当前位置:网站首页>Benchmarking Detection Transfer Learning with Vision Transformers(2021-11)
Benchmarking Detection Transfer Learning with Vision Transformers(2021-11)
2022-07-07 21:52:00 【GY-赵】

这篇文章是何凯明在MAE之后关于纯transformer架构用于目标检测下游任务的探索,在MAE最后有所提及,之后还有一篇文章ViTDET一脉相承。对于VIT架构用于视觉任务带来了很多启发。
简介
目标检测作为一个中心的下游任务经常用来测试预训练模型的性能,例如训练速度或者精度等。当新的架构如VIT出现时,目标检测任务的复杂性使得这种基准测试变得更加重要。事实上,一些困难(如架构不兼容、训练缓慢、内存消耗高、未知的训练公式等)阻碍了VIT迁移到目标检测任务研究。论文提出了使用VIT作为Mask RCNN backbone,实现了最初的研究目的:作者对比了五种VITs初始化,包括自监督学习方法、监督初始化以及较强的随机初始化baseline。
无监督/自监督深度学习是常用的预训练方法用来初始化模型参数,之后他们迁移到下游任务,例如图像分类和目标检测进行finetune。无监督算法的有效性常常使用下游任务的指标(精度度、收敛速度等)来衡量与baseline作一个比较,例如有监督预训练或者 从头训练的网络(不适用预训练).
视觉领域的无监督深度学习通常使用CNN模型,因为CNNs广泛用于大部分下游任务,因此基准原型很容易被定义,可以将使用CNN的无监督算法视为一种即插即用的参数初始化模型。
论文使用Mask RCNN框架评估ViT模型在目标检测和语义分割领域COCO数据集上的性能,对ViT作最小程度的修改,保留它的简单、灵活的特性。
结论
论文给出了在Mask RCNN架构中使用VIT基础模型作为backbone的有效方法。这些方法在训练内存和时间上都可以被接受,同时没有使用太多复杂扩展的情况下实现了COCO的强大效果。
- 得到了有效的训练公式,能够对五种不同的ViT初始化方法进行基准测试。实验表明,Random initation花费的时间比任何pre-training 的初始化都要长4倍,但获得了比ImageNet-1k监督前训练更高的AP。MoCo v3,对比无监督学习的代表性算法,表现出了与监督预训练几乎相同的性能(但比随机初始化更差)。
- 重要的是,一个令人兴奋的新结果:基于mask的方法(BEiT和MAE)在监督和随机初始化方面显示出了相当可观的增益,这些增益随着模型大小的增加而增加。基于supervise的初始化和基于MoCo v3的初始化都没有观察到这种sacling 行为。
VIT backbone
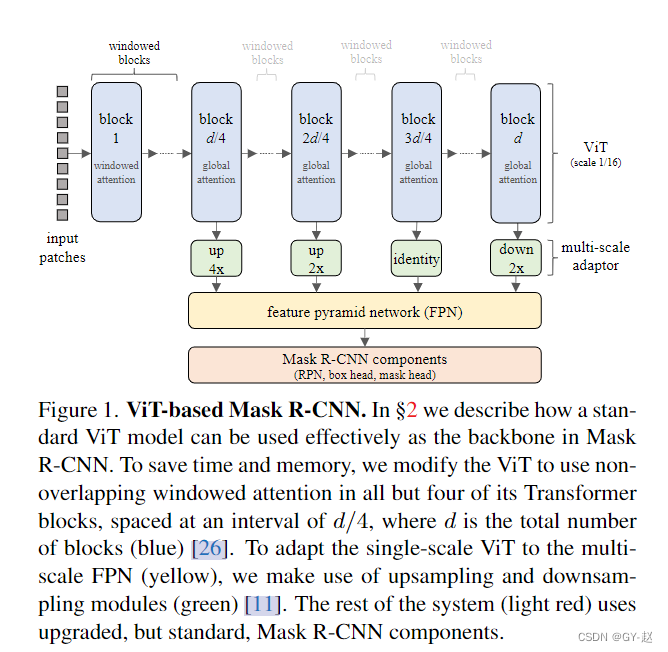
使用ViT 作为Mask RCNN 的backbone有两个问题:
- 怎样使它与FPN协同(ViT产生单一尺度的feature map)
- 如何减少内存消耗和运行时间
针对第1点:
为了适应FPN的多尺度输入,对ViT中间层产生的feature map通过四个不同分辨率的模块进行上采样或者下采样产生多尺度特征,如上图所示绿色module,这四个模块之间的间隔都为 d 4 \frac{d}{4} 4d, d d d是transformer blocks的数目,也就是等间隔划分。
