当前位置:网站首页>面试官: ShardingSphere 学一下吧
面试官: ShardingSphere 学一下吧
2020-11-06 21:30:00 【全栈小刘】
文章目录
[toc]
学习之前先了解下分库分表概念:https://spiritmark.blog.csdn.net/article/details/109524713
一、ShardingSphere简介
在数据库设计时候考虑垂直分库和垂直分表。随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使 用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表。
分库分表导致的问题:
- 跨节点连接查询问题(分页、排序)
- 多数据源管理问题
Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、 Proxy和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场 景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
二、Sharding-JDBC
Sharding-JDBC 是轻量级的 java 框架,是增强版的 JDBC 驱动,简化对分库分表之后数据相关操作。 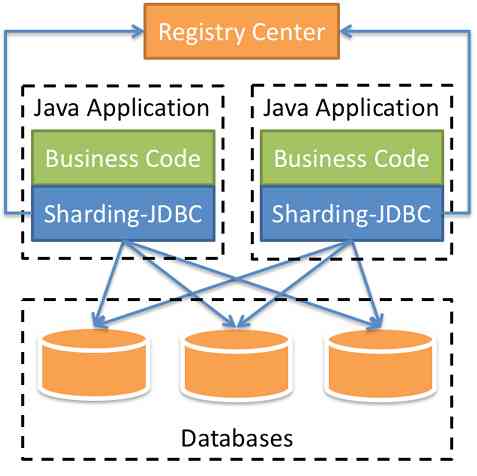 新建项目并添加依赖:
新建项目并添加依赖:
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-parentartifactId>
<version>2.2.1.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.20version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
dependencies>
2.1 Sharding-JDBC实现水平分表
① 按照水平分表的方式,创建数据库和数据库表
水平分表规则:如果添加 cid是偶数把数据添加 course_1,如果是奇数添加到 course_2 
CREATE TABLE `course_1` (
`cid` bigint(16) NOT NULL,
`cname` varchar(255) ,
`userId` bigint(16),
`cstatus` varchar(16) ,
PRIMARY KEY (`cid`)
)
② 编写实体和 Mapper 类
@Data
public class Course {
private Long cid;
private String cname;
private Long userId;
private String cstatus;
}
@Repository
public interface CourseMapper extends BaseMapper<Course> {
}
③ 详细配置文件
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m1.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
table-strategy:
inline:
shardingcolumn: cid
algorithm-expression: course_$->{cid%2+1}
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ 测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i 10; i++) {
Course course = new Course();
course.setCname("java" + i);
course.setUserId(100L);
course.setCstatus("Normal" + i);
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid",493001315358605313L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
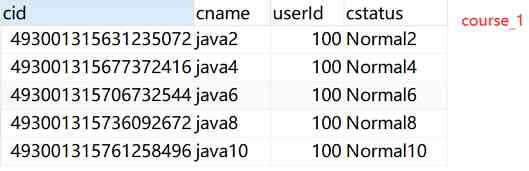
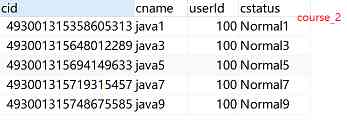
2.2 Sharding-JDBC实现水平分库
① 需求分析 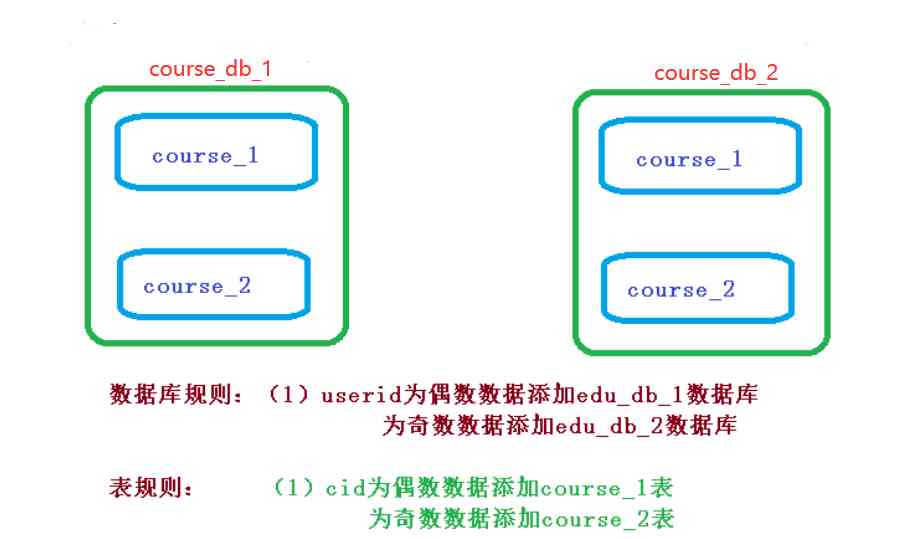 ② 创建数据库和表
② 创建数据库和表
③ 详细配置文件
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_2?serverTimezone=GMT%2B8
username: root
password: 1234
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_3?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m$->{1..2}.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
database-strategy:
inline:
sharding-column: userId
algorithm-expression: m$->{userId%2+1}
