Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Apache Flink It's a distribution 、 Stateful stream computing engine .
Now it will officially open Flink Series of learning notes and summary .(https://flink.apache.org/). This is a preparation , This paper mainly introduces the basic concepts of stream processing . Don't underestimate these theories , It is very helpful for the follow-up study and understanding .
Many of the following words come from flink official :https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html
What is data flow
An event is a statement about a change of the state of the domain modelled by the application. Events can be input and/or output of a stream or batch processing application.
Any kind of data is produced as a stream of events. Credit card transactions, sensor measurements, machine logs, or user interactions on a website or mobile application, all of these data are generated as a stream.
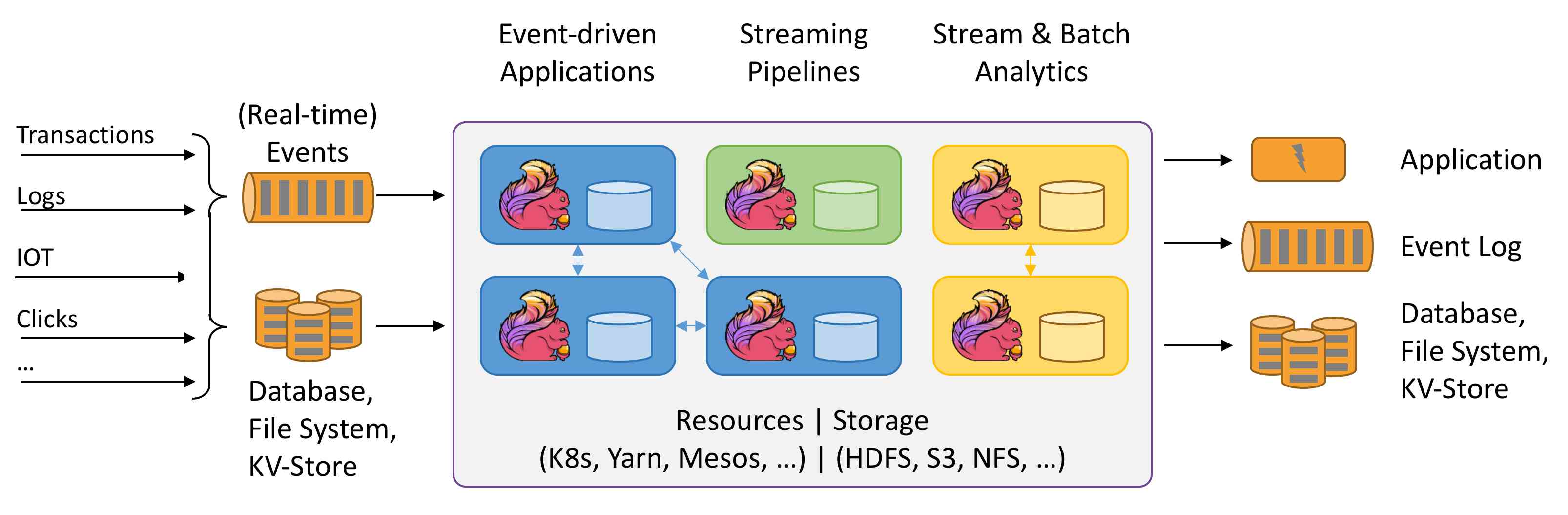
Data flow : It's a potentially infinite sequence of events . The events here can be real-time monitoring data 、 Sensor measurements 、 Transfer transaction 、 Logistics information 、 E-commerce online shopping order 、 User operation on the interface and so on .
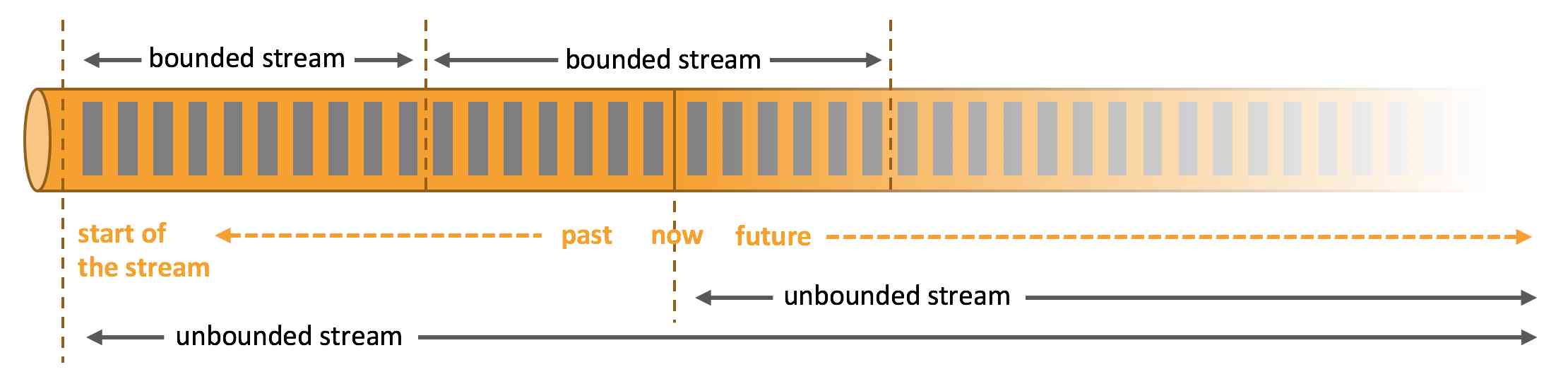
It can be divided into flow By incident and Bounded flow . As shown in the figure below :
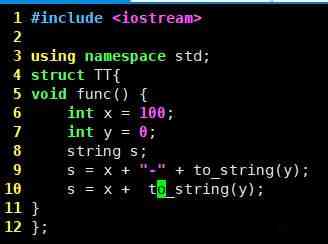
-
Unbounded streamshave a start but no defined end. They do not terminate and provide data as it is generated. -
Bounded streamshave a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations
Operations on data streams
Stream processing engine usually provides a series of operations to achieve data stream acquisition (Source)、 transformation (Transformation)、 Output (Sink).
