当前位置:网站首页>Recommendation system based on deep learning
Recommendation system based on deep learning
2020-11-06 01:28:00 【Artificial intelligence meets pioneer】
author |James Loy compile |VK source |Towards Data Science
The traditional recommendation system is based on clustering 、 Nearest neighbor and matrix factorization . However , In recent years , Deep learning has achieved great success in many fields from image recognition to natural language processing . Recommendation systems also benefit from the success of deep learning . in fact , Today's most advanced recommendation system , such as Youtube and Amazon The recommendation system of , All driven by complex deep learning systems , Instead of the traditional method .
This tutorial
After reading a lot of useful tutorials , These tutorials introduce the basics of recommendation systems that use traditional methods such as matrix factorization , But I noticed , Lack of a tutorial on deep learning based recommendation system . In this tutorial , We will introduce the following :
-
How to use PyTorch Lightning Create your own recommendation system based on deep learning
-
The difference between implicit feedback and explicit feedback in recommendation system
-
How to train test segmented data set to train recommendation system without introducing bias and data leakage
-
Evaluate the indicators of the recommendation system ( Tips : Accuracy or RMSE Don't fit !)
Data sets
This tutorial USES MovieLens 20M Movie reviews provided by the dataset , This is a popular movie rating dataset , contain 1995 - 2015 Collected in 2000 Million movie reviews .
If you want to see the code in this tutorial , You can check mine Kaggle Notebook, Here you can run the code , And see the output in this tutorial :https://www.kaggle.com/jamesloy/deep-learning-based-recommender-systems
Using implicit feedback to build a recommendation system
Before we build the model , It's important to understand the difference between implicit feedback and explicit feedback , And why modern recommendation systems are based on implicit feedback .
Explicit feedback
In the recommendation system , Explicit feedback is collected directly from users 、 Quantitative data . for example , Amazon allows users to make 1-10 The score . These ratings are provided directly by users , This rating scale allows Amazon to quantify user preferences . Another example of explicit feedback includes YouTube Upper Fabulous / Step on Button , It captures a user's explicit preference for a particular video ( Like or dislike ).
However , The problem with explicit feedback is that they rarely . If you think about it , The last time you hit YouTube On the video “ like ” Button , Or when to rate your online shopping ? It's very likely that you are in YouTube The number of videos you watch on is far greater than the number of videos you explicitly rate .
Implicit feedback
On the other hand , Implicit feedback is received from the middle of user interaction , They act as proxies for user preferences . for example . you are here YouTube The video viewed on is used as implicit feedback , Make your own recommendations , Even if you don't explicitly rate the video . Another example of implicit feedback includes products you've browsed on Amazon , These products are used to recommend other similar projects to you .
The hidden advantage is that it's rich . The recommendation system built with implicit feedback also allows us to customize the recommendation in real time through each click and interaction . today , The online recommendation system is built using implicit feedback , It allows the system to adjust its recommendations in real time with each user interaction .
Data preprocessing
Before we start building and training our models , Let's do some preprocessing , In order to obtain the desired format MovieLens data .
In order to maintain 30% Is used within the user's manageable range , We will only use 30% Data set of . Let's choose at random 30% Users of , And only use the data of the selected user .
import pandas as pd
import numpy as np
np.random.seed(123)
ratings = pd.read_csv('rating.csv', parse_dates=['timestamp'])
rand_userIds = np.random.choice(ratings['userId'].unique(),
size=int(len(ratings['userId'].unique())*0.3),
replace=False)
ratings = ratings.loc[ratings['userId'].isin(rand_userIds)]
After filtering the dataset , Now there are from 41547 Of users 6027314 Row data ( It's still a lot of data !). Each line in the data frame corresponds to a single user's Movie Review , As shown below .
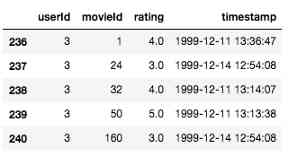
Training test split
Besides ratings , There's also a timestamp column , Displays the date and time of submission for review . Use timestamp Column , We will use the leave one method to implement our training test segmentation strategy . For each user , The latest scores are used as test sets ( namely , The number of samples in the test set is 1), And the rest will be used as training data .
