当前位置:网站首页>Using NLP and ml to extract and construct web data
Using NLP and ml to extract and construct web data
2020-11-06 01:28:00 【Artificial intelligence meets pioneer】
author |Conner Brew compile |VK source |Towards Data Science

Introduce
In this paper , We're going to create a war Research Institute (ISW) Structured document database of .ISW Providing information products for diplomatic and intelligence professionals , To deepen our understanding of conflicts around the world .
To see the source code associated with this article and Notebook, Please visit the following link :https://colab.research.google.com/drive/1pTrOXW3k5VQo1lEaahCo79AHpyp5ZdfQ?usp=sharing
To visit Kaggle The final structured dataset hosted on , Please visit the following link :https://www.kaggle.com/connerbrew2/isw-web-scrape-and-nlp-enrichment
This article will be about web extract 、 natural language processing (NLP) And named entity recognition (NER) The practice of . about NLP, We will mainly use open source Python library NLTK and Spacy.
The purpose of this article is to demonstrate web Extract and NLP A use case of , Rather than a comprehensive beginner's tutorial on the use of these two techniques . If you are NLP or web The novice of extraction , I suggest you follow different tutorials , Or browse Spacy、BeautifulSoup and NLTK Document page .
# Import library
import requests
import nltk
import math
import re
import spacy
import regex as re
import pandas as pd
import numpy as np
import statistics as stats
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import json
# You need to get from NLTK Download some packages .
from bs4 import BeautifulSoup
from nltk import *
nltk.download('stopwords')
nltk.download('punkt')
from nltk.corpus import stopwords
# # In most environments , You need to install NER-D.
!pip install ner-d
from nerd import ner
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.cluster import MiniBatchKMeans
from sklearn.feature_extraction.text import TfidfVectorizer
Initialize variable
First , We will initialize the data fields needed in the final structured data . For each document , I'm going to extract the title 、 Release date 、 The person's name 、 Place names and all kinds of other information . We will also enhance the information that already exists in the document — for example , We will use the place names in the document to get the relevant coordinates , This is very useful for visualizing data in the future .
# Initialize the data fields of the final dataset
dates=[]
titles=[]
locations=[]
people=[]
key_countries=[]
content_text=[]
links=[]
coord_list=[]
mentioned_countries=[]
keywords=[]
topic_categories=[]
# Initialize the cluster variables for the following topic model
cluster_keywords=[]
cluster_number=[]
# Use SPACY Library initialization NLP object
nlp = spacy.load("en_core_web_sm")
extract href
We will start from ISW Extracting documents from the production Library of . First , We're going to grab “ Browse ” Page to get a separate href link . Then we store these links in a list , For the extraction function to access later .
# # from ISW Browse the page for product links
urls=['http://www.understandingwar.org/publications?page={}'.format(i) for i in range(179)]
hrefs=[]
def get_hrefs(page,class_name):
page=requests.get(page)
soup=BeautifulSoup(page.text,'html.parser')
container=soup.find_all('div',{'class':class_name})
container_a=container[0].find_all('a')
links=[container_a[i].get('href') for i in range(len(container_a))]
for link in links:
if link[0]=='/':
hrefs.append('http://www.understandingwar.org'+link)
for url in urls:
get_hrefs(url,'view-content')
Web Crawling
The first few functions we're going to write are fairly simple text extraction . This tutorial is not about BeautifulSoup A tutorial on usage , To understand Python Medium web Crawling , Please check the documentation here :https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Get date
For our first function , We will extract the release date . It scans... Extracted from the product web page html file , And find a class called “submitted” Field of . This is our production date .
Get the title
Next , We need a product name . Again , This field is conveniently marked as “title” class .
Get all the text
Last , We will extract the full text of the document . When I extract text , I usually follow “ Extract first , Post filtration ” Of web Extraction method . It means , In the initial text extraction , I do the least filtering and processing of text . I prefer to deal with it in future analysis , Because it's necessary . however , If you want to go further , You may want to preprocess the extracted text more than the following function demonstrates .
For my get_contents function , I stick to the most basic principles —— I've blacklisted some text that I don't want to be extracted . Then extract all the text from the page and attach it to a temporary string , The string is then appended to the list content_text in .
