当前位置:网站首页>Advanced MySQL: Basics (5-8 Lectures)
Advanced MySQL: Basics (5-8 Lectures)
2022-07-04 07:27:00 【Cool as the wind, wild as a dog】
05 | Index in simple terms ( Next )
In the last article , I introduced to you InnoDB Data structure model of index , Today we'll continue to talk with MySQL Index related concepts .
Before starting this article , Let's take a look at this problem first :
Here's the watch T in , If I execute select * from T where k between 3 and 5, You need to perform several tree searches , How many lines will be scanned ?
Here is the initialization statement for this table .
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
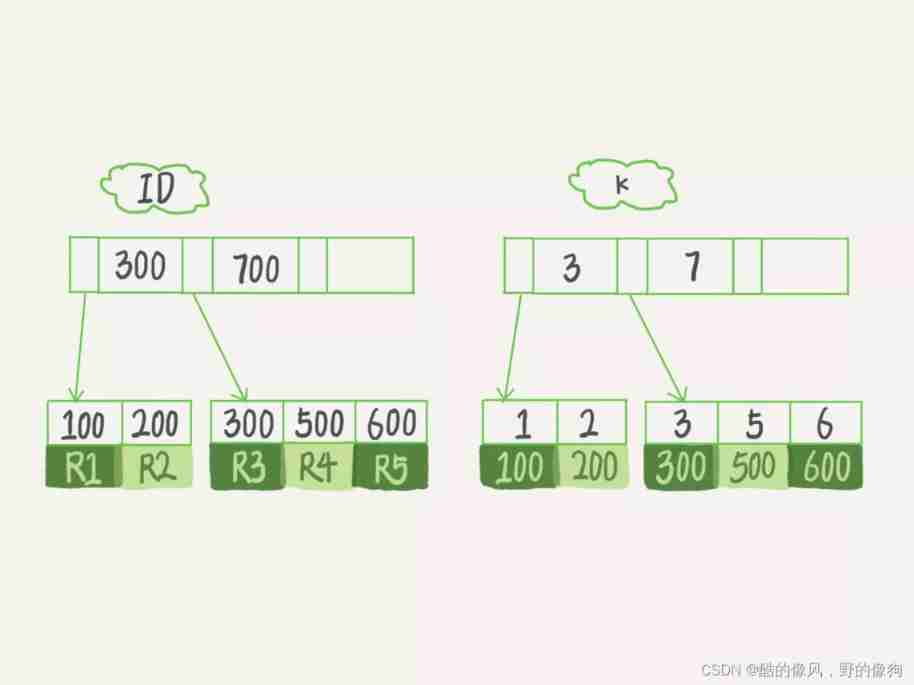
Now? , Let's take a look at this SQL The execution process of query statement :
- stay k Found on index tree k=3 The record of , obtain ID = 300;
- Until then ID Index tree found ID=300 Corresponding R3;
- stay k Index tree takes next value k=5, obtain ID=500;
- Back to ID Index tree found ID=500 Corresponding R4;
- stay k Index tree takes next value k=6, Not meeting the conditions , The loop ends .
In the process ,** Go back to the process of searching the primary key index tree , We call it return watch .** You can see , This query process read k Of the index tree 3 Bar record ( step 1、3 and 5), I went back to my watch twice ( step 2 and 4).
In this case , Because the data needed for query results is only on the primary key index , So I have to go back to my watch . that , Is it possible to be index optimized , Avoid the return process ?
Overlay index
If the executed statement is select ID from T where k between 3 and 5, At this time, we just need to check ID Value , and ID The value of is already in k On the index tree , So you can directly provide query results , There is no need to return the form . in other words , In this query , Indexes k already “ covers ” Our query needs , We call it coverage index .
Tree searches can be reduced by overwriting the index , Significantly improve query performance , Therefore, using overlay index is a common performance optimization method .
It should be noted that , Use the overlay index inside the engine to index k I actually read three records ,R3~R5( The corresponding index k Record item on ), But for MySQL Of Server Layer , It just looked for the engine and got two records , therefore MySQL Think the number of scan lines is 2.
remarks : About how to view the number of scan lines , I will be on the 16 article 《 How to display random messages correctly ?》 in , Discuss with you in detail .
Based on the description of the overlay index above , Let's talk about a problem : On a citizen information sheet , Is it necessary to establish a joint index of ID number and name ?
Suppose this is the definition of the citizen table :
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB
We know , The ID number is the only sign of the public. . in other words , If there is a need for citizen information based on the ID number. , We just need to index the ID number field. That's enough. . And build another ( ID number 、 full name ) Joint index of , Is it a waste of space ?
If there is a high frequency request now , He should check his name according to the ID number of the citizen. , This joint index makes sense . It can use overlay index on this high frequency request , There is no need to go back to the table to look up the whole record , Reduce statement execution time .
Of course , The maintenance of index fields always comes at a cost . therefore , A trade-off is needed when building redundant indexes to support coverage indexes . This is business DBA, Or the work of a business data architect .
Leftmost prefix principle
You must have a question when you see this , If you design an index for each query , Are there too many indexes . If I want to check his family address according to the citizen's ID number now? ? Although the probability of this query requirement in the business is not high , But we can't let it scan the whole table ? On the other hand , Create a separate one for an infrequent request ( ID number , Address ) The index is a bit wasteful . What should be done ?
here , Let me tell you the conclusion first .B+ Tree is an index structure , Available with index “ Left most prefix ”, To locate records .
To illustrate the concept intuitively , We use it (name,age) This joint index is used to analyze .
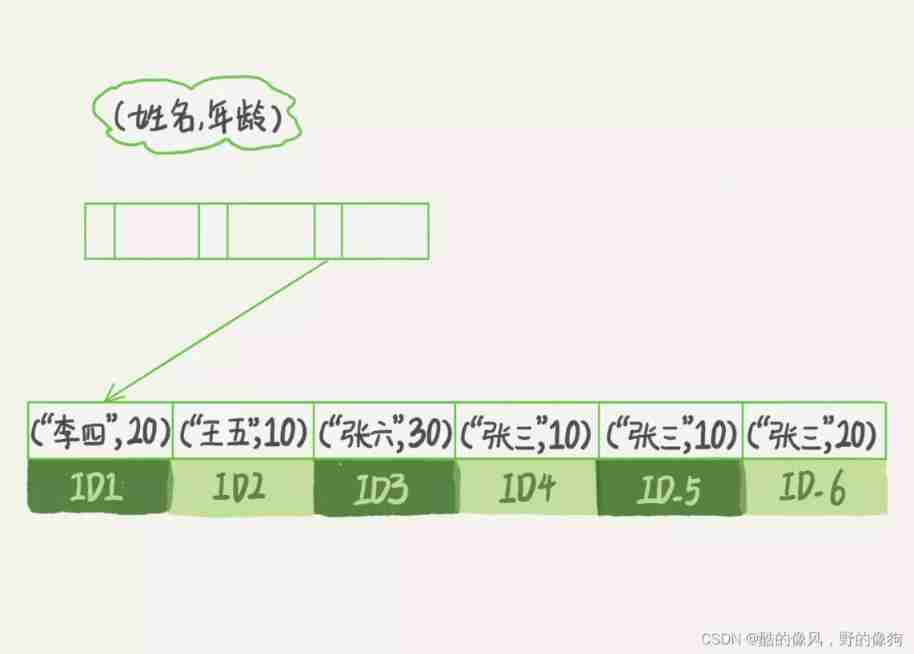
You can see , Index items are sorted according to the order of the fields in the index definition .
When your logical need is to find out all the names are “ Zhang San ” When people are , Can quickly locate ID4, Then go back and get all the results you need .
If you're looking up all the names, the first word is “ Zhang ” People who , Yours SQL The condition of the statement is "where name like ‘ Zhang %’". At this time , You can also use this index , The first eligible record found is ID3, And then go back through , Until the conditions are not met .
You can see , Not just the full definition of index , As long as the leftmost prefix is satisfied , You can use indexes to speed up retrieval . This leftmost prefix can be the leftmost of the union index N A field , It can also be the leftmost of a string index M Characters .
Based on the above description of the leftmost prefix index , Let's talk about a problem : When building a federated index , How to arrange the order of the fields in the index .
Our evaluation criteria here is , Index reusability . Because it can support the leftmost prefix , So when it's already there (a,b) After this joint index , In general, you don't need to be alone in a Index on . therefore , The first principle is , If by adjusting the order , One less index can be maintained , So this order is often the one that needs to be prioritized .
So now you know , In the question at the beginning of this paragraph , We want to create for high frequency requests ( ID number , full name ) This joint index , And support it with this index “ Inquire address according to ID number ” The needs of .
that , If there is an existing union query , Also based on a、b What about their own queries ? There are only b The sentence of , Can't use (a,b) This joint index , At this point you have to maintain another index , That means you need to maintain it at the same time (a,b)、(b) These two indexes .