To illustrate this point , user 39849 The films reviewed are as follows . The last movie users commented on was 2014 It's a hot year 《 Galactic guardian 》. We will use this movie as test data for this user , And use the rest of the films reviewed as training data .
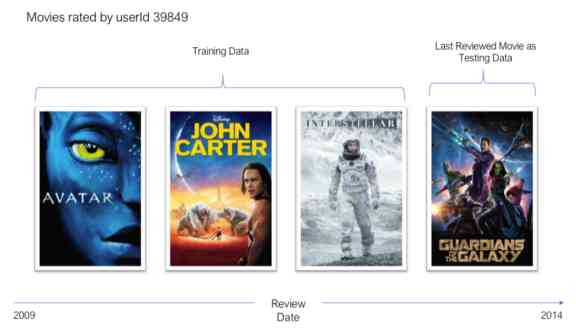
When training and evaluating the recommendation system , Use this training a lot - Test the segmentation strategy . It's not fair to do a random segmentation , Because we may use the user's recent comments for training , And use early reviews to test . This introduces data leakage with prospective bias , And the performance of the trained model cannot be summarized as the performance of the real world .
The following code will split our scoring dataset into a training and test set using the leave one method .
ratings['rank_latest'] = ratings.groupby(['userId'])['timestamp'].rank(method='first', ascending=False)
train_ratings = ratings[ratings['rank_latest'] != 1]
test_ratings = ratings[ratings['rank_latest'] == 1]
# Delete columns that we no longer need
train_ratings = train_ratings[['userId', 'movieId', 'rating']]
test_ratings = test_ratings[['userId', 'movieId', 'rating']]
Converting data sets to implicit feedback data sets
As mentioned earlier , We're going to use implicit feedback to train the recommendation system . However , What we use MovieLens Data sets are based on explicit feedback . To convert this dataset to an implicit feedback dataset , We just need to binarize the rating and convert it to “1”( That is, positive class ). value “1” Indicates that the user has interacted with the item .
It should be noted that , Using implicit feedback can redefine the problem our recommender is trying to solve . We're not trying to predict movie ratings when using timed feedback , It's trying to predict whether users will interact with each movie ( Click / Buy / watch ), The goal is to show users the movie with the highest interaction possibilities .
train_ratings.loc[:, 'rating'] = 1
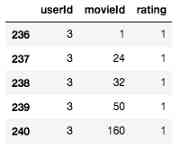
however , We do have problems right now . After binarizing the dataset , We see that every sample in the dataset is now a positive class . Let's assume that the rest of the movies are those that users are not interested in - Even if it's a broad assumption , It may not be true , It's usually pretty good practice .
The following code generates for each line of data 4 Negative samples . let me put it another way , The ratio of negative to positive samples is 4:1. This ratio is optional , But I find it works pretty well in practice ( You can find the best ratio on your own !).
# Get all the movies id A list of
all_movieIds = ratings['movieId'].unique()
# A place holder to hold training data
users, items, labels = [], [], []
# This is the set of projects that every user interacts with
user_item_set = set(zip(train_ratings['userId'], train_ratings['movieId']))
# 4:1
num_negatives = 4
for (u, i) in user_item_set:
users.append(u)
items.append(i)
labels.append(1) # Users interact with the project
for _ in range(num_negatives):
# Randomly select a project
negative_item = np.random.choice(all_movieIds)
# Check if the user has interacted with the project
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_movieIds)
users.append(u)
items.append(negative_item)
labels.append(0) # No interaction
Great ! We now have the data in the format required for the model . Before proceeding , Let's define one PyTorch Data sets , For training . The following class simply encapsulates the code written above into PyTorch In the dataset class .
