当前位置:网站首页>Quantitative calculation research
Quantitative calculation research
2022-07-03 11:53:00 【Diros1g】
1.Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
1.1 methods
Prunes the network: Keep only some important connections ;
Quantize the weights: Share some through weight quantization weights;
Huffman coding: Further compression by Huffman coding ;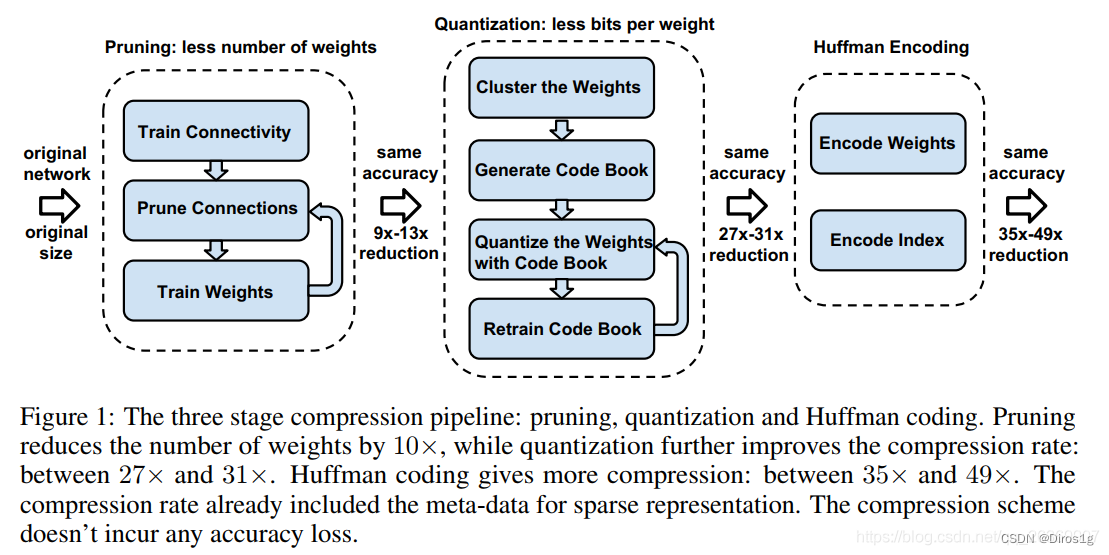
1.1.1 prune
1. Learn to connect from the normally trained network
2. Trim connections with small weights , Those less than the threshold are deleted ;
3 Retraining the web , Its parameters are obtained from the remaining sparse connections ;
1.1.2 Quantification and weight sharing
quantitative

