当前位置:网站首页>MySQL Index Optimization Practice I
MySQL Index Optimization Practice I
2022-07-07 23:23:00 【Which floor do you rate, moto】
Catalog
The range of the first field of the joint index will not go through the index
like kk% The index will be used regardless of the size of the table data
Why range lookup Mysql No index push down optimization
Mysql How to choose the right index
common sql In depth optimization
Using filesort Detailed explanation of document sorting principle
How to choose which method to use
The union index tries to cover the conditions
Don't index small cardinal fields
We can use prefix index for long strings
where And order by Conflicts are limited where
Comprehensive case
The range of the first field of the joint index will not go through the index
The first field of the joint index is searched by range, and the index will not be used ,mysql Internally, you may think that the first field is a range , The result set should be large , The meter return efficiency is not high , You might as well scan the whole table ( It can be analyzed from the figure , It may be used to change the union index, but it doesn't work in the end , Internal optimization , In this case, it is not recommended to force the use of indexes )
In the case of , You can go Overlay index perhaps Force index

<!-- Use the first of the three joint indexes or direct full table scan -->
EXPLAIN SELECT * FROM employees WHERE NAME > 'xxx' AND age = 22 AND POSITION = 'xxx';
<!-- Use the first two of the three federated indexes -->
EXPLAIN SELECT * FROM employees WHERE NAME = 'xxx' AND age > 22 AND POSITION = 'xxx';
<!-- Use three of the three federated indexes -->
EXPLAIN SELECT * FROM employees WHERE NAME = 'xxx' AND age = 22 AND POSITION = 'xxx';
<!-- Use three of the three federated indexes -->
EXPLAIN SELECT * FROM employees WHERE NAME = 'xxx' AND age = 22 AND POSITION = 'xxx';
Force Index

- Although the forced index is used, the first field range lookup of the joint index also goes through the index , Scanning line rows It looks a little less , However, the final search efficiency is not necessarily higher than that of full table scanning , Because the meter return efficiency is not high
Coverage index optimization

in and or When the amount of table data is large, the index will be taken , When there are few table records, full table scanning will be selected
- Large amount of data

- Small amount of data

like kk% The index will be used regardless of the size of the table data
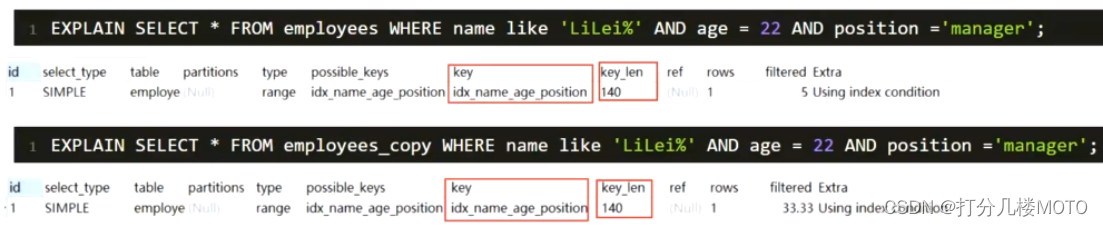
Index push down
- like kk% Index push down optimization is used
- For auxiliary federated indexes (name,age,position), Normally, the leftmost prefix is used SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager' This situation will only go name Field index , Because according to name After filtering the fields , In the resulting index line age and position Is chaotic , Can't make good use of indexes .
- stay MySQL5.6 Previous version , This query can only match the name in the union index 'LiLei' The index at the beginning , Then take the primary keys corresponding to these indexes back to the table one by one , Find the corresponding record in the primary key index , Compare again age and position Whether the values of these two fields match .
- MySQL 5.6 Index push down optimization is introduced , During index traversal , Judge all the fields contained in the index first , Filter out the unqualified records before returning to the table , It can effectively reduce the times of returning to the table . After using index push down optimization , The name that the query above matches in the union index is 'LiLei' After the first index , It also filters in the index age and position These two fields , Take the primary key corresponding to the filtered index id Then go back to the table to check the whole row of data .
- Index push down will reduce the number of table returns , about innodb The table index push down of the engine can only be used for secondary indexes ,innodb Primary key index of ( Cluster index ) The tree leaf node stores the entire row of data , Therefore, index push down will not reduce the effect of querying the whole row of data at this time .
Why range lookup Mysql No index push down optimization
- Should be Mysql The result set of the range lookup filter is considered too large ,like kk% In most cases , The filtered result set is relatively small , therefore Mysql Choose to give like kk% Push down with index
Mysql How to choose the right index

