当前位置:网站首页>MySQL查询优化与调优
MySQL查询优化与调优
2022-08-04 03:00:00 【清风拂来水波不兴】
概述
数据库调优的方式有多种:
- 建立索引、充分利用到索引、不让索引失效
- 对SQL语句进行优化
- 调优如缓冲、线程数等参数
- 数据过多时,分库分表
大方向上可以分为物理查询优化和逻辑查询优化两块。
- 物理查询优化是通过索引和表连接方式等技巧来进行优化。
- 逻辑查询优化是通过SQL等价变换提升查询效率。
数据准备:
CREATE TABLE `student_info` (
`id` int NOT NULL AUTO_INCREMENT,
`student_id` int NOT NULL,
`name` varchar(20) DEFAULT NULL,
`course_id` int NOT NULL,
`class_id` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8;CREATE TABLE `course` (
`id` int NOT NULL AUTO_INCREMENT,
`course_id` int NOT NULL,
`course_name` varchar(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8;一、关联查询优化
1.左(右)外连接
- 没有索引的情况:
mysql> explain select * from student_info s
-> left join course c
-> on s.course_id=c.course_id;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+--------------------------------------------+
| 1 | SIMPLE | c | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 996875 | 10.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+--------------------------------------------+可以看到驱动表和被驱动表都没有索引(ALL),都是全表进行扫描。
此时连接查询就相当于一个双层循环,驱动表的每一次循环都会去遍历被驱动表,消耗比较大。但查询优化器会进行优化,被驱动表的Extra字段是Using join buffer (hash join),后续会讲。
执行计划中的第一条记录是驱动表,其余的都是被驱动表
- 使用索引的情况:
create index idx_ci on course(course_id); --给被驱动表的连接条件添加索引mysql> explain select * from student_info s
-> left join course c
-> on s.course_id=c.course_id;
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+--------+----------+-------------+
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 996875 | 100.00 | Using where |
| 1 | SIMPLE | c | NULL | ref | idx_ci | idx_ci | 4 | db1.s.course_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+--------+----------+-------------+此时被驱动表的type为ref,使用到了索引,加快了被驱动表的搜索。(此例中给驱动表加索引是没有意义的,因为要全表数据)
2.内连接