import torch
from torch.utils.data import Dataset
class MovieLensTrainDataset(Dataset):
"""MovieLens PyTorch Data set for training
Args:
ratings (pd.DataFrame): Including movie ratings DataFrame
all_movieIds (list): Including all the movies id A list of
"""
def __init__(self, ratings, all_movieIds):
self.users, self.items, self.labels = self.get_dataset(ratings, all_movieIds)
def __len__(self):
return len(self.users)
def __getitem__(self, idx):
return self.users[idx], self.items[idx], self.labels[idx]
def get_dataset(self, ratings, all_movieIds):
users, items, labels = [], [], []
user_item_set = set(zip(ratings['userId'], ratings['movieId']))
num_negatives = 4
for u, i in user_item_set:
users.append(u)
items.append(i)
labels.append(1)
for _ in range(num_negatives):
negative_item = np.random.choice(all_movieIds)
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_movieIds)
users.append(u)
items.append(negative_item)
labels.append(0)
return torch.tensor(users), torch.tensor(items), torch.tensor(labels)
Our model - Neural collaborative filtering (NCF)
Although there are many recommendation system architectures based on deep learning , But I found that by He wait forsomeone (https://arxiv.org/abs/1708.05031) The proposed framework . Is the most direct , It's very simple , It can be implemented in such a tutorial .
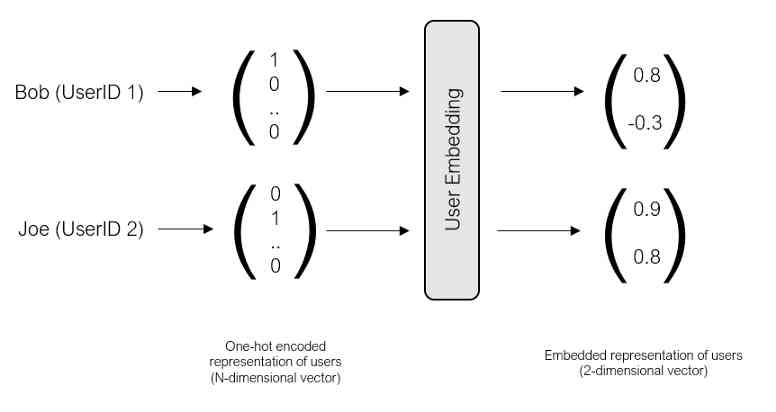
Users embed
Before delving into the architecture of the model , Let's familiarize ourselves with the concept of embeddedness . Embedding is a low dimensional space , It captures the relationships between vectors from high-dimensional space . To better understand the concept , Let's take a closer look at user embedding .
Suppose we want to represent users based on their preferences for both types of movies —— Action and romance . Let the first dimension be the user's love for action movies , The second dimension is the user's preference for romantic movies .
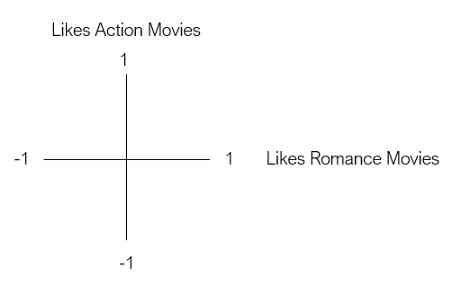
Now? , hypothesis Bob It's our first user . Bob likes action movies , But I don't like love movies . In order to Bob Expressed as a two-dimensional vector , We according to the Bob Put it in the diagram .
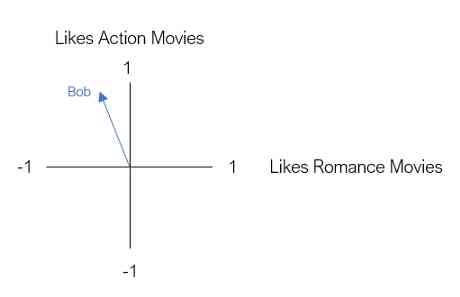
Our next user is Joe . Joe is a big fan of action and love movies . Let's use a two-dimensional vector to express Joe, It's like Bob equally .
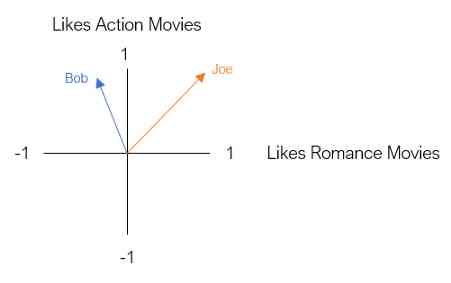
This two-dimensional space is called embedding . Essentially , Embedding reduces our users , So that they can be represented in a meaningful way in a low dimensional space . In this embedding , Users with similar movie preferences are close to each other , vice versa .