To borrow flink official 1.10 Version of the picture https://ci.apache.org/projects/flink/flink-docs-release-1.10/concepts/programming-model.html, as follows :
A
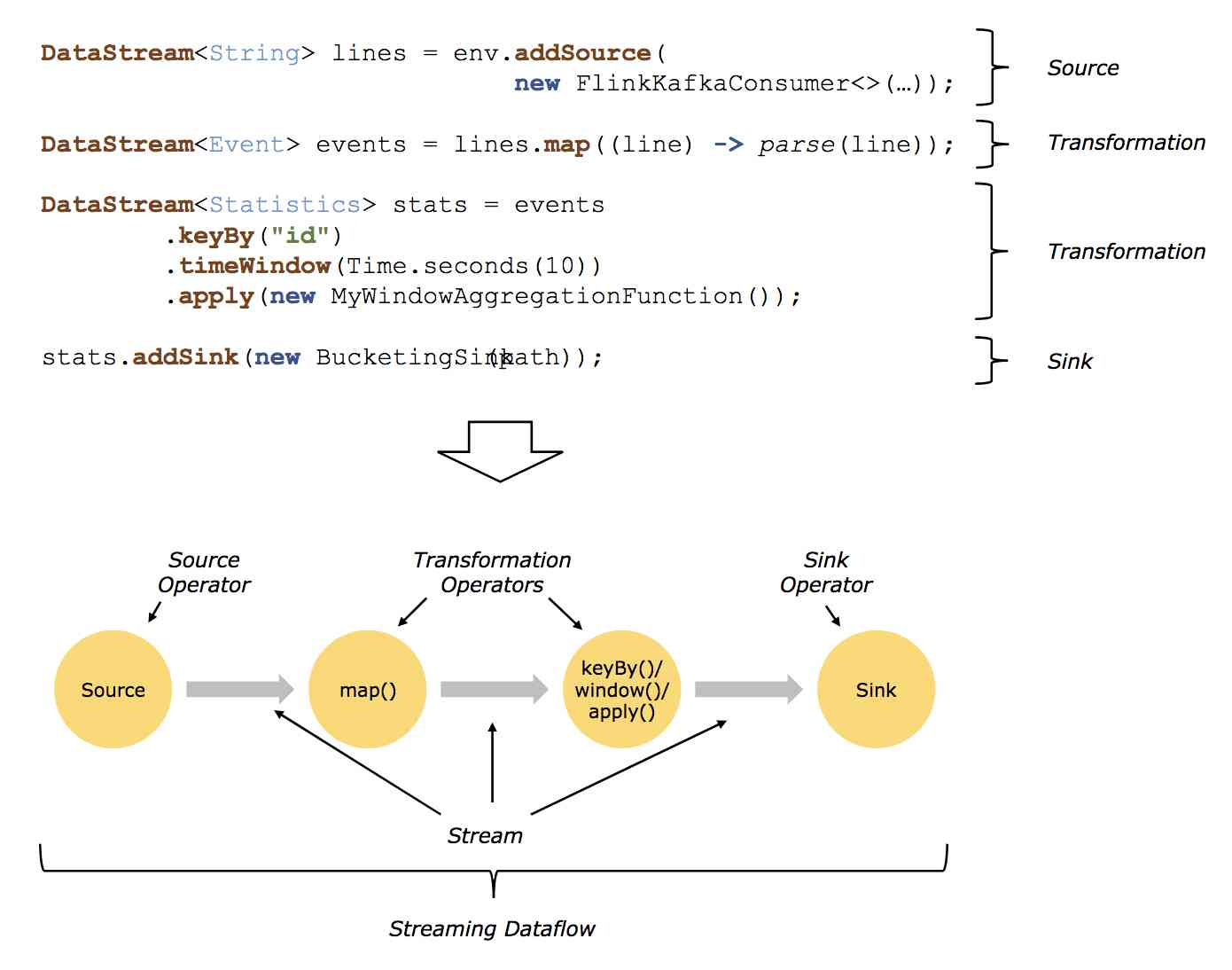
logical graphis a directed graph where the nodes are Operators and the edges define input/output-relationships of the operators and correspond to data streams or data sets. A logical graph is created by submitting jobs from a Flink Application.Logical graphsare also often referred to asdataflow graphs.
Operator: Node of a Logical Graph. An Operator performs a certain operation, which is usually executed by a Function. Sources and Sinks are special Operators for data ingestion and data egress.
dataflow chart : Describes how data flows between different operations .dataflow A graph is usually a directed graph . The nodes in the figure are called operator ( It's often called operation ), For calculation ; Edge represents data dependency , operator Get data from input , Calculate it , Then the data is generated and sent to the output for subsequent processing . An operator without input is called source, An operator with no output is called sink. One dataflow There must be at least one picture source And a sink.