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid%2+1}
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ 测试代码
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i 20; i++) {
Course course = new Course();
course.setCname("java" + i);
int random = (int) (Math.random() * 10);
course.setUserId(100L + random);
course.setCstatus("Normal" + i);
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid", 493001315358605313L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
查询实际对应的 SQL: 
2.3 Sharding-JDBC操作公共表
公共表 :
- 存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
- 在每个数据库中创建出相同结构公共表
① 思路分析 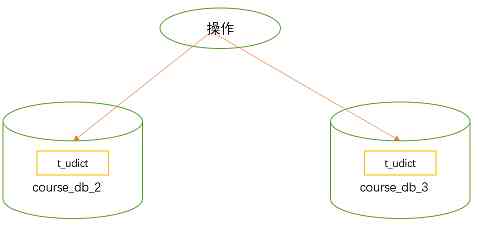 ② 在对应数据库创建公共表
② 在对应数据库创建公共表 t_udict,并创建对应实体和 Mapper``
CREATE TABLE `t_udict` (
`dict_id` bigint(16) NOT NULL,
`ustatus` varchar(16) ,
`uvalue` varchar(255),
PRIMARY KEY (`dict_id`)
)
③ 详细配置文件
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_2?serverTimezone=GMT%2B8
username: root
password: 1234
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_3?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m$->{1..2}.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
database-strategy:
inline:
sharding-column: userId
algorithm-expression: m$->{userId%2+1}
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid%2+1}
t_udict:
key-generator:
column: dict_id
type: SNOWFLAKE
broadcast-tables: t_udict
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ 进行测试
经测试:数据插入时会在每个库的每张表中插入,删除时也会删除所有数据。
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
UdictMapper udictMapper;
@Test
public void addUdict() {
Udict udict = new Udict();
udict.setUstatus("a");
udict.setUvalue("已启用");
udictMapper.insert(udict);
}
@Test
public void deleteUdict() {
QueryWrapper<Udict> wrapper = new QueryWrapper<>();
wrapper.eq("dict_id", 493080009351626753L);
udictMapper.delete(wrapper);
}
}
2.4 Sharding-JDBC实现读写分离
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器是对外提供增删改业务的生产服务器;第二台数据库服务器主要进行读的操作。
Sharding-JDBC通过 sql语句语义分析,实现读写分离过程,不会做数据同步,数据同步通常数据库集群间会自动同步。
详细配置文件:
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m0,s0
m0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
s0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3307/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
masterslave:
master-data-source-name: m0
slave-data-source-names: s0
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
经过测试:增删改操作都是会通过 master数据库,同时 master数据库会同步数据给 slave数据库;查操作都是通过 slave数据库.
