当前位置:网站首页>Redis入门完整教程:Pipeline
Redis入门完整教程:Pipeline
2022-07-04 22:29:00 【谷哥学术】
3.3.1 Pipeline概念
Redis客户端执行一条命令分为如下四个过程:
1)发送命令
2)命令排队
3)命令执行
4)返回结果
其中1)+4)称为Round Trip Time(RTT,往返时间)。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。但
大部分命令是不支持批量操作的,例如要执行n次hgetall命令,并没有
mhgetall命令存在,需要消耗n次RTT。Redis的客户端和服务端可能部署在不
同的机器上。例如客户端在北京,Redis服务端在上海,两地直线距离约为
1300公里,那么1次RTT时间=1300×2/(300000×2/3)=13毫秒(光在真空中
传输速度为每秒30万公里,这里假设光纤为光速的2/3),那么客户端在1秒
内大约只能执行80次左右的命令,这个和Redis的高并发高吞吐特性背道而
驰。
Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进
行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序
返回给客户端,图3-5为没有使用Pipeline执行了n条命令,整个过程需要n次
RTT。
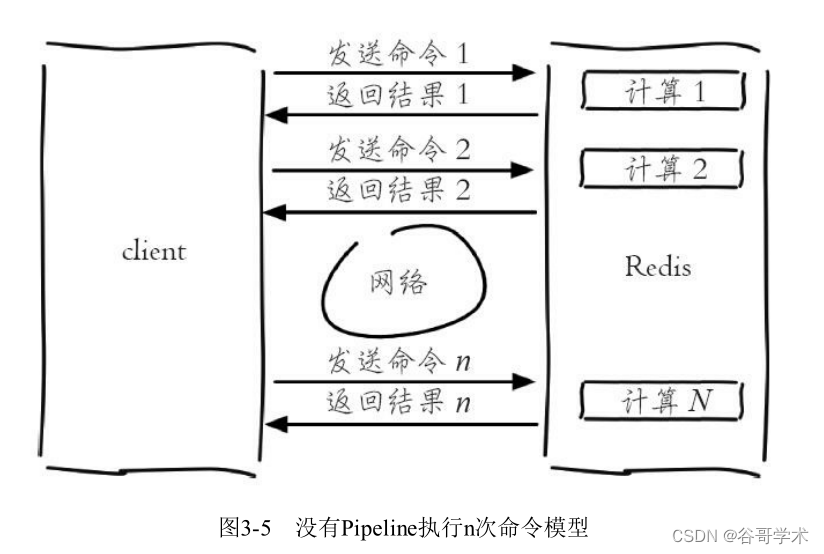
图3-6为使用Pipeline执行了n次命令,整个过程需要1次RTT。
Pipeline并不是什么新的技术或机制,很多技术上都使用过。而且RTT
在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区
会比较慢。Redis命令真正执行的时间通常在微秒级别,所以才会有Redis性
能瓶颈是网络这样的说法。
redis-cli的--pipe选项实际上就是使用Pipeline机制,例如下面操作将set
hello world和incr counter两条命令组装:
echo -en '*3\r\n$3\r\nSET\r\n$5\r\nhello\r\n$5\r\nworld\r\n*2\r\n$4\r\nincr\r\
n$7\r\ncounter\r\n' | redis-cli --pipe
但大部分开发人员更倾向于使用高级语言客户端中的Pipeline,目前大
部分Redis客户端都支持Pipeline,第4章我们将介绍如何通过Java的Redis客
户端Jedis使用Pipeline功能。
3.3.2 性能测试
表3-1给出了在不同网络环境下非Pipeline和Pipeline执行10000次set操作
的效果,可以得到如下两个结论:
·Pipeline执行速度一般比逐条执行要快。
·客户端和服务端的网络延时越大,Pipeline的效果越明显。
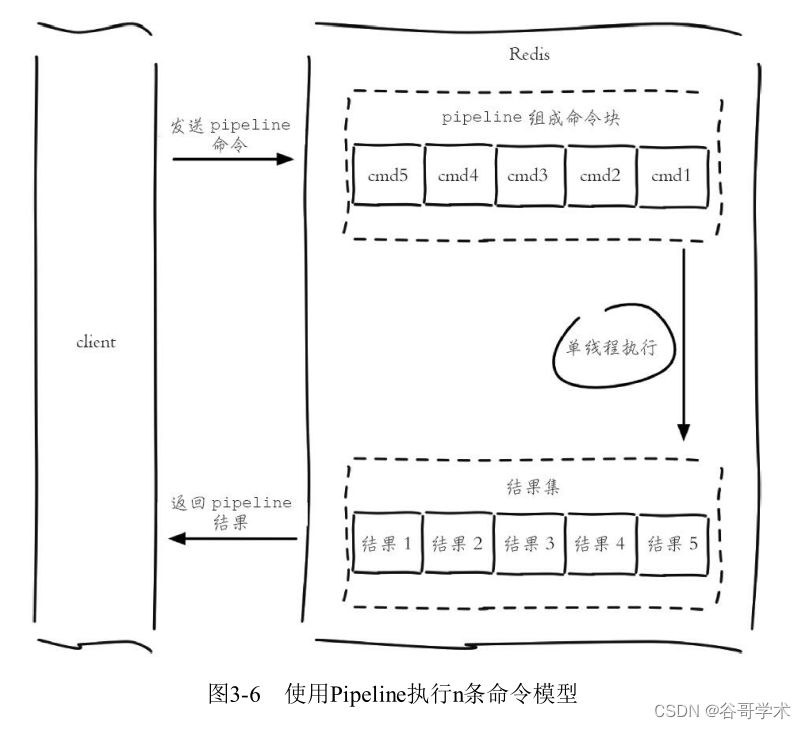
因测试环境不同可能得到的具体数字不尽相同,本测试Pipeline每次携
带100条命令。
3.3.3 原生批量命令与Pipeline对比
可以使用Pipeline模拟出批量操作的效果,但是在使用时要注意它与原
生批量命令的区别,具体包含以下几点:
·原生批量命令是原子的,Pipeline是非原子的。
·原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
·原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户
端的共同实现。
3.3.4 最佳实践
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否
则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方
面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次
较小的Pipeline来完成。
Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可
以作为批量操作的重要优化手段,具体细节见第11章。
边栏推荐
- Install the gold warehouse database of NPC
- LOGO特训营 第三节 首字母创意手法
- LOGO特训营 第二节 文字与图形的搭配关系
- 业务太忙,真的是没时间搞自动化理由吗?
- 新版判断PC和手机端代码,手机端跳转手机端,PC跳转PC端最新有效代码
- Unity Xiuxian mobile game | Lua dynamic sliding function (specific implementation of three source codes)
- 不同环境相同配置项的内容如何diff差异?
- [cooking record] - stir fried 1000 pieces of green pepper
- sobel过滤器
- SQL中MAX与GREATEST的区别
猜你喜欢