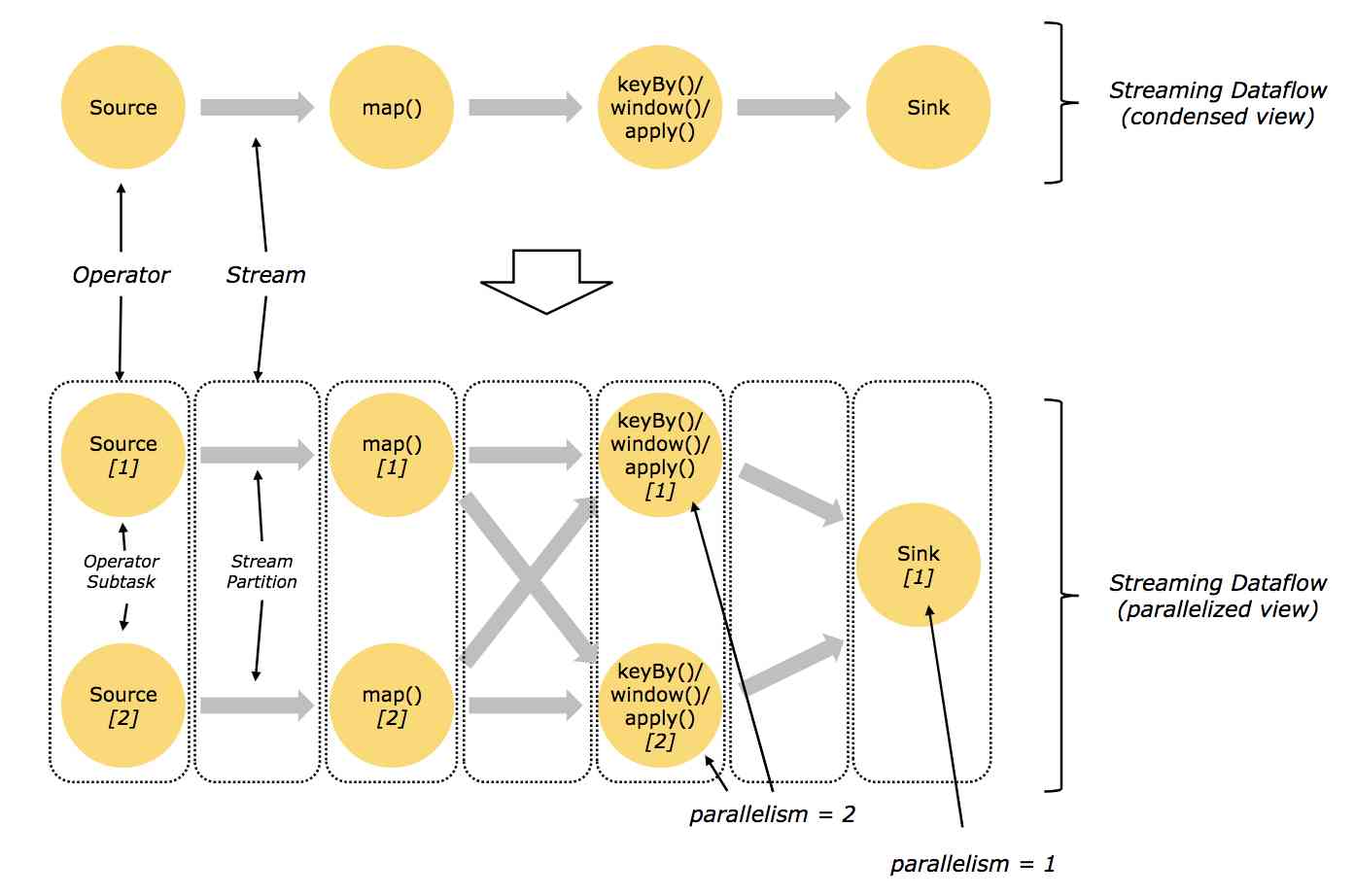
dataflow A graph is called a logic diagram (logical graph), Because it's just computational logic , In actual distributed processing , Each operator may run multiple parallel computations on different machines .
Source、Sink、Transformation
Sources are where your program reads its input from.
Data sinks consume DataStreams and forward them to files, sockets, external systems, or print them.
Data access (Source) And data output (Sink) Operations allow the stream processing engine to communicate with external systems . Data access operation is to obtain raw data from external data sources and convert it into a format suitable for subsequent processing by stream processing engine . The operator that implements the operation logic of data access is called Source, It can come from socket、 file 、kafka etc. . The output of the data stream in the output engine will be processed in an external format , The operator responsible for data output is called Sink, Can write files 、 database 、kafka etc. .
A Transformation is applied on one or more data streams or data sets and results in one or more output data streams or data sets. A transformation might change a data stream or data set on a per-record basis, but might also only change its partitioning or perform an aggregation.
Between data access and data output , There are a lot of conversion operations (Transformation). The conversion operation handles each event separately . These operations read events one by one , Apply some transformation to it and produce a new output stream . The operator can receive multiple input streams or output multiple output streams simultaneously , Single stream segmentation can also be done 、 Multi stream merging, etc .
How to understand the State
Operations on a data stream can be stateless (stateless), It can also be stateful (stateful), Stateless operations do not maintain internal state , That is, you don't need to rely on the event that has been processed , And it doesn't preserve historical events . Because the event processing does not affect each other and has nothing to do with the time when the event comes , Stateless operations are easy to parallelize . Besides , If something goes wrong , Stateless operators can be easily restarted and restored to work . contrary , Stateful operators may need to maintain previously received event information , Their status is updated based on new events , And used in the processing logic of future events . Stateful stream processing applications can be more challenging in parallelization and fault tolerance .