- 第一个绿色module,通过使用两个stride-two 的 2 × 2 2 \times 2 2×2的转置卷积对特征映射进行4倍上采样,首先使用一个 2 × 2 2 \times 2 2×2转置卷积,然后通过Group Normaliztion ,再经过一个Gelu非线性函数,接着再使用一个stride-two 2 × 2 2 \times 2 2×2转置卷积.
- 接下来的 d 4 \frac{d}{4} 4dblock 采用一个stride-two 2 × 2 2 \times 2 2×2转置卷积进行2倍上采样,不使用归一化和非线性函数。
- 第三个 d 4 \frac{d}{4} 4dblock 输出不做任何变化
- 最后一个block进行stride为2 的 2 × 2 2 \times 2 2×2的max pooling 两倍下采样。
这些module,每一个都保留了ViT的Embeding/channel 维度,对于一个size =16 的patch 来说产生的feature map stride 分别为4,8,16,32,然后输入FPN。(因为原始的ViT 产生的feature 大小为input 1 16 \frac{1}{16} 161,上采样下采样后就是论文所说的大小)
针对第2点:
ViT中每一个self-attention计算具有 O ( h 2 w 2 ) O(h^2w^2) O(h2w2)的空间复杂度,以及把图像展开成不重叠的 h × w h \times w h×w的patches花费的时间。
在预训练的时候这种复杂度是可控的,因为一般图像大小为 224 × 224 224 \times 224 224×224,patch大小为 16 16 16, h = w = 14 h=w=14 h=w=14这是典型设置。但是在目标检测下游任务中,标准图像大小为 1024 × 1024 1024 \times 1024 1024×1024,这通常是预训练像素以及patch的20倍大,这么大的分辨率也是为了检测较大和较小目标所需要的。因此这种情况下,即使是以ViT-base作为Mask RCNN的backbone,在小批量和半精度浮点数的情况下通常也需要消耗20-30GB的GPU内存。
为了减少空间和时间复杂度,采用受限制的self-attention(也叫 windowed self-attention)(来源于attention is all you need ,没印象,要去查一下,第一印象是Swin的window attention)。将 h × w h \times w h×w的拼接图像划分为 r × r r \times r r×r个不重叠的窗口,在每个窗口单独计算self-attention。这种windowed self-attention 拥有 O ( r h 2 w 2 ) O(rh^2w^2) O(rh2w2)的空间和时间复杂度。设置 r 为全局自注意力的尺寸,典型值为14。(共有 h r × w r 个 w i n d o w s , 每 个 w i n d o w 拥 有 O ( r 2 ) 复 杂 度 \frac{h}{r} \times \frac{w}{r}个windows,每个window拥有O(r^2)复杂度 rh×rw个windows,每个window拥有O(r2)复杂度)。