Now , We want to The principle of consideration is space 了 . For example, the above table of citizens ,name The field is the ratio age Field large , Then I suggest you create one (name,age) And a (age) Single field index of .
Index push down
In the last paragraph, we talked about meeting the leftmost prefix principle , The leftmost prefix can be used to locate records in the index . At this time , You may want to ask , Those parts that don't match the leftmost prefix , What will happen ?
We still use the joint index of the citizen table (name, age) For example . If there is a need now : Search out the “ The first word of the name is Zhang , And the age is 10 All the boys at the age of ”.
that ,SQL This is how the statement is written :
mysql> select * from tuser where name like ' Zhang %' and age=10 and ismale=1;
You already know the prefix index rule , So this statement is used to search the index tree , Only use “ Zhang ”, Find the first record that meets the conditions ID3. Of course , It's not bad , Better than full scan .
so what ?
Of course, it is to judge whether other conditions are met .
stay MySQL 5.6 Before , Only from ID3 Start back to watch one by one . Find the data row on the primary key index , Then compare the field values .
and MySQL 5.6 Index push down optimization introduced (index condition pushdown), During index traversal , Judge the fields included in the index first , Filter out unqualified records directly , Reduce the number of times to return to the table .
chart 3 Sum graph 4, Is the execution flow chart of these two processes .
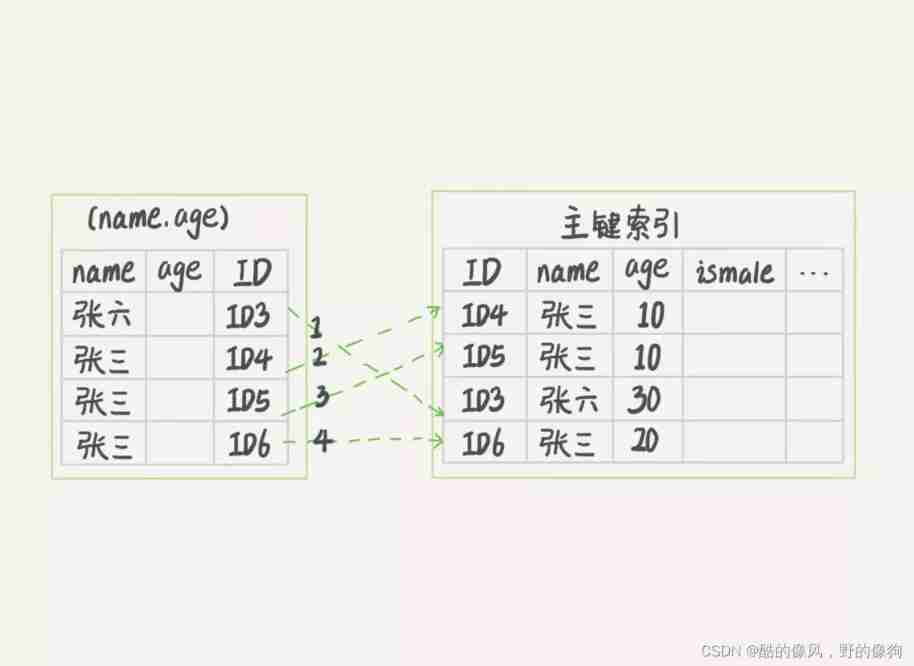
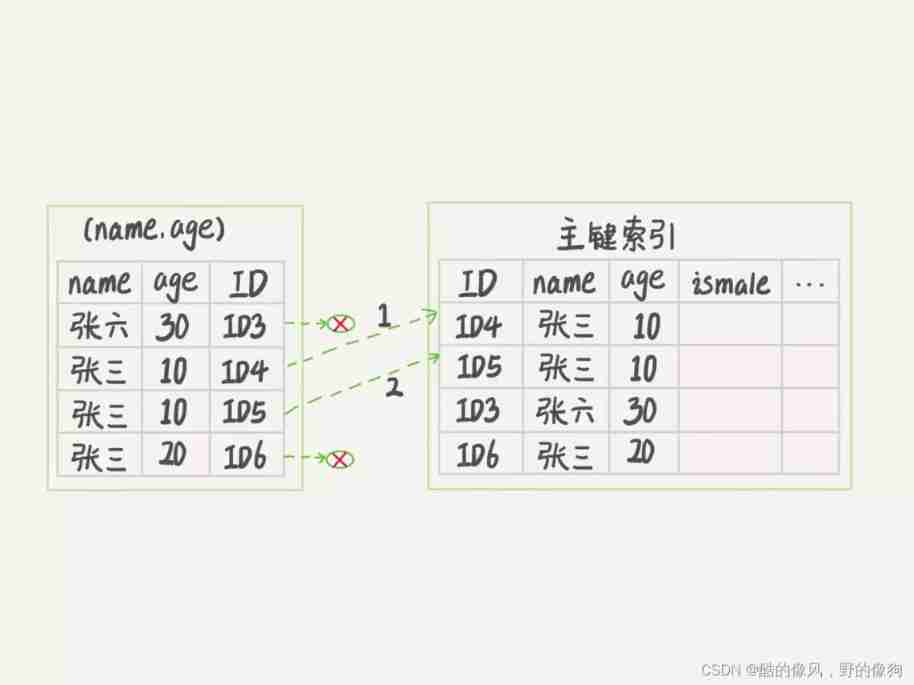
In the figure 3 and 4 In these two pictures , Each dashed arrow represents a return to the table .
chart 3 in , stay (name,age) I took it out of the index age Value , This process InnoDB Not going to see age Value , Just put... In order “name The first word is ’ Zhang ’” Take out the records one by one and return them to the table . therefore , We need to go back to the table 4 Time .
chart 4 Follow chart 3 Is the difference between the ,InnoDB stay (name,age) Inside the index, we judge age Is it equal to 10, For not equal to 10 The record of , Judge directly and skip . In our case , Only need to ID4、ID5 These two records are returned to the table for data judgment , Just go back to the table 2 Time .
Summary
Today's article , I continued to discuss the concept of database index with you , Coverage index is included 、 Prefix index 、 Index push down . You can see , In the case of satisfying the statement requirements , One of the important principles of database design is to access resources as little as possible . When we use the database , Especially when designing table structures , We should also aim at reducing resource consumption .
Let me leave you a question .
In fact, the primary key index can also use multiple fields .DBA When Xiao LV joined the new company , I found that I took over the maintenance of the library , There's a table like this , The table structure definition looks like this :
CREATE TABLE `geek` (
`a` int(11) NOT NULL,
`b` int(11) NOT NULL,
`c` int(11) NOT NULL,
`d` int(11) NOT NULL,
PRIMARY KEY (`a`,`b`),
KEY `c` (`c`),
KEY `ca` (`c`,`a`),
KEY `cb` (`c`,`b`)
) ENGINE=InnoDB;
A colleague in the company told him , For historical reasons , This watch needs a、b Make joint primary key , This little Lu understood .
however , Xiao Lu, who has studied this chapter, is puzzled again , Since the primary key contains a、b These two fields , That means separate in the field c Create an index on , It already contains three fields , Why create “ca”“cb” These two indexes ?
Colleagues told him , Because there are two kinds of statements in their business :
select * from geek where c=N order by a limit 1;
select * from geek where c=N order by b limit 1;
My question for you is , Is this colleague's explanation correct , For these two query patterns , Are both indexes required ? Why? ?
Last issue time
The question in the last issue is , Through two alter Statement rebuild index k, And through two alter Whether the statement rebuilds the primary key index is reasonable .
In the comment area , A classmate asked why we need to rebuild the index . Our article mentioned , Index may be deleted , Or page split , Cause data page to be empty , The process of re indexing creates a new index , Insert data in order , This makes the page the most efficient , That is, the index is more compact 、 More save a space .
The subject , I gave it to you “ Refer to the answer ” yes :
Rebuild index k It's reasonable , Can achieve the goal of space saving . however , The process of rebuilding the primary key is unreasonable . Whether to delete or create a primary key , Will rebuild the entire table . So if you execute these two statements together , The first sentence is done for nothing . These two sentences , You can use this sentence instead : alter table T engine=InnoDB. At the end of the column 12 An article 《 Why delete half of the table data , Table file size unchanged ?》 in , I will analyze the execution process of this statement with you .
+++
06_ Global lock and table lock : How can adding a field to a table be so much of a hindrance ?
I want to talk to you today MySQL Lock of . The original intention of database lock design is to deal with concurrent problems . Shared resources as multiple users , When concurrent access occurs , Database needs to control access rules of resources reasonably . Lock is an important data structure to implement these access rules .