# Extract release data
def get_date(soup):
try:
data=soup.find('span',{'class':'submitted'})
content=data.find('span')
date=content.get('content')
dates.append(date)
except Exception:
dates.append('')
pass
# Extract product title
def get_title(soup):
try:
title=soup.find('h1',{'class':'title'}).contents
titles.append(title[0])
except Exception:
titles.append('')
pass
# Extract the text content of the product
def get_contents(soup):
try:
parents_blacklist=['[document]','html','head',
'style','script','body',
'div','a','section','tr',
'td','label','ul','header',
'aside',]
content=''
text=soup.find_all(text=True)
for t in text:
if t.parent.name not in parents_blacklist and len(t) > 10:
content=content+t+' '
content_text.append(content)
except Exception:
content_text.append('')
pass
natural language processing
Next , We will find out which countries are cited in the product . There's a lot of API Can be used to check the text content of the country , But here we're going to use a simple approach : Make a list of all the countries in the world . This list is from Wikipedia :https://en.wikipedia.org/wiki/Lists_of_countries_and_territories
In the function we get all_mentioned_countries after , It uses basic statistical analysis to determine which countries are most prominent —— These countries are most likely to be the focus of the documentary narrative . So , This function calculates the number of times a country is mentioned throughout the document , Then look for countries mentioned more than average . And then add these countries to key_countries In the list .
# Quote a list of all countries in the text .
# If a word in the text matches a country in the list , Then it will be added to the list of countries .
def get_countries(content_list):
iteration=1
for i in range(len(content_list)):
print('Getting countries',iteration,'/',len(content_list))
temp_list=[]
for word in word_tokenize(content_list[i]):
for country in country_list:
if word.lower().strip() == country.lower().strip():
temp_list.append(country)
counted_countries=dict(Counter(temp_list))
temp_dict=dict.fromkeys(temp_list,0)
temp_list=list(temp_dict)
if len(temp_list)==0:
temp_list.append('Worldwide')
mentioned_countries.append(temp_list)
# Count the number of times each country is mentioned , Then check each count against the average .
# If a country is mentioned more than the average , It will be recorded as a keyword .
keywords=[]
for key in counted_countries.keys():
if counted_countries[key] > np.mean(list(counted_countries.values())):
keywords.append(key)
if len(keywords) != 0:
key_countries.append(keywords)
else:
key_countries.append(temp_list)
iteration+=1
Named entity recognition : place
Next , We need to enrich our data . Final , The goal of structured data is often to perform some kind of analysis or visualization —— In this context of international conflict information , It's valuable to map information by geographic location . So , We need coordinates corresponding to the document .
Find the place name
First , We will use natural language to process (NLP) And named entity recognition (NER) Extract place names from text .
NLP It's a form of machine learning , Computer algorithms use grammar and grammar rules to learn the relationships between words in text . Through this kind of learning ,NER Be able to understand the role of certain words in a sentence or paragraph . This tutorial is not intended to be a comprehensive introduction to NLP— For such resources , Please check out :https://medium.com/@ODSC/an-introduction-to-natural-language-processing-nlp-8e476d9f5f59
From the outside API Get coordinates
To find the coordinates of a place name , We will use Open Cage API Query coordinates ; You can create a free account here and receive API secret key . There are many other popular geography api To choose from , But through trial and error , I find Open-Cage It has the best performance in the Middle East .
First , We iterate over each place name retrieved from the document , And in Open Cage Query it in . Once the work is done , We will compare Open Cage With the previously created mentioned_countries list . This will ensure that the query results we retrieve are in the right place .
# Use NLP Extracting place names , Then the query open-cage API To get the coordinates needed for the drawing
# Insert your own OpenCage API key:
geo_api_key='Insert Your API Key Here'
def get_coords(content_list):
iteration=1
for i in range(len(content_list)):
print('Getting coordinates',iteration,'/',len(content_list))
temp_list=[]
text=content_list[i]
# Apply one NER Algorithm , from python library 'ner-d' Looking for place names in .
doc=nlp(text)
location=[X.text for X in doc.ents if X.label_ == 'GPE']
location_dict=dict.fromkeys(location,0)
location=list(location_dict)
# Query location .
for l in location:
try:
request_url='https://api.opencagedata.com/geocode/v1/json?q={}&key={}'.format(l,geo_api_key)
page=requests.get(request_url)
data=page.json()
for n in range(len(data)):
# This line of code checks whether the country in the query result matches mentioned_countries One of them matches . If not , Then the query result is likely to be a false positive example .
if data['results'][n]['components']['country'] in mentioned_countries[i]:
lat=data['results'][n]['geometry']['lat']
lng=data['results'][n]['geometry']['lng']
coordinates={'Location': l,
'Lat': lat,
'Lon': lng}
temp_list.append(coordinates)
break
else:
continue
except Exception:
continue
coord_list.append(temp_list)
iteration+=1
Named entity recognition : people
Next , We will extract the names of the people mentioned in the document . So , We will use it again NER-d python In the library NER Algorithm .
