当前位置:网站首页>Tiflash compiler oriented automatic vectorization acceleration
Tiflash compiler oriented automatic vectorization acceleration
2022-07-05 14:04:00 【Tidb community dry goods portal】
The source of the original :https://tidb.net/blog/1886d9cd
author : Zhuyifan
Catalog
- SIMD Introduce
<!---->
- SIMD Function dispatch scheme
<!---->
- Compiler oriented optimization
SIMD Introduce
SIMD Is an important means of program acceleration .CMU DB Group in Advanced Database Systems There are two special chapters in (vectorization-1, vectorization-2) Introduce SIMD The application of Vectorization in database , It can be seen that it is of great importance to modern database systems . This article briefly introduces some in TiFlash Introduction to using the compiler for automatic vectorization in .
TiFlash Currently supported architectures are x86-64 and Aarch64, The operating system platform has Linux and MacOS. Subject to the platform ISA And operating systems API, Do... In different environments SIMD Support has different problems .
X86-64
We traditionally put x86-64 The platform is divided into 4 individual Level:
- x86-64: CMOV, CMPXCHG8B, FPU, FXSR, MMX, FXSR, SCE, SSE, SSE2
<!---->
- x86-64-v2: (close to Nehalem) CMPXCHG16B, LAHF-SAHF, POPCNT, SSE3, SSE4.1, SSE4.2, SSSE3
<!---->
- x86-64-v3: (close to Haswell) AVX, AVX2, BMI1, BMI2, F16C, FMA, LZCNT, MOVBE, XSAVE
<!---->
- x86-64-v4: AVX512F, AVX512BW, AVX512CD, AVX512DQ, AVX512VL
There are different extensions at each level . The status quo is TiFlash stay x86-64 The goal of compiling on is x86-64-v2, At present, the vast majority of home and server CPU Have support x86-64-v3. because Intel At present, we are facing the update of large and small core architectures ,x86-64-v4 Support for is relatively chaotic , But on the server side , The newer models have different degrees of AVX512 Support . stay AWS Support matrix of We can see the support of the third generation Zhiqiang expandable processor in AVX512 The model of has been adopted in the production environment .
x86-64 It's different CPU The overhead of the same extended instruction set before the architecture is also different , Generally speaking , Can be in Intel Intrinsic Guide To briefly view the related instructions on different microarchitectures CPI Information . If you want to optimize for a specific platform , You can read platform related Tuning Guides and Performance Analysis Papers ,INTEL ADVANCED VECTOR EXTENSIONS as well as Intel 64 and IA-32 Architectures Software Developer Manuals (Software Optimization Reference Manual series ) To obtain a Intel Official advice .
How to choose SSE,AVX/AVX2,AVX512? In fact, it is not that the technology is more and more new , The larger the bit width , The effect must be better . Such as , stay INTEL ADVANCED VECTOR EXTENSIONS Of 2.8 Chapter we can see , Mix tradition SSE and AVX Command assembly leads to what is called SSE-AVX Transition Penalty:
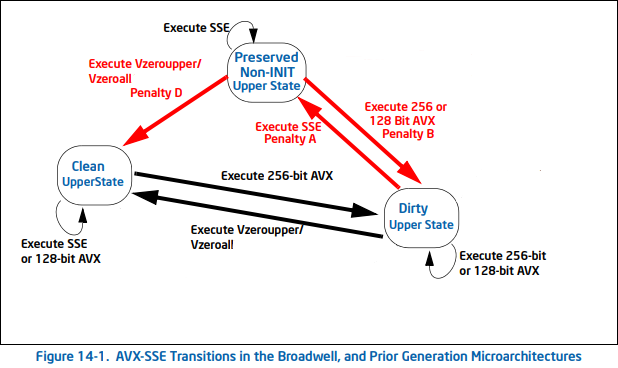
On the other hand ,AVX2,AVX512 There are corresponding Frequency Scaling problem .Cloudflare The article On the dangers of Intel's frequency scaling as well as Gathering Intel on Intel AVX-512 Transitions There is an analysis of this problem . Briefly ,AVX-512 Improve performance in intensive computing , here CPU The frequency drops , However, vectorization itself greatly improves the speed . however , If it is mixed in non dense scenes AVX512 And general instructions , We can imagine the loss of overall performance caused by frequency reduction .