Stateful operators use both incoming events and internal states to calculate output . Because flow operators deal with potentially endless data , So care must be taken to avoid infinite growth of internal states . To limit the state size , Operators usually keep only a summary or overview of events seen so far . This summary may be a quantitative value , An accumulated value , A sampling of all events to date , A window buffer or a custom data structure that preserves some valuable information in the running process of an application .
It's not hard to imagine , There are many implementation challenges in supporting stateful operators . Stateful operators need to ensure that the state can be restored , And even if there is a failure, make sure the results are correct .
One more time (At Most Once)
It means that each event is processed at most once .
When a task fails, the simplest measure is to neither restore the lost state , And don't replay lost Events . let me put it another way , Events can be discarded at will , The correctness of the results is not guaranteed .
At least once (At Least Once)
It means that all events will eventually be dealt with , Although some may be dealt with more than once .
For most applications , The expectation of users is not to lose events . If the accuracy of the final result depends only on the integrity of the information , It may be acceptable to repeat processing . for example , Confirm whether an event has occurred , You can use it at least once to ensure the correct result . Its worst result is nothing more than repeated judgments . But if you want to count the number of times an event occurs , At least once, it may return the wrong result .
To ensure semantic correctness at least once , You need to find a way to replay events from the source or buffer . Persistent event logs write all events to persistent storage , So that they can be replayed in the event of a mission failure . Another way to do this is to use record validation (ack). Store all events in the buffer , The event will not be discarded until all tasks in the processing pipeline confirm that an event has been processed .
Exactly once (Exactly Once)
It means that not only is there no event lost , And each event updates the internal state only once .
Accuracy is the most strict , It's also the most difficult type of security to achieve . Essentially , Precise one-time semantics means that the application will always provide the right result , It's as if the fault never happened .
Exactly once also requires an event replay mechanism . Besides , The stream processing engine needs to ensure the consistency of internal state , That is, after fault recovery , The computing engine needs to know whether the update corresponding to an event has been reflected in the state . Transactional update is one way to achieve this goal , But it can bring huge performance overhead .Flink A lightweight checkpoint mechanism is used (Checkpoint) To achieve accurate results once .(flink The series will be followed by articles focusing on , It's enough to know that there is such a thing .)
As mentioned above “ Results guarantee ”, It refers to the consistency of the internal state of the stream processing engine . in other words , We focus on the state values that the application code can see after recovery . Please note that , It is not the same thing to ensure the consistency of application state and output . Once the data from Sink Write , Unless the target system supports transactions , Otherwise, it is difficult to guarantee the correctness of the final result .
Window operation
There is an official blog about window Introduction :https://flink.apache.org/news/2015/12/04/Introducing-windows.html
windows Related documents :https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#windows
Windowsare at the heart of processing infinite streams. Windows split the stream into “buckets” of finite size, over which we can apply computations.
Conversion operation (Transformation) It's possible that every event you deal with produces results and ( Probably ) Update status . However , Some operations must collect and buffer records in order to calculate the results , For example, streaming Join Or aggregate the median (Aggregation). In order to perform these operations efficiently on unbounded data streams , The amount of data maintained by the operation must be limited . The window operations that support this feature are discussed below .
Besides , With window manipulation , We can do some computation with actual semantic value on the data stream . for instance , Traffic flow at an intersection in recent minutes 、 Every intersection 10 Minutes of traffic etc. .
Window operations continue to create something called bucket A finite set of events for , And allow us to calculate based on these finite sets . Events are usually assigned to different buckets based on their time or other data properties . In order to define the semantics of window operators accurately , We need to decide how events are allocated to buckets and how often windows produce results . The behavior of a window is defined by a set of policies , These window policies determine when the bucket is created , How events are allocated to the bucket and when the data in the bucket participates in the calculation . The decision involved in the calculation will be determined according to the trigger conditions , When the trigger condition is met , The data in the bucket is sent to a calculation function , It is used to apply computational logic to the elements in the bucket . These computational functions can be some kind of aggregation ( For example, count (count)、 Sum up (sum)、 Maximum (max)、 minimum value (min)、 Average (avg) etc. ), It can also be a custom action . Policy can be specified based on Time ( for example “ lately 5 Events received in seconds ”)、 Number ( for example “ newest 100 Events ”) Or other data properties .
Next, we will focus on several common window semantics .