** According to the range of locking ,MySQL The locks inside can be roughly divided into global locks 、 Table level lock and row lock .** Today's article , I will share global locks and table level locks with you . And about row locks , I'll keep it for you in the next article .
Here's the thing to note , The design of the lock is more complicated , These two articles will not cover the specific implementation details of locks , This paper mainly introduces the phenomenon when encountering lock and the principle behind it .
Global lock
seeing the name of a thing one thinks of its function , Global lock is to lock the whole database instance .MySQL It provides a way to add global read lock , The order is Flush tables with read lock (FTWRL). When you need to make the entire library read-only , You can use this command , After that, the following statements of other threads will be blocked : Data update statement ( Data addition, deletion and modification )、 Data definition statement ( Including building tables 、 Modify table structure, etc ) Commit statements for and update class transactions .
** A typical use scenario for global locks is , Make a full library logical backup .** That is to say, every table in the whole library select Come out and save it as text .
There used to be a way , It's through FTWRL Make sure that no other threads update the database , Then back up the entire library . Be careful , During the backup process, the entire library is completely read-only .
But make the entire library read-only , It sounds dangerous :
- If you back up on the main database , The update cannot be performed during the backup , Business basically has to stop ;
- If you are backing up from a library , During the backup period, the master database cannot be synchronized from the slave database binlog, Will cause master-slave delay .
It seems that it's not good to add a global lock . But think about it , Why is backup locked ? Let's take a look at what happens when you don't lock it .
Suppose you want to maintain “ Geek time ” The purchase system of , Focus on the user account balance table and user curriculum .
Now initiate a logical backup . Assuming the backup period , There's a user , He bought a course , His balance will be deducted from the business logic , Then add a course to the purchased course .
If the time sequence is to back up the account balance table first (u_account), And then the user buys , Then back up the user curriculum (u_course), What will happen ? You can take a look at this picture :
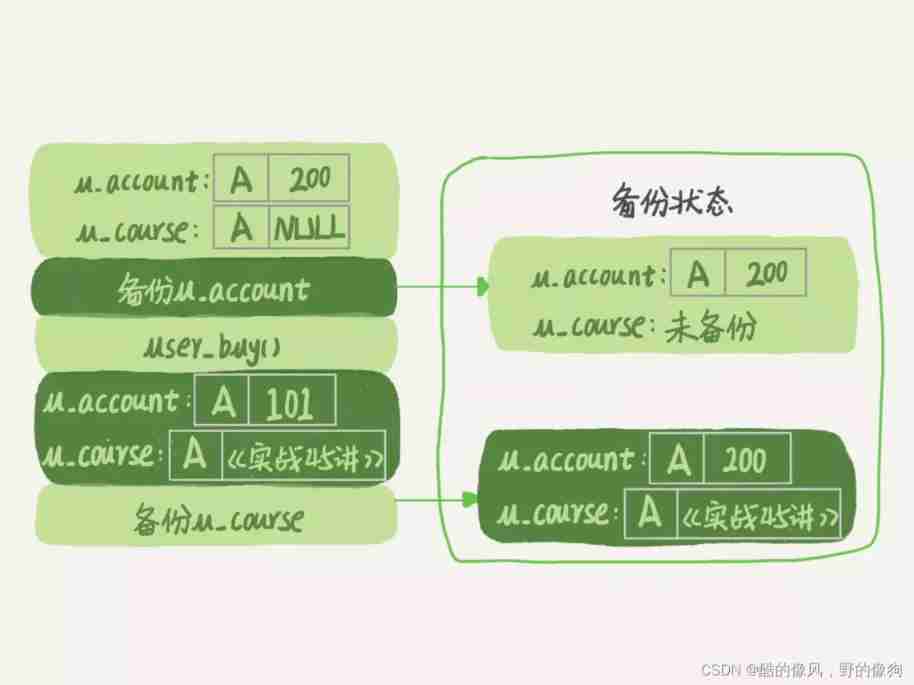
You can see , In this backup result , user A The data status of is “ The account balance is not deducted , But there is one more course in the user's curriculum ”. If you use this backup to recover data later , user A Found , I earned .
As a user, don't think it's so nice , You can imagine : If the order of the backup tables is reversed , First back up the user curriculum and then the account balance table , And what could happen ?
in other words , If you don't lock it , The library that the backup system backs up is not a logical point in time , This view is logically inconsistent .
When it comes to views, you must remember , When we talked about transaction isolation , In fact, there is a way to get a consistent view , Right ?
Yes , This is to start a transaction at the repeatable read isolation level .
remarks : If you don't have a clear concept of transaction isolation level , Let's go back to chapter 3 An article 《 The transaction isolation : Why do you change? I can't see ?》 Related content in .
The official logic backup tool is mysqldump. When mysqldump Using parameter –single-transaction When , A transaction will be started before importing data , To ensure a consistent view . And because the MVCC Support for , During this process, the data can be updated normally .
You must be wondering , With this function , Why do we still need FTWRL Well ?** Consistent reading is good , But only if the engine supports this isolation level .** such as , about MyISAM This engine does not support transactions , If there is an update during the backup , Always only get the latest data , Then it destroys the consistency of the backup . At this time , We need to use it FTWRL The command .
therefore ,**single-transaction Method only applies to all tables using the transaction engine's Library .** If some tables use an engine that does not support transactions , Then backup can only be through FTWRL Method . This is often DBA Ask business developers to use InnoDB replace MyISAM One of the reasons .
You may ask ,** Since the whole library is read-only , Why not use set global readonly=true What is the way? ?** exactly readonly Mode can also make the entire library read-only , But I'll suggest you use FTWRL The way , There are two main reasons :
- One is , In some systems ,readonly The value of will be used to do other logic , For example, it is used to determine whether a database is a primary or a standby database . therefore , modify global The way the variables affect the surface is larger , I don't recommend that you use .
- Two is , There are differences in exception handling mechanisms . If you execute FTWRL After the command, due to the abnormal disconnection of the client , that MySQL This global lock will be released automatically , The whole library can be updated normally . Instead, set the entire library to readonly after , If the client has an exception , Then the database will remain readonly state , This will cause the entire library to be in a non writable state for a long time , High risk .
Business update is not just about adding, deleting and changing data (DML), It is also possible to add fields and other operations to modify the table structure (DDL). Either way , When a library is locked globally , You need to add fields to any of the tables , It's all locked up .
however , Even if it is not locked by the whole situation , Adding fields doesn't make it easy , Because you will encounter the table level lock that we will introduce next .
Table lock
MySQL There are two types of lock at the inner table level : One is watch lock , One is metadata lock (meta data lock,MDL).
** The syntax of table lock is lock tables … read/write.** And FTWRL similar , It can be used unlock tables Active release lock , It can also be released automatically when the client is disconnected . We need to pay attention to ,lock tables The syntax will restrict the reading and writing of other threads , It also defines the next operation objects of this thread .
for instance , If in a thread A In the implementation of lock tables t1 read, t2 write; This statement , Other threads write t1、 Reading and writing t2 All of the statements will be blocked . meanwhile , Threads A In execution unlock tables Before , It can only be read t1、 Reading and writing t2 The operation of . Linking t1 Not allowed , Naturally, you can't access other tables .
Before a finer grained lock appears , Table locking is the most common way to handle concurrency . And for InnoDB This kind of engine supports row lock , Generally not used lock tables Command to control concurrency , After all, the effect of locking the whole watch is still too great .
** Another type of table level lock is MDL(metadata lock).**MDL You don't need to explicitly use , When accessing a table, it will be automatically added .MDL The role of is , Ensure the correctness of reading and writing . You can imagine , If a query is traversing data in a table , During execution, another thread changes the table structure , Delete a list , Then the result obtained by the query thread does not match the table structure , Surely not .
therefore , stay MySQL 5.5 The version introduces MDL, When adding, deleting, modifying and querying a table , Add MDL Read the lock ; When you want to make structural changes to a table , Add MDL Write lock .
- Read locks are not mutually exclusive , So you can have multiple threads to add, delete, modify and query a table at the same time .
- Read-write lock 、 Write locks are mutually exclusive , To ensure the security of the operation to change the structure of the table . therefore , If two threads want to add fields to a table at the same time , One of them can't be executed until the other has finished .
although MDL Locks are added by default , But it's a mechanism you can't ignore . Here's an example , I often see people fall into this pit : Add a field to a small table , Cause the whole library to hang .
You must know , Add fields to a table , Or modify the fields , Or the Caucasian , Need to scan the data of the whole table . When working on a large watch , You must be very careful , In order to avoid the impact on online services . But in fact , Even a small watch , Careless operation can also cause problems . Let's take a look at the following sequence of operations , Hypothesis table t It's a little watch .
remarks : The experimental environment here is MySQL 5.6.