stay Intel On the platform ,SIMD The instruction set corresponds to XMM,YMM,ZMM And so on , We can use gdb Of disassmble Command to see the result of vectorization :
#!/usr/bin/env bashargs=(-batch -ex "file $1")while IFS= read -r line; do args+=("-ex" "disassemble '$line'")done < <(nm --demangle $1 | grep $2 | cut -d\ -f3-)gdb "${args[@]}" | c++filt# bash ./this-script.sh tiflash xxx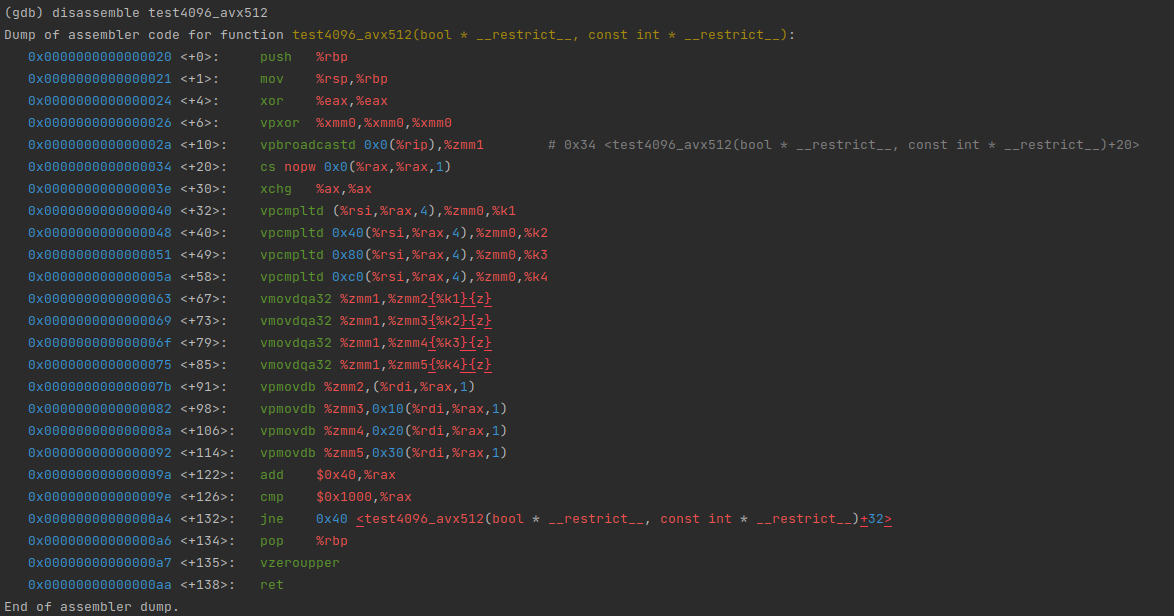
Aarch64
stay Arm There is also a problem of uneven platform vectorization instruction set support in the world .Arm V8 At present, it has been refined into 8 A version :

stay SIMD aspect ,Aarch64 There are mainly two or three instruction sets ASIMD,SVE,SVE2.ASIMD Has been widely used , in fact , GCC/Clang It will open by default ASIMD Support . stay Arm V8 in ,SVE Generally not in A Profile To realize , But for HPC Etc CPU in . stay Arm V9 in ,SVE,SVE2 It has become the standard extended instruction set .
ASIMD It describes the fixed length vectorization operation , Act on 64bit and 128bit The register of , Functionally and SSE The series is close to .SVE Is to use a variable length vector ,Vendor Can provide up to 2048bit Super wide register of . Use Per-Lane Prediction The plan ,SVE The instruction set establishes a programming model without knowing the actual register width .

in application ,AWS C7g ( be based on AWS Graviton3) Has begun to support SVE Instruction set , Up to 256bit Width . and ASIMD In Kunpeng ,AWS Graviton2 etc. CPU Has a good implementation on the instances of .
stay AARCH64 On , common ASIMD The associated register is q0-q15, Sometimes they also take the form of v0-v15 The suffixed form appears in ASM in .SVE And so on z0-z15.

SIMD Function dispatch scheme
TiFlash Of CD Pipeline For each OS/Arch Combine to generate a unified binary package for publishing , Therefore, the goal of overall compilation is a relatively general architecture . and SIMD Instruction sets differ from platform to platform , So we need some scheme to distribute the vectorized function . The following two categories of solutions are provided , Runtime and load time . As a whole , You can refer to the following conditions to select :
- If you want to support non Linux The goal is , And it is known that the operation itself takes relatively more time , Don't care about oneortwo more branch, You can use runtime dispatch . under these circumstances ,TiFlash There is a runtime switch that provides the corresponding vectorization scheme , More controllable functions .
<!---->
- If the operation is used in an extremely large number , And branch May affect performance , Priority can be given to load time distribution .TiFlash Basically used in production environments Linux, So you can just MacOS Provides the default version of the function .
Run time dispatch
This scheme is relatively simple , stay common/detect_features.h in ,TiFlash Provides specific information for inspection CPU A better solution , We can write a runtime check function , Then determine the function entry of the specific implementation scheme . This scheme is applicable to the known vectorization operation which takes a long time , Compared with the situation where the distribution cost can be ignored .