Scroll the window
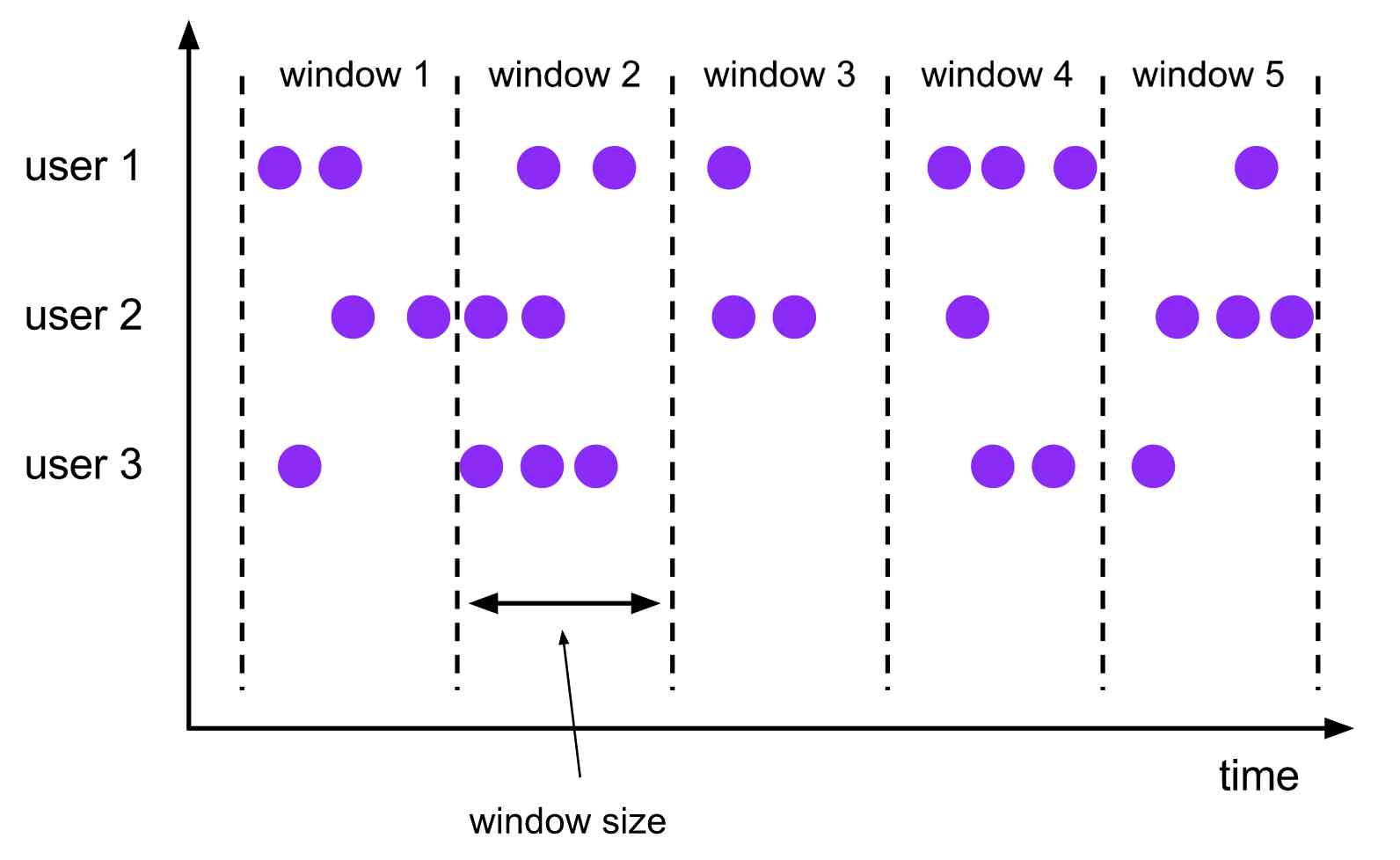
A
tumbling windowsassigner assigns each element to a window of a specified window size. Tumbling windows have a fixed size and do not overlap. For example, if you specify a tumbling window with a size of 5 minutes, the current window will be evaluated and a new window will be started every five minutes as illustrated by the following figure.
Scrolling windows assign events to buckets of fixed length that do not overlap .
- Based on quantity (
count-based) The scrolling window defines how many events need to be assembled before triggering the calculation ; - Based on time (
time-based) The scrolling window defines the interval between events buffered in the bucket . As shown in the figure above , Scrolling windows based on time intervals aggregate events into buckets , Every once in a while (window size) Trigger a calculation .
The sliding window
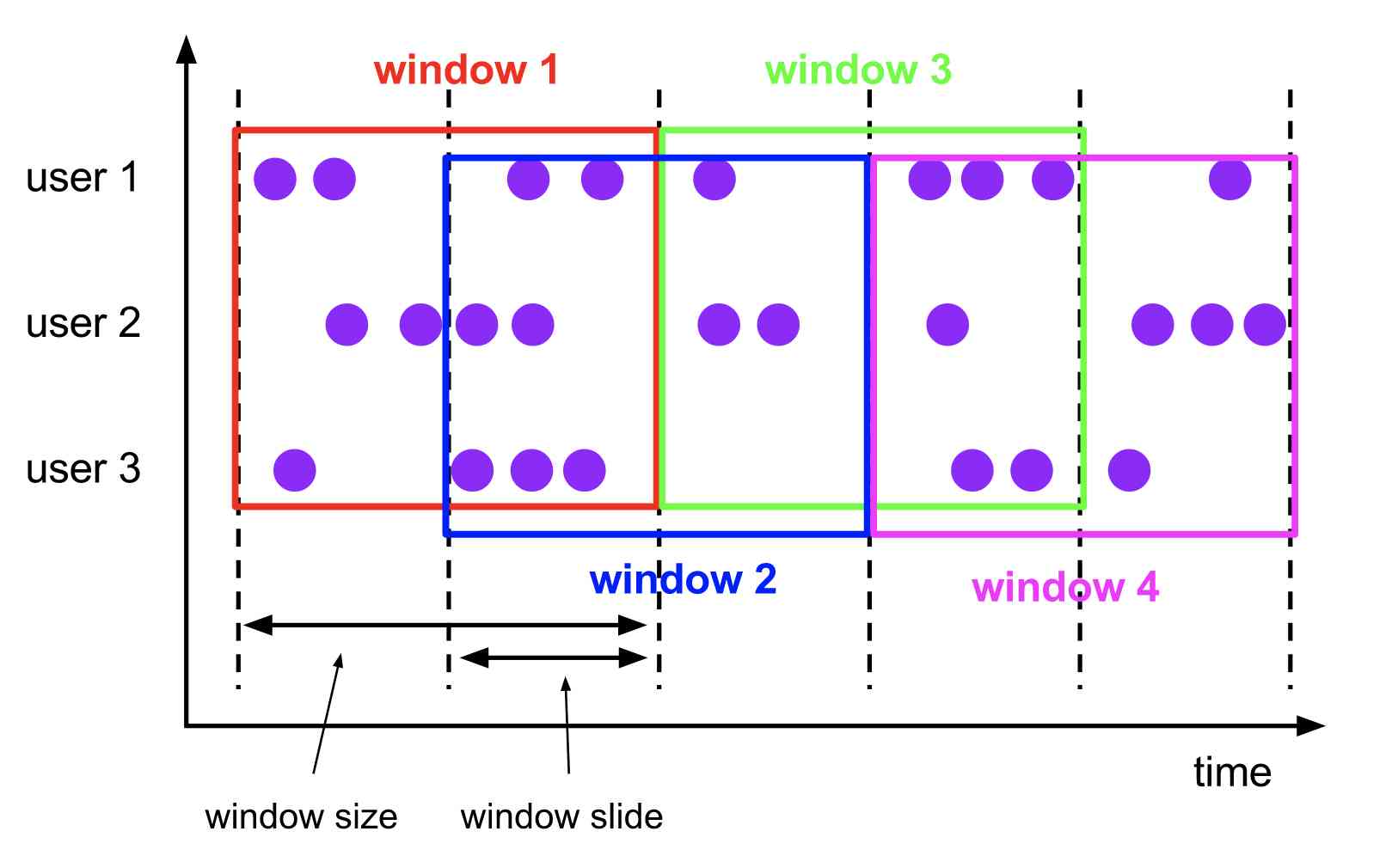
The
sliding windowsassigner assigns elements to windows of fixed length. Similar to a tumbling windows assigner, the size of the windows is configured by the window size parameter. An additional window slide parameter controls how frequently a sliding window is started. Hence, sliding windows can be overlapping if the slide is smaller than the window size. In this case elements are assigned to multiple windows.
