当前位置:网站首页>Alibaba canal usage details (pit draining version)_ MySQL and ES data synchronization
Alibaba canal usage details (pit draining version)_ MySQL and ES data synchronization
2022-07-06 01:29:00 【shstart7】
canal summary
use
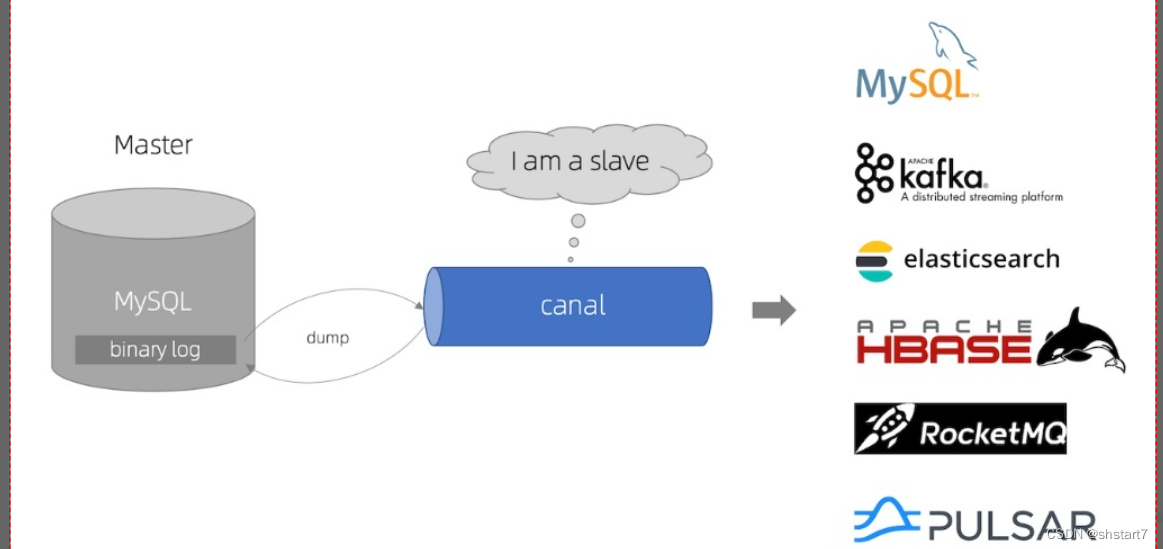
canal The main use is for MySQL Database incremental log analysis , Provide subscription and consumption of incremental data , In short, it is possible to correct MySQL Real time synchronization of incremental data , Support synchronization to MySQL、Elasticsearch、HBase Wait for data storage .
working principle
canal Can simulate MySQL The interaction protocol between master and slave libraries , In order to disguise as MySQL Slave Library , And then to MySQL Master database send dump agreement ,MySQL Master library received dump Requests will be sent to canal push binlog,canal Through analysis binlog Synchronize data to other storage .
1. edition
Here mine MySQL and ES All installed in On alicloud servers ,MySQL Version is 5.7,ES Version is 7.14.