Of course , We are not limited to using only two dimensions to represent our users . We can use any number of dimensions to represent our users . A larger number of dimensions will allow us to capture more accurately the characteristics of each user , And the cost is the complexity of the model . In our code , We will use 8 Dimensions ( I'll see later ).
Learning to embed
Similarly , We will use a separate project embedding layer to represent the project ( Movie ) Features in low dimensional space .
You may want to know , How do we understand the weight of the embedded layer , So that it provides an accurate representation of users and projects ? In the previous example , We used Bob and Joe Preference for action and romantic movies to manually create embeddings . Is there any way to automatically learn this embedding ?
The answer is collaborative filtering —— By using hierarchical datasets , We can identify similar users and movies , Create user and project embeddings that learn from existing ratings .
Model architecture
Now that we have a better understanding of embeddedness , We can define the model architecture . As you will see , User and item embedding is the key to the model .
Let's use the following training example to explore the model architecture :

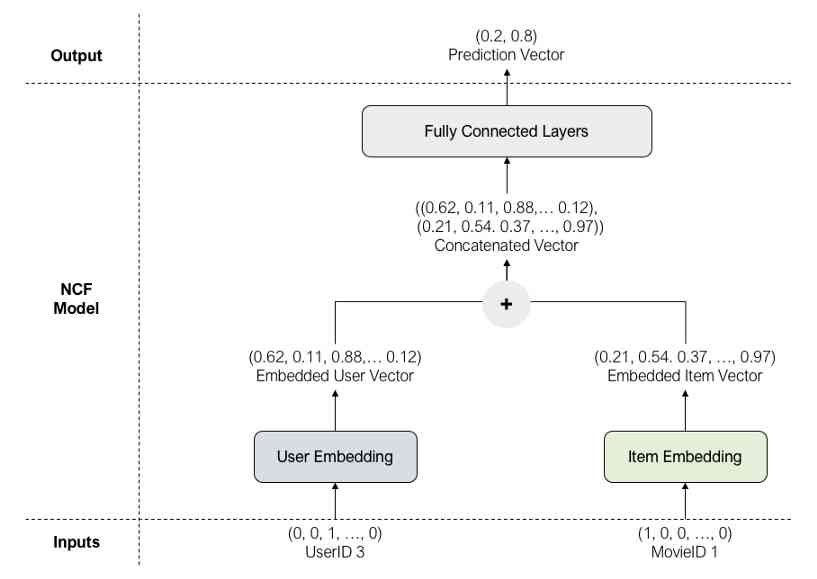
The input to the model is userId=3 and movieId=1 Of one-hot Encode user and term vectors . Because this is a positive sample ( The movie that the user actually rated ), So the label is 1.
User vector and item vector are input into user embedding and project embedding respectively , So you get smaller 、 More intensive user and project vectors .
Embedded user and item vectors are connected before passing through a series of fully connected layers , These layers map the connected embedding into a prediction vector as output . In the output layer , We use a Sigmoid Function to get the most likely class . In the example above , because 0.8>0.2, The most likely class is 1( Just like ).
Now? , Let's use it PyTorch Lightning To define this NCF Model !
import torch.nn as nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader
class NCF(pl.LightningModule):
""" Neural collaborative filtering (NCF)
Args:
num_users (int): The number of unique users
num_items (int): The number of unique items
ratings (pd.DataFrame): Contains movie ratings for training
all_movieIds (list): Contains all the movieIds A list of ( Training + test )
"""
def __init__(self, num_users, num_items, ratings, all_movieIds):
super().__init__()
self.user_embedding = nn.Embedding(num_embeddings=num_users, embedding_dim=8)
self.item_embedding = nn.Embedding(num_embeddings=num_items, embedding_dim=8)
self.fc1 = nn.Linear(in_features=16, out_features=64)
self.fc2 = nn.Linear(in_features=64, out_features=32)
self.output = nn.Linear(in_features=32, out_features=1)
self.ratings = ratings
self.all_movieIds = all_movieIds
def forward(self, user_input, item_input):
# Through the embedded layer
user_embedded = self.user_embedding(user_input)
item_embedded = self.item_embedding(item_input)
# Concat Two embedded layers
vector = torch.cat([user_embedded, item_embedded], dim=-1)
# Through the full connectivity layer
vector = nn.ReLU()(self.fc1(vector))
vector = nn.ReLU()(self.fc2(vector))
# Output layer
pred = nn.Sigmoid()(self.output(vector))
return pred
def training_step(self, batch, batch_idx):
user_input, item_input, labels = batch
predicted_labels = self(user_input, item_input)
loss = nn.BCELoss()(predicted_labels, labels.view(-1, 1).float())
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
def train_dataloader(self):
return DataLoader(MovieLensTrainDataset(self.ratings, self.all_movieIds),
batch_size=512, num_workers=4)
Let's use it GPU Train our NCF Model ,epoch=5
Be careful :PyTorch Lightning And vanilla PyTorch One advantage of comparison is , You don't have to write your own training code . Be careful Trainer How classes allow us to train our model with just a few lines of code .