这种做法的一个副作用就是window之间没有跨窗口信息交互,因此采用了一种混合方法,就像图中所示,包含4个全局自注意力模块,与FPN相吻合,这里也就是作者所说的添加额外部分使VIT产生多尺度特征。
对Mask RCNN module的修改
- FPN中的卷积使用Batch Normalization
- 在RPN中使用两个卷积层而不是一个
- region-of-interest (RoI) classification and box regression head之后的全连接层使用四个带有batch normal的卷积层取代原有的带有Normalization的两层MLP。
- 遵循在标准mask head中的卷积使用Batch Normal
修改代码位于:https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md #new-baselines-using-large-scale-jitter-and-longer-training-schedule
采用不同预训练方法的差异
- 不同预训练采用的epoch不一样,每一个epoch训练cost也不一样,论文采用了各个方法默认的epoch,显然这些方法不具有可比性。
- BEiT使用可学习的realtive positional bias添加到每个块的自我注意logits中,而其他方法使用绝对位置嵌入。为了解释这一点,作者在所有检测模型中都包含了相对位置偏差和绝对位置嵌入,无论它们在训练中是否使用。对于BEiT,作者迁移pre-trained bias,并随机初始化绝对位置嵌入。对其他方法,relative positional bias 进行零初始化,并迁移预训练的绝对位置嵌入。相对位置偏差在across windowed attention blocks和(单独)在across global attention blocks中共享。当预训练和微调之间存在空间维度不匹配时,我们将调整预训练参数的大小,使其达到所需的分辨率。
- BEiT在训练中使用了layer scale,而其他方法没有使用。在微调过程中,Beit初始化的模型也必须参数化使用来自预训练模型的layer scale,其他模型在训练前或微调时都不使用layer scale。
- 作者试图将训练前的数据标准化到ImageNet1k,然而,BEiT使用DALL·E、discrete VAE (dVAE),这是在约2.5亿专有和未公开的图像上训练的。这些额外的训练数据的影响还没有被完全理解。
实验部分
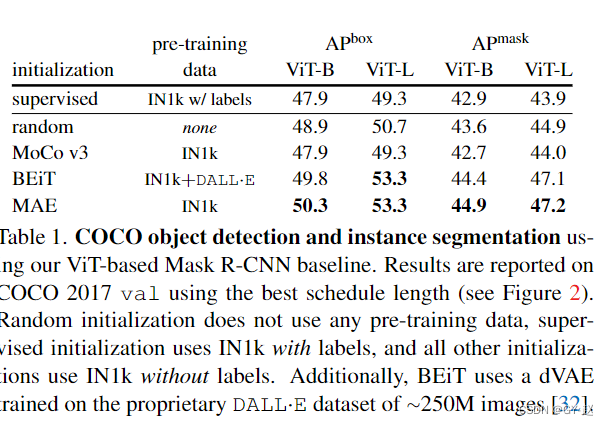
- 初始化方法的比较,随机初始化是没有预训练的。
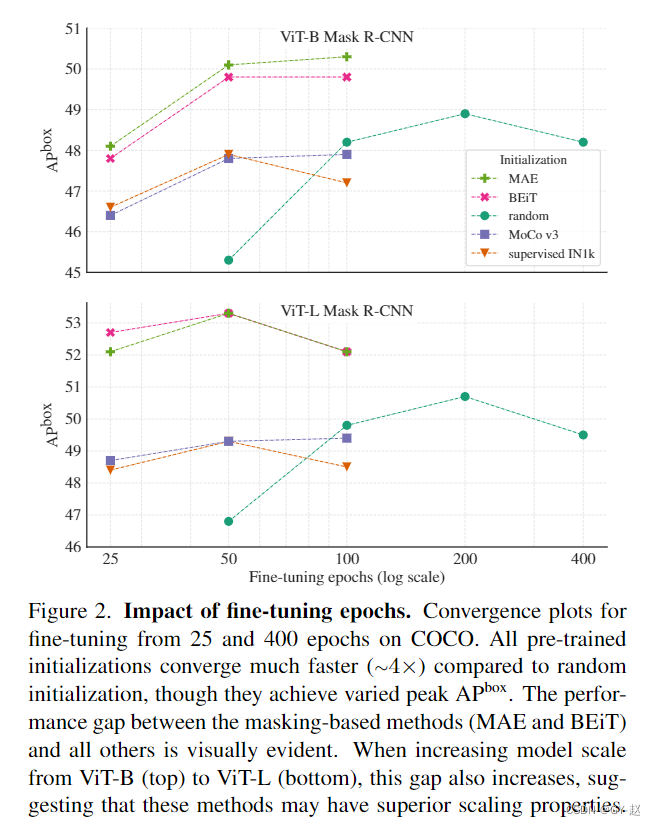
- finetune epoch 从25-400的收敛比较,可以看到任何一种方法收敛都要比随机初始化快,并且各种方法取得的AP各不相同,其中MAE与BeiT类似,但显然ViT-B比起ViT-L 与BeiT的差距更大,这是随着模型尺寸增大而增大的,表明他们具有很强的伸缩性。
大部分方法在长时间训练后,都表现出了过拟合迹象,AP值有所下降,同时观察到随机初始化方法的AP要高于MoCo V3 和有监督的IN1k,这是因为COCO数据集对于迁移学习来说是一个有挑战性的设置,因此随机初始化可能取得较好的性能。MAE和BEiT提供了第一个令人信服的结果,基于预训练COCO AP得到极大改善,并且随着模型尺寸增大AP还有很大的提升潜能。
消融实验