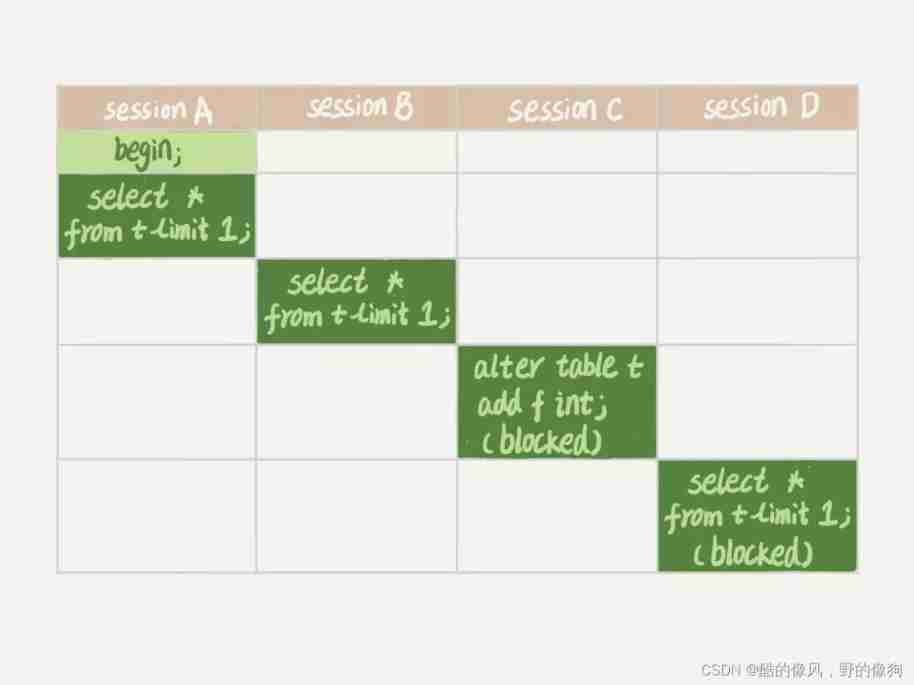
We can see session A Start... First , I'll check my watch t Add one more MDL Read the lock . because session B What is needed is MDL Read the lock , So it can be executed normally .
after session C Will be blocked, Because session A Of MDL The lock has not been released , and session C need MDL Write lock , So it can only be blocked .
If only session C It doesn't matter that I'm blocked , But after that, it's all on the watch t New application MDL The request to read the lock will also be session C Blocking . We said that before , All operations of adding, deleting, modifying and querying tables need to be applied for first MDL Read the lock , They're all locked , It means that it's completely unreadable .
If the query statements on a table are frequent , And the client has a retry mechanism , That is to say, there will be a new one after the timeout session If you ask again , The threads in this library will soon be full .
You should know by now , In the transaction MDL lock , Apply at the beginning of statement execution , However, the statement is not released immediately after completion , It will wait until the whole transaction is committed before releasing .
Based on the above analysis , Let's talk about a problem , How to add fields to a small table safely ?
First of all, we have to deal with long affairs , The transaction does not commit , Will always occupy MDL lock . stay MySQL Of information_schema Library innodb_trx In the table , You can find the current transaction in progress . If you want to do DDL The changed table happens to have a long transaction running , Consider suspending DDL, perhaps kill Drop this long business .
But think about this scenario . If the table you want to change is a hotspot table , Although the amount of data is small , But the requests are frequent , And you have to add a field , What should you do ?
Now kill It may not work , Because new requests are coming soon . The ideal mechanism is , stay alter table Set the waiting time in the statement , If you can get it within the specified waiting time MDL It's better to write lock , Don't block the following business statements if you can't get them , Give up first . Then the developer or DBA Repeat the process by retrying the command .
MariaDB Has merged AliSQL This function of , So these two open source branches currently support DDL NOWAIT/WAIT n This grammar .
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ...
Summary
today , I introduced you to MySQL Global locks and table level locks .
Global lock is mainly used in the process of logical backup . For all of them InnoDB Engine library , I suggest you choose to use –single-transaction Parameters , It's more app friendly .
Table locks are generally used when the database engine does not support row locks . If you find that your app has lock tables Such a statement , You need to trace it , The more likely scenario is :
- Either your system is still working MyISAM This type of engine does not support transactions , Then we should arrange to upgrade and change the engine ;
- Either your engine has been upgraded , But the code hasn't been upgraded . I've seen this happen , Finally, business development is to put lock tables and unlock tables Change to begin and commit, The problem is solved .
MDL Will not be released until the transaction is committed , When making table structure changes , You must be careful not to lock up online queries and updates .
Last , Let me leave you a question . Backup is usually performed on the standby database , You are using –single-transaction Method in the process of logical backup , If a small table on the main database makes a DDL, Like adding a column to a table . Now , What can be seen from the standby database ?
explain : This article does not cover physical backup , There will be a separate article on physical backup .
Last issue time last issue is about the joint primary key index and InnoDB Understanding of index organization table .
–a--|–b--|–c--|–d--
1 2 3 d
1 3 2 d
1 4 3 d
2 1 3 d
2 2 2 d
2 3 4 d
Primary key a,b The order in which the clustered indexes are organized is equivalent to order by a,b , That is, press first a Sort , Press again b Sort ,c disorder .
Indexes ca Our organization is based on c Sort , Press again a Sort , Record primary key at the same time
–c--|–a--|– Primary key part b-- ( Be careful , It's not here ab, It's just b)
2 1 3
2 2 2
3 1 2
3 1 4
3 2 1
4 2 3
This is the same as the index c The data are as like as two peas. .
Indexes cb Our organization is based on c Sort , Press b Sort , Record primary key at the same time
–c--|–b--|– Primary key part a--( ditto )
2 2 2
2 3 1
3 1 2
3 2 1
3 4 1
4 3 2
therefore , The conclusion is that ca Can be removed ,cb Need to keep .
+++
07_ The merits and demerits of line lock : How to reduce the impact of row locks on performance ?
In the last article , I introduced you to MySQL Global locks and table level locks , Today we will talk about MySQL The row lock .
MySQL The row lock is implemented by each engine in the engine layer . But not all engines support row locks , such as MyISAM The engine doesn't support row locks . Not supporting row locks means that concurrency control can only use table locks , For tables with this engine , Only one update can be executed on the same table at any time , This will affect the business concurrency .InnoDB It supports row locking , This is also MyISAM By InnoDB One of the important reasons for substitution .
Let's talk about it today InnoDB The row lock , And how to improve business concurrency by reducing lock conflicts .
seeing the name of a thing one thinks of its function , Row locks are locks for row records in the data table . That makes sense , For example, affairs. A Updated a line , And at this time business B Also update the same line , Then we have to wait for business A You can't update until the operation of .
Of course , There are also some less obvious concepts and designs in the database , If these concepts are not properly understood and used , It is easy to cause unexpected behavior of the program , Like a two-stage lock .
Start with two-stage locking
Let me give you an example . In the following sequence of operations , Business B Of update What happens when a statement is executed ? Hypothetical field id It's a watch t Primary key of .

The conclusion of this question depends on the transaction A At the end of the two update After the statement , What locks are held , And when to release . You can verify : In fact, the business B Of update The statement will be blocked , Until transaction A perform commit after , Business B In order to proceed .
Knowing the answer , You must know the business A Hold the row lock of two records , It's all in commit It was released when .
in other words , stay InnoDB Transaction , Row locks are added when needed , But it's not about releasing them immediately when they don't need to , It's about waiting until the end of the transaction . This is the two-stage lock protocol .
I know the setting , How does it help us use transactions ? That's it , If you need to lock multiple rows in your transaction , The most likely cause of lock conflict 、 The lock most likely to affect concurrency should be put back as far as possible . Let me give you an example .
Suppose you are in charge of implementing an online transaction business for movie tickets , customer A In the cinema B Purchase movie tickets . Let's simplify it a little bit , This business needs to involve the following operations :
- From customers A The movie ticket price is deducted from the account balance ;
- To the cinema B The balance of the account increases the ticket price of this movie ;
- Keep a transaction log .
in other words , To close the deal , We need to update Two records , and insert A record . Of course , To ensure the atomicity of the deal , We're going to put these three operations in one transaction . that , How would you arrange the order of these three statements in a transaction ?
Imagine if you had another customer at the same time C In the cinema B Buy tickets , So the conflict between these two transactions is the statement 2 了 . Because they want to update the balance of the same theater account , You need to modify the same row of data .
According to the two-stage lock protocol , No matter how you arrange the sentence order , All row locks required by operations are released when the transaction is committed . therefore , If you put the sentence 2 At the end , For example, according to 3、1、2 In this order , Then the lock time of the balance line of the cinema account is the least . This minimizes lock waiting between transactions , Increased concurrency .