Get full name
In the final structured data , I just want the full name . Only to find “Jack” or “John” The data of , Is it confusing ? So , We're going to use some basic statistics again . When it comes to full names , Function tracks the full name , Usually at the beginning of the text .
When it comes to part of the name , It will refer to the full name list , To identify who the part name refers to . for example , If a news article says this :“ Joe · Biden is running for President . Joe is the vice president of former President Barack Obama , We know Joe means Biden , Because his full name was given earlier in the article . This function will run in the same way .
Repeated names
If there is a repetition , This function will use the previous one for country / The same statistics for the region function . It will measure the number of times a name is mentioned , And make it the most likely name . for example : Joe · Biden and his son Hunt · Biden is a popular American politician . Joe · Biden was a former Vice President . Biden is now working with President Donald · Trump is running for President ”. According to the statistical focus of the text , This article is obviously about Joe · Biden , Not hunt · Biden .
Verify name
Once the function calculates all the full names mentioned , It will add them to a list . then , It will look up every name in Wikipedia , To verify that it's the name of an influential person worthy of inclusion in structured data .
def get_people(content_list):
iteration=1
# Use NER Look up a person's name in the text .
for i in range(len(content_list)):
print('Getting people',iteration,'/',len(content_list))
temp_list=[]
text=content_list[i]
doc=nlp(text)
persons=[X.text for X in doc.ents if X.label_ == 'PERSON']
persons_dict=dict.fromkeys(persons,0)
persons=list(persons_dict)
full_names=[]
for person in persons:
if len(word_tokenize(person)) >= 2:
string_name=re.sub(r"[^a-zA-Z0-9]+", ' ', person).strip()
full_names.append(string_name)
final_names=[]
for person in persons:
for name in full_names:
tokens=word_tokenize(name)
for n in range(len(tokens)):
if person==tokens[n]:
final_names.append(name)
for name in full_names:
final_names.append(name)
name_dict=dict.fromkeys(final_names,0)
final_names=list(name_dict)
valid_names=[]
for name in final_names:
page=requests.get('https://en.wikipedia.org/wiki/'+name)
if page.status_code==200:
valid_names.append(name)
people.append(valid_names)
iteration+=1
Keywords extraction :TF-IDF
Our next task is to extract keywords from text . The most common method is to use a method called TF-IDF Methods .TF-IDF The model measures the frequency of words used in a single document , Then compare it with the average usage rate in the whole document corpus .
If a term is frequently used in a single document , And it is rarely used in the whole document corpus , Then the term is likely to represent a keyword specific to that particular document . This article is not about TF-IDF A comprehensive overview of the model . To learn more , Please check out this article about Medium The article :https://medium.com/datadriveninvestor/tf-idf-in-natural-language-processing-8db8ef4a7736
First , Our function will create what is usually called “ The word bag ”. This will track every word used in each document . then , It will calculate the number of times each word is used in each document — Frequency of words (TF). then , It calculates the inverse document frequency (IDF). These values are then written into the coordinates in the matrix , And then sort the matrix , To help us find the words that most likely represent the document .
# The first function preprocesses text by reducing the case of characters and removing special characters .
def pre_process(text):
text=text.lower()
text=re.sub("</?.*?>"," <> ",text)
text=re.sub("(\\d|\\W)+"," ",text)
return text
# This function maps a matrix to coordinates .TF-IDF Function maps frequency fractions to a matrix , Then you need to sort these matrices , To help us find keywords .
def sort_coo(coo_matrix):
tuples = zip(coo_matrix.col, coo_matrix.data)
return sorted(tuples, key=lambda x: (x[1], x[0]), reverse=True)
# Same as above , This is a helper function , Once the frequency maps to the matrix , It will help sort and select keywords .
