当前位置:网站首页>Redis入门完整教程:哈希说明
Redis入门完整教程:哈希说明
2022-07-04 22:29:00 【谷哥学术】
几乎所有的编程语言都提供了哈希(hash)类型,它们的叫法可能是哈
希、字典、关联数组。在Redis中,哈希类型是指键值本身又是一个键值对
结构,形如value={ {field1,value1},...{fieldN,valueN}},Redis键值对和
哈希类型二者的关系可以用图2-14来表示。
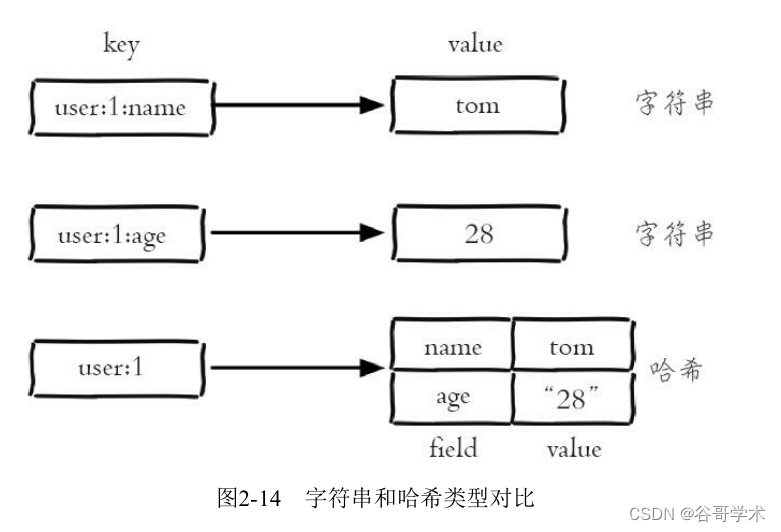
哈希类型中的映射关系叫作field-value,注意这里的value是指field对应
的值,不是键对应的值,请注意value在不同上下文的作用。
2.3.1 命令
(1)设置值
hset key field value
下面为user:1添加一对field-value:
127.0.0.1:6379> hset user:1 name tom
(integer) 1
如果设置成功会返回1,反之会返回0。此外Redis提供了hsetnx命令,它
们的关系就像set和setnx命令一样,只不过作用域由键变为field。
(2)获取值
hget key field
例如,下面操作获取user:1的name域(属性)对应的值:
127.0.0.1:6379> hget user:1 name
"tom"
如果键或field不存在,会返回nil:
127.0.0.1:6379> hget user:2 name
(nil)
127.0.0.1:6379> hget user:1 age
(nil)
(3)删除field
hdel key field [field ...]
hdel会删除一个或多个field,返回结果为成功删除field的个数,例如:
127.0.0.1:6379> hdel user:1 name
(integer) 1
127.0.0.1:6379> hdel user:1 age
(integer) 0
(4)计算field个数
hlen key
例如user:1有3个field:
127.0.0.1:6379> hset user:1 name tom
(integer) 1
127.0.0.1:6379> hset user:1 age 23
(integer) 1
127.0.0.1:6379> hset user:1 city tianjin
(integer) 1
127.0.0.1:6379> hlen user:1
(integer) 3
(5)批量设置或获取field-value
hmget key field [field ...]
hmset key field value [field value ...]
