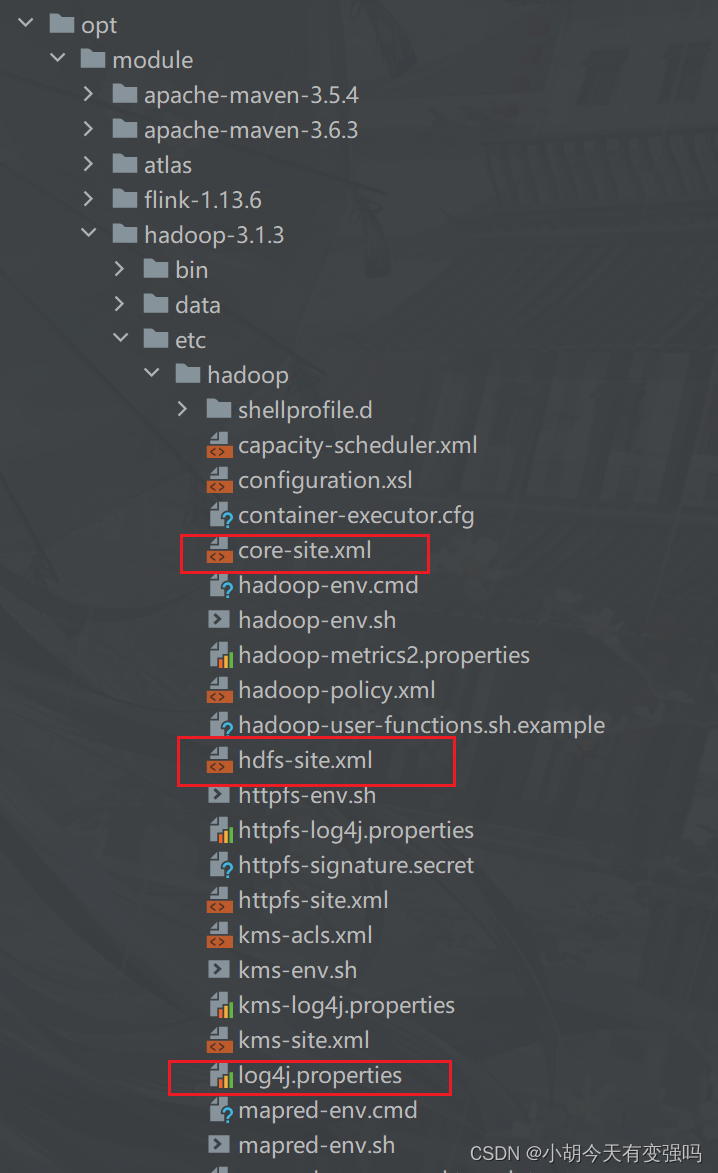
Set up log4j.properties For printing warning exception information :
log4j.rootCategory=WARN, console
- add to pom.xml file
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.0.0</spark.version>
<hadoop.version>2.7.3</hadoop.version>
<hudi.version>0.9.0</hudi.version>
</properties>
<dependencies>
<!-- rely on Scala Language -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client rely on -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hudi-spark3 -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3-bundle_2.12</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
To comment out the following code generated when creating the project , Otherwise, the dependency keeps reporting errors :
<!-- <properties>-->
<!-- <maven.compiler.source>8</maven.compiler.source>-->
<!-- <maven.compiler.target>8</maven.compiler.target>-->
<!-- </properties>-->
The code structure :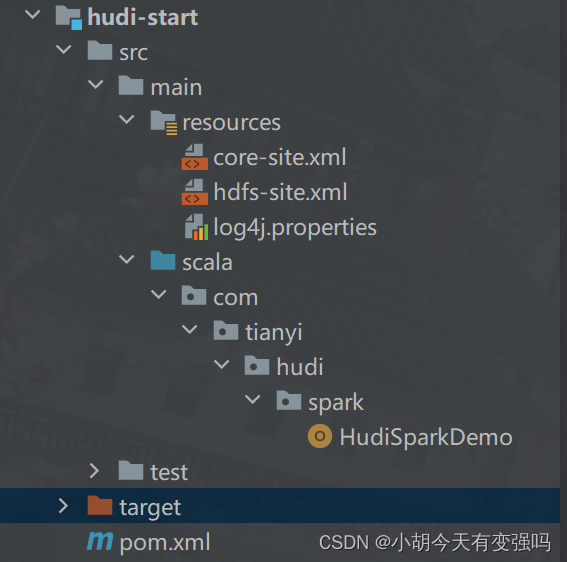
Core code
import org.apache.hudi.QuickstartUtils.DataGenerator
import org.apache.spark.sql.{
DataFrame, SaveMode, SparkSession}
/** * Hudi Framework of data Lake , be based on Spark Calculation engine , On data CURD operation , Use the taxi travel data generated by the official simulation * * Task a : Analog data , Insert Hudi surface , use COW Pattern * Task 2 : Snapshot query (Snapshot Query) data , use DSL The way * Task three : to update (Update) data * Task 4 : Incremental query (Incremental Query) data , use SQL The way * Task five : Delete (Delete) data */
object HudiSparkDemo {
/** * Official case : Simulation generates data , Insert Hudi surface , The type of the table is COW */
def insertData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// The first 1 Step 、 Simulated ride data
import org.apache.hudi.QuickstartUtils._
val dataGen: DataGenerator = new DataGenerator()
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
// insertDF.printSchema()
// insertDF.show(10, truncate = false)
// The second step : Insert data into Hudi surface
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.insert.shuffle.parallelism", 2)
//Hudi Property settings of the table
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
/** * use Snapshot Query Query table data in snapshot mode */
def queryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
// tripsDF.printSchema()
// tripsDF.show(10, truncate = false)
// The query cost is greater than 10, Less than 50 Ride data
tripsDF
.filter($"fare" >= 20 && $"fare" <=50)
.select($"driver", $"rider", $"fare", $"begin_lat", $"begin_lon", $"partitionpath", $"_hoodie_commit_time")
.orderBy($"fare".desc, $"_hoodie_commit_time".desc)
.show(20, truncate = false)
}
def queryDataByTime(spark: SparkSession, path: String):Unit = {
import org.apache.spark.sql.functions._
// Mode one : Specified string , Filter and obtain data according to date and time
val df1 = spark.read
.format("hudi")
.option("as.of.instant", "20220610160908")
.load(path)
.sort(col("_hoodie_commit_time").desc)
df1.printSchema()
df1.show(numRows = 5, truncate = false)