# This function is specifically designed to help us to use TF-IDF Statistics select the most relevant keywords
def extract_topn_from_vector(feature_names, sorted_items, topn=10):
sorted_items = sorted_items[:topn]
score_vals = []
feature_vals = []
for idx, score in sorted_items:
fname = feature_names[idx]
score_vals.append(round(score, 3))
feature_vals.append(feature_names[idx])
results= {}
for idx in range(len(feature_vals)):
results[feature_vals[idx]]=score_vals[idx]
return results
# The last function contains the above helper function , It applies to the text TF-IDF Algorithm , Search keywords according to frequency of use .
def get_keywords(content_list):
iteration=1
processed_text=[pre_process(text) for text in content_list]
stop_words=set(stopwords.words('english'))
cv=CountVectorizer(max_df=0.85,stop_words=stop_words)
word_count_vector=cv.fit_transform(processed_text)
tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True)
tfidf_transformer.fit(word_count_vector)
feature_names=cv.get_feature_names()
for i in range(len(processed_text)):
print('Getting Keywords',iteration,'/',len(content_list))
doc=processed_text[i]
tf_idf_vector=tfidf_transformer.transform(cv.transform([doc]))
sorted_items=sort_coo(tf_idf_vector.tocoo())
keys=extract_topn_from_vector(feature_names,sorted_items,10)
keywords.append(list(keys.keys()))
iteration+=1
Theme model
NLP One of the most common tasks in is the topic model . This is a form of clustering , It tries to automatically classify documents according to their text content . In this particular case , I want to know at a glance ISW What topics are involved . By classifying documents according to their text content , I can easily get a general idea of the main idea of the document .
To quantify
For this example , I will use k-means Clustering algorithm for topic modeling . First , I'll use it again TF-IDF The algorithm vectorizes each document . Vectorization is a machine learning term , It refers to the conversion of non digital data into digital spatial data that computers can use to perform machine learning tasks .
Optimize
Once the document is vectorized ,helper Function will check the optimal number of clusters .(k Express k-means Of k). In this case , The best number is 50. Once I find the best number , In this case , I've commented out this line of code , And manually adjust the parameter to equal to 50. This is because the dataset I'm analyzing doesn't change very often , So I can expect that over time , The number of optimal clusters remains the same . For data that changes more frequently , You should return the best number of clusters as a variable - This will help your clustering algorithm automatically set its best parameters . I showed an example in my time series analysis article .
clustering
After each cluster is finished , I'll number each cluster (1–50) Save to the list of cluster numbers , The keywords that make up each cluster are saved to cluster_keywords List of . These cluster keywords will be used later to add titles to each topic cluster .
# This function is based on a variety of “k” Parameter checking clustering algorithm , To find “k” The optimal value .
def find_optimal_clusters(data, max_k):
iters = range(2, max_k+1, 2)
sse = []
for k in iters:
sse.append(MiniBatchKMeans(n_clusters=k,
init_size=1024,
batch_size=2048,
random_state=20).fit(data).inertia_)
print('Fit {} clusters'.format(k))
f, ax = plt.subplots(1, 1)
ax.plot(iters, sse, marker='o')
ax.set_xlabel('Cluster Centers')
ax.set_xticks(iters)
ax.set_xticklabels(iters)
ax.set_ylabel('SSE')
ax.set_title('SSE by Cluster Center Plot')
# Get keywords from the content list to help classify topic models
def get_top_keywords(data, clusters, labels, n_terms):
df = pd.DataFrame(data.todense()).groupby(clusters).mean()
for i,r in df.iterrows():
cluster_keywords.append(','.join([labels[t] for t in np.argsort(r)[-n_terms:]]))
# List of content applied to topic modeling
def get_topics(content_list):
processed_text=[pre_process(text) for text in content_list]
stop_words=set(stopwords.words('english'))
cv=CountVectorizer(max_df=0.85,stop_words=stop_words)
word_count_vector=cv.fit_transform(processed_text)
tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True)
tfidf_transformer.fit(word_count_vector)
feature_names=cv.get_feature_names()
vector=tfidf_transformer.transform(cv.transform(processed_text))
#find_optimal_clusters(vector,50)
clusters = MiniBatchKMeans(n_clusters=50, init_size=1024, batch_size=2048, random_state=20).fit_predict(vector)
for cluster in clusters:
cluster_number.append(int(cluster))
get_top_keywords(vector, clusters, cv.get_feature_names(), 20)
Put together
Last , We're going to extract our data . Use what we've got before href list , Now it's time to apply all the extraction functions to web Time for content .