- If you use name The index needs to be traversed name Field union index tree , Then we need to go to the primary key index tree according to the traversal primary key value, and then find out the final data , It costs more than a full table scan , You can use overlay index optimization , It's just traversal name The joint index book of fields can get all the results
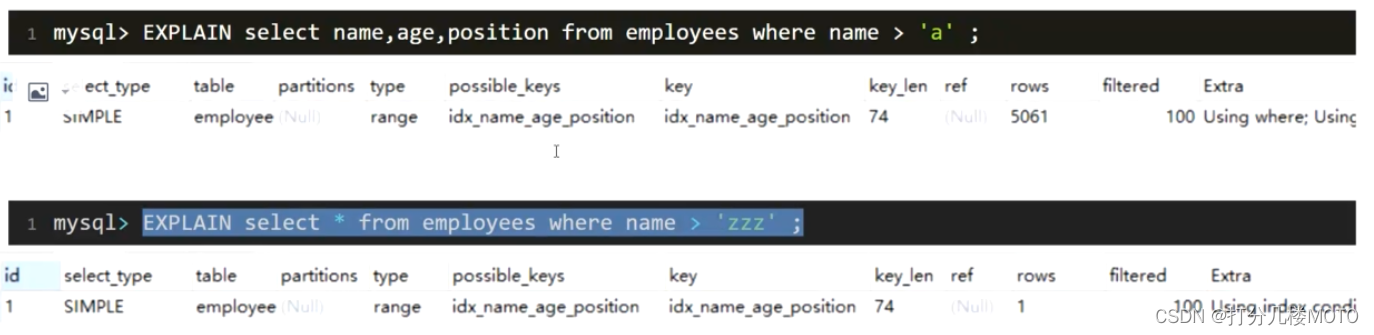
- For the two above name>'a' and name>'zzz' The results of the implementation of ,mysql Finally, whether to choose to go through the index or design multiple indexes for one table ,mysql How to choose index finally , We can use trace Tools analysis
open trace
SET SESSION optimizer_trace="enabled=on",end_markers_in_json=ON;
SELECT * FROM employees WHERE NAME > 'a' ORDER BY POSITION;
SELECT * FROM information_schema.optimizer_traceclose trace
SET SESSION optimizer_trace="enabled=off"
- result
{
"steps": [
{
"join_preparation": { The first stage :sql Preparation stage , format sql
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'a') order by `employees`.`position` limit 0,1000"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { The second stage :sql Optimization stage
"select#": 1,
"steps": [
{
"condition_processing": { Conditional processing
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'a')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`employees`.`name` > 'a')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`employees`.`name` > 'a')"
}
] /* steps */
} /* condition_processing */
},
{
"substitute_generated_columns": {
} /* substitute_generated_columns */
},
{
"table_dependencies": [ Table dependency details
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ Estimate the access cost of the table
{
"table": "`employees`",
"range_analysis": {
"table_scan": { Full table scanning
"rows": 1, Number of scanning lines
"cost": 2.45 Query cost
} /* table_scan */,
"potential_range_indexes": [ Query possible indexes
{
"index": "PRIMARY", primary key
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_ name_ age_ position", Secondary index
"usable": true,
"key_parts": [
"name",
"age",
"position",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "idx_ name_ age_ position",
"usable": false,
"cause": "query_references_nonkey_column"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": { Analyze the cost of using each index
"range_scan_alternatives": [
{
"index": "idx_ name_ age_ position",
"ranges": [
"a < name" Index usage scope
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false, Whether the records obtained by this index are sorted by primary key
"using_mrr": false,
"index_only": false, Whether to use overlay index
"rows": 1, Number of index scan lines
"cost": 0.61, Index usage cost
"chosen": true Whether to select the index
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "idx_ name_ age_ position",
"rows": 1,
"ranges": [
"a < name"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`employees`",
"best_access_path": { Left and right access paths
"considered_access_paths" : [ Final access path
{
"rows_to_scan": 1,
"filtering_effect": [
] /* filtering_effect */,
"final_filtering_effect": 1,
"access_type": "range", The model text type is range
"range_details": {
"used_index": "idx_ name_ age_ position"
} /* range_details */,
"resulting_rows": 1,
"cost": 0.71,
"chosen": true, Determine the choice
"use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 1,
"cost_for_plan": 0.71,
"sort_cost": 1,
"new_cost_for_plan": 1.71,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`employees`.`name` > 'a')",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`employees`",
"attached": "(`employees`.`name` > 'a')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"optimizing_distinct_group_by_order_by": {
"simplifying_order_by": {
"original_clause": "`employees`.`position`",
"items": [
{
"item": "`employees`.`position`"
}
] /* items */,
"resulting_clause_is_simple": true,
"resulting_clause": "`employees`.`position`"
} /* simplifying_order_by */
} /* optimizing_distinct_group_by_order_by */
},
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "ORDER BY",
"steps": [
] /* steps */,
"index_order_summary": {
"table": "`employees`",
"index_provides_order": false,
"order_direction": "undefined",
"index": "idx_ name_ age_ position",
"plan_changed": false
} /* index_order_summary */
} /* reconsidering_access_paths_for_index_ordering */
},
{
"finalizing_table_conditions": [
{
"table": "`employees`",
"original_table_condition": "(`employees`.`name` > 'a')",
"final_table_condition ": "(`employees`.`name` > 'a')"
}
] /* finalizing_table_conditions */
},
{
"refine_plan": [
{
"table": "`employees`",
"pushed_index_condition": "(`employees`.`name` > 'a')",
"table_condition_attached": null
}
] /* refine_plan */
},
{
"considering_tmp_tables": [
{
"adding_sort_to_table": "employees"
} /* filesort */
] /* considering_tmp_tables */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": { The third stage :SQL Execution phase
"select#": 1,
"steps": [
{
"sorting_table": "employees",
"filesort_information": [
{
"direction": "asc",
"expression": "`employees`.`position`"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"limit": 1000,
"chosen": false,
"cause": "sort_is_cheaper"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": {
"memory_available": 262144,
"key_size": 40,
"row_size": 190,
"max_rows_per_buffer": 15,
"num_rows_estimate": 15,
"num_rows_found": 0,
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 0,
"sort_algorithm": "none",
"sort_mode": "<fixed_sort_key, packed_additional_fields>"
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
] /* steps */
}
common sql In depth optimization
Order by
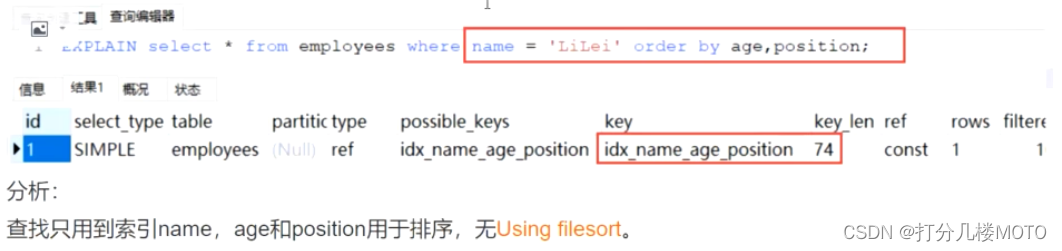
case1
- Using the leftmost prefix rule : The middle field cannot be broken , So the query uses name Indexes , from key_len=74 You can see ,age Index columns are used in sorting , because Extra There is no using filesort