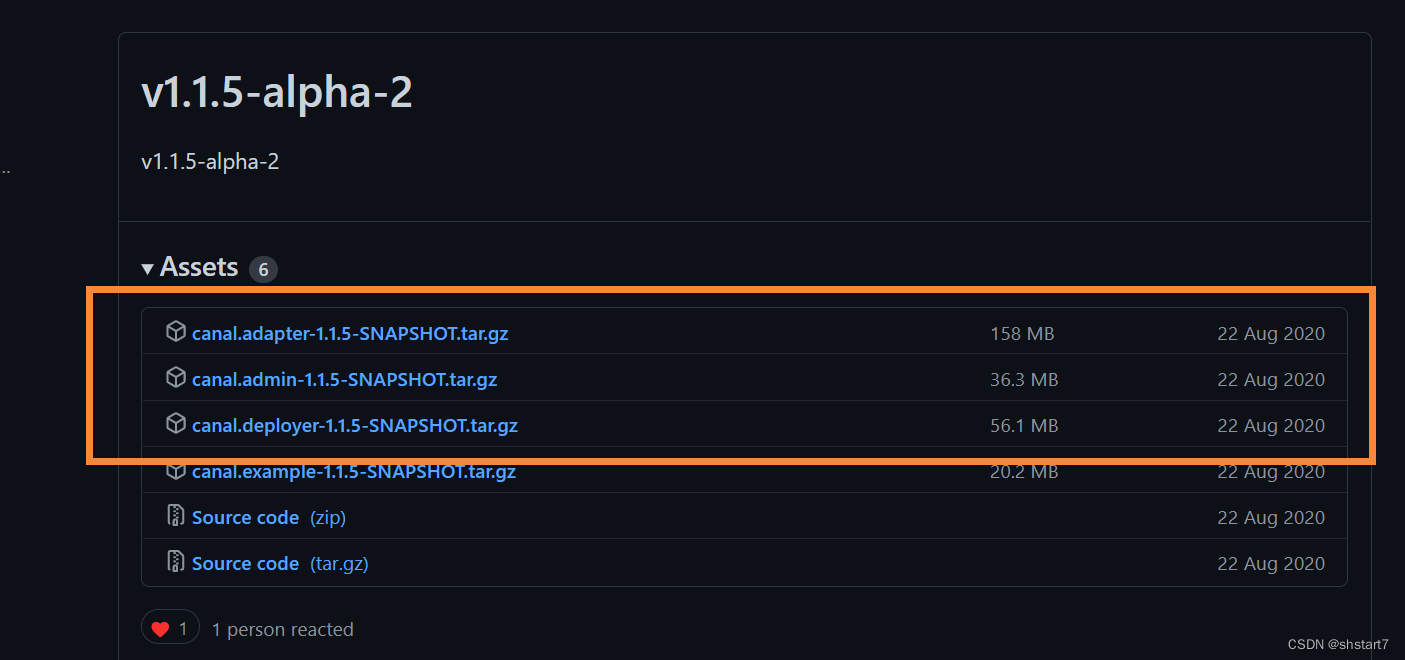
2. download
Download address Github, The version I downloaded here is v1.1.5-alpha-2, Download the first three components .
3. Upload
because Canal The memory required for startup is large , My Alibaba cloud server configuration is low , So here I am in the local Liunx Install the configuration on the server Canal.
Upload the three components to Linux Server .
4. To configure MySQL
because canal It's through subscribe MySQL Of binlog To achieve data synchronization , So we need to turn on MySQL Of binlog Write function , And set up binlog-format by ROW Pattern ,
my MySQL It's running in Alibaba cloud Docker Medium , And do the mount , So modify the external my.cnf File can , Add the following configuration
[mysqld]
## Set up server_id, You need to be unique in the same LAN
server_id=101
## Specify the name of the database that does not need to be synchronized
binlog-ignore-db=mysql
## Turn on binary log function
log-bin=mall-mysql-bin
## Set the memory size of binary log ( Business )
binlog_cache_size=1M
## Set the binary log format to use (mixed,statement,row)
binlog_format=row
## Binary log expiration cleanup time . The default value is 0, Does not automatically clean up .
expire_logs_days=7
## Skip all errors encountered in master-slave replication or errors of the specified type , avoid slave End copy interrupt .