# Ergodic “browse” Extracted from href, Extract relevant content
iteration=1
# The first few functions depend on the original extracted web Content as a parameter . These are basic web Grabbing Technology .
for href in hrefs:
print('Web scraping: iteration',iteration,'/',len(hrefs))
page=requests.get(href)
soup=BeautifulSoup(page.text,'html.parser')
links.append(href)
get_date(soup)
get_title(soup)
get_contents(soup)
iteration+=1
# The following functions depend on the body of the text as parameters .
# These are based on nlp Function of .
# Be careful : Because of the external query API,
# Need a timeout to prevent server overload .
# This part of the code takes a long time to run .
get_countries(content_text)
get_coords(content_text)
get_people(content_text)
get_keywords(content_text)
get_topics(content_text)
Enrich the theme model
Our next question is : Our clusters provide us with a list of words associated with each cluster , But cluster names are just numbers . This gives us the opportunity to draw a word cloud or other interesting Visualization , It helps us understand each cluster , But for a clear understanding of structured data sets , It's not that useful . in addition , I think some documents may belong to more than one topic category .k-means Does not support multiclustering , So I had to identify these documents manually . First , I'm going to print the first few lines of keywords , To understand the data I'm working on .

Some keywords associated with each topic . We will use these keywords to classify clusters into predefined categories .
After a lot of experiments with various technologies , I decided to take a very simple approach . I scanned every keyword list associated with each cluster , And the important keywords are recorded in each keyword related to a specific topic . At this stage , Domain knowledge is the key . for example , That's true. ,ISW Aleppo in the document almost certainly refers to the Syrian civil war . For your data , If you lack the appropriate domain knowledge , You may need to do further research , Consult the rest of your team , Or define a more advanced programming method to name clusters .
However , For this example , The simple method works . After recording several important keywords in the cluster list , I made a few lists myself , It contains keywords associated with the final topic category I want in structured data . This function simply compares the keyword list of each cluster with the list I created , Then assign the topic name according to the match in the list . Then attach these final topics to the topic category list .
# Search the keyword list corresponding to the topic , Cross reference with clustered thesaurus , Assign a topic category to each article .
oir=['OIR Iraq','yezidis','mosul','peshmerga','isis','iraq','sinjar','baghdad','maliki',
'daquq','anbar','isf','abadi','malaki','ramadi','iraqi','fallujah','dabiq']
terrorism=['Terrorism','jihadi','islamic','salafi','qaeda',
'caliphate','isis','terrorist','terrorism']
syrian_conflict=['Syrian Conflict','sana','syria','assad',
'idlib','afrin','aleppo']
russia=['Russia','russia','belarus','slavic','kremlin','russian',
'minsk','ukraine','putin']
iran=['Iran','iran','iranian','proxy','militias','militia','marjah']
turkey=['Turkey','erdogan','turkish','turkey']
ors=['ORS','kabul','ghani','pakistan','afghan','afghanistan',
'taliban','ansf','karzai','helmand']
africa=['Africa','libya','libyan','egypt','egyptian','africa','african']
cat_list=[oir,terrorism,syrian_conflict,russia,iran,turkey,ors,africa]
topic_dict={}
for i in range(len(cluster_keywords)):
temp_list=[]
for n in nltk.word_tokenize(cluster_keywords[i]):
for item in cat_list:
if n in item:
temp_list.append(item[0])
temp_dict=dict.fromkeys(temp_list,0)
temp_list=list(temp_dict)
topic_dict[i] = temp_list
for num in cluster_number:
topic_categories.append(topic_dict[num])
Database creation
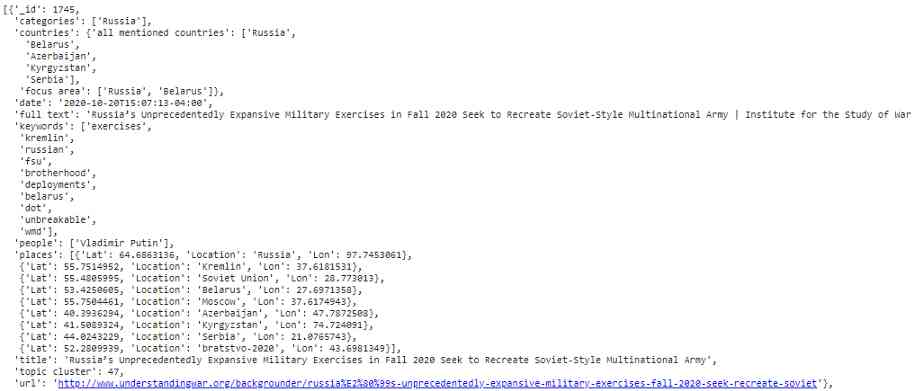
The last step is to aggregate all the data we extract . For these data , I prefer JSON Format . This is because I want to organize certain types of data in different ways — for example ,locations The field will contain the place name 、 Dictionary list of latitude and longitude . in my opinion ,JSON Format is the most effective way to store this formatted data on local disk . I'm still in the document database MongoDB A copy of this database is backed up in , But this is not the point of this article .