内连接和外连接没有索引时是相同的,都使用join buffer加快连接速度,但是内连接的特性是主表和从表地位是相同的,位置可以改变,所以优化器会根据情况优化修改两者的位置(所以我们也可以将外连接转内连接,这样sql语句可以享受更多的优化措施)。
演示:
--创建student_info表的连接条件的索引
create index idx_ci on student_info(course_id); mysql> explain select * from student_info s
-> inner join course c
-> on s.course_id=c.course_id;
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+------+----------+-------+
| 1 | SIMPLE | c | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ref | idx_ci | idx_ci | 5 | db1.c.course_id | 9773 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+------+----------+-------+虽然主表是s,但实际执行时是c表驱动s表,因为这样可以充分使用到s的索引。
如果只有c表的连接条件有索引:
drop index idx_ci on student_info; -- 删除s表连接条件的索引
create index idx_ci on course(course_id); -- 创建c表连接条件的索引mysql> explain select * from student_info s
-> inner join course c
-> on s.course_id=c.course_id;
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+--------+----------+-------------+
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 996875 | 100.00 | Using where |
| 1 | SIMPLE | c | NULL | ref | idx_ci | idx_ci | 4 | db1.s.course_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------+---------+-----------------+--------+----------+-------------+c表如约变为了被驱动表。
如果两个表都有索引,那就是根据优化器来决定谁是驱动表,谁是被驱动表(会根据数据的多少决定,一般小表会成为驱动表)。
结论:在内连接中,如果连接字段只能有一个字段有索引,那么被驱动表有索引成本更低;如果都存在索引或都不存在,那么小数据的表作为驱动表成本更低(小表驱动大表)。
注意:外连接的驱动和被驱动表也不一定是根据SQL语句的顺序决定的,也有可能会被优化器更改。
3.JOIN语句原理
join方式连接多个表,本质就是各个表之间数据的循环匹配。MySQL5.5版本之前,MySQL只支持一种表间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则join关联的执行时间会非常长。在MySQL5.5以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
- 简单嵌套循环连接(Simple Nested-Loop Join)
从表A中取出一条数据,遍历表B,将匹配到的数据放到结果集,以此类推,驱动表A中的每一条记录与被驱动表B的记录进行判断:
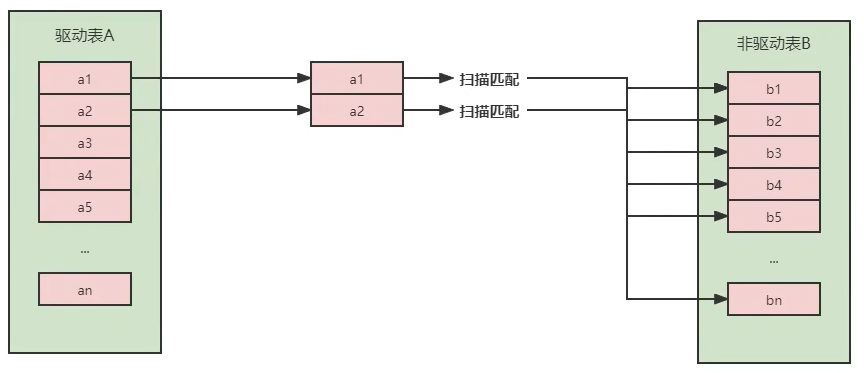
此方法性能最低,假设表A有A条数据,表B有B条数据,那么读取的记录数就为A+A*B(这也证明了为什么要小表驱动大表,因为A是驱动表,更能影响读取记录的次数)。
- 索引嵌套循环连接(Index Nested-Loop Join)