## Such as :1062 An error is a duplicate of some primary keys ,1032 The error is because the master-slave database data is inconsistent
slave_skip_errors=1062
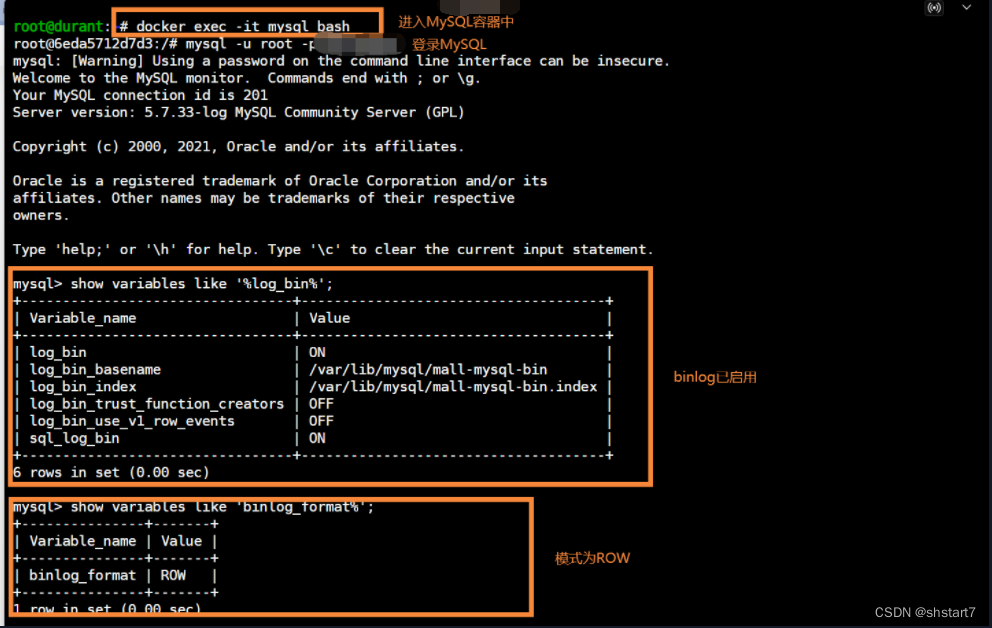
After the configuration is completed, you need to restart MySQL, After restart, use the following command to check binlog Is it enabled?
command
# see binlog Is it enabled?
show variables like '%log_bin%';
# Look at the MySQL Of binlog Pattern ;
show variables like 'binlog_format%';
Next, you need to create an account with permissions from the database , To subscribe to binlog, The account created here is
canal:canal
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
Create a database for testing bookstore, Then create a table book,
create table book(
id int(32) auto_increment primary key,
book_name varchar(32),
price double,
introduce varchar(2048),
press varchar(32),
author varchar(32),
publish_date DATE
)
5. To configure canal-server
Upload our canal.deployer-1.1.5-SNAPSHOT.tar.gz Extract to the specified directory
tar -zxvf canal.deployer-1.1.5-SNAPSHOT.tar.gz -C / Specify the path
Unzipped directory
├── bin
│ ├── restart.sh
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
├── conf
│ ├── canal_local.properties
│ ├── canal.properties
│ └── example
│ └── instance.properties
├── lib
├── logs
│ ├── canal
│ │ └── canal.log
│ └── example
│ ├── example.log
│ └── example.log
└── plugin
Modify the configuration
Modify the configuration file conf/example/instance.properties, You can configure it as follows , It is mainly to modify the database configuration ;
# Need to synchronize data MySQL Address
canal.instance.master.address=ip Address :3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# The account data is used to synchronize the database
canal.instance.dbUsername=canal
# Database password used to synchronize data
canal.instance.dbPassword=canal
# Database connection code
canal.instance.connectionCharset = UTF-8
# Need to subscribe to binlog Filter table of regular expressions
canal.instance.filter.regex=.*\\..*
Modify operation parameters
because canal The default operation requires a large amount of memory , Let's revise it here ( This step is very important )
modify bin In the catalog startup.sh, I changed it here to 512M

start-up
- Get into bin Catalog , start-up startup.sh
sh bin/startup.sh
6. To configure canal-adapter
Same as above , First unpack and install . The extracted directory is as follows .