Okay , Now because of your right design , The row lock of the cinema balance line will not stay in a transaction for a long time . however , It doesn't completely solve your problem .
If this theater is active , You can pre sell all movie tickets for a year at a low price , And it's only for one day . So at the beginning of the activity time , Yours MySQL I hung up. . You log on to the server and have a look ,CPU Consumption is close to 100%, But the whole database can't be executed every second 100 One transaction . What's the reason for this ?
here , I'm going to talk about deadlock and deadlock detection .
Deadlock and deadlock detection
Different threads in a concurrent system have circular resource dependencies , The threads involved are waiting for other threads to release resources , It will cause these threads to enter the state of infinite waiting , Deadlock . Here I use row locks in the database as an example .

Now , Business A Waiting for business B Release id=2 The row lock , And the business B Waiting for business A Release id=1 The row lock . Business A And transaction B Waiting for each other's resources to be released , Is to enter the deadlock state . When there's a deadlock , There are two strategies :
- One strategy is , Direct entry waiting , Until timeout . This timeout can be set by the parameter innodb_lock_wait_timeout To set up .
- Another strategy is , Initiate deadlock detection , After deadlock is found , Actively roll back a transaction in the deadlock chain , Allow other business to continue . The parameter innodb_deadlock_detect Set to on, Indicates that the logic is turned on .
stay InnoDB in ,innodb_lock_wait_timeout The default value of is 50s, That means if you use the first strategy , When there's a deadlock , The first locked thread will pass 50s Will time out , Then it's possible for other threads to continue . For online services , This waiting time is often unacceptable .
however , We can't directly set this time to a very small value , such as 1s. So when a deadlock occurs , It's really going to work out soon , But if it's not deadlock , It's a simple lock waiting ? therefore , If the timeout setting is too short , There will be a lot of injuries .
therefore , Under normal circumstances, we still need to adopt the second strategy , namely : Active deadlock detection , and innodb_deadlock_detect The default value of is on. Active deadlock detection when deadlock occurs , It can be found and processed quickly , But it also has an extra burden .
You can imagine the process : Whenever a transaction is locked , To see if the thread it depends on is locked by someone else , So circular , Finally, judge whether there is a cycle waiting , That's deadlock .
So if all the above transactions need to update the same row ?
Every new blocked thread , We have to judge whether it will cause deadlock due to our own joining , This is a time complexity of O(n) The operation of . Suppose there is 1000 All concurrent threads update the same row at the same time , So the deadlock detection operation is 100 Of this magnitude . Although the final test result is no deadlock , But during this period, a lot of CPU resources . therefore , You'll see CPU High utilization , But not a few transactions can be executed every second .
Based on the above analysis , Let's talk about it , How to solve the performance problem caused by this hot line update ? The crux of the problem is , Deadlock detection is costly CPU resources .
** A method of treating headache , If you can make sure that there will be no deadlock in this business , Can temporarily turn off deadlock detection .** But there is a certain risk in this operation , Because business design generally does not regard deadlock as a serious error , After all, there's a deadlock , Just roll back , Then it's OK to retry through business , This is business intact . Turning off deadlock detection means that there may be a lot of timeouts , It's business that's damaging .
** Another idea is to control concurrency .** Based on the above analysis , You'll find that if concurrency can be controlled , For example, there is only one line at a time 10 Threads updating , So the cost of deadlock detection is very low , That's not going to happen . A direct idea is , Do concurrency control on the client side . however , You will soon find that this method is not very feasible , Because there are a lot of clients . I've seen an app , Yes 600 A client , In this way, even if each client controls only 5 Concurrent threads , After summarizing to the database server , The peak concurrency may also reach 3000.
therefore , This concurrency control should be done on the database server . If you have Middleware , Consider middleware implementation ; If your team has the ability to modify MySQL Source person , It can also be done in MySQL Inside . The basic idea is , For peer updates , Queue up before getting into the engine . In this way InnoDB There won't be a lot of deadlock detection work inside .
Maybe you'll ask , If there is no database expert on the team for the time being , You can't do this , Can we optimize this problem from the design ?
You can consider reducing lock conflicts by changing one row to logical multiple lines . Take cinema accounts for example , Consider putting it on multiple records , such as 10 A record , The total number of cinema accounts is equal to this 10 The sum of the recorded values . So every time you have to add money to your movie theater account , Randomly select one of the records to add . So the probability of each conflict becomes the same 1/10, Can reduce the number of locks waiting , It also reduces the deadlock detection CPU Consume .
The plan seems to be undamaged , But in fact, such schemes need to be designed in detail according to business logic . If the account balance is likely to decrease , Such as refund logic , Then we need to consider when a branch record becomes 0 When , Code has to have special handling .
Summary
today , I introduced to you MySQL The row lock , Two phase lock protocol is involved 、 Deadlock and deadlock detection are two parts of the content .
among , I started with a two-phase agreement , We discussed with you how to arrange the right transaction statement during development . Principles here / My advice to you is : If you need to lock multiple rows in your transaction , The most likely cause of lock conflict 、 The application time of locks that are most likely to affect concurrency should be postponed as far as possible .
however , Adjusting the order of statements does not completely avoid deadlocks . So we introduce the concept of deadlock and deadlock detection , And offered three solutions , To reduce the impact of deadlock on the database . The main direction to reduce deadlocks , It is to control the amount of concurrent transactions accessing the same resource .
Last , Let me leave you a question . If you want to delete a table before 10000 Row data , There are three ways to do it :
- The first one is , Direct execution delete from T limit 10000;
- The second kind , Loop through a connection 20 Time delete from T limit 500;
- The third kind of , stay 20 Simultaneous execution of connections delete from T limit 500.
Which method would you choose ? Why? ?
Last issue time
The question I left you last time is : It can be used as a backup library –single-transaction When doing logical backup , If from the main library binlog Here comes a DDL What happens to the sentence ?
Suppose this DDL It's against tables. t1 Of , Here I list some key statements in the backup process :
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* moment 1 */
Q4:show create table `t1`;
/* moment 2 */
Q5:SELECT * FROM `t1`;
/* moment 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* moment 4 */
/* other tables */
At the beginning of the backup , To make sure RR( Repeatable ) Isolation level , Set it again RR Isolation level (Q1);
Start transaction , Here we use WITH CONSISTENT SNAPSHOT Make sure that you get a consistent view after the statement is executed (Q2);
Set a save point , This is very important (Q3);
show create To get the structure of the watch (Q4), And then we're going to officially import the data (Q5), Roll back to SAVEPOINT sp, The role here is to release t1 Of MDL lock (Q6). Of course, this part belongs to “ Superclass ”, It is not mentioned in the text above .
DDL The time from the main database varies according to the effect , I played four times . Set the title as a small table , We assume that when we arrive , If you start to execute , Then it can be executed quickly .
The answers are as follows :
- If in Q4 Statement arrives before execution , The phenomenon : No impact , What the backup got was DDL Table structure after .
- If in “ moment 2” arrive , The table structure has been changed ,Q5 When it comes to execution , newspaper Table definition has changed, please retry transaction, The phenomenon :mysqldump End ;
- If in “ moment 2” and “ moment 3” Arrive between ,mysqldump Occupy t1 Of MDL Read the lock ,binlog Blocked , The phenomenon : Master-slave delay , until Q6 Execution completed .
- from “ moment 4” Start ,mysqldump The release of the MDL Read the lock , The phenomenon : No impact , What the backup got was DDL The front table structure .
+++
08_ Is the transaction isolated or not ?
I'm at number one 3 It was mentioned in this article when talking about the level of transaction isolation , If it's a repeatable read isolation level , Business T A view will be created at startup read-view, After that T During execution , Even if there are other transactions that modify the data , Business T What I see is still the same as what I saw when I started . in other words , A transaction executed at a repeatable read isolation level , It seems that there is no struggle with the world , Not affected by the outside world .
however , In my last article , I mentioned it when I shared the row lock with you , A transaction needs to update a row , If another transaction happens to have a row lock for this row , It can't be so detached , Will be locked , Enter the waiting state . The problem is , Now that we are in a waiting state , Then wait until the transaction obtains the row lock to update the data , What is the value it reads ?
Let me give you an example . Here is the initialization statement for a table with only two rows :
mysql>
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2);

here , What we need to pay attention to is when the transaction starts .
begin/start transaction Command is not the starting point of a transaction , The first operation after they are executed InnoDB Statement of table , The business really starts . If you want to start a transaction immediately , have access to start transaction with consistent snapshot This command .
The first way to start , The consistency view is created when the first snapshot read statement is executed ;
The second way to start , The consistency view is executing start transaction with consistent snapshot Created when .
The other thing to note is that , In the whole column , If there is no special explanation in our example , All default autocommit=1.