Look at the following code :
__attribute__((target("avx512f"))) void test4096_avx512(bool * __restrict a, const int * __restrict b){ for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; }}__attribute__((target("avx2"))) void test4096_avx2(bool * __restrict a, const int * __restrict b){ for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; }}__attribute__((noinline)) void test4096_generic(bool * __restrict a, const int * __restrict b){ for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; }}void test4096(bool * __restrict a, const int * __restrict b){ if (common::cpu_feature_flags.avx512f) { return test4096_avx512(a, b); } if (common::cpu_feature_flags.avx2) { return test4096_avx2(a, b); } return test4096_generic(a, b);}You can see , Function entry is the detection function , Implementation of call corresponding platform :
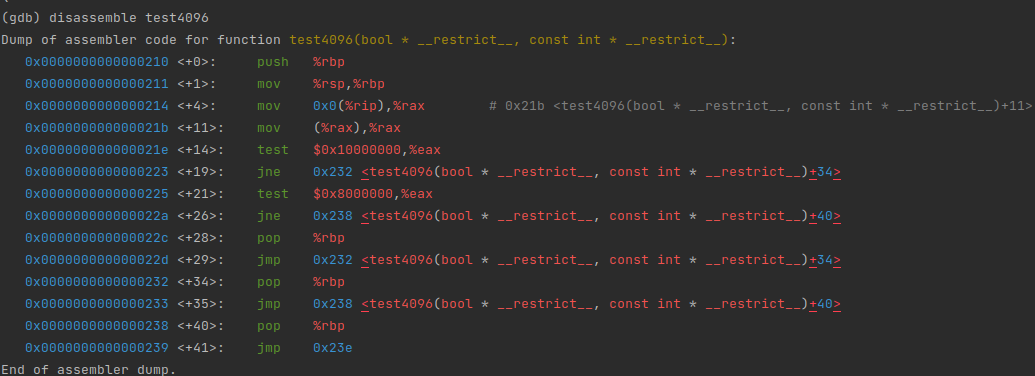
The specific function has the vectorization optimization of the corresponding platform
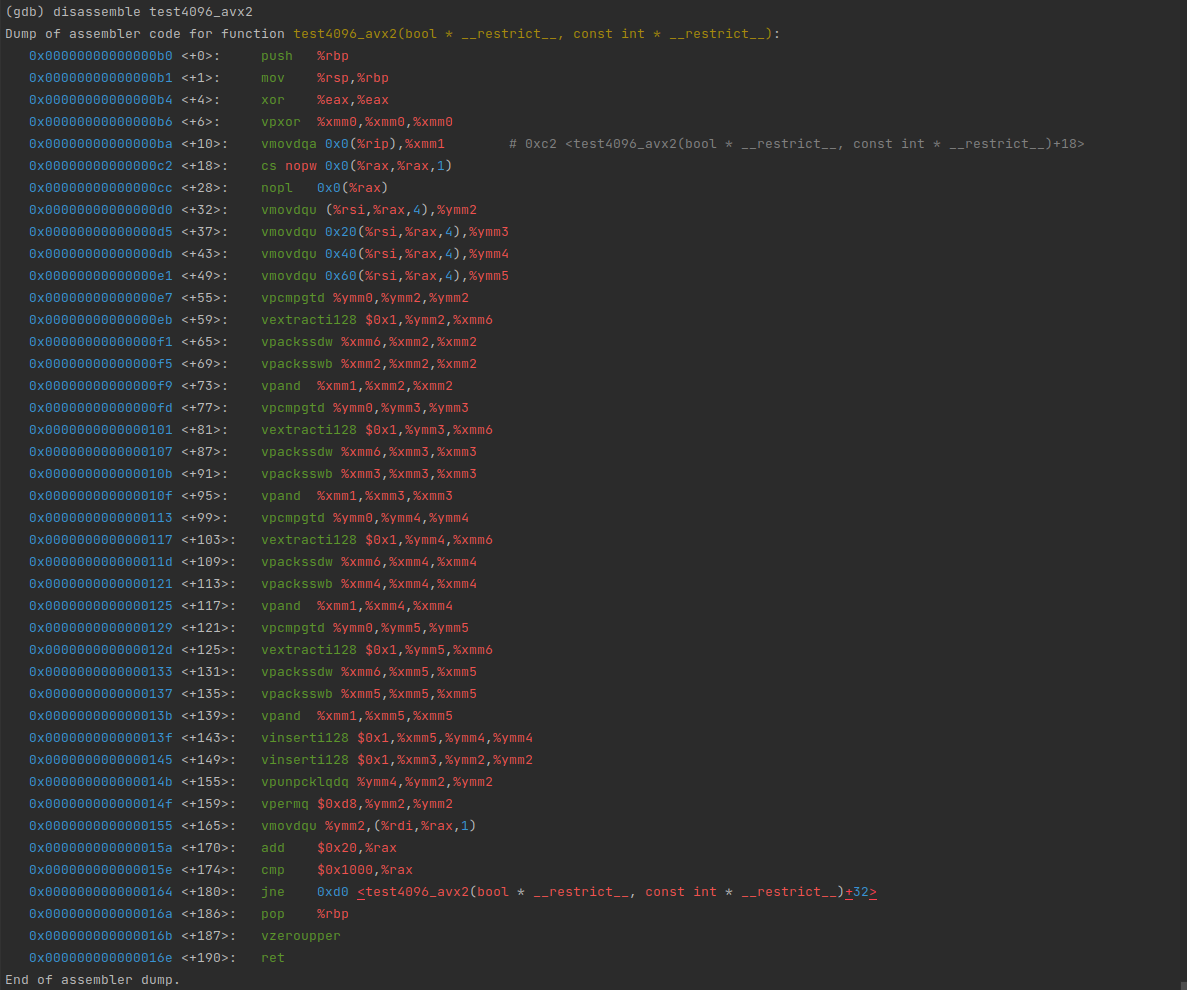
actually , For the distribution of this same function body ,TiFlash Packaged... Has been provided macro, The above code can be written as
#include <Common/TargetSpecific.h>TIFLASH_DECLARE_MULTITARGET_FUNCTION( /* return type */ void, /* function name */ test4096, /* argument names */ (a, b), /* argument list */ (bool * __restrict a, const int * __restrict b), /* body */ { for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; } })IFUNC distributed