case2

case3
case4

case5

case6

case7
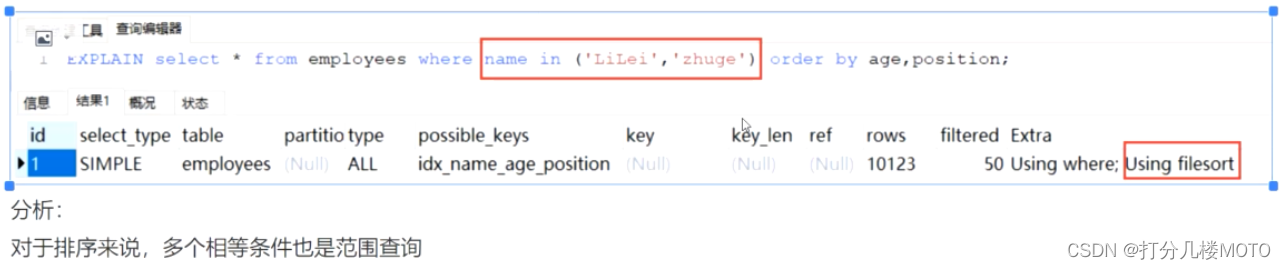
in If it is not in the sort query, it is possible to use the index , But the index must not be used in Sorting Query (in It will cause the following two fields to be out of order )
case8