In this case , Business C Not explicitly used begin/commit, Express this update Statement itself is a transaction , When the statement is completed, it will be submitted automatically . Business B Query after the row has been updated ; Business A Query in a read-only transaction , And chronologically, it's in transactions B After the query of .
At this time , If I tell you something B Checked up k The value of is 3, And the business A Checked up k The value of is 1, Do you feel a little dizzy ?
therefore , Today's article , I just want to explain this problem to you , I hope that through the process of solving this doubt , Can help you with InnoDB There is a further understanding of transactions and locks for .
stay MySQL in , There are two “ View ” The concept of :
- One is view. It is a virtual table defined by a query statement , Execute the query statement at the time of the call and generate the result . The syntax for creating a view is create view … , And its query method is the same as the table .
- The other is InnoDB In the realization of MVCC Consistent read view used in , namely consistent read view, Used to support RC(Read Committed, Read the submission ) and RR(Repeatable Read, Repeatable ) Implementation of isolation level .
It has no physical structure , It is used to define during the execution of a transaction “ What data can I see ”.
stay The first 3 An article 《 The transaction isolation : Why do you change? I can't see ?》 in , I explained to you once again MVCC The implementation logic of . Update for the difference between today's query and today's query , Let me explain it in another way , hold read view Open . You can take a deeper understanding of MVCC.
“ snapshot ” stay MVCC How does Li work ?
At repeatable read isolation level , When the transaction starts “ Took a snapshot ”. Be careful , This snapshot is based on the entire library .
At this time , You would say it doesn't seem realistic . If a library has 100G, So I start a transaction ,MySQL Just copy 100G Data from , How slow the process is . But , I usually carry out affairs very quickly .
actually , We don't need to copy this 100G The data of . Let's take a look at how this snapshot is implemented .
InnoDB Each transaction has a unique transaction ID, called transaction id. It is at the beginning of the transaction to InnoDB Of the transaction system , It is strictly increasing in the order of application .
And each row of data has multiple versions . Every time a transaction updates data , Will generate a new data version , And the transaction id The transaction assigned to this data version ID, Write it down as row trx_id. meanwhile , Keep the old data version , And in the new data version , You can get information directly .
in other words , A row in a data table , There may be multiple versions (row), Each version has its own row trx_id.
Pictured 2 Shown , It is the state of a record that is continuously updated by multiple transactions .
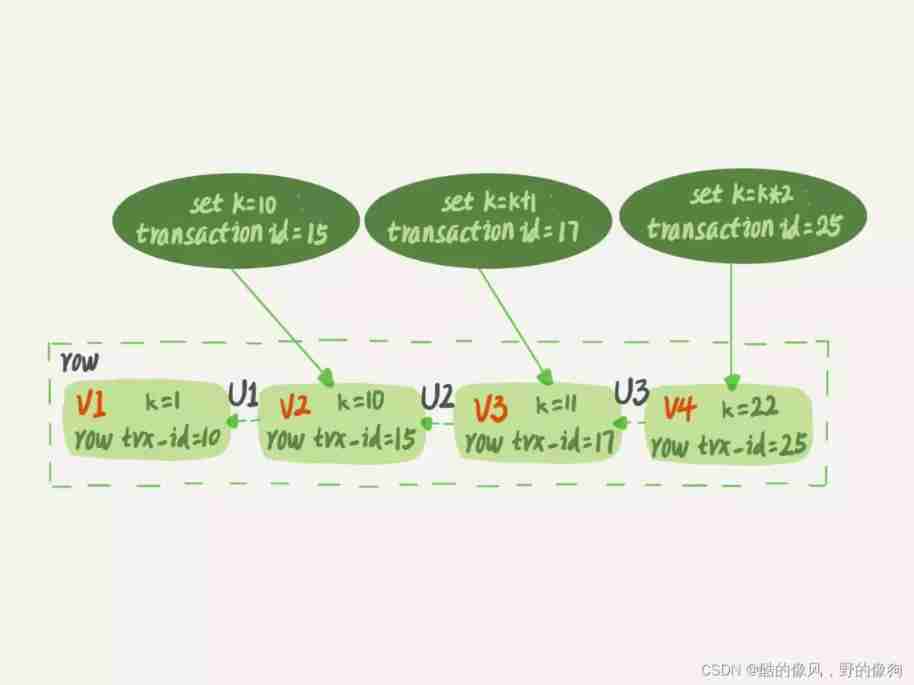
The dotted line in the figure shows the same line of data 4 A version , The latest version is V4,k The value of is 22, It is be transaction id by 25 Transaction update of , So it's row trx_id It's also 25.
You may ask , The previous article does not say , Statement update generates undo log( Rollback log ) Do you ? that ,undo log Where to? ?
actually , chart 2 Three dashed arrows in , Namely undo log; and V1、V2、V3 It's not physically real , It's based on the current version and undo log Calculated . such as , need V2 When , It is through V4 Execute sequentially U3、U2 Figure out .
See, multiple versions and row trx_id After the concept of , Let's think about it again ,InnoDB How to define that “100G” A snapshot of .
According to the definition of repeatable reading , When a transaction starts , Be able to see the results of all transactions that have been committed . But after that, , During the execution of this transaction , Updates to other transactions are not visible to it .
therefore , A transaction only needs to declare at startup that ,“ At the moment I start , If a data version is generated before I start , Just admit it ; If it was generated after I started , I don 't know , I have to find the last version of it ”.
Of course , If “ Last version ” Nor visible , Then we have to move on . also , If it is the data updated by the transaction itself , It still has to recognize itself .
On the implementation , InnoDB An array is constructed for each transaction , Used to save the transaction startup moment , Right now “ active ” All the business of ID.“ active ” Refers to , Launched but not yet submitted .
Transactions in the array ID The minimum value of is recorded as low water level , Transactions that have been created in the current system ID The maximum value of plus 1 Record as high water level .
This view array and high water level , It makes up the consistency view of the current transaction (read-view).
And the visibility rules of data version , It's data-based row trx_id Compared with the consistency view, the result is .
This view array takes all the row trx_id It's divided into several different situations .

such , For the moment the current transaction starts , A data version of row trx_id, There are several possibilities :
If it falls on the green part , Indicates that the version is a committed transaction or is generated by the current transaction itself , This data is visible ;
If it falls on the red part , Indicates that this version is generated by a transaction that will be started in the future , It's definitely invisible ;
If it falls on the yellow part , There are two situations
a. if row trx_id In the array , Indicates that this version is generated by uncommitted transactions , invisible ;
b. if row trx_id Not in array , Indicates that this version is generated by committed transactions , so .
such as , For Graphs 2 According to the data in , If there is a business , Its low water level is 18, So when it accesses this row of data , It will start from V4 adopt U3 To calculate the V3, So in its view , The value of this line is 11.
You see , With this statement , Subsequent updates in the system , It has nothing to do with what this transaction sees ? Because of the later updates , The generated version must belong to the above 2 perhaps 3(a) The situation of , And for it , These new data versions don't exist , The snapshot of this transaction, so , Namely “ static state ” Of course. .
So now you know ,InnoDB Take advantage of “ There are multiple versions of all the data ” This characteristic of , Realized “ Seconds to create a snapshot ” The ability of .
Next , Let's move on to the following picture 1 Three things in , Analyze the business A The result returned by the statement of , Why k=1.
here , Let's make the following assumptions :
- Business A Prior to the start , There is only one active transaction in the system ID yes 99;
- Business A、B、C The version numbers of are 100、101、102, And there are only four transactions in the current system ;
- Before three things begin ,(1,1) This line of data row trx_id yes 90.
such , Business A The view array of is [99,100], Business B The array of views for is [99,100,101], Business C The array of views for is [99,100,101,102].
To simplify the analysis , I'll get rid of the other distractions , It's just the business A Operations related to the query logic :
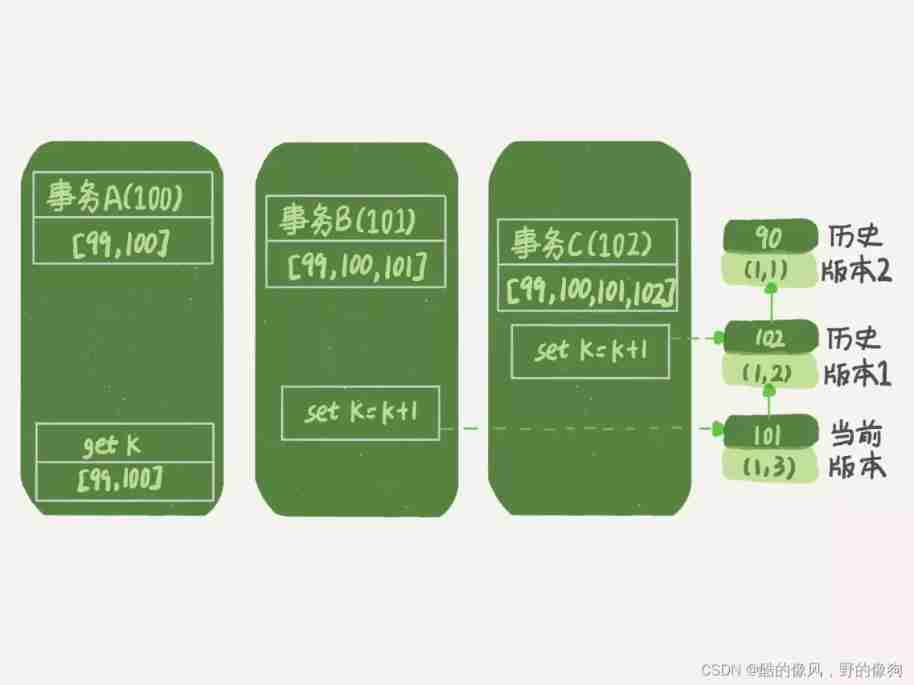
As you can see from the diagram , The first valid update is the transaction C, The data from (1,1) Changed to (1,2). Now , The latest version of this data row trx_id yes 102, and 90 This version has become a historical version .