Sliding windows allocate events to buckets of fixed size that allow overlapping , This means that each event may belong to more than one bucket at the same time .
For example, you could have windows of size 10 minutes that slides by 5 minutes. With this you get every 5 minutes a window that contains the events that arrived during the last 10 minutes as depicted by the following figure.
We specify the length of (size) And sliding interval (slide) To define a sliding window . The sliding interval determines how often a new bucket is generated . for instance ,SlidingTimeWindows(size = 10min, slide = 5min) The meaning of the expression is every other 5 The minute count is the most recent 10 Minute data .
Session window
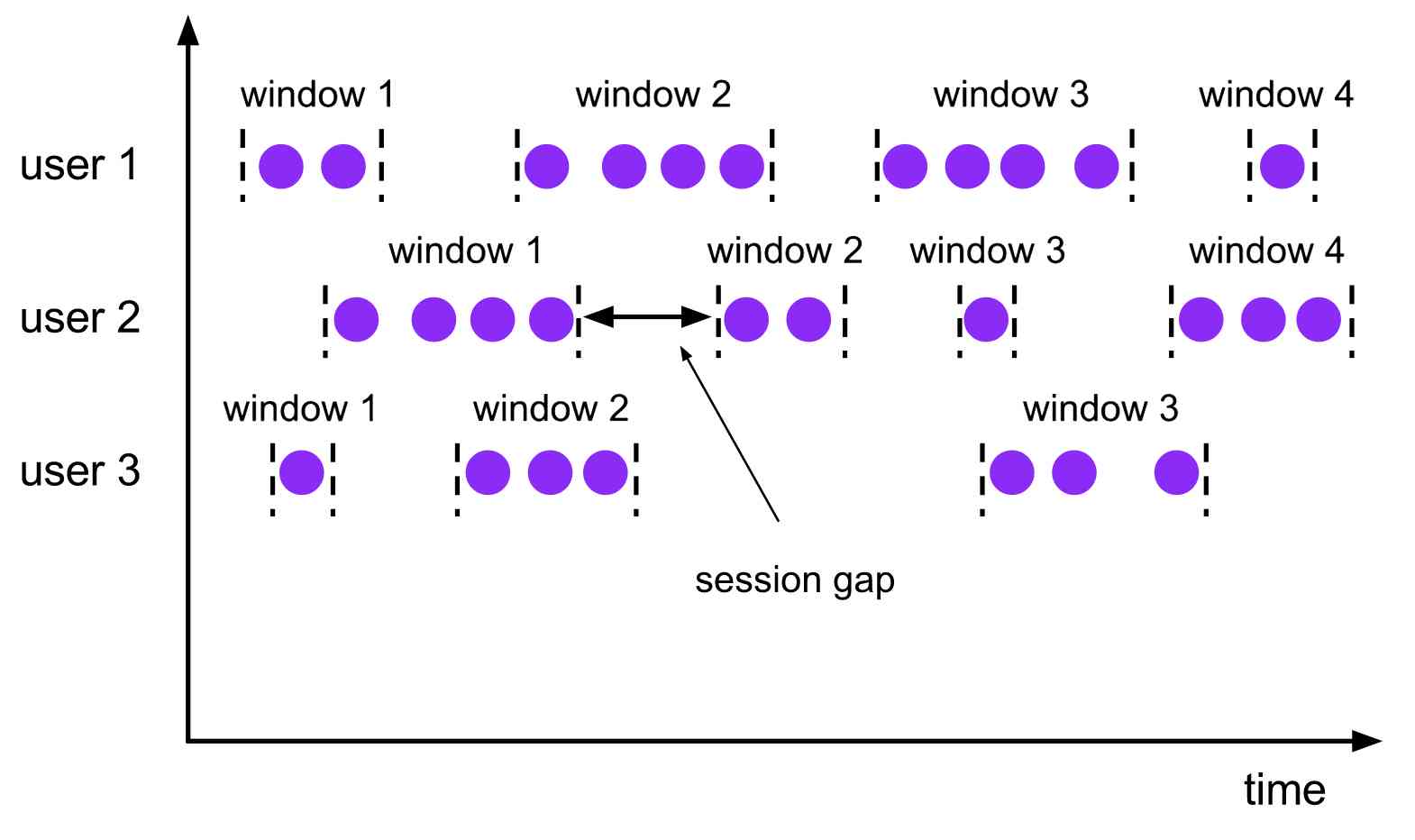
The
session windowsassigner groups elements by sessions of activity. Session windows do not overlap and do not have a fixed start and end time, in contrast to tumbling windows and sliding windows. Instead a session window closes when it does not receive elements for a certain period of time, i.e., when a gap of inactivity occurred. A session window assigner can be configured with either a static session gap or with a session gap extractor function which defines how long the period of inactivity is. When this period expires, the current session closes and subsequent elements are assigned to a new session window.