三、Sharding-Proxy
Sharding-Proxy定位为 透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持, 目前仅 MySQL和 PostgreSQL版本。
Sharding-Proxy是独立应用,需要安装服务,进行分库分表或者读写分离配置,启动使用。 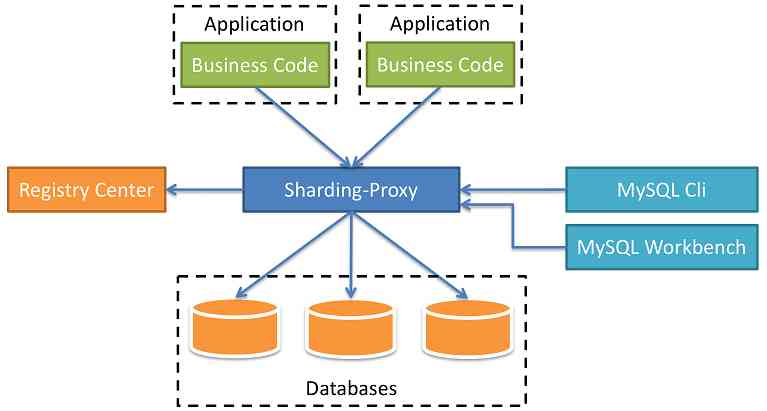 <br>
<br> Sharding-proxy的使用参考:Sharding-Proxy的基本使用。 微信搜一搜:全栈小刘
版权声明
本文为[全栈小刘]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4199331/blog/4705383
边栏推荐
- 2020年第四届中国 BIM (数字建造)经理高峰论坛即将在杭举办
- The AI method put forward by China has more and more influence. Tianda et al. Mined the development law of AI from a large number of literatures
- What are Devops
- nacos、ribbon和feign的簡明教程
- DC-1靶機
- 快速排序为什么这么快?
- The data of pandas was scrambled and the training machine and testing machine set were selected
- Jmeter——ForEach Controller&Loop Controller
- Azure data factory (3) integrate azure Devops to realize CI / CD
- Cglib 如何实现多重代理?
猜你喜欢

JVM内存分配 -Xms128m -Xmx512m -XX:PermSize=128m -XX:MaxPermSize=512m
Read the advantages of Wi Fi 6 over Wi Fi 5 in 3 minutes
每个大火的“线上狼人杀”平台,都离不开这个新功能
MeterSphere开发者手册

Shh! Is this really good for asynchronous events?
Staying up late summarizes the key points of report automation, data visualization and mining, which is different from what you think
DRF JWT authentication module and self customization
游戏开发中的新手引导与事件管理系统
Live broadcast preview | micro service architecture Learning Series live broadcast phase 3
大会倒计时|2020 PostgreSQL亚洲大会-中文分论坛议程安排
随机推荐
Building and visualizing decision tree with Python
What if the front end doesn't use spa? - Hacker News
Discussion on the technical scheme of text de duplication (1)
JVM内存分配 -Xms128m -Xmx512m -XX:PermSize=128m -XX:MaxPermSize=512m
Gather in Beijing! The countdown to openi 2020
Xmppmini project details: step by step from the principle of practical XMPP technology development 4. String decoding secrets and message package
How to get started with new HTML5 (2)
Python基础变量类型——List浅析
Using NLP and ml to extract and construct web data
Custom function form of pychar shortcut key
Humor: hacker programming is actually similar to machine learning!
What are the common problems of DTU connection
给字节的学姐讲如何准备“系统设计面试”
How to customize sorting for pandas dataframe
How to turn data into assets? Attracting data scientists
Discussion on the development practice of aspnetcore, a cross platform framework
Outsourcing is really difficult. As an outsourcer, I can't help sighing.
Vue.js Mobile end left slide delete component
【自学unity2d传奇游戏开发】如何让角色动起来
百万年薪,国内工作6年的前辈想和你分享这四点