hmset和hmget分别是批量设置和获取field-value,hmset需要的参数是key
和多对field-value,hmget需要的参数是key和多个field。例如:
127.0.0.1:6379> hmset user:1 name mike age 12 city tianjin
OK
127.0.0.1:6379> hmget user:1 name city
1) "mike"
2) "tianjin"
(6)判断field是否存在
hexists key field
例如,user:1包含name域,所以返回结果为1,不包含时返回0:
127.0.0.1:6379> hexists user:1 name
(integer) 1
(7)获取所有field
hkeys key
hkeys命令应该叫hfields更为恰当,它返回指定哈希键所有的field,例
如:
127.0.0.1:6379> hkeys user:1
1) "name"
2) "age"
3) "city"
(8)获取所有value
hvals key
下面操作获取user:1全部value:
127.0.0.1:6379> hvals user:1
1) "mike"
2) "12"
3) "tianjin"
(9)获取所有的field-value
hgetall key
下面操作获取user:1所有的field-value:
127.0.0.1:6379> hgetall user:1
1) "name"
2) "mike"
3) "age"
4) "12"
5) "city"
6) "tianjin"
开发提示
在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能。
如果开发人员只需要获取部分field,可以使用hmget,如果一定要获取全部
field-value,可以使用hscan命令,该命令会渐进式遍历哈希类型,hscan将在
2.7节介绍。
(10)hincrby hincrbyfloat
hincrby key field
hincrbyfloat key field
hincrby和hincrbyfloat,就像incrby和incrbyfloat命令一样,但是它们的作
用域是filed。
(11)计算value的字符串长度(需要Redis3.2以上)
hstrlen key field
例如hget user:1name的value是tom,那么hstrlen的返回结果是3:
127.0.0.1:6379> hstrlen user:1 name
(integer) 3
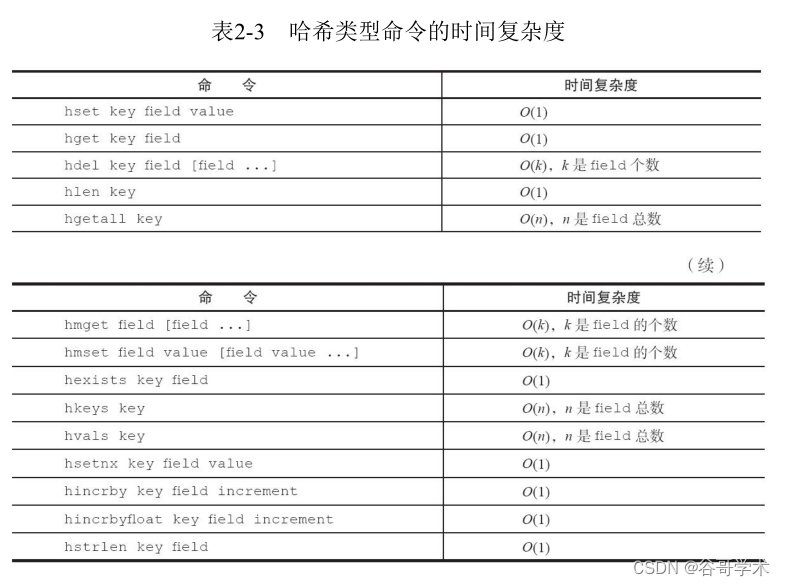
表2-3是哈希类型命令的时间复杂度,开发人员可以参考此表选择适合
的命令。
2.3.2 内部编码
哈希类型的内部编码有两种:
·ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries
配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64
字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的
结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
·hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使
用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而
hashtable的读写时间复杂度为O(1)。
下面的示例演示了哈希类型的内部编码,以及相应的变化。
1)当field个数比较少且没有大的value时,内部编码为ziplist:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
2.1)当有value大于64字节,内部编码会由ziplist变为hashtable:
127.0.0.1:6379> hset hashkey f3 "one string is bigger than 64 byte... 忽略 ..."