The second valid update is the transaction B, The data from (1,2) Changed to (1,3). Now , The latest version of this data ( namely row trx_id) yes 101, and 102 It's a historical version again .
You may have noticed , In the transaction A When querying , In fact, the business B Not yet submitted , But it produces (1,3) This version has become the current version . But this version of transaction A It has to be invisible , Otherwise it will become dirty reading .
good , Now business A It's time to read the data , Its view array is [99,100]. Yes, of course , Data is read from the current version . therefore , Business A The data reading process of query statement is as follows :
- find (1,3) When , Determine the row trx_id=101, It's bigger than the high water level , In the red zone , invisible ;
- next , Find the last historical version , Take a look row trx_id=102, It's bigger than the high water level , In the red zone , invisible ;
- Look forward to , Finally found (1,1), its row trx_id=90, Less than the low water level , In the Green Zone , so .
This is how it works , Although this row of data has been modified during the period , But the business A Whenever you look up , The result of seeing this line of data is consistent , So we call it consistent reading .
This judgment rule is directly translated from the code logic , But as you can see , Visibility for human flesh analysis is cumbersome .
therefore , Let me translate it for you . A data version , For a transaction view , Except that your updates are always visible , There are three situations :
- Version not submitted , invisible ;
- Version submitted , But it was submitted after the view was created , invisible ;
- Version submitted , And it was submitted before the view was created , so .
Now? , We use this rule to judge graphs 4 Query results in , Business A The view array of query statements is in transaction A Generated at startup , Now :
- (1,3) It hasn't been submitted yet , Belong to the situation 1, invisible ;
- (1,2) Although submitted , But it was submitted after the view array was created , Belong to the situation 2, invisible ;
- (1,1) It was submitted before the view array was created , so .
You see , After taking out the number comparison , Judge only in chronological order , Is it much easier to analyze . therefore , We will use this rule to analyze .
Update logic
Careful students may have questions : Business B Of update sentence , If you read according to consistency , It seems that the result is wrong ?
Look at the picture 5 in , Business B The view array of is generated first , After that C To submit , It's not supposed to be invisible (1,2) Do you , How can you figure out (1,3) Come on ?
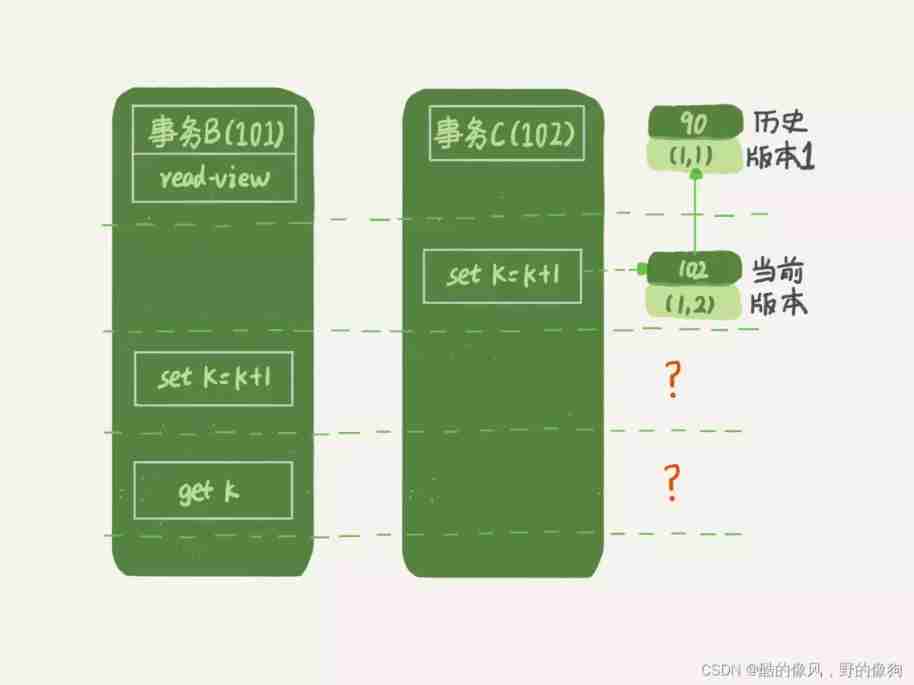
Yes , If the transaction B Query data once before updating , This query returns k The value of is really 1.
however , When it's going to update the data , You can't update the historical version anymore , Otherwise, the transaction C The update of was lost . therefore , Business B At this time set k=k+1 Is in (1,2) Based on the operation of .
therefore , Here's a rule : The updated data is read first and then written , And this read , Can only read the current value , be called “ The current reading ”(current read).
therefore , At the time of the update , The current data we read is (1,2), After the update, a new version of the data is generated (1,3), This new version of row trx_id yes 101.
therefore , In the execution of the transaction B When querying statements , Take a look at their own version number is 101, The version number of the latest data is also 101, It's your own update , You can use it directly , So the query results in k The value of is 3.
Here we mention a concept , It's called current reading . Actually , except update Out of statement ,select If the statement is locked , It's also the current reading .
therefore , If the business A Query statement select * from t where id=1 Revise it , add lock in share mode or for update, You can also read that the version number is 101 The data of , Back to k The value of is 3. The next two select sentence , That is to add the read lock respectively (S lock , Shared lock ) And write lock (X lock , Exclusive lock ).
mysql> select k from t where id=1 lock in share mode;
mysql> select k from t where id=1 for update;
One more step forward , What if C It wasn't submitted immediately , It becomes the following business C’, What will happen ?

Business C’ The difference is that the , The update was not submitted immediately , Before it's submitted , Business B The update statement of is initiated first . As I said before , Although the business C’ It hasn't been submitted yet , however (1,2) This version has also been generated , And it's the latest version of . that , Business B How to deal with the update statement of ?
Now , We mentioned in the last article “ Two stage lock protocol ” We're going to play . Business C’ Not submitted , in other words (1,2) The write lock on this version has not been released . And the business B It's the current reading , You have to read the latest version , And it has to be locked , So it's locked up , We have to wait for business C’ Release the lock , In order to continue its current reading .
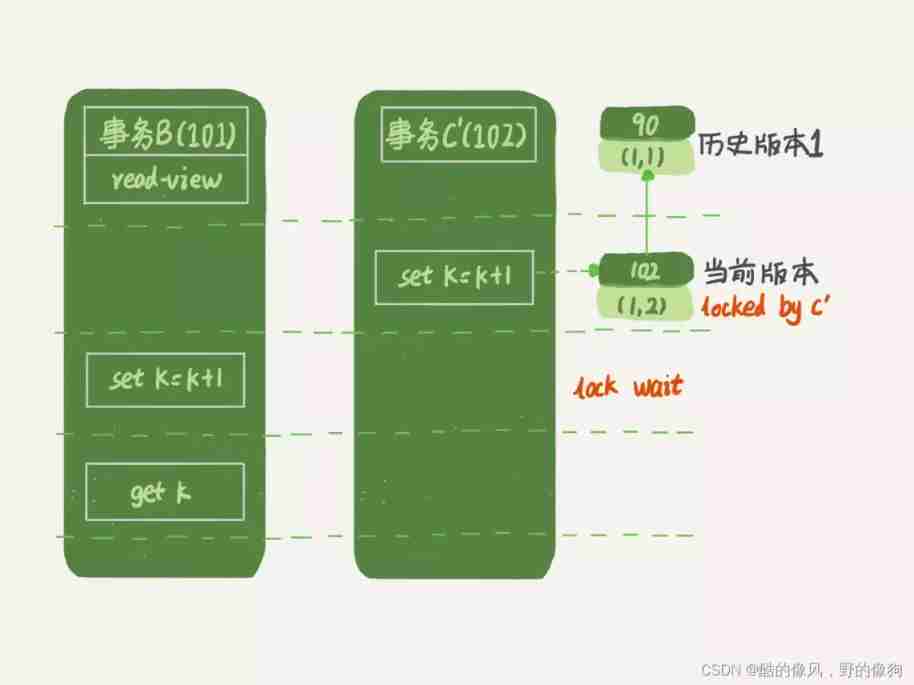
Come here , We read consistency 、 The current read and row locks are linked .