// Mode two : Specified string , Filter and obtain data according to date and time
val df2 = spark.read
.format("hudi")
.option("as.of.instant", "2022-06-10 16:09:08")
.load(path)
.sort(col("_hoodie_commit_time").desc)
df2.printSchema()
df2.show(numRows = 5, truncate = false)
}
/** * take DataGenerator Pass in the generated data as a parameter */
def insertData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {
import spark.implicits._
// The first 1 Step 、 Simulated ride data
import org.apache.hudi.QuickstartUtils._
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
// insertDF.printSchema()
// insertDF.show(10, truncate = false)
// The second step : Insert data into Hudi surface
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
// Replace with Overwrite Pattern
.mode(SaveMode.Overwrite)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.insert.shuffle.parallelism", 2)
//Hudi Property settings of the table
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
/** * Simulation produces Hudi Update data in table , Update it to Hudi In the table */
def updateData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator):Unit = {
import spark.implicits._
// The first 1 Step 、 Simulated ride data
import org.apache.hudi.QuickstartUtils._
// Generate updated data
val updates = convertToStringList(dataGen.generateUpdates(100))
import scala.collection.JavaConverters._
val updateDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(updates.asScala, 2).toDS()
)
// TOOD: The first 2 Step 、 Insert data into Hudi surface
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
updateDF.write
// Append mode
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi Set the attribute value of the table
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
/** * use Incremental Query Query data incrementally , You need to specify a timestamp */
def incrementalQueryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
// The first 1 Step 、 load Hudi Table data , obtain commit time Time , As an incremental query data threshold
import org.apache.hudi.DataSourceReadOptions._
spark.read
.format("hudi")
.load(path)
.createOrReplaceTempView("view_temp_hudi_trips")
val commits: Array[String] = spark
.sql(
""" |select | distinct(_hoodie_commit_time) as commitTime |from | view_temp_hudi_trips |order by | commitTime DESC |""".stripMargin
)
.map(row => row.getString(0))
.take(50)
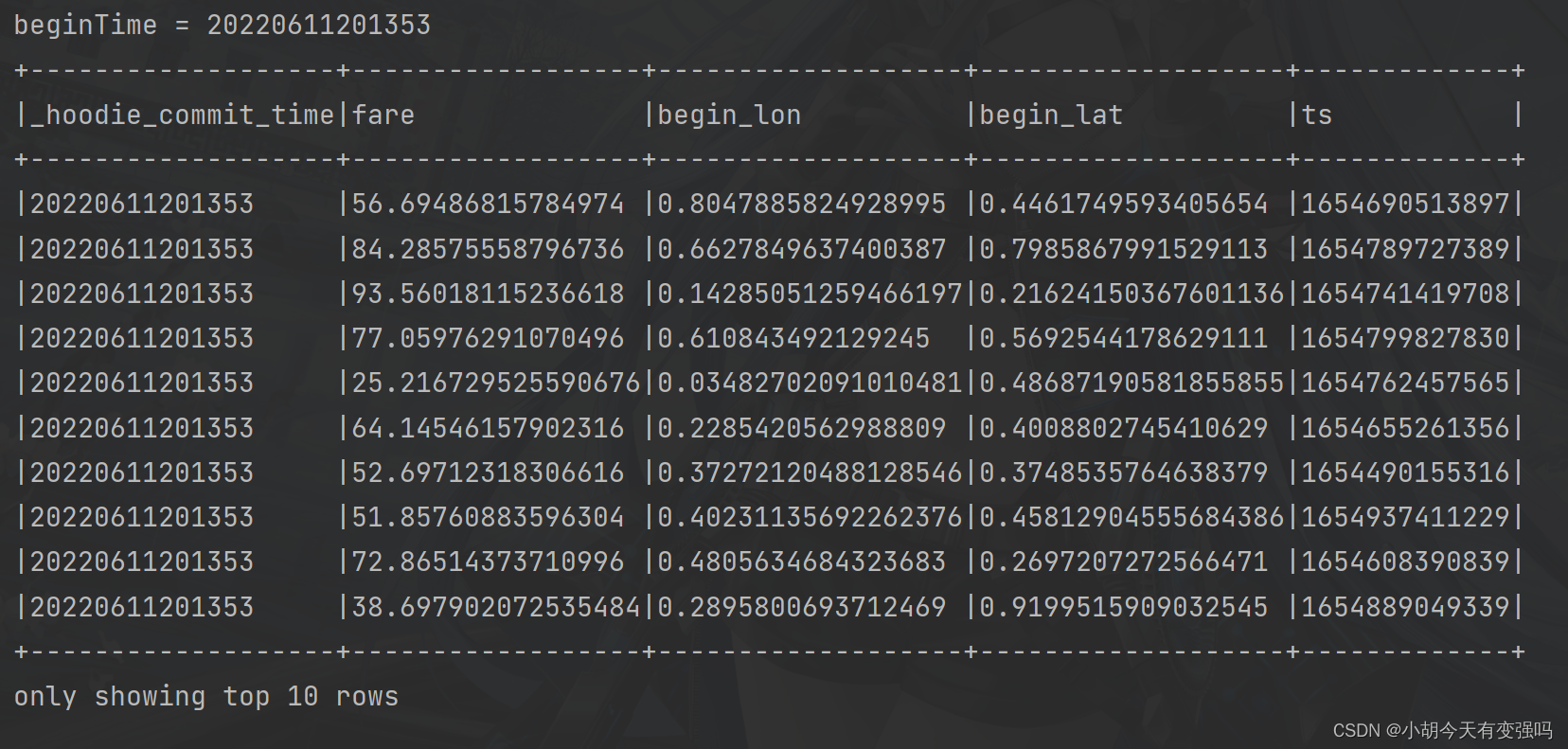
val beginTime = commits(commits.length - 1) // commit time we are interested in
println(s"beginTime = ${
beginTime}")
// The first 2 Step 、 Set up Hudi data CommitTime Time threshold , Perform incremental data query
val tripsIncrementalDF = spark.read
.format("hudi")
// Set the query data mode to :incremental, Incremental read
.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL)
// Set the start time when incrementally reading data
.option(BEGIN_INSTANTTIME.key(), beginTime)
.load(path)
// The first 3 Step 、 Register the incremental query data as a temporary view , The query cost is greater than 20 data
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark
.sql(