The session window is very useful in some real situations , These scenes are not suitable for scrolling windows or sliding windows . for instance , There's an app to analyze user behavior online , In this application, we need to group events according to the same activity or session source of users . A conversation consists of a series of events occurring in adjacent time plus a period of inactivity . say concretely , The interaction between users browsing a series of news articles can be regarded as a conversation . Because the session length is not pre-defined , It's about the actual data , So neither scrolling nor sliding windows can be applied to the scene . And we need a window operation , Events belonging to the same session can be assigned to the same bucket . Session window according to session interval (session gap) Divide the event into different sessions , This interval value defines the length of inactivity before the session is closed .
Time semantics
The related documents :https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/timely-stream-processing.html
All of the above window types need to buffer data before generating results , It is not difficult to find that time has become the core element in the application . for instance , Whether the operator should rely on the time when the event actually occurs or when the application processes the event ? This needs to be analyzed according to the specific application scenarios .
There are two different concepts of time in streaming applications , Processing time (Processing time) And event time (Event time). As shown in the figure below :
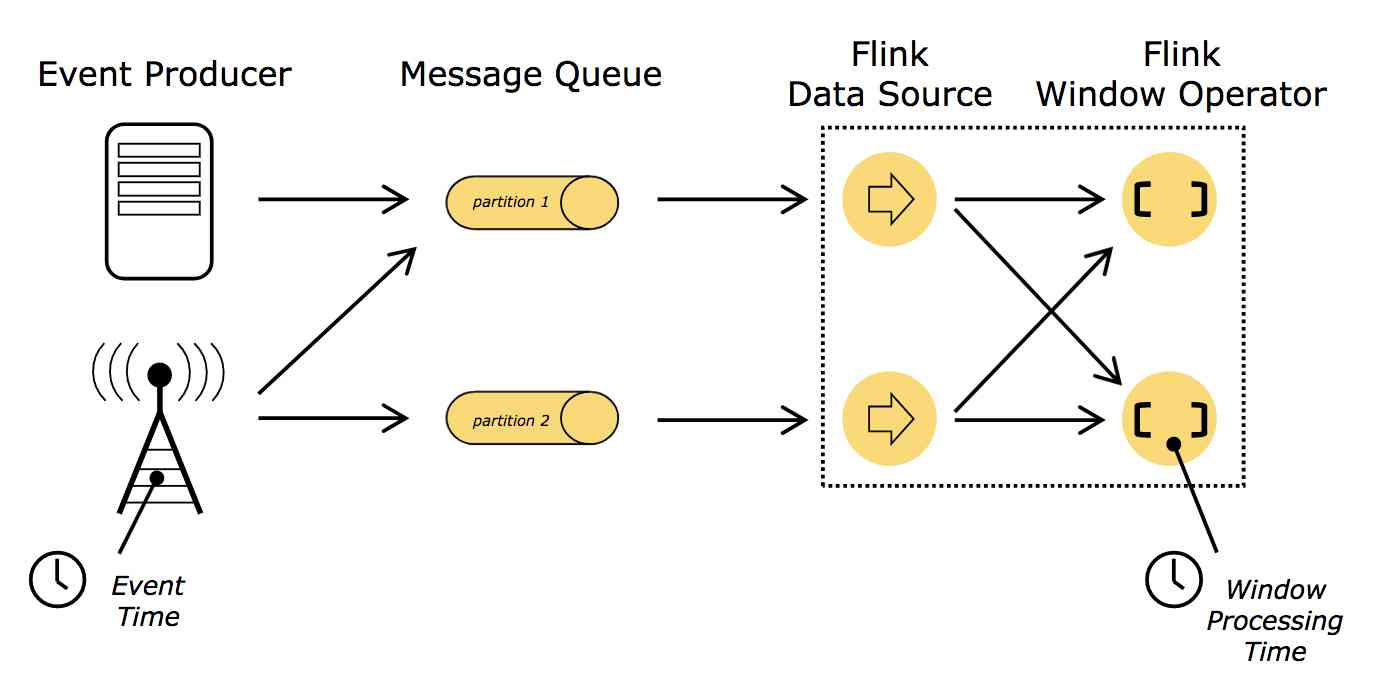
The processing time
Processing time: Processing time refers to the system time of the machine that is executing the respective operation.