stay Linux Upper observation Glibc The symbol table of :
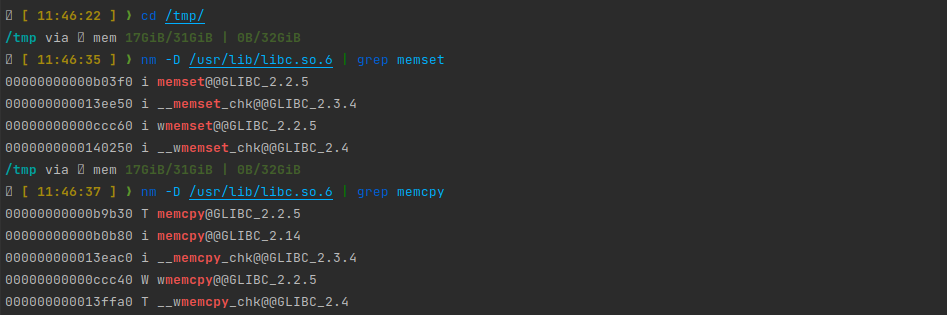
We can see , Some performance critical functions are marked before i Symbol . This means that these functions are indirect function : That is, the program can provide multiple implementations of a function , Then, in the program loading link phase, the ld Decide which implementation the target symbol is specifically linked to .Glibc It is this scheme that is used to determine some key functions such as memcpy/memcmp/memset Such as the implementation of the .
test4096 Can rewrite :
void test4096(bool * __restrict a, const int * __restrict b) __attribute__((ifunc("test4096_resolver")));extern "C" void * test4096_resolver(){ if (__builtin_cpu_supports("avx512f")) return reinterpret_cast<void *>(&test4096_avx512); if (__builtin_cpu_supports("avx2")) return reinterpret_cast<void *>(&test4096_avx2); return reinterpret_cast<void *>(&test4096_generic);}This scheme reduces the overhead of runtime dispatch , But there are some limitations :
- Only applicable to GNU/Linux platform
<!---->
- ifunc Of resolver It has to be in the current unit Inside . If resolver yes c++ Function of , Need to provide mangle The name after .