├── bin
│ ├── adapter.pid
│ ├── restart.sh
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
├── conf
│ ├── application.yml
│ ├── es6
│ ├── es7
│ │ ├── biz_order.yml
│ │ ├── customer.yml
│ │ └── product.yml
│ ├── hbase
│ ├── kudu
│ ├── logback.xml
│ ├── META-INF
│ │ └── spring.factories
│ └── rdb
├── lib
├── logs
│ └── adapter
│ └── adapter.log
└── plugin
Modify the configuration file
conf/application.yml, You can configure it as follows , The main thing is to modify canal-server To configure 、 Data source configuration and client adapter configuration ;
Be careful : Linux To turn on 11111 port
canal.conf:
mode: tcp # Client mode , Optional tcp kafka rocketMQ
flatMessage: true # flat message switch , Whether or not to json Post data in string form , Only in kafka/rocketMQ Valid in mode
zookeeperHosts: # Corresponding to the cluster mode zk Address
syncBatchSize: 1000 # Number of batches per synchronization
retries: 0 # Retry count , -1 Try again for infinity
timeout: # Synchronization timeout , Unit millisecond
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111 # Set up canal-server The address of
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources: # Source database configuration
defaultDS:
url: jdbc:mysql:// own MySQL Of ip Address :3306/bookstore?useUnicode=true
username: canal
password: canal
canalAdapters: # Adapter list
- instance: example # canal Instance name or MQ topic name
groups: # Group list
- groupId: g1 # grouping id, If it is MQ The pattern will use this value
outerAdapters:
- name: logger # Log print adapter
- name: es7 # ES Synchronization adapter
hosts: own ES Of ip Address :9200 # ES Connection address
properties:
mode: rest # Mode options transport(9300) perhaps rest(9200)
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch # ES Cluster name
add mapping
Get into canal-adapter/conf/es7 Catalog , Create a book.yml, To configure MySQL The table in and Elasticsearch The mapping relation of index in