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
2.2)当field个数超过512,内部编码也会由ziplist变为hashtable:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2 f3 v3 ... 忽略 ... f513 v513
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
2.3.3 使用场景
图2-15为关系型数据表记录的两条用户信息,用户的属性作为表的列,
每条用户信息作为行。
如果将其用哈希类型存储,如图2-16所示。
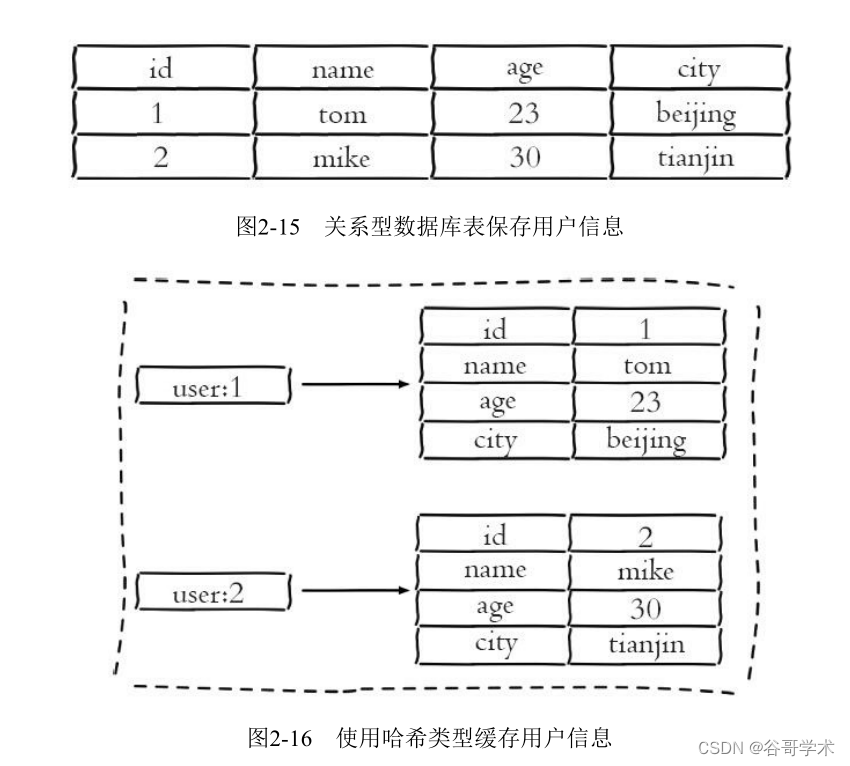
相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且
102
在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对field-
value对应每个用户的属性,类似如下伪代码:
UserInfo getUserInfo(long id){
// 用户 id 作为 key 后缀
userRedisKey = "user:info:" + id;
// 使用 hgetall 获取所有用户信息映射关系
userInfoMap = redis.hgetAll(userRedisKey);
UserInfo userInfo;
if (userInfoMap != null) {
// 将映射关系转换为 UserInfo
userInfo = transferMapToUserInfo(userInfoMap);
} else {
// 从 MySQL 中获取用户信息
userInfo = mysql.get(id);
// 将 userInfo 变为映射关系使用 hmset 保存到 Redis 中
redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));
// 添加过期时间
redis.expire(userRedisKey, 3600);
}
return userInfo;
}
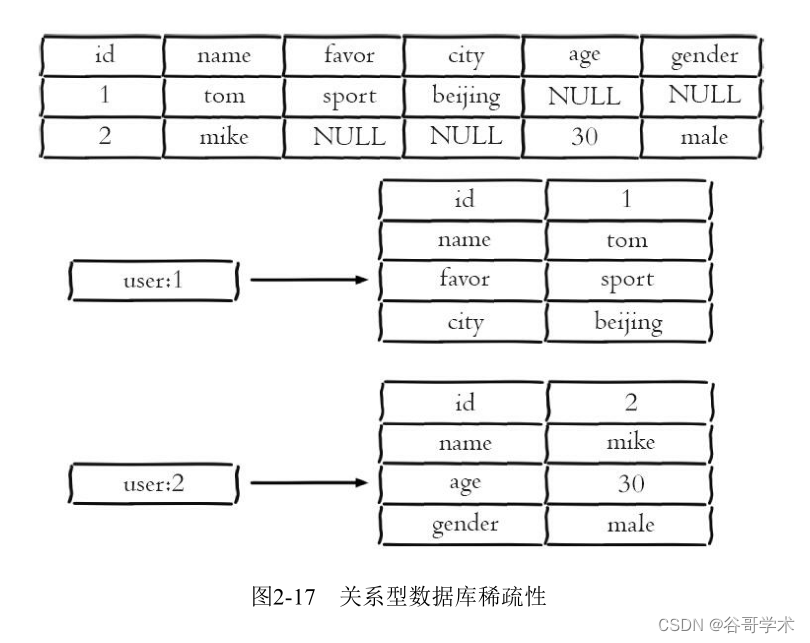
但是需要注意的是哈希类型和关系型数据库有两点不同之处:
·哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型
每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为
其设置值(即使为NULL),如图2-17所示。
·关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询
开发困难,维护成本高。