- name > 'a' order by name: According to our understanding, we should take the index , It could be mysql I think the amount of data is too large , Moreover, the query field is all fields and needs to be returned to the table, so full table scanning and file sorting are used
Optimization summary
- Mysql Support two ways of sorting filesort and index,Using index Refer to Mysql Scan index itself to complete sorting ,index, Efficient ,filesort Low efficiency
- order by Meet two situations will use Using index
- order by The statement uses the left most front of the index
- Use where And mirror pairs order by The sentence conditions meet the leftmost row of the index
- Try to sort on the index columns , Follow index building ( The order in which the indexes are created ), The leftmost prefix rule of
- If order by The condition of is not on the index column , It will produce Using filesort
- Can use overlay index, try to use overlay index
- group by And odert by Very type , Its essence is to sort first and then group , Follow the leftmost prefix rule of index creation order . about group by If you don't need sorting, you can add order by null No sorting , Be careful where higher than having, It can be written in where Don't go to... If you have the qualifications in having Medium limit
Using filesort Detailed explanation of document sorting principle
filesort Sort files
- One way sorting : Retrieve all fields of the qualified row at one time , And then in sort buffer In order ; use trace Tools can see sort_mode The message shows <sort_key,additional_fields> perhaps <sort_key,packed_additional_fields>
- Two way sorting ( Back to table sorting mode ): First, according to the corresponding conditions, get the corresponding sorting fields and the... That can directly locate the data row ID( Get these fields from the result set of one-way sorting ), And then in sort buffer In order , After sorting, you need to retrieve other required fields again ; use trace Tools can see sort_mode The message shows <sort_key,rowid>
How to choose which method to use
By comparing system variables max_length_for_sort_data( The default is 1024 byte ) And the total size of the fields to be queried to determine which sort mode
If the total length of the field is less than max_length_for_sort_data, Use one-way sorting mode
If the total length of the field is greater than max_length_for_sort_data, Use two-way sorting mode
SET SESSION optimizer_trace="enabled=on",end_markers_in_json=ON;
SELECT * FROM employees WHERE NAME = 'xxx' ORDER BY POSITION;
SELECT * FROM information_schema.optimizer_trace{
"steps": [
{
"join_execution": { sql Execution phase
"select#": 1,
"steps": [
{
"sorting_table": "employees",
"filesort_information": [
{
"direction": "asc",
"expression": "`employees`.`position`"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"limit": 1000,
"chosen": true
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": { File sort information
"memory_available": 262144,
"key_size": 40,
"row_size": 186,
"max_rows_per_buffer": 1001,
"num_rows_estimate": 18446744073709551615,
"num_rows_found": 0,"num_of_tmp_files": 3, Number of temporary files used , If this value is 0 What represents all use is sort_buffer Memory sorting , Otherwise, use disk file sorting
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 194194,
"sort_algorithm": "none",
"unpacked_addon_fields": "using_priority_queue",
"sort_mode": "<fixed_sort_key, additional_fields>" sort order , One way sorting is used here
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
] /* steps */
}
- Let's first look at the detailed process of one-way sorting :
- From the index name Find the first satisfaction name = 'zhuge' The primary key of the condition id
- According to primary key id Take out the whole line , Take the values of all fields , Deposit in sort_ buffer in
- From the index name Find the next satisfaction name = 'zhuge' The primary key of the condition id
- Repeat step 2、3 Until not satisfied name = 'zhuge'
- Yes sort_ _buffer The data in is sorted by field position Sort
- Returns the result to the client
- Let's look at the detailed process of two-way sorting :
- From the index name Find the first satisfaction name = 'zhuge' Primary key of id
- According to primary key id Take out the whole line , Put the sort field position And the primary key id These two fields are placed in sort buffer in
- From the index name Take down a satisfaction name =‘'zhuge' The primary key of the record id
- repeat 3、4 Until not satisfied name = 'zhuge'
- Yes sort_ buffer In the field position And the primary key id According to the field position Sort
- Traversal sort ok id And field position, according to id Return to the original table, take out the values of all fields and return them to the client
- In fact, compare the two sorting modes , One way sorting will put all the fields to be queried into sort buffer in , The two-way sorting will only put the primary key and the fields to be sorted into sort buffer In order , Then return to the fields required by the original table query through the primary key . If MySQL Sort memory sort_ buffer The configuration is relatively small and there are no conditions to continue to increase , You can put max_ _length_ for_ _sort_ _data Configure small points , Let the optimizer choose to use the two-way sorting algorithm , Can be in sort_ buffer in - - Sort more rows at a time , You just need to go back to the original table to get data according to the primary key . If MySQL Sorting memory can be configured conditionally, which is relatively large , It can be increased appropriately max_ length_ for_ sort. _data Value , Let the optimizer prioritize full field sorting ( One way sorting ), Put the required fields in sort _buffer in , After sorting, the query results will be returned directly from memory . therefore ,MySQL adopt max_ _length_ _for_ sort_ data This parameter controls the sorting , Use different sorting modes in different scenarios , So as to improve the sorting efficiency .
- Be careful : If you use it all sort_ _buffer Memory sort one In general, the efficiency will be higher than that of magnetic Disk file sorting , But you can't just increase because of this sort_ _buffer( Default 1M),mysq| Many parameter settings have been optimized , Don't adjust easily .
Index design principles
Code first , Index is up
- Generally, you should wait until the main business function is developed , Refer to the table sq| Take it out and analyze it before building an index .
The union index tries to cover the conditions
- For example, you can design one or two or three joint indexes ( Try to build fewer single valued indexes ), Let every joint index contain sq| In the sentence where、order by. group by Field of , Also make sure that the field order of these joint indexes meets sq| The leftmost prefix principle of query .
Don't index small cardinal fields
- Index cardinality refers to the total number of different values of this field in the table , For example, a table totals 100 Ten thousand records , There is a gender field , Its value is either male or female , Then the cardinality of this field is 2.