dataSourceKey: defaultDS # Of the source data source key, Corresponding to the srcDataSources The value in
destination: example # canal Of instance perhaps MQ Of topic
groupId: g1 # Corresponding MQ Mode of groupId, It only synchronizes the correspondence groupId The data of
esMapping:
_index: book # es The index name of
_id: _id # es Of _id, If you do not configure this item, you must configure the following pk term _id It will be es Automatically assigned
sql: "SELECT
b.id AS _id, # This is to bring MySQL Of id Corresponding upper ES Of _id
b.id, # This is to bring MySQL Of id Corresponding ES In document id attribute
b.book_name,
b.price,
b.introduce,
b.press,
b.author,
b.publish_date
FROM
book b" # sql mapping
etlCondition: "where a.c_time>={}" #etl Condition parameter of
commitBatch: 3000 # Submit batch size
Modify operation parameters
To canal_adapter/bin Under the table of contents , modify startup.sh file , I have set it as above 512M
And then run startup.sh, To start the
7. stay ES Create index in
PUT /book
{
"mappings" : {
"properties" : {
"author" : {
"type" : "keyword"
},
"book_name" : {
"type" : "text",
"analyzer": "ik_max_word" // Use a word breaker
},
"id" : {
"type" : "integer"
},
"introduce" : {
"type" : "text",
"analyzer": "ik_max_word" // Use a word breaker
},
"press" : {
"type" : "keyword"
},
"price" : {
"type" : "double"
},
"publish_date" : {
"type" : "date"
}
}
}
}
Look at the index

8. test
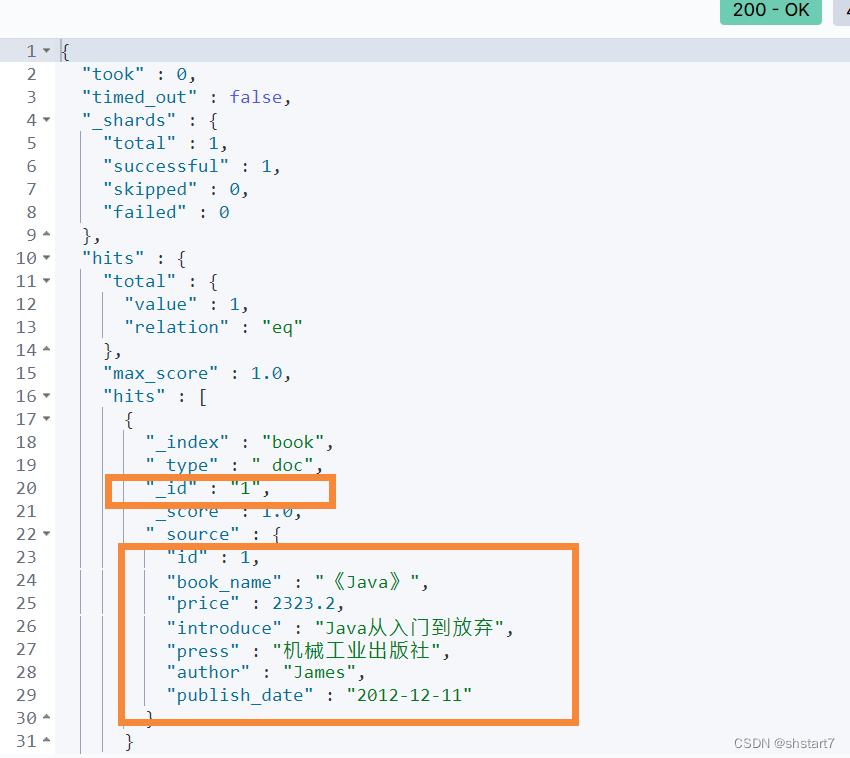
Use SQL Statement to create a record in the database
insert into book values(1, "《Java》", 2323.2,"Java From entry to abandonment ", " Mechanical industry press ", "James","2012-12-11")
After successful insertion , We are ES Search for , Find that the data is synchronized .
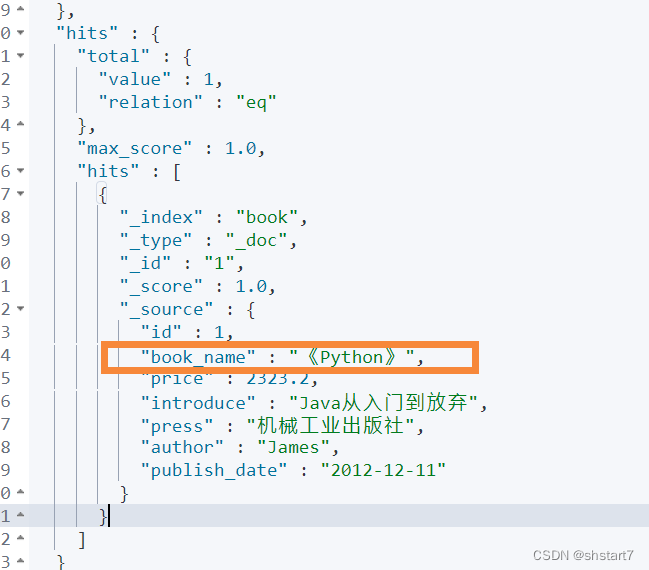
Test and modify
update book set book_name = "《Python》" where id = 1
To search again , Find out book_name Already synchronized .