# Initialize an empty list
db=[]
for i in range(len(hrefs)):
countries={
'focus area': key_countries[i],
'all mentioned countries': mentioned_countries[i]
}
# Add all lists defined in the function to the new storage list
doc={
'_id': len(hrefs) - i,
'title': titles[i],
'date': dates[i],
'places': coord_list[i],
'people': people[i],
'keywords': keywords[i],
'countries': countries,
'full text': content_text[i],
'url': links[i],
'topic cluster': cluster_number[i],
'categories': topic_categories[i]
}
db.append(doc)
# Save the list as... In Google drive .JSON Data storage files ( For demonstration purposes )
with open ('/content/drive/My Drive/Colab Notebooks/isw_products.json', 'w') as fout:
json.dump(db, fout)
Abstract
Now we're done ! We extract links from web pages , Then use these links to extract more from the site . We use these things , And then use the external api、ML Clustering algorithm and NLP To extract and enhance this information .TF-IDF To quantify 、 Keyword extraction and topic model , These are NLP Cornerstone . If you have more questions or need information , Please contact us , Wish you in the future NLP Good luck !
Link to the original text :https://towardsdatascience.com/something-from-nothing-use-nlp-and-ml-to-extract-and-structure-web-data-3f49b2f72b13
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- [event center azure event hub] interpretation of error information found in event hub logs
- 使用 Iceberg on Kubernetes 打造新一代云原生数据湖
- 阿里云Q2营收破纪录背后,云的打开方式正在重塑
- ES6 essence:
- Working principle of gradient descent algorithm in machine learning
- What problems can clean architecture solve? - jbogard
- How to use parameters in ES6
- 一篇文章教会你使用Python网络爬虫下载酷狗音乐
- Python3 e-learning case 4: writing web proxy
- Advanced Vue component pattern (3)
猜你喜欢

Filecoin的经济模型与未来价值是如何支撑FIL币价格破千的

Mac installation hanlp, and win installation and use
Construction of encoder decoder model with keras LSTM
一篇文章带你了解CSS 渐变知识

git rebase的時候捅婁子了,怎麼辦?線上等……
Python基础变量类型——List浅析
一篇文章带你了解CSS3圆角知识
教你轻松搞懂vue-codemirror的基本用法:主要实现代码编辑、验证提示、代码格式化

What is the side effect free method? How to name it? - Mario
Python Jieba segmentation (stuttering segmentation), extracting words, loading words, modifying word frequency, defining thesaurus
随机推荐
加速「全民直播」洪流,如何攻克延时、卡顿、高并发难题?
ES6学习笔记(二):教你玩转类的继承和类的对象
Let the front-end siege division develop independently from the back-end: Mock.js
Summary of common algorithms of binary tree
Group count - word length
Nodejs crawler captures ancient books and records, a total of 16000 pages, experience summary and project sharing
Interface pressure test: installation, use and instruction of siege pressure test
Filecoin的经济模型与未来价值是如何支撑FIL币价格破千的
前端工程师需要懂的前端面试题(c s s方面)总结(二)
ES6学习笔记(五):轻松了解ES6的内置扩展对象
使用 Iceberg on Kubernetes 打造新一代云原生数据湖
Python filtering sensitive word records
Common algorithm interview has been out! Machine learning algorithm interview - KDnuggets
Just now, I popularized two unique skills of login to Xuemei
零基础打造一款属于自己的网页搜索引擎
Python download module to accelerate the implementation of recording
在大规模 Kubernetes 集群上实现高 SLO 的方法
Python基础数据类型——tuple浅析
Python saves the list data
如何玩转sortablejs-vuedraggable实现表单嵌套拖拽功能