<!---->
resolver Execute on entering C Runtime sum C++ Before runtime , Out-of-service TiFlash Detection function of . stay
x86_64platform , have access to__builtin_cpu_supports; stayaarch64On , You can use the following scheme :#include <sys/auxv.h>#ifndef HWCAP2_SVE2#define HWCAP2_SVE2 (1 << 1)#endif#ifndef HWCAP_SVE#define HWCAP_SVE (1 << 22)#endif#ifndef AT_HWCAP2#define AT_HWCAP2 26#endif#ifndef AT_HWCAP#define AT_HWCAP 16#endifnamespace detail{static inline bool sve2_supported(){ auto hwcaps = getauxval(AT_HWCAP2); return (hwcaps & HWCAP2_SVE2) != 0;}static inline bool sve_supported(){ auto hwcaps = getauxval(AT_HWCAP); return (hwcaps & HWCAP_SVE) != 0;}} // namespace detailAnother interesting example is , If you need in resolver Read function variables in , You may need to manually initialize environ The pointer :
extern char** environ;extern char **_dl_argv;char** get_environ() { int argc = *(int*)(_dl_argv - 1); char **my_environ = (char**)(_dl_argv + argc + 1); return my_environ;}typeof(f1) * resolve_f() { environ = get_environ(); const char *var = getenv("TOTO"); if (var && strcmp(var, "ok") == 0) { return f2; } return f1;}int f() __attribute__((ifunc("resolve_f")));
Function Multiversioning distributed
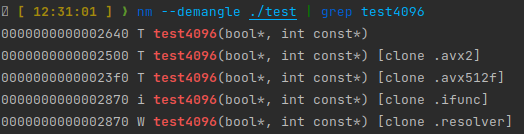
stay x86-64 On ,Clang/GCC It actually provides a more convenient IFUNC Implementation scheme :
#include <iostream>__attribute__((target("avx512f"))) void test4096(bool * __restrict a, const int * __restrict b){ std::cout << "using avx512" << std::endl; for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; }}__attribute__((target("avx2"))) void test4096(bool * __restrict a, const int * __restrict b){ std::cout << "using avx2" << std::endl; for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; }}__attribute__((target("default"))) void test4096(bool * __restrict a, const int * __restrict b){ std::cout << "using default" << std::endl; for (int i = 0; i < 4096; ++i) { a[i] = b[i] > 0; }}int main() { bool results[4096]; int data[4096]; for (auto & i : data) { std::cin >> i; } test4096(results, data); for (const auto & i : results) { std::cout << i << std::endl; }}here , We don't have to distinguish between function names and providing resolver, Instead, they directly mark different target, The compiler generates it automatically ifunc The implementation of the .
Macro Integrate
You can use the following code to integrate x86-64 and aarch64 Based on IFUNC The plan :
#ifdef __linux__#include <sys/auxv.h>#ifndef HWCAP2_SVE2#define HWCAP2_SVE2 (1 << 1)#endif#ifndef HWCAP_SVE#define HWCAP_SVE (1 << 22)#endif#ifndef AT_HWCAP2#define AT_HWCAP2 26#endif#ifndef AT_HWCAP#define AT_HWCAP 16#endifnamespace detail{static inline bool sve2_supported(){ auto hwcaps = getauxval(AT_HWCAP2); return (hwcaps & HWCAP2_SVE2) != 0;}static inline bool sve_supported(){ auto hwcaps = getauxval(AT_HWCAP); return (hwcaps & HWCAP_SVE) != 0;}} // namespace detail#endif#define TMV_STRINGIFY_IMPL(X) #X#define TMV_STRINGIFY(X) TMV_STRINGIFY_IMPL(X)#define TIFLASH_MULTIVERSIONED_VECTORIZATION_X86_64(RETURN, NAME, ARG_LIST, ARG_NAMES, BODY) \ struct NAME##TiFlashMultiVersion \ { \ __attribute__((always_inline)) static inline RETURN inlined_implementation ARG_LIST BODY; \ \ __attribute__((target("default"))) static RETURN dispatched_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ __attribute__((target("avx"))) static RETURN dispatched_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ __attribute__((target("avx2"))) static RETURN dispatched_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ __attribute__((target("avx512f,avx512vl,avx512bw,avx512cd"))) static RETURN dispatched_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ __attribute__((always_inline)) static inline RETURN invoke ARG_LIST \ { \ return dispatched_implementation ARG_NAMES; \ }; \ };#define TIFLASH_MULTIVERSIONED_VECTORIZATION_AARCH64(RETURN, NAME, ARG_LIST, ARG_NAMES, BODY) \ struct NAME##TiFlashMultiVersion \ { \ __attribute__((always_inline)) static inline RETURN inlined_implementation ARG_LIST BODY; \ \ static RETURN generic_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ __attribute__((target("sve"))) static RETURN sve_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ __attribute__((target("sve2"))) static RETURN sve2_implementation ARG_LIST \ { \ return inlined_implementation ARG_NAMES; \ }; \ \ static RETURN dispatched_implementation ARG_LIST \ __attribute__((ifunc(TMV_STRINGIFY(__tiflash_mvec_##NAME##_resolver)))); \ \ __attribute__((always_inline)) static inline RETURN invoke ARG_LIST \ { \ return dispatched_implementation ARG_NAMES; \ }; \ }; \ extern "C" void * __tiflash_mvec_##NAME##_resolver() \ { \ if (::detail::sve_supported()) \ { \ return reinterpret_cast<void *>(&NAME##TiFlashMultiVersion::sve_implementation); \ } \ if (::detail::sve2_supported()) \ { \ return reinterpret_cast<void *>(&NAME##TiFlashMultiVersion::sve2_implementation); \ } \ return reinterpret_cast<void *>(&NAME##TiFlashMultiVersion::generic_implementation); \ }#if defined(__linux__) && defined(__aarch64__)#define TIFLASH_MULTIVERSIONED_VECTORIZATION TIFLASH_MULTIVERSIONED_VECTORIZATION_AARCH64#elif defined(__linux__) && defined(__x86_64__)#define TIFLASH_MULTIVERSIONED_VECTORIZATION TIFLASH_MULTIVERSIONED_VECTORIZATION_X86_64#else#define TIFLASH_MULTIVERSIONED_VECTORIZATION(RETURN, NAME, ARG_LIST, ARG_NAMES, BODY) \ struct NAME##TiFlashMultiVersion \ { \ __attribute__((always_inline)) static inline RETURN invoke ARG_LIST BODY; \ };#endifTIFLASH_MULTIVERSIONED_VECTORIZATION( int, sum, (const int * __restrict a, int size), (a, size), { int sum = 0; for (int i = 0; i < size; ++i) { sum += a[i]; } return sum; })Compiler oriented optimization
LLVM It provides a good automatic vectorization guide : Auto-Vectorization in LLVM - LLVM 15.0.0git documentation
You can refer to the chapters to learn which common patterns can be used for vectorization . Simply speaking , We can think about the scenario of a cycle : Can you simplify unnecessary control flow , Can you reduce opaque function calls and so on . besides , You can also consider , For some simple function definitions , If it gets a lot of continuous calls , Can we define a function in header in , Let the compiler see and inline these functions , And then improve the space of vectorization .