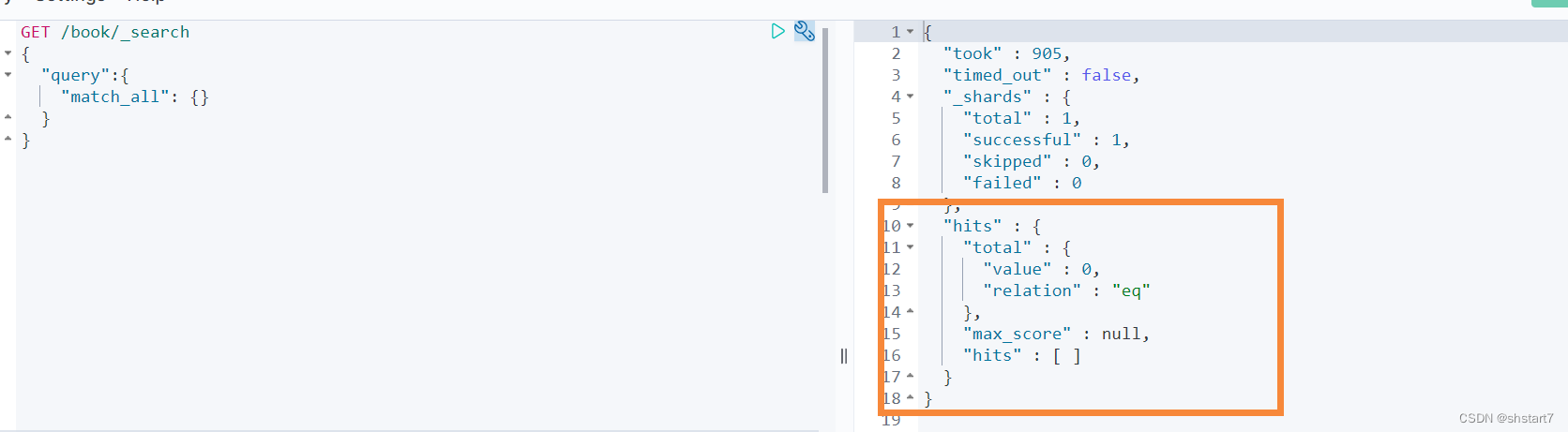
Test delete
delete from book where id = 1
Synchronous success
9.canal-admin Use
decompression canal.admin-1.1.5-SNAPSHOT.tar.gz, The extracted directory is as follows
├── bin
│ ├── restart.sh
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
├── conf
│ ├── application.yml
│ ├── canal_manager.sql
│ ├── canal-template.properties
│ ├── instance-template.properties
│ ├── logback.xml
│ └── public
│ ├── avatar.gif
│ ├── index.html
│ ├── logo.png
│ └── static
├── lib
└── logs
Executable files
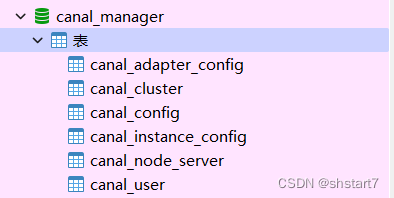
take conf/canal_manager.sql This file executes , Will create a canal_manager Database and several tables .
Modify the configuration
Modify the configuration fileconf/application.yml, You can configure it as follows , It is mainly to modify the data source configuration andcanal-adminManagement account configuration of , Note that you need to use a database account with read and write permissions , For example, management accountroot:root;
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: ip Address :3306
database: canal_manager
username: root
password: root password
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${
spring.datasource.address}/${
spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
- Next, for the previous building
canal-server(canal_deployer)Ofconf/canal_local.propertiesFile , The main thing is to modifycanal-adminConfiguration of , Use after modificationsh bin/startup.sh localrestartcanal-server:
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
alike , modify bin/startup.sh Operation parameters of
And then run startup The script to start admin
visit canal-admin Of Web Interface , Enter the account and password admin:123456 To log in , Access address :[http://192.168.80.100:8089
After successful login, you can use Web interface canal-server.