num_users = ratings['userId'].max()+1
num_items = ratings['movieId'].max()+1
all_movieIds = ratings['movieId'].unique()
model = NCF(num_users, num_items, train_ratings, all_movieIds)
trainer = pl.Trainer(max_epochs=5, gpus=1, reload_dataloaders_every_epoch=True,
progress_bar_refresh_rate=50, logger=False, checkpoint_callback=False)
trainer.fit(model)
Evaluate our recommendation system
Now we've trained the model , We're going to use the test data to evaluate it . In traditional machine learning programs , We use things like accuracy ( For the classification problem ) and RMSE( For the return question ) Such a measure to evaluate our model . However , Such a measure is too simple to evaluate a recommendation system .
In order to design a good evaluation system of indicators , We first need to understand how modern recommendation systems are used .
have a look Netflix, We can see the following list of recommendations :
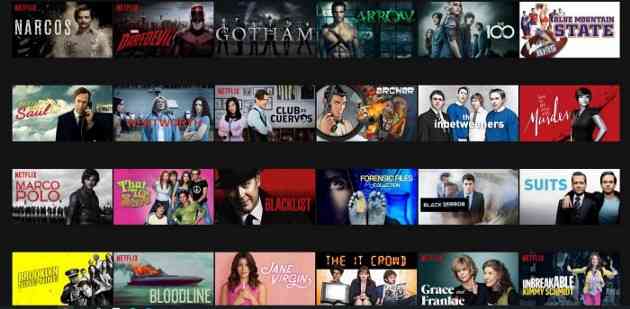
Again , Amazon gives :
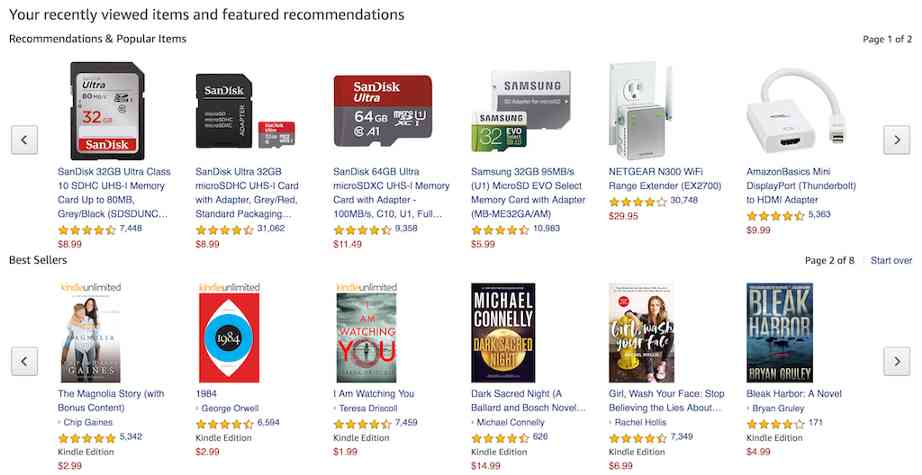
The key here is that we don't need users to interact with every item in the recommended list . At least we need the user to interact with an item in the list , At least we need to interact with the project .
To simulate this , Let's run the following evaluation protocol , Generate a front for each user 10 A list of recommended items .
-
For each user , Random selection 99 Projects that users don't interact with .
-
Will this 99 Projects and testing projects ( The actual project the user last interacted with ) Combine . We have 100 Pieces of .