Gartner said ,premature optimization is the root of all evil( Premature optimization is the source of all evils ). There is no need to rewrite some non performance critical loops into vectorization friendly forms for vectorization . combination profiler It is a good choice to further optimize those functions .
Check the vectorization condition
We use the following parameters to check the vectorization process :
-Rpass-missed='.*vectorize.*'Check why the compiler did not successfully vectorize
<!---->
-Rpass='.*vectorize.*'Check the compiler for those vectorizations
In particular , stay TiFlash, Let's first extract a object file Compile instruction
cat compile_commands.json | grep "/VersionFilterBlockInputStream.cpp" then , Add... Before compiling the directive -Rpass-missed='.*vectorize.*' perhaps -Rpass='.*vectorize.*' To see the information .


Loop unrolling Pragma
following pragma It can be used to control the loop expansion strategy , Auxiliary vectorization
void test1(int * a, int *b, int *c) { #pragma clang loop unroll(full) for(int i = 0; i < 1024; ++i) { c[i] = a[i] + b[i]; }}void test2(int * a, int *b, int *c) { #pragma clang loop unroll(enable) for(int i = 0; i < 1024; ++i) { c[i] = a[i] + b[i]; }}void test3(int * a, int *b, int *c) { #pragma clang loop unroll(disable) for(int i = 0; i < 1024; ++i) { c[i] = a[i] + b[i]; }}void test4(int * a, int *b, int *c) { #pragma clang loop unroll_count(2) for(int i = 0; i < 1024; ++i) { c[i] = a[i] + b[i]; }}To quantify Pragma
following pragma You can suggest clang To quantify .
static constexpr int N = 4096;int A[N];int B[N];struct H { double a[4]; H operator*(const H& that) { return { a[0] * that.a[0], a[1] * that.a[1], a[2] * that.a[2], a[3] * that.a[3], }; }};H C[N];H D[N];H E[N];void test1() { #pragma clang loop vectorize(enable) for (int i=0; i < N; i++) { C[i] = D[i] * E[i]; }}void test2() { for (int i=0; i < N; i++) { C[i] = D[i] * E[i]; }}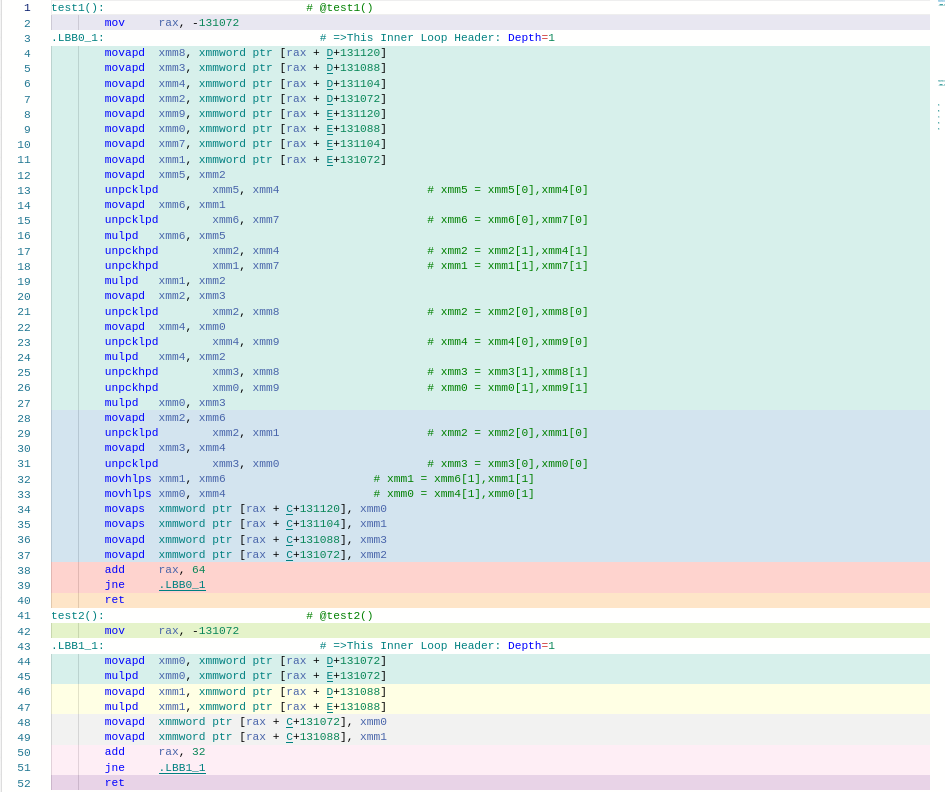
in fact , stay Aarch64 On ,TiFlash in getDelta By default, there is no vectorization , While using hint Then you can .