开发人员需要将两者的特点搞清楚,才能在适合的场景使用适合的技
术。到目前为止,我们已经能够用三种方法缓存用户信息,下面给出三种方
案的实现方法和优缺点分析。
1)原生字符串类型:每个属性一个键。
set user:1:name tom
set user:1:age 23
set user:1:city beijing
优点:简单直观,每个属性都支持更新操作。
缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,
所以此种方案一般不会在生产环境使用。
2)序列化字符串类型:将用户信息序列化后用一个键保存。
set user:1 serialize(userInfo)
优点:简化编程,如果合理的使用序列化可以提高内存的使用效率。
缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全
部数据取出进行反序列化,更新后再序列化到Redis中。
3)哈希类型:每个用户属性使用一对field-value,但是只用一个键保
存。
hmset user:1 name tomage 23 city beijing
优点:简单直观,如果使用合理可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会
消耗更多内存。
边栏推荐
- PostgreSQL server programming aggregation and grouping
- [the 2023 autumn recruitment of MIHA tour] open [the only exclusive internal push code of school recruitment eytuc]
- 浅聊一下中间件
- About stack area, heap area, global area, text constant area and program code area
- The overview and definition of clusters can be seen at a glance
- LOGO特训营 第五节 字体结构与设计常用技法
- Redis入门完整教程:HyperLogLog
- 关于栈区、堆区、全局区、文字常量区、程序代码区
- 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
- 新版判断PC和手机端代码,手机端跳转手机端,PC跳转PC端最新有效代码
猜你喜欢
Google Earth Engine(GEE)——基于 MCD64A1 的 GlobFire 日常火灾数据集
浅聊一下中间件
Serial port data frame

都说软件测试很简单有手就行,但为何仍有这么多劝退的?

Sobel filter