- 基于FPN的多尺度以及单一尺度的变种 对比。

- 减少时间和内存消耗的策略对比,有四种方案。
- 用 14 × 14 14 \times 14 14×14window self-attention 代替全部Global attention
- 混合使用attention
- 全部使用Global attention with activation checkpointing
- 不使用以上策略 ,会报错 out-of-memory (OOM) error阻止训练。
第二个方案在精度和训练时间以及内存方面取得较好的平衡,令人惊讶的是全部使用window attention表现并没有那么糟糕。这可能是由于卷积操作引入的跨窗口计算以及在Mask R-CNN的RoI Align的其余部分导致的。
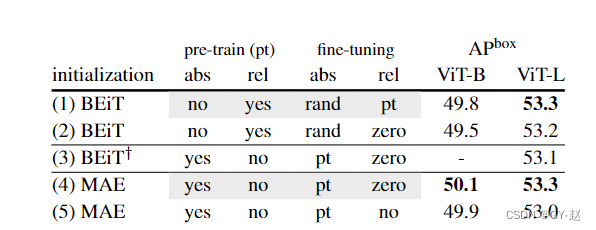
- 位置信息的影响。
-在BEiT中VIT被修改为在每一个transformer block中使用realtive positional bias,而不是添加absolute positional Embeeding 到Patch embeeding。这种选择是一种正交增强,其他预训练方法都没有使用。
为了公平比较,默认在所有微调模型中包括relative positional bias(和绝对位置嵌入)。
表格中含义
relative position biases (rel)
absolute position embeddings (abs)
pt: initialized with pre-trained values;
rand: random initialization;
zero: initialized at zero;
no: this positional information is not used in the fine-tuned model
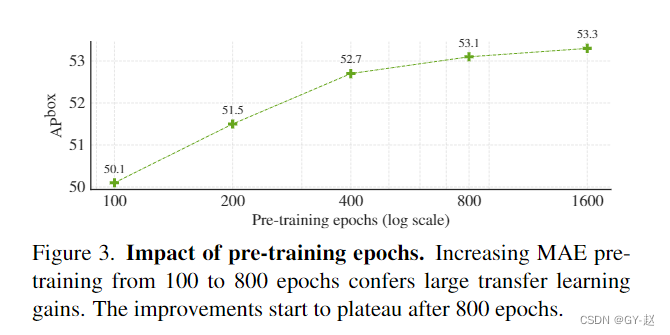
- 预训练epoch的影响。随着epoch增大,AP也增大。
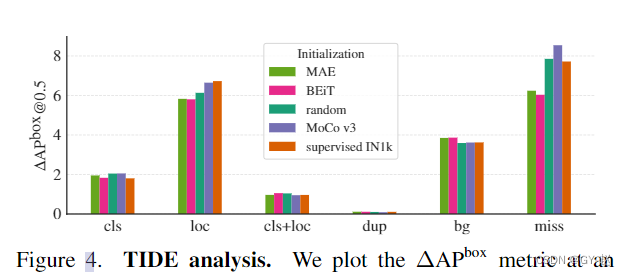
- 绘制了 Δ A P b o x @ 0.5 \Delta AP^{box}@0.5 ΔAPbox@0.5的指标。每一条代表修正某种错误后可以提升的 A P AP AP值。
cls:定位正确(IoU>0.5),分类错误
loc:分类正确但是定位错误 (IoU in [0.1, 0.5))
cls+loc: 分类和定位都出错
dup: detection would be correct if not for a higher scoring correct detection
bg: detection is in the background (IoU <0.1)
miss: all undetected ground-truth objects not covered by other error types.
基于mask的方法(MAE /BEiT)比起MoCo V3和有监督初始化方法有更少的定位错误,漏检次数也更少。
- 模型复杂度。从头开始训练时,ResNet101 与ViT-B都取得了48.9 A P b o x AP^{box} APbox,在训练中VIT-B训练200个epoch就达到了峰值,ResNet-101要400个epoch.ResNet-101的fps明显更快。
边栏推荐
- 648. Word replacement
- Progress broadcast | all 29 shield machines of Guangzhou Metro Line 7 have been launched
- SAP HR labor contract information 0016
- Senior programmers must know and master. This article explains in detail the principle of MySQL master-slave synchronization, and recommends collecting
- Lm12 rolling heikin Ashi double K-line filter
- Open source hardware small project: anxinco esp-c3f control ws2812
- USB (XIV) 2022-04-12
- Explain
- Markdown
- C cat and dog
猜你喜欢

Class C design questions
SAP HR 社会工作经历 0023

B_QuRT_User_Guide(38)
![Balanced binary tree [AVL tree] - insert, delete](/img/1f/cd38b7c6f00f2b3e85d4560181a9d2.png)
Balanced binary tree [AVL tree] - insert, delete
Anxinco esp32-a1s development board is adapted to Baidu dueros routine to realize online voice function

Home appliance industry channel business collaboration system solution: help home appliance enterprises quickly realize the Internet of channels

Markdown

LM12丨Rolling Heikin Ashi二重K线滤波器
Lm12 rolling heikin Ashi double K-line filter

The file format and extension of XLS do not match
随机推荐
家用电器行业渠道商协同系统解决方案:助力家电企业快速实现渠道互联网化
B_QuRT_User_Guide(37)
B_ QuRT_ User_ Guide(37)
Spark 离线开发框架设计与实现
8.31 Tencent interview
ASP. Net query implementation
[stm32+esp8266 connect Tencent cloud IOT development platform 2] stm32+esp8266-01s connect Tencent cloud
Anxin can internally test offline voice module vb-01 to communicate with esp-c3-12f
Given an array, such as [7864, 284, 347, 7732, 8498], now you need to splice the numbers in the array to return the "largest possible number."
Mobile heterogeneous computing technology - GPU OpenCL programming (basic)
做自媒体视频剪辑怎么赚钱呢?
The 19th Zhejiang Provincial College Programming Contest VP record + supplementary questions
Windows set redis to start automatically
【leetcode】day1
SAP HR奖罚信息导出
POJ2392 SpaceElevator [DP]
Deep understanding of MySQL lock and transaction isolation level
windows设置redis开启自动启动
C method question 1
Possible SQL for Oracle table lookup information