these pragma If you want to macro For internal use , It can be changed to _Pragma("clang loop vectorize(enable)") In the form of .
Loop split
Reuse the example above
void x() { #pragma clang loop vectorize(enable) for (int i=0; i < N; i++) { A[i + 1] = A[i] + B[i]; C[i] = D[i] * E[i]; }}void y() { for (int i=0; i < N; i++) { A[i + 1] = A[i] + B[i]; } #pragma clang loop vectorize(enable) for (int i=0; i < N; i++) { C[i] = D[i] * E[i]; }} among x Functions are not vectorized , because A There are data dependencies in .y Split two loop after , After a loop Then vectorization can be performed . In practice , If C[i] = D[i] * E[i] The scalar operation of is relatively time consuming , It makes sense to do this .
Theoretically
#pragma clang loop distribution(enable)The corresponding situation can be handled automatically , But even if you use this pragma,clang Still relatively conservative .
Control vectorization strategy
Resize the unit vector
void test(char *x, char *y, char * z) { #pragma clang loop vectorize_width(8) for (int i=0; i < 4096; i++) { x[i] = y[i] * z[i]; }}For example Aarch64 On ,vectorize_width(1) It means that there is no vectorization ,vectorize_width(8) It means using 64bit register ,vectorize_width(16) It means using 128bit register .
besides , You can also use vectorize_width(fixed) , vectorize_width(scalable) Adjust the orientation of fixed length and variable length vectors .
Adjust the vectorized batch size
It can be used interleave_count(4) Suggest to the compiler the loop batch expanded during vectorization . Increasing the batch size within a certain range can promote the processor to accelerate with superscalar and out of order execution .
void test(char *x, char *y, char * z) { #pragma clang loop vectorize_width(8) interleave_count(4) for (int i=0; i < 4096; i++) { x[i] = y[i] * z[i]; }}Extract the fixed length cycle unit
The following function is used to confirm the first visible column in the database inventory :
const uint64_t* filterRow( const uint64_t* data, size_t length, uint64_t current_version) { for(size_t i = 0; i < length; ++i) { if (data[i] > current_version) { return data + i; } } return nullptr;}It cannot be vectorized , Because there is an outward jump control flow inside the loop .
In this case , You can manually extract a loop to help the compiler do automatic vectorization :
const uint64_t* filterRow( const uint64_t* data, size_t length, uint64_t current_version) { size_t i = 0; for(; i + 64 < length; i += 64) { uint64_t mask = 0; #pragma clang loop vectorize(enable) for (size_t j = 0; j < 64; ++j) { mask |= data[i + j] > current_version ? (1ull << j) : 0; } if (mask) { return data + i + __builtin_ctzll(mask); } } for(; i < length; ++i) { if (data[i] > current_version) { return data + i; } } return nullptr;}(__builtin_ctzll Is used to calculate the end of an integer 0 The number of compiler built-in functions , Generally, it can be translated into an instruction efficiently )
边栏推荐
- Kotlin collaboration uses coroutinecontext to implement the retry logic after a network request fails
- matlab学习2022.7.4
- 牛客网:拦截导弹
- 链表(简单)
- 如何将 DevSecOps 引入企业?
- 常见问题之PHP——Fatal error: Allowed memory size of 314572800 bytes exhausted...
- 汇编语言 assembly language
- In addition to the root directory, other routes of laravel + xampp are 404 solutions
- Zhubo Huangyu: it's really bad not to understand these gold frying skills
- 让秒杀狂欢更从容:大促背后的数据库(下篇)
猜你喜欢
如何将 DevSecOps 引入企业?