-
For this 100 Project running model , And sort them according to their prediction probability .
-
from 100 Before selecting from the list of items 10 A project . If the test item appears before 10 Item in , So we think it's a hit .
-
Repeat this process for all users . The hit rate is the average hit rate .
This evaluation protocol is called shooting @10( Hit Ratio @ 10), Usually used to evaluate recommendation systems .
shooting @10
Now? , Let's use the protocol described to evaluate our model .
# Users for testing - Project pair
test_user_item_set = set(zip(test_ratings['userId'], test_ratings['movieId']))
# All the items that each user interacts with
user_interacted_items = ratings.groupby('userId')['movieId'].apply(list).to_dict()
hits = []
for (u,i) in test_user_item_set:
interacted_items = user_interacted_items[u]
not_interacted_items = set(all_movieIds) - set(interacted_items)
selected_not_interacted = list(np.random.choice(list(not_interacted_items), 99))
test_items = selected_not_interacted + [i]
predicted_labels = np.squeeze(model(torch.tensor([u]*100),
torch.tensor(test_items)).detach().numpy())
top10_items = [test_items[i] for i in np.argsort(predicted_labels)[::-1][0:10].tolist()]
if i in top10_items:
hits.append(1)
else:
hits.append(0)
print("The Hit Ratio @ 10 is {:.2f}".format(np.average(hits)))

We have a pretty good percentage @10! From the context , It means 86% 's users were recommended the actual project they eventually interacted with ( stay 10 Item list ). Pretty good !
next step
I hope this is a useful introduction , To create a recommendation system based on deep learning . To learn more , I suggest using the following resources :
- Wide & Deep Learning — Model introduced by Google for Recommender Systems(https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html)
- Recommenders library by Microsoft — Best practices for Recommender Systems(https://github.com/microsoft/recommenders)
- Deep Learning based Recommender Systems — Useful survey paper(https://arxiv.org/pdf/1707.07435.pdf)
Link to the original text :https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- 6.6.1 localeresolver internationalization parser (1) (in-depth analysis of SSM and project practice)
- Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
- 多机器人行情共享解决方案
- 每个前端工程师都应该懂的前端性能优化总结:
- 5.5 controlleradvice notes - SSM in depth analysis and project practice
- 教你轻松搞懂vue-codemirror的基本用法:主要实现代码编辑、验证提示、代码格式化
- Group count - word length
- What is the side effect free method? How to name it? - Mario
- How long does it take you to work out an object-oriented programming interview question from Ali school?
- html
猜你喜欢

前端基础牢记的一些操作-Github仓库管理
Filecoin最新动态 完成重大升级 已实现四大项目进展!
Can't be asked again! Reentrantlock source code, drawing a look together!
一篇文章带你了解CSS 分页实例

Arrangement of basic knowledge points
阿里云Q2营收破纪录背后,云的打开方式正在重塑
有了这个神器,快速告别垃圾短信邮件
小程序入门到精通(二):了解小程序开发4个重要文件
NLP model Bert: from introduction to mastery (2)
Do not understand UML class diagram? Take a look at this edition of rural love class diagram, a learn!
随机推荐
Aprelu: cross border application, adaptive relu | IEEE tie 2020 for machine fault detection
Mac installation hanlp, and win installation and use
容联完成1.25亿美元F轮融资
I think it is necessary to write a general idempotent component
Analysis of react high order components
Network security engineer Demo: the original * * is to get your computer administrator rights! 【***】
一篇文章带你了解CSS3圆角知识
Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)
Electron application uses electronic builder and electronic updater to realize automatic update
Summary of common algorithms of linked list
It's so embarrassing, fans broke ten thousand, used for a year!
100元扫货阿里云是怎样的体验?
嘗試從零開始構建我的商城 (二) :使用JWT保護我們的資訊保安,完善Swagger配置
PN8162 20W PD快充芯片,PD快充充电器方案
Python + appium automatic operation wechat is enough
Classical dynamic programming: complete knapsack problem
有了这个神器,快速告别垃圾短信邮件
PHPSHE 短信插件说明
Filecoin最新动态 完成重大升级 已实现四大项目进展!
Skywalking series blog 5-apm-customize-enhance-plugin