""" |select | `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts |from | hudi_trips_incremental |where | fare > 20.0 |""".stripMargin
)
.show(10, truncate = false)
}
/** * Delete Hudi Table data , According to the primary key uuid To delete , If it's a partition table , Specify partition path */
def deleteData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// The first 1 Step 、 load Hudi Table data , Get the number of entries
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Raw Count = ${
tripsDF.count()}")
// The first 2 Step 、 Simulate the data to be deleted , from Hudi Load data in , Get a few pieces of data , Convert to the data set to be deleted
val dataframe = tripsDF.limit(2).select($"uuid", $"partitionpath")
import org.apache.hudi.QuickstartUtils._
val dataGenerator = new DataGenerator()
val deletes = dataGenerator.generateDeletes(dataframe.collectAsList())
import scala.collection.JavaConverters._
val deleteDF = spark.read.json(spark.sparkContext.parallelize(deletes.asScala, 2))
// The first 3 Step 、 Save data to Hudi In the table , Set the operation type :DELETE
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
deleteDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Set the data operation type to delete, The default value is upsert
.option(OPERATION.key(), "delete")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
// The first 4 Step 、 Load again Hudi Table data , Count the number of entries , See if you can reduce 2 Data
val hudiDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Delete After Count = ${
hudiDF.count()}")
}
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","hty")
// establish SparkSession Sample object , Set properties
val spark: SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// Set serialization method :Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
}
// Defining variables : The name of the table 、 Save the path
val tableName: String = "tbl_trips_cow"
val tablePath: String = "/hudi_warehouse/tbl_trips_cow"
// Build a data generator , Simulate and generate business data
import org.apache.hudi.QuickstartUtils._
// Task a : Analog data , Insert Hudi surface , use COW Pattern
//insertData(spark, tableName, tablePath)
// Task 2 : Snapshot query (Snapshot Query) data , use DSL The way
//queryData(spark, tablePath)
//queryDataByTime(spark, tablePath)
// Task three : to update (Update) data , The first 1 Step 、 Simulation generates data , The first 2 Step 、 Simulation generates data , For 1 Step data field value update ,
// The first 3 Step 、 Update data to Hudi In the table
val dataGen: DataGenerator = new DataGenerator()
//insertData(spark, tableName, tablePath, dataGen)
//updateData(spark, tableName, tablePath, dataGen)
// Task 4 : Incremental query (Incremental Query) data , use SQL The way
//incrementalQueryData(spark, tablePath)
// Task five : Delete (Delete) data
deleteData(spark, tableName,tablePath)
// End of application , close resource
spark.stop()
}
}
test
perform insertData(spark, tableName, tablePath) Method, and then query it in the way of snapshot query :
queryData(spark, tablePath)

Incremental query (Incremental Query) data :