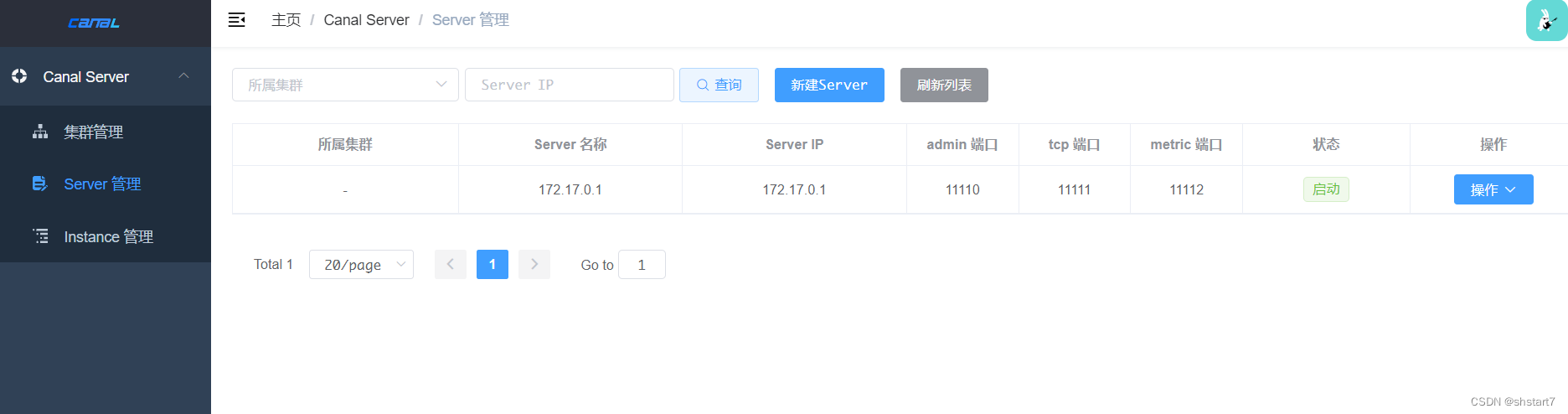
10. Problems encountered
Running memory problemsThis problem is still a pit , At first my Canal They all run on cloud servers , The operating parameters have not been modified , The result is often Canal It's working , then ES Hang up , Or is it Canal It doesn't work , So the memory is small xdm
must doModify the parameters .Port problemGuarantee Linux To turn on 11111 11110 8089 port
Start sequence problemWe need to start first.
canal_deployer, Then startcanal_adapterFind out bin There are some in the catalog
hs_error_xxxfile , To delete it , Then continue to configure and start
边栏推荐
- Paging of a scratch (page turning processing)
- Mysql--- query the top 5 students
- Unity VR solves the problem that the handle ray keeps flashing after touching the button of the UI
- leetcode刷题_验证回文字符串 Ⅱ
- Leetcode 剑指 Offer 59 - II. 队列的最大值
- 2022 Guangxi Autonomous Region secondary vocational group "Cyberspace Security" competition and its analysis (super detailed)
- MCU lightweight system core
- ctf. Show PHP feature (89~110)
- Leetcode skimming questions_ Sum of squares
- internship:项目代码所涉及陌生注解及其作用
猜你喜欢
3D模型格式汇总

Leetcode skimming questions_ Sum of squares
晶振是如何起振的?
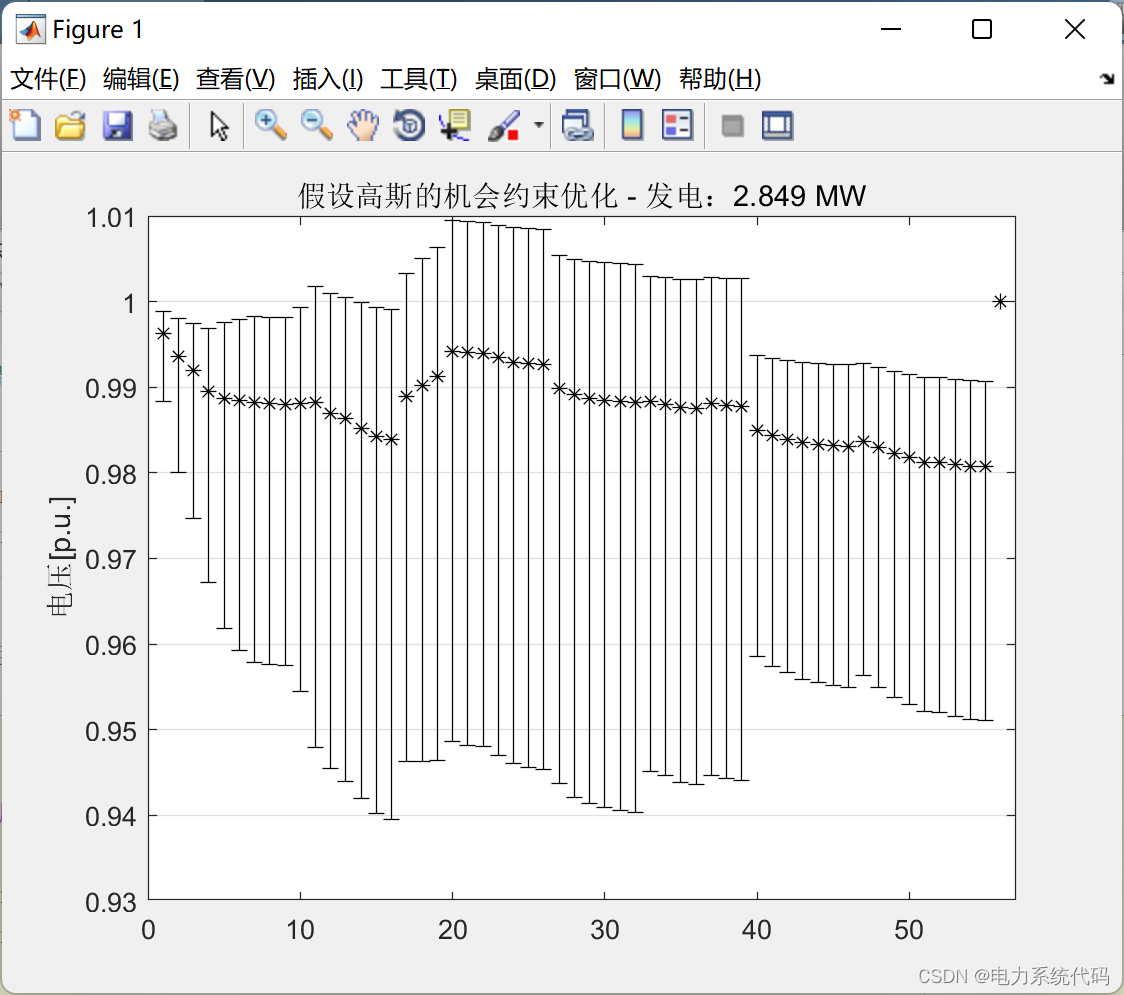
MATLB|实时机会约束决策及其在电力系统中的应用
Huawei Hrbrid interface and VLAN division based on IP

How to see the K-line chart of gold price trend?

Vulhub vulnerability recurrence 74_ Wordpress