Index Nested-Loop Join其优化的思路主要是为了减少被驱动表数据的匹配次数,所以要求被驱动表上必须有索引才行。通过驱动表匹配条件直接与被驱动表索引进行匹配,避免和它的的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
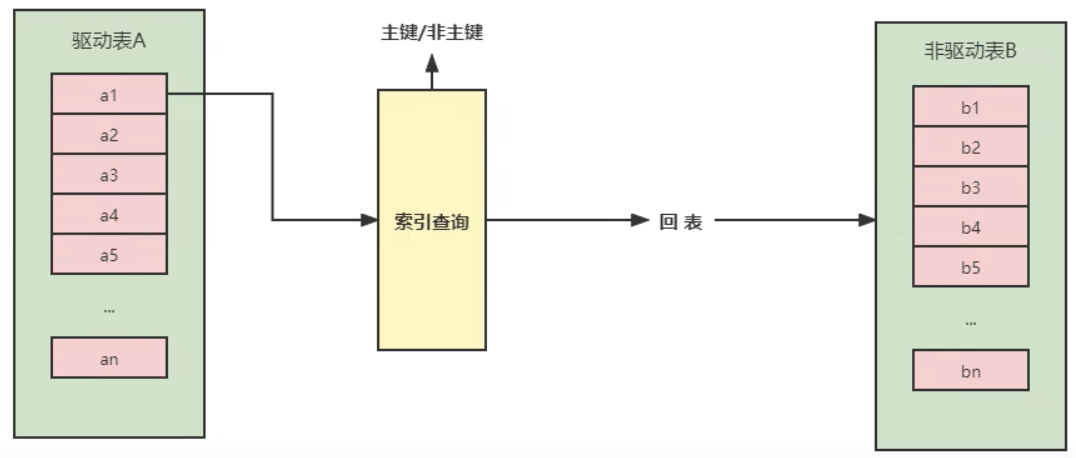
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表作为驱动表。
该方法读取的记录数为A+B(match匹配数)。
- 块嵌套循环连接(Block Nested-Loop Join)
Simple Nested-Loop Join中被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录再加载到内存匹配,这样周而复始,大大增加了IO的次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了join buffer缓冲区,将驱动表join相关的部分数据列(大小受join buffer的限制)缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
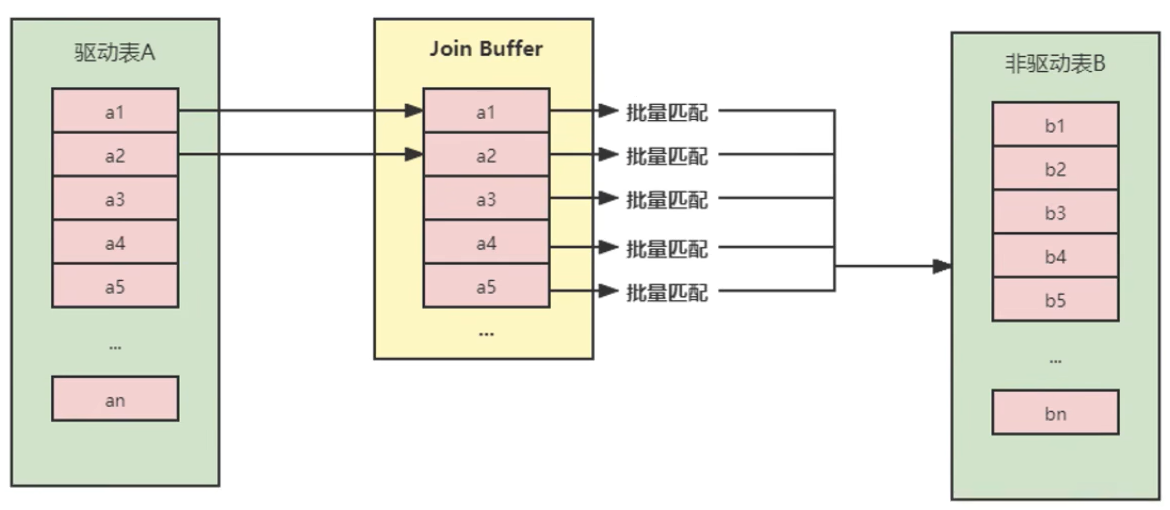
1. 通过 show variables like '%optimizer_switch%' 可以查看block_nested_loop是否开启,默认开启。
2. 驱动表能不能一次加载完,要看join buffer能不能存储所有的数据,通过show variables like '%join_buffer_size%' 查看,容量默认为256K
4.JOIN小结
- 整体效率:INLJ>BNLJ>SNLJ
- 关联查询选择小表驱动大表(度量单位:表行数*每行大小)
- 尽量给被驱动表的连接条件增加索引
- 增大join buffer size,使一次缓存的驱动表数据更多,此时被驱动表的扫描次数也就越少
- 减少驱动表不必要的字段查询,因为字段越少,join buffer所缓存的数据条数就越多
5.Hash Join
从MySQL的8.0.20版本开始将废弃BNLJ,因为从MySQL8.0.18版本开始就加入了hash join,默认都会使用hash join。
- Hash Join是做大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用Join Key在内存中建立散列表,然后扫描较大的表并探测散列表,找出与Hash表匹配的行。
- 这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。
- 在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高I/O的性能。
- 它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。Hash Join只能应用于等值连接(如WHERE A.COL1=B.COL2),这是由Hash的特点决定的。
二、子查询优化
子查询查询的效率并不高。原因是:
- 执行不相关子查询时,会创建一个临时表,临时存储子查询的结果,然后外层查询再从临时表取数据。查询完毕后还需要删除临时表,会消耗过多的IO和CPU资源。
- 子查询产生的临时表,不论是内存临时表还是磁盘临时表都不存在索引,查询效率不高。
- 综上两点,临时表越大,对查询性能的影响也越大。
如果子查询单独查询,返回的结果非常的多,那将导致效率非常低下,甚至内存可能放不下这么多的结果,对于这种情况,MySQL提出了物化表的概念,即将子查询的结果放到一张临时表(也称物化表 select-type为MATERIALIZED)中。
物化表转连接
物化表也是一张表,有了物化表后,可以考虑将原本的表和物化表建立连接查询,针对如下的SQL:
select * from t1 where key1 in (select m1 from s2 where key2 = 'a')如果t1表中的key1在物化表中的m1里存在,则加入结果集,对物化表说,如果m1在t1表中的key1里存在,则加入结果集,此时可以将子查询转化为内连接查询,转成连接查询后,就可以享受很多优化措施。
半连接(semi-join)
通过物化表可以将子查询转换为连接查询,MySQL在物化表的基础上做了更进一步的优化,即不建立临时表,直接将子查询转为连接查询。
上面的SQL优化后与下面的SQL较为相似:
select t1.* from t1 inner join s2 on t1.key1 = s2.m1 where s2.key2 = 'a'这么一看好像满足可以转换的趋势,不过需要考虑三种情况:
- 对于t1表,s2结果集中如果没有满足on条件的,不加入结果集
- 对于t1表,s2结果集中有且只有一条符合条件的,加入结果集
- 对于t1表,s2结果集中有多条符合条件的,那么该记录将多次加入结果集
对于情况1、2的内连接,都是符合上面子查询的要求的,但是结果3,在子查询中只会出现一条记录,但是连接查询中将会出现多条,因此二者又不能完全等价,但是连接查询的效果又非常好,因此MySQL推出了半连接(semi-join)的概念。
对于t1表,只关心s1表中有没有符合条件的记录,而不关心有多少条记录与之匹配,最终的结果集只保留t1表中的就行了,因此MySQL内部的半连接语法类似是这么写的:
select t1.* from t1 semi join s2 on t1.key1 = s2.m1 where s2.key2 = 'a'
--(这不能直接执行,半连接只是一种概念,不开放给用户使用)补充:尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代
三、排序优化
在MySQL中支持两种排序方式:
- FileSort:对数据进行排序,内部或外部排序,占用CPU较多,效率低
- Index:索引就保证了有序性,不需要再进行排序,效率高
优化建议:
- 可以在ORDER BY子句中使用索引,目的是在ORDER BY子句避免使用FileSort排序。
- 尽量使用Index完成ORDER BY排序。如果WHERE和ORDER BY后面是相同的列就使用单索引列;如果不同就使用联合索引。
- 无法使用Index时,需要对FileSort方式进行调优。
案例:
- 情况一:排序字段没有索引时
mysql> explain select * from student_info order by class_id;
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | student_info | NULL | ALL | NULL | NULL | NULL | NULL | 996875 | 100.00 | Using filesort |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+----------------+使用了filesort手动排序,效率不高。
- 情况二:排序字段有索引,但order by时不limit
create index idx_cls on student_info(class_id); --创建索引mysql> explain select * from student_info order by class_id;
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | student_info | NULL | ALL | NULL | NULL | NULL | NULL | 996875 | 100.00 | Using filesort |
+----+-------------+--------------+------------+------+---------------+------+---------+------+--------+----------+----------------+依然使用的是filesort,为啥呢?
