当前位置:网站首页>[I'm a mound pytorch tutorial] learning notes
[I'm a mound pytorch tutorial] learning notes
2022-07-02 12:15:00 【therrrr】
边栏推荐
- Brush questions --- binary tree --2
- lombok常用注解
- 计算二叉树的最大路径和
- Full link voltage measurement
- [QT] Qt development environment installation (QT version 5.14.2 | QT download | QT installation)
- Day12 control flow if switch while do While guessing numbers game
- Natural language processing series (II) -- building character level language model using RNN
- 自然语言处理系列(一)——RNN基础
- Differences between nodes and sharding in ES cluster
- 单指令多数据SIMD的SSE/AVX指令集和API
猜你喜欢

The blink code based on Arduino and esp8266 runs successfully (including error analysis)
基于Arduino和ESP8266的Blink代码运行成功(包含错误分析)

5g era, learning audio and video development, a super hot audio and video advanced development and learning classic

PyTorch nn. Full analysis of RNN parameters
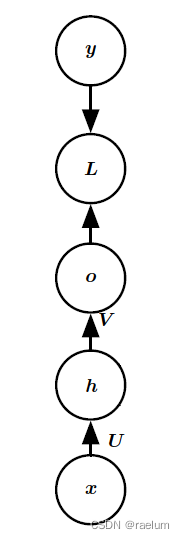
Natural language processing series (I) -- RNN Foundation

Go learning notes - multithreading
CDH存在隐患 : 该角色的进程使用的交换内存为xx兆字节。警告阈值:200字节

SVO2系列之深度濾波DepthFilter
![[C language] convert decimal numbers to binary numbers](/img/9b/1848b68b95d98389ed985c83f2e856.png)
[C language] convert decimal numbers to binary numbers

测试左移和右移
随机推荐
中国交通标志检测数据集
计算二叉树的最大路径和
单指令多数据SIMD的SSE/AVX指令集和API
Deep understanding of P-R curve, ROC and AUC
Take you ten days to easily finish the finale of go micro services (distributed transactions)
SCM power supply
基于Arduino和ESP8266的Blink代码运行成功(包含错误分析)
基于Arduino和ESP8266的连接手机热点实验(成功)
求16以内正整数的阶乘,也就是n的阶层(0=<n<=16)。输入1111退出。
CDA data analysis -- Introduction and use of aarrr growth model
Jenkins voucher management
[untitled] how to mount a hard disk in armbian
(C language) input a line of characters and count the number of English letters, spaces, numbers and other characters.
How does Premiere (PR) import the preset mogrt template?
drools执行String规则或执行某个规则文件
Discrimination of the interval of dichotomy question brushing record (Luogu question sheet)
LeetCode—剑指 Offer 37、38
(C语言)八进制转换十进制
Brush questions --- binary tree --2
On data preprocessing in sklearn