![[solved] how to generate a beautiful static document description page](/img/c1/6ad935c1906208d81facb16390448e.png)
[solved] how to generate a beautiful static document description page

General operation method of spot Silver
【Flask】官方教程(Tutorial)-part2:蓝图-视图、模板、静态文件
随机推荐
MATLB | real time opportunity constrained decision making and its application in power system
[flask] static file and template rendering
Internship: unfamiliar annotations involved in the project code and their functions
关于softmax函数的见解
SSH login is stuck and disconnected
Unity VR resource flash surface in scene
Unity | two ways to realize facial drive
Remember that a version of @nestjs/typeorm^8.1.4 cannot be obtained Env option problem
Netease smart enterprises enter the market against the trend, and there is a new possibility for game industrialization
Basic operations of databases and tables ----- primary key constraints
[detailed] several ways to quickly realize object mapping
500 lines of code to understand the principle of mecached cache client driver
How to see the K-line chart of gold price trend?
MATLB|实时机会约束决策及其在电力系统中的应用
Unity VR solves the problem that the handle ray keeps flashing after touching the button of the UI
[flask] response, session and message flashing
A glimpse of spir-v
黄金价格走势k线图如何看?
Leetcode skimming questions_ Sum of squares
Mlsys 2020 | fedprox: Federation optimization of heterogeneous networks