incrementalQueryData(spark, tablePath)
Reference material
https://www.bilibili.com/video/BV1sb4y1n7hK?p=21&vd_source=e21134e00867aeadc3c6b37bb38b9eee
边栏推荐
- [advanced feature learning on point clouds using multi resolution features and learning]
- LeetCode 515. 在每个树行中找最大值
- LeetCode 532. 数组中的 k-diff 数对
- [set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)
- NPM install installation dependency package error reporting solution
- Notes on numerical analysis (II): numerical solution of linear equations
- In the digital transformation, what problems will occur in enterprise equipment management? Jnpf may be the "optimal solution"
- 【点云处理之论文狂读前沿版10】—— MVTN: Multi-View Transformation Network for 3D Shape Recognition
- 【点云处理之论文狂读经典版13】—— Adaptive Graph Convolutional Neural Networks
- What is the difference between sudo apt install and sudo apt -get install?
猜你喜欢

Basic knowledge of network security

LeetCode 532. 数组中的 k-diff 数对

LeetCode 715. Range 模块
![[point cloud processing paper crazy reading classic version 13] - adaptive graph revolutionary neural networks](/img/61/aa8d0067868ce9e28cadf5369cd65e.png)
[point cloud processing paper crazy reading classic version 13] - adaptive graph revolutionary neural networks

dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article
Recommend a low code open source project of yyds
【点云处理之论文狂读前沿版11】—— Unsupervised Point Cloud Pre-training via Occlusion Completion

【点云处理之论文狂读经典版7】—— Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs
![[advanced feature learning on point clouds using multi resolution features and learning]](/img/f0/abed28e94eb4a95c716ab8cecffe04.png)
[advanced feature learning on point clouds using multi resolution features and learning]
![[point cloud processing paper crazy reading classic version 12] - foldingnet: point cloud auto encoder via deep grid deformation](/img/62/edb888200e3743b03e5b39d94758f8.png)
[point cloud processing paper crazy reading classic version 12] - foldingnet: point cloud auto encoder via deep grid deformation
随机推荐
Crawler career from scratch (I): crawl the photos of my little sister ① (the website has been disabled)
Jenkins learning (III) -- setting scheduled tasks
即时通讯IM,是时代进步的逆流?看看JNPF怎么说
Introduction to the usage of getopts in shell
2022-2-14 learning xiangniuke project - generate verification code
数字化转型中,企业设备管理会出现什么问题?JNPF或将是“最优解”
The "booster" of traditional office mode, Building OA office system, was so simple!
What are the stages of traditional enterprise digital transformation?
LeetCode 30. Concatenate substrings of all words
LeetCode 535. Encryption and decryption of tinyurl
[untitled] use of cmake
Go language - JSON processing
Digital statistics DP acwing 338 Counting problem
Install third-party libraries such as Jieba under Anaconda pytorch
On February 14, 2022, learn the imitation Niuke project - develop the registration function
LeetCode 508. The most frequent subtree elements and
LeetCode 30. 串联所有单词的子串
LeetCode 1089. Duplicate zero
【点云处理之论文狂读前沿版13】—— GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature
传统办公模式的“助推器”,搭建OA办公系统,原来就这么简单!