- If a cable bow is established for this small base segment | Words , It's better to scan the whole table , Because your index tree contains both male and female values , There's no way to do a quick binary search , Then it doesn't make much sense to use an index .
- Generally build index , Try to use fields with large cardinality , Fields with more values , Then we can play B+ The advantages of tree fast binary search .
We can use prefix index for long strings
- Try to design indexes for columns with smaller field types , For example, what tinyint And Class , Because if the field type is small , It also takes up less disk space , At this time, your performance will be better when searching - spot .
- Of course , The so-called field type is small - Column of points , It's not absolute , Many times you just want to target varchar(255) This field is indexed , It is necessary to take up even more disk space . For this varchar(255) Large fields may take up more disk space , You can optimize it a little , For example, for the front of this field 20 Characters to index , That is to say , For the first... Of each value in this field 20 Put characters in the index tree , Be similar to KEY index(name(20),age,position). At this point you are where When searching in terms , If it's based on name Field to search , Then the index will come first | According to name First... Of the field 20 A character to search , Locate the
Then before 20 After the prefix of characters matches part of the data , Then go back to the cluster index to extract the complete name Compare field values . - But if you order by name, So now your name Because the index tree contains only the first 20 Characters , So this sort can't be indexed ,group by It's the same thing . So here we need to have an understanding of prefix index .
where And order by Conflicts are limited where
- stay where and order by When an index design conflict occurs , Is it aimed at where To design the index , Or for order by Design index ? In the end is to let where Use the index , let order by Use the index ?
- Usually this kind of time is often to let where Conditions Use the index to quickly filter out a part of the specified data , Then sort . Because most cases are based on indexes where Filtering is often the fastest way to filter out a small part of the data you want , Then the cost of sorting may be much smaller .
Optimize based on slow query
- Reference article :(9 Bar message ) mysql The slow query _ Eight thirty Bruce , D The blog of -CSDN Blog _mysql The slow query
Index design practice
In a social context APP For example , We usually search for some friends , This involves the screening of user information , This must be for users user Table search , This table - Generally speaking, the amount of data will be relatively large , Let's not consider the situation of sub database and sub table . such as , We usually screen areas ( Provinces ), Gender , Age , height , Hobbies and so on , yes , we have APP Maybe the user still has a score , For example, the user's popularity rating , We may also sort according to the score and so on . For the background program, in addition to filtering various conditions of users , You also need processing such as paging , May generate something like sql Statement execution :select XX from user where xx=Xx and xx=xx order by XX limit xx,XX In this case, how to reasonably design the index ,
- Users may often prioritize users in the same city according to provinces and cities , And screening by sex , Should we design a joint index (province,ity,sex) 了 ? These fields seem to have a small cardinality , In fact, it should , Because these fields are queried too often .
- Suppose another user filters according to the age range , such as where province=xx and city=xx and age>=xx and age<=xx, We try to make age Add fields to the union index (province,city,sex,age), Be careful , - Generally, the search conditions of this range should be put at the end , As mentioned before, the conditions after the joint index range cannot be indexed , But for the current situation, it is still not necessary age This index field , Because the user did not filter sex Field , Then how to optimize ? In fact, we can optimize it like this sq|l Writing : where province=xx and city=xx and sex in ('female' ,'male') and age>=Xx and age<=xx
- Fields such as hobbies can also be similar sex Field handling , So you can also add the hobby field to the index (province ,city,sex,hobby,age)
- Suppose there may be another filter , For example, to filter users who have logged in in the last week , One You must want to make friends with active users , So you can get feedback as soon as possible , Corresponding to the background sq| It could be that :where province=xx and city=xx and sex in ('female','male') and age>=xx and age<=xx and latest_login_ time>= Xx Then can we put latest_login_ time Fields are also indexed ? such as (province,city,sex,hobby,age,latest login_ time) , Obviously not , Then how to optimize this situation ? In fact, we can try to redesign - - A field is_ _login_ in_ latest 7_ days, If the user - The login value within a week is 1, Otherwise 0, Then we can design the index as (province,ity,sex,hobby,is_ _login_ in_ latest_ 7_ days,age) To satisfy the above scenario !
- Generally speaking , Through such a multi field cable bow | It can filter out most of the data , Keep a small part of the data based on disk files order by Sorting of statements , Based on the limit paging , So the general performance is still relatively high . But sometimes users may query like this , Just check out the more popular women , such as sq|: where sex = 'female' order by score limit xx,xx, So the index above is hard to use , You can't use too many fields and too many values in The statement is spliced into sq| Inside , So what? ? In fact, we can redesign - A secondary federated index , such as (sex,score), In this way, the query requirements can be met .
- The above is to tell you some ideas of index design , The core idea is , Make full use of - - Two complex multi field joint indexes , Resist you 80% The above query , Then try to resist the rest with oneortwo auxiliary indexes - - Some atypical queries , Ensure that the query of this large data scale can make full use of the index as much as possible , This will ensure your query speed and performance !
边栏推荐
- 高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
- Vulnerability recurrence ----- 49. Apache airflow authentication bypass (cve-2020-17526)
- USB (十八)2022-04-17
- Conversion between commonsmultipartfile and file
- 给出一个数组,如 [7864, 284, 347, 7732, 8498],现在需要将数组中的数字拼接起来,返回「最大的可能拼出的数字」
- Install Fedora under RedHat
- Wechat forum exchange applet system graduation design completion (7) Interim inspection report
- The text editor of markdown class should add colors to fonts (including typora, CSDN, etc.)
- Description of longitude and latitude PLT file format
- 网络安全-CSRF
猜你喜欢