Now? , Let's go back to the question at the beginning of the article : How is the ability to reread transactions possible ?
The core of repeatable reading is consistent reading (consistent read); When the transaction updates the data , You can only use the current reading . If the row lock of the current record is occupied by other transactions , You need to enter the lock and wait .
The logic of read submission is similar to that of repeatable reading , The main difference between them is :
- At repeatable read isolation level , Just create the consistency view at the beginning of the transaction , After that, other queries in the transaction share the consistency view ;
- Under read commit isolation level , A new view is recalculated before each statement is executed .
that , Let's see , Under read commit isolation level , Business A And transaction B The query statement of k, How much should the difference be ?
There's a little bit of clarification here ,“start transaction with consistent snapshot; ” It means to start with this sentence , Create a consistent snapshot of the entire transaction . therefore , Under read commit isolation level , This usage is meaningless , Equivalent to ordinary start transaction.
Here's the status diagram when reading commit , You can see that the timing of creating the view array of these two query statements has changed , It's the read view box .( Be careful : here , We still use business C The logic of direct submission , Not business C’)
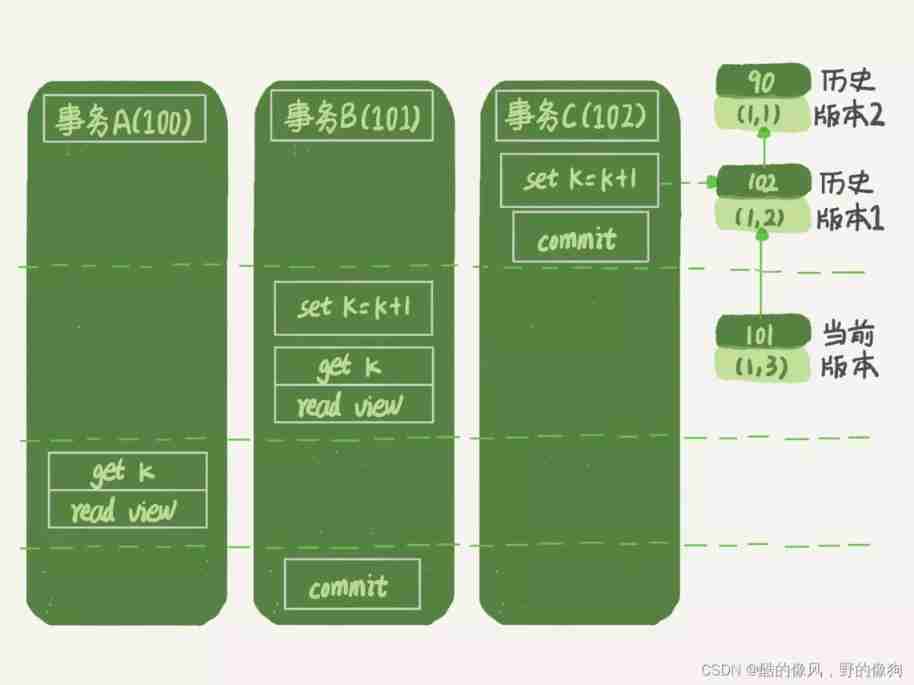
At this time , Business A The view array of the query statement is created when the statement is executed , In time sequence (1,2)、(1,3) The generation time of the view array is all before the time when the view array is created . however , At this moment :
- (1,3) It hasn't been submitted yet , Belong to the situation 1, invisible ;
- (1,2) submitted , Belong to the situation 3, so .
therefore , It's time for business A The query statement returns k=2.
apparently , Business B Query results k=3.
Summary
InnoDB There are multiple versions of row data for , Each data version has its own row trx_id, Each transaction or statement has its own consistency view . Common query statements are consistent reads , Consistent reading will be based on row trx_id And consistency view to determine the visibility of the data version .
- For repeatable reading , The query only acknowledges data that has been committed before the transaction started ;
- For read submissions , The query only acknowledges data that has been submitted before the statement was started ;
And now reading , Always read the latest version that has been committed .
You can also think about , Why does table structure not support “ Repeatable ”? This is because the table structure has no corresponding row data , either row trx_id, So we can only follow the logic of the current reading .
Of course ,MySQL 8.0 You can put the table structure in InnoDB It's in the dictionary , Maybe we will support repeatable reading of table structure in the future .
It's time to think again . I use the following table structure and initialization statements as the experimental environment , Transaction isolation level is repeatable read . Now? , I'm going to put all “ Field c and id Rows with equal values ” Of c It's worth clearing , But I found one “ Weird ” Of 、 What can't be changed . Please construct this situation , And explain its principle .
mysql>
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);
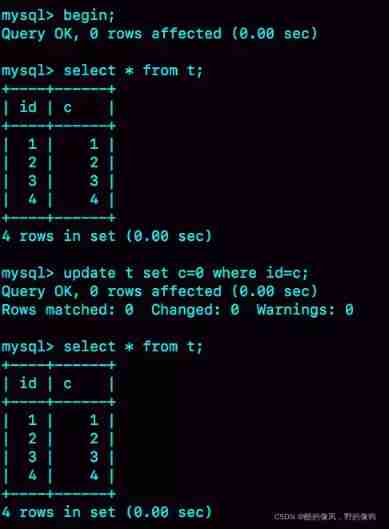
When it reappears , Please think again , Is it possible to encounter this situation in actual business development ? Will your application code fall into this “ pit ” in , How did you solve it ?
Last issue time
At the end of my last article , The question for you is : How to delete the front of the table 10000 That's ok . More messages choose the second way , namely : Loop through a connection 20 Time delete from T limit 500.
It's true , The second way is relatively better .
The first way ( namely : Direct execution delete from T limit 10000) Inside , A single statement takes a long time , It takes a long time to lock ; And big transactions can also cause master-slave delays .
The third way ( namely : stay 20 Simultaneous execution of connections delete from T limit 500), Lock conflict will be caused artificially .
边栏推荐
- Industrial computer anti-virus
- the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
- The crackdown on Huawei prompted made in China to join forces to fight back, and another enterprise announced to invest 100 billion in R & D
- flask-sqlalchemy 循环引用
- 两年前美国芯片扭捏着不卖芯片,如今芯片堆积如山祈求中国帮忙
- Novel website program source code that can be automatically collected
- SQL foundation 9 [grouping data]
- What is industrial computer encryption and how to do it
- Blog stop statement
- There is no Chinese prompt below when inputting text in win10 Microsoft Pinyin input method
猜你喜欢

Centos8 install mysql 7 unable to start up
提升复杂场景三维重建精度 | 基于PaddleSeg分割无人机遥感影像
Computer connects raspberry pie remotely through putty
Adaptive spatiotemporal fusion of multi-target networks for compressed video perception enhancement
System architecture design of circle of friends

A new understanding of how to encrypt industrial computers: host reinforcement application

Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Detailed introduction to the big changes of Xcode 14
![[Android reverse] function interception (use cache_flush system function to refresh CPU cache | refresh CPU cache disadvantages | recommended time for function interception)](/img/5c/afb0d43665a8b46579dc604d983790.jpg)
[Android reverse] function interception (use cache_flush system function to refresh CPU cache | refresh CPU cache disadvantages | recommended time for function interception)

window上用.bat文件启动项目
随机推荐
[kubernetes series] kubesphere is installed on kubernetes
Chain ide -- the infrastructure of the metauniverse
Rapidjson reading and writing JSON files
It's healthy to drink medicinal wine like this. Are you drinking it right
手写简易版flexible.js以及源码分析
Zephyr study notes 2, scheduling
rapidjson读写json文件
Blue Bridge Cup Quick sort (code completion)
【Kubernetes系列】Kubernetes 上安装 KubeSphere
Redis - detailed explanation of cache avalanche, cache penetration and cache breakdown
Data double write consistency between redis and MySQL
Flink memory model, network buffer, memory tuning, troubleshooting
Distributed transaction management DTM: the little helper behind "buy buy buy"
Campus network problems
Introduction to deep learning Ann neural network parameter optimization problem (SGD, momentum, adagrad, rmsprop, Adam)
Implementation of ZABBIX agent active mode
Routing decorator of tornado project
Jianmu continuous integration platform v2.2.2 release
tornado项目之路由装饰器
BibTex中参考文献种类