The processing time is the local clock time on the machine where the current stream processing operator is located .
The window based on processing time contains events that arrive at the window operator within a certain period of time , The time period here is measured according to the local clock time on the machine .
be based on The processing time The result of the operation is unpredictable , The result of the calculation is uncertain . When the processing speed of data stream is not consistent with the expected speed 、 The sequence of event arrival operators is chaotic 、 The local clock is not correct , be based on The processing time The window events of may be different .
Event time
Event time: Event time is the time that each individual event occurred on its producing device. This time is typically embedded within the records before they enter Flink, and that event timestamp can be extracted from each record.
Event time is the time when the event actually occurs in the data stream . It's attached to the event itself , Before entering the stream processing engine (Flink) There has been .
Even if there is a delay , rely on Event time It can also reflect what happened , Thus, the event can be assigned to the corresponding time window accurately .
be based on Event time Is predictable , The result is certain . Regardless of the processing speed of the data stream 、 What is the order in which events arrive at the operator , be based on Event time The same result will be generated in the window of .
One of the challenges to overcome with event time is how to handle delayed events . It can't be because it happened a year ago , A year ago, the time window has not been closed, waiting for the arrival of late events . This leads to an important question : How to determine the trigger time of event time window ? In other words , How long does it take to be sure that all events that occurred before a certain point in time have been received ?
The mechanism in Flink to measure progress in event time is
watermarks. Watermarks flow as part of the data stream and carry a timestamp t. A Watermark(t) declares that event time has reached time t in that stream, meaning that there should be no more elements from the stream with a timestamp t’ <= t (i.e. events with timestamps older or equal to the watermark).
Waterline (watermark) It's a global progress indicator , A point in time when you are confident that there will be no more delay events . Essentially , The waterline provides a logical clock , Used to inform the system of the current event time . When an operator receives a time of t The water level line of , You can assume that you will not receive any more timestamps less than or equal to t The event .
The waterline allows us to make a trade-off between the accuracy of the results and the delay . Aggressive waterline strategy ensures low latency , But then comes low credibility . In this case , Delay events may come after the water mark , We have to add some extra code to deal with them . conversely , If the water level is too conservative , Although credibility is guaranteed , But it may unnecessarily increase processing latency .
Practical application , It may be difficult for the system to obtain enough information to perfectly determine the water level . The stream processing engine needs to provide some mechanism to handle late events that are later than the water mark . Depending on the specific needs , These events may be ignored directly , It's possible to log them , Or use them to correct previous results .
Summary
Since event time can solve most problems , Why care about processing time ? in fact , Processing time also has its applicable scenarios . The processing time window minimizes latency . Because there is no need to consider late or out of order events , The window simply buffers Events , Then the window calculation is triggered immediately after the specified time . therefore , For applications that place more emphasis on speed than accuracy , Processing time will come in handy . Another scenario is , You need to report results periodically in real time, regardless of their accuracy . for example , You want to observe the access of the data stream , Detect data interrupts by calculating the approximate number of events per second , You can use processing time for window computation .
To make a long story short , Although processing time provides lower latency , But its results depend on the speed of processing , With uncertainty . The event time is the opposite , It can guarantee the relative accuracy of the results , And allows you to handle delayed or out of order events .
How to evaluate the performance of stream processing
about Batch application for , The total execution time of a job is usually used as an aspect of performance evaluation . but Streaming applications Event infinite input 、 The program continues to run , There is no concept of total execution time , Therefore, latency and throughput are often used to evaluate the performance of streaming applications . Usually , We want the system to have low latency 、 High throughput .
Delay : Represents the time required to process an event . That is, the time interval from receiving the event to observing the effect of event processing . for instance , The average delay is 10 millisecond , It means that the average data will be in 10 Processing in milliseconds ;95% Delay for 10 Millisecond means 95% The event will be in 10 Processing in milliseconds . Guaranteed low latency for many streaming applications ( The alarm system 、 Network monitoring 、 Fraud identification 、 Risk control, etc ) crucial , Thus, the so-called Real time applications .
throughput : Represents how many events can be processed per unit time . It can be used to measure the processing speed of the system . But should pay attention to , Processing speed also depends on the speed of data arrival , therefore , Low throughput does not necessarily mean poor system performance . In streaming applications , It is usually expected that the system will be able to cope with events coming at maximum speed , This is the upper performance limit when the system is fully loaded ( Peak throughput ). In production , Once the event arrival speed is too high, the system can not handle it , The system is forced to start buffering Events . If the throughput of the system has reached the limit , Increasing the speed of event arrival will only increase the delay . If the system continues to receive events at a rate beyond its power , Then the buffer may run out . This condition is often referred to as back pressure (backpressure), We have a variety of alternative strategies to deal with it .flink The series will be followed by an article focusing on this .
Reference material
- [1] [Fabian Hueske & Vasiliki Kalavri Writing , Cui Xingcan translate ; be based on Apache Flink Flow processing of (Stream Processing with Apache Flink); China Electric Power Press ,2020]
- [2] Apache Flink Documentation v1.11

![[elastic search technology sharing] - ten pictures to show you the principle of ES! Understand why to say: ES is quasi real time!](/img/4b/176185ba622b275404e2083df4f28a.jpg)