ROS2专题(03):ROS1和ROS2的区别【02】
LDO voltage stabilizing chip - internal block diagram and selection parameters
七月第一周
2021ICPC上海 H.Life is a Game Kruskal重构树
When copying something from the USB flash disk, an error volume error is reported. Please run CHKDSK

JMeter interface automated test read case, execute and write back result
13、 System optimization

Cloud native is devouring everything. How should developers deal with it?
leetcode-520. 检测大写字母-js

漏洞复现----49、Apache Airflow 身份验证绕过 (CVE-2020-17526)
随机推荐
网络安全-sqlmap与DVWA爆破
Advantages and disadvantages of rest ful API
How to generate unique file names
Unity3D学习笔记4——创建Mesh高级接口
UE4_UE5全景相机
Specific method example of V20 frequency converter manual automatic switching (local remote switching)
PCI-Express接口的PCB布线规则
Cloud native is devouring everything. How should developers deal with it?
智慧社区和智慧城市之间有什么异同
Adrnoid开发系列(二十五):使用AlertDialog创建各种类型的对话框
Ros2 topic (03): the difference between ros1 and ros2 [01]
ROS2专题(03):ROS1和ROS2的区别【01】
Opencv scalar passes in three parameters, which can only be displayed in black, white and gray. Solve the problem
Archlinux install MySQL
Gee (IV): calculate the correlation between two variables (images) and draw a scatter diagram
云原生正在吞噬一切,开发者该如何应对?
Wechat forum exchange applet system graduation design completion (7) Interim inspection report
opencv scalar传入三个参数只能显示黑白灰问题解决
Dynamics 365 find field filtering
Oracle-数据库的备份与恢复