都说软件测试很简单有手就行,但为何仍有这么多劝退的?
Attack and Defense World MISC Advanced Area Erik baleog and Olaf
Logo special training camp Section V font structure and common design techniques

LOGO特訓營 第一節 鑒別Logo與Logo設計思路
业务太忙,真的是没时间搞自动化理由吗?
Logo special training camp section 1 Identification logo and logo design ideas

Logo Camp d'entraînement section 3 techniques créatives initiales
LOGO特训营 第三节 首字母创意手法
新版判断PC和手机端代码,手机端跳转手机端,PC跳转PC端最新有效代码
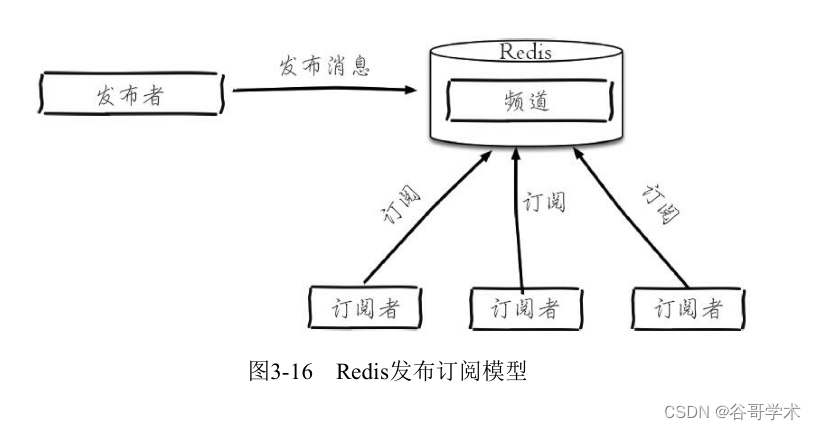
Redis入门完整教程:发布订阅
随机推荐
La prospérité est épuisée, les choses sont bonnes et mauvaises: Où puis - je aller pour un chef de station personnel?
The overview and definition of clusters can be seen at a glance
环境加密技术解析
Attack and defense world misc advanced grace-50
MYSQL架构——逻辑架构
Advanced area of attack and defense world misc 3-11
It is said that software testing is very simple, but why are there so many dissuasions?
Interview essential leetcode linked list algorithm question summary, whole process dry goods!
Create Ca and issue certificate through go language
集群的概述与定义,一看就会
MD5 tool class
Feature scaling normalization
Sobel filter
Logo special training camp section III initial creative techniques
攻防世界 MISC 进阶区 3-11
Deployment of JVM sandbox repeater
LOGO special training camp section I identification logo and Logo Design Ideas
How to send a reliable request before closing the page
【lua】int64的支持
攻防世界 MISC 进阶区 hit-the-core