这是因为如果使用索引排序的话,那么它是二级索引,虽然已经将class_id字段排序好了,但是,因为查询的字段是*,所以还需要疯狂回表,又因为数据量较多(回表操作太多),所以有些情况下还不如直接在聚簇索引的基础上去排序所有数据。
如果select *改为select class_id,id,排序方式就为index,使用了索引覆盖。
- 情况三:排序字段有索引,order by时使用limit
mysql> explain select * from student_info order by class_id limit 200;
+----+-------------+--------------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | student_info | NULL | index | NULL | idx_cls | 5 | NULL | 200 | 100.00 | NULL |
+----+-------------+--------------+------------+-------+---------------+---------+---------+------+------+----------+-------+加上limit后就使用到了索引,因为优化器认为limit过后数据量较小,回表操作次数也少,就直接使用二级索引排序好的数据了。
如果limit后的数据过大,照样会使用filesort排序
- 情况四:联合索引中order by规则不一致
-- 创建联合索引
create index idx_cls_cou on student_info(class_id desc,course_id);
有多种情况:
-- 索引失效的情况,filesort
explain select * from student_info order by class_id desc,course_id desc limit 20;
explain select * from student_info order by class_id,course_id limit 20;
-- 使用索引的情况,index
explain select * from student_info order by class_id desc,course_id limit 20;
explain select * from student_info order by class_id ,course_id desc limit 20;
- 情况五:无过滤,不索引
-- 创建联合索引
create index idx_cls_cou on student_info(class_id,course_id);
-- where过滤使用到了class_id索引
explain select * from student_info where class_id=2 order by course_id;
-- 未使用索引
explain select * from student_info where course_id=2 order by class_id;
-- 使用了索引,使用索引排序
explain select * from student_info where course_id=2 order by class_id limit 20;小结:
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
不能使用索引进行排序
- ORDER BY a ASC,b DESC,c DESC /* 排序不一致 */
- WHERE g = const ORDER BY b,c /*丢失a索引*/
- WHERE a = const ORDER BY c /*丢失b索引*/
- WHERE a = const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/补充:filesort算法分为双路排序和单路排序。
双路排序需要加载两次数据(类似回表),单路排序只需要一次(在sort buffer中排序),效率更高,但对内存的要求也更高。
优化策略:
1.尝试提高 sort_buffer_size
2.尝试提高 max_length_for_sort_data
3.order by时select需要用到的参数,防止数据超过sort buffer,从而增加额外的操作
四、GROUP BY优化
- group by使用索引的原则几乎跟order by一致,group by也可以使用索引。
- group by是先排序再分组,遵照索引建的最佳左前缀法则
- 当无法使用索引时,可增大max_length_for_sort_data和sort_buffer_size参数的设置进行优化
- where效率高于having,能写在where限定的条件就不要写在having中了
- 减少使用order by,可将排序放到程序端去做。Order by、group by、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果应该比较少,否则SQL会很慢。
五、优先考虑覆盖索引
什么是覆盖索引?二级索引能快速找到一个列的数据,但是还需要额外的做一次回表操作,去主键索引查找真正的行数据,但如果要查找列的数据在二级索引中都能找到,那么它不必回表去读取整个行。
一个二级索引包含了满足查询结果的数据就叫做覆盖索引(常用在联合索引中)。 简单说就是, 索引列+主键包含SELECT需要查找的所有的列。
即使有些查询看似使用不到索引,但是优化器有些时候会使用到覆盖索引进行优化。因为InnoDB中非聚簇索引查找比聚簇索引消耗更低。(一页存储的数据更多,避免加载多页)
六、使用前缀索引
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
七、索引下推ICP
即回表前再去过滤一些数据,尽可能让需要回表的数据变得更少。如下
create index idx_cls on student_info(class_id);
explain select * from student_info where class_id>10192 and course_id=10038- 如果没有索引下推:
mysql使用索引去查找class_id大于10192的数据,然后逐一回表,将所有的这些数据保存起来,然后再根据couse_id找出最后的结果。
- 如果使用索引下推:
mysql使用索引去查找class_id大于10192的数据,此时不立马回表,继续执行and后面的条件,把结果进一步压缩,再去回表得到最终结果。这样,回表的次数将会大大减小。
ICP默认是开启的,可以使用系统参数optimizer_switch来控制器是否开启。
-- 修改默认值
set ="index_condition_pushdown=off";
set ="index_condition_pushdown=on";ICP的使用条件:
- 只能用于二级索引
- explain显示的执行计划中type值(join 类型)为range、ref、eq_ref或者ref_or_null。
- 并非全部where条件都可以用ICP筛选,如果where条件的字段不在索引列中,还是要读取整表的记录到server端做where过滤。
- ICP可以用于MyISAM和InnnoDB存储引擎
- 当SQL使用覆盖索引时,不支持ICP优化方法。
八、其他查询优化
1.COUNT(*)与COUNT(具体字段)效率
在MySQL中统计数据表的行数,可以使用三种方式:SELECT COUNT(*) 、SELECT COUNT(1)和SELECT COUNT(具体字段),使用这三者之间的查询效率是怎样的?