SPSS installation and activation tutorial (including network disk link)

醒悟的日子,我是怎么一步一步走向软件测试的道路
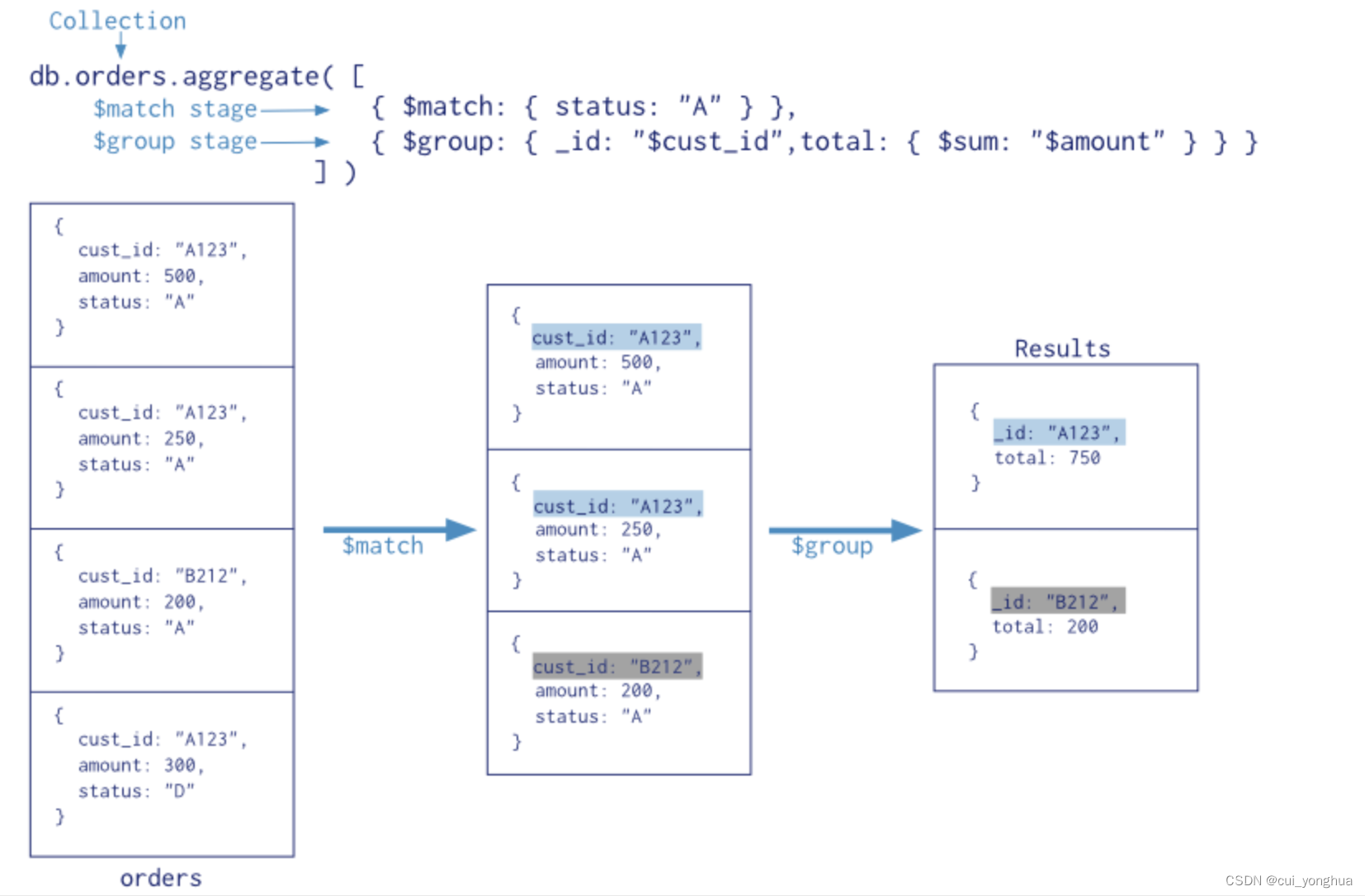
Mongodb aggregation operation summary
业务太忙,真的是没时间搞自动化理由吗?
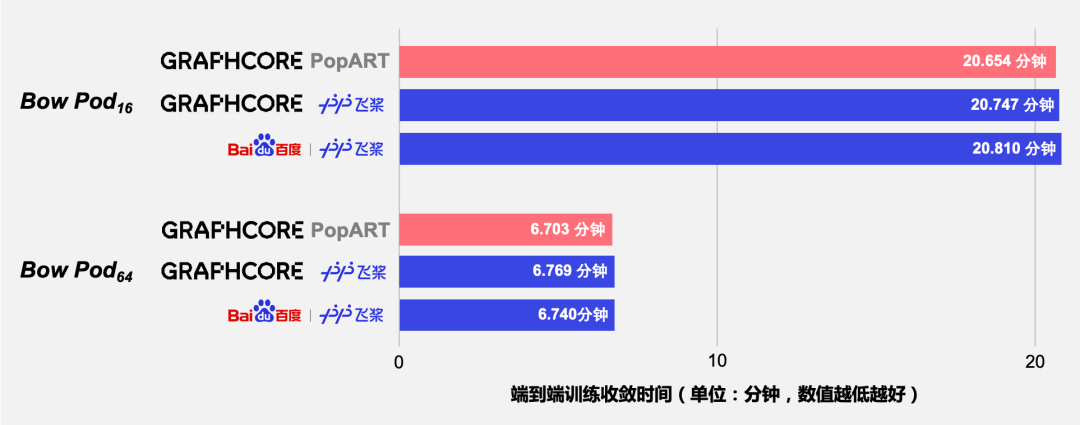
共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf
随机推荐
Unity Xiuxian mobile game | Lua dynamic sliding function (specific implementation of three source codes)
[cooking record] - stir fried 1000 pieces of green pepper
攻防世界 MISC 进阶 glance-50
剑指Offer 68 - II. 二叉树的最近公共祖先
Embedded development: skills and tricks -- seven skills to improve the quality of embedded software code
SQL中MAX与GREATEST的区别
LOGO特训营 第二节 文字与图形的搭配关系
业务太忙,真的是没时间搞自动化理由吗?
MYSQL架构——用户权限与管理
On-off and on-off of quality system construction
Introduction and application of bigfilter global transaction anti duplication component
Business is too busy. Is there really no reason to have time for automation?
记录:关于Win10系统中Microsoft Edge上的网页如何滚动截屏?
Close system call analysis - Performance Optimization
Now MySQL cdc2.1 is parsing the datetime class with a value of 0000-00-00 00:00:00
Shell script implements application service log warehousing MySQL
The Sandbox 和数字好莱坞达成合作,通过人力资源开发加速创作者经济的发展
Redis入门完整教程:HyperLogLog
High school physics: linear motion
LOGO特训营 第三节 首字母创意手法