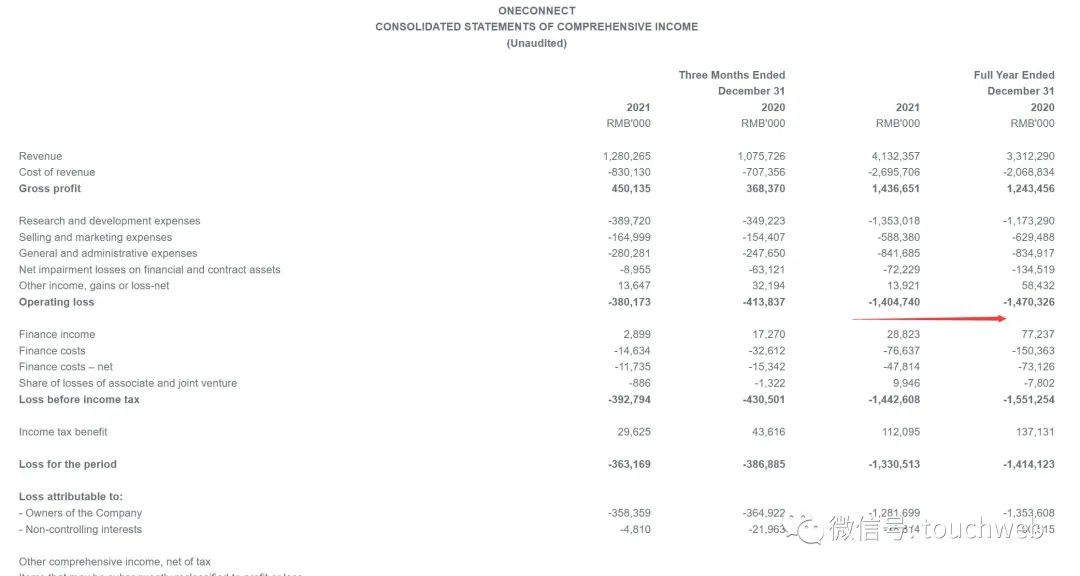
Financial one account Hong Kong listed: market value of 6.3 billion HK $Ye wangchun said to be Keeping true and true, long - term work
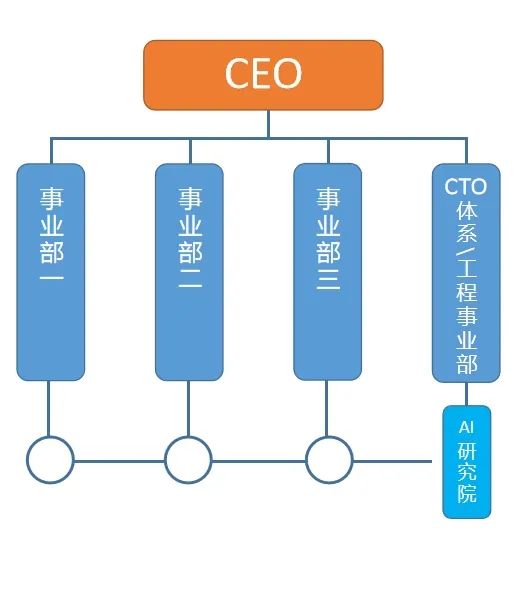
我为什么支持 BAT 拆掉「AI 研究院」

清大科越冲刺科创板:年营收2亿 拟募资7.5亿

IP packet header analysis and static routing
Network security - Novice introduction
![[machine learning notes] several methods of splitting data into training sets and test sets](/img/f6/eca239bb4b1764a1495ccd9a868ec1.jpg)
[machine learning notes] several methods of splitting data into training sets and test sets

【云资源】云资源安全管理用什么软件好?为什么?

Xampp configuring multiple items

Laravel dompdf exports PDF, and the problem of Chinese garbled code is solved
随机推荐
Brief introduction to revolutionary neural networks
Liste des liens (simple)
SSH免密码登录详解
为什么我认识的机械工程师都抱怨工资低?
Fault analysis | analysis of an example of MySQL running out of host memory
Matlab learning 2022.7.4
TiFlash 面向编译器的自动向量化加速
Blue Bridge Cup study 2022.7.5 (morning)
Linked list (simple)
关于Apache Mesos的一些想法
RK3566添加LED
Getting started with rce
国富氢能冲刺科创板:拟募资20亿 应收账款3.6亿超营收
[buuctf.reverse] 152-154
Laravel - view (new and output views)
Jetpack compose introduction to mastery
Wechat app payment callback processing method PHP logging method, notes. 2020/5/26
uplad_ Labs first three levels
PHP5下WSDL,SOAP调用实现过程
Linux下mysql数据库安装教程