如果是MyISM存储引擎,那么都是O(1)的复杂度,因为它维持了row_count记录行数值。
如果是InnoDB存储引擎,需要扫描全表,如果采用COUNT(具体字段)来统计数据行数,要尽量采用二级索引。因为主键采用的索引是聚簇索引,聚簇索引包含的信息多,明显会大于二级索引(非聚簇索引)。对于COUNT(*)和COUNT(1)来说,它们不需要查找具体的行,只是统计行数,系统会自动采用占用空间更小的二级索引来进行统计。
如果有多个二级索引,会使用key_len小的二级索引进行扫描。当没有二级索引的时候,才会采用主键索引来进行统计。
2.不使用SELECT *
应该是有SELECT 具体字段,因为:
- 无法使用覆盖索引
- MySQL在解析的过程中,会通过查询数据字典将"*"按序转换成所有列名,这会大大的耗费资源和时间。
- 关联查询时join buffer能存的记录数变少
3.LIMIT 1优化
针对的是会扫描全表的SQL语句,如果你可以确定结果集只有一条,那么加上LIMIT 1的时候,当找到一条结果的时候就不会继续扫描了,这样会加快查询速度。
如果数据表已经对字段建立了唯一索引,那么可以通过索引进行查询,不会全表扫描的话,就不需要加上LIMIT 1了。
4.多使用commit
只要有可能,在程序中尽量多使用COMMIT,这样程序的性能得到提高,COMMIT会释放多种资源:
- 回滚段上用于恢复数据的信息
- 被程序语句获得的锁
- redo / undo log buffer中的空间
- 管理上述3种资源中的内部花费
边栏推荐
猜你喜欢
Taurus.MVC WebAPI 入门开发教程1:框架下载环境配置与运行(含系列目录)。
DHCP服务详解

There are n steps in total, and you can go up to 1 or 2 steps each time. How many ways are there?
pytorch applied to MNIST handwritten font recognition

STM8S105k4t6c--------------点亮LED

Security First: Tools You Need to Know to Implement DevSecOps Best Practices
复制带随机指针的链表
一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
Development of Taurus. MVC WebAPI introductory tutorial 1: download environment configuration and operation framework (including series directory).
Parquet encoding
随机推荐
Architecture of the actual combat camp module three operations
MallBook联合人民交通出版社,推动驾培领域新发展,开启驾培智慧交易新生态
Brush esp8266-01 s firmware steps
APP电商如何快速分润分账?
怎样提高网络数据安全性
Sfdp 超级表单开发平台 V6.0.5 正式发布
uni-app 从零开始-基础模版(一)
Development of Taurus. MVC WebAPI introductory tutorial 1: download environment configuration and operation framework (including series directory).
【翻译】Terraform和Kubernetes的交集
2022G1工业锅炉司炉考试练习题及模拟考试
【项目实现】Boost搜索引擎
Homemade bluetooth mobile app to control stm8/stm32/C51 onboard LED
Security First: Tools You Need to Know to Implement DevSecOps Best Practices
sudo 权限控制,简易
【学习笔记之菜Dog学C】动态内存管理
数据安全峰会2022 | 美创DSM获颁“数据安全产品能力验证计划”评测证书
说说数据治理中常见的20个问题
STM8S project creation (STVD creation) --- use COSMIC to create a C language project
Utilities of Ruineng Micrometer Chip RN2026
数据湖(二十):Flink兼容Iceberg目前不足和Iceberg与Hudi对比