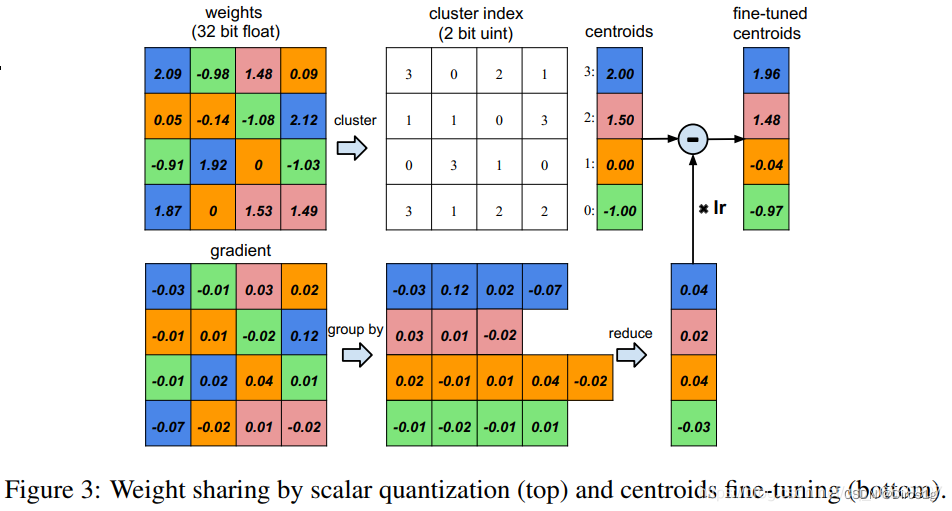
Weight sharing
It uses a very simple K-means, Make one for each floor weight The clustering , Belong to the same cluster Of share the same weight size . One thing to watch out for : Cross layer weight Do not share weights ;
1.1.3 Huffman code
Huffman coding will first use the frequency of characters to create a tree , Then a specific code is generated for each character through the structure of the tree , Characters with high frequency use shorter encoding , If the frequency is low, a longer code is used , This will reduce the average length of the encoded string , So as to achieve the purpose of data lossless compression .
1.2 effect
Pruning: Reduce the number of connections to the original 1/13~1/9;
Quantization: Every connection from the original 32bits Reduced to 5bits;
Final effect :
- hold AlextNet Compressed 35 times , from 240MB, Reduce to 6.9MB;
- hold VGG-16 Compressed 49 north , from 552MB Reduce to 11.3MB;
- The calculation speed is the original 3~4 times , Energy consumption is the original 3~7 times ;
1.3 The experimental requirements
1. The weight preservation requirements of training are complete , It can't be model.state_dict(), But most of our current weight files are parameter states rather than complete models
2. It requires a complete network structure
3. Have enough training data
Reference resources :1.【 Deep neural network compression 】Deep Compression
2. Deep compression : Adopt pruning , Quantization training and Huffman coding to compress the depth neural network
3.Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
4.pytorch Official documents
5. Understanding of Huffman coding (Huffman Coding)
2.torch The official quantitative calculation
https://pytorch.apachecn.org/#/
https://pytorch.org/docs/stable/quantization.html
2.0 Data type quantification Quantized Tensor
Can be stored int8/uint8/int32 Data of type , And carry with you scale、zero_point These parameters
>>> x = torch.rand(2,3, dtype=torch.float32)
>>> x
tensor([[0.6839, 0.4741, 0.7451],
[0.9301, 0.1742, 0.6835]])
>>> xq = torch.quantize_per_tensor(x, scale = 0.5, zero_point = 8, dtype=torch.quint8)
tensor([[0.5000, 0.5000, 0.5000],
[1.0000, 0.0000, 0.5000]], size=(2, 3), dtype=torch.quint8,
quantization_scheme=torch.per_tensor_affine, scale=0.5, zero_point=8)
>>> xq.int_repr()
tensor([[ 9, 9, 9],
2.1 Two quantitative methods
2.2Post Training Static Quantization, Static quantization after model training torch.quantize_per_tensor
scale ( scale ) and zero_point( Zero position ) You need to customize it . The quantified model , Can't train ( It's not back propagation ), Nor can you reason , After dequantization , In order to do the calculation
2.3. Post Training Dynamic Quantization, Dynamic quantification after model training : torch.quantization.quantize_dynamic
The system automatically selects the most appropriate scale ( scale ) and zero_point( Zero position ), No need to customize . The quantified model , You can infer , But not training ( It's not back propagation )
边栏推荐
- Vulnhub's cereal
- vulnhub之narak
- This article explains the complex relationship between MCU, arm, MCU, DSP, FPGA and embedded system
- MySQL searches and sorts out common methods according to time
- Mmc5603nj geomagnetic sensor (Compass example)
- Deploying WordPress instance tutorial under coreos
- "Jianzhi offer 04" two-dimensional array search
- Qt+VTK+OCCT读取IGES/STEP模型
- ArcGIS application (XXI) ArcMap method of deleting layer specified features
- uniapp scroll view 解决高度自适应、弹框滚动穿透等问题。
猜你喜欢

PHP基础
Vulnhub geminiinc V2

Numpy np. Max and np Maximum implements the relu function

金额计算用 BigDecimal 就万无一失了?看看这五个坑吧~~
The excel table is transferred to word, and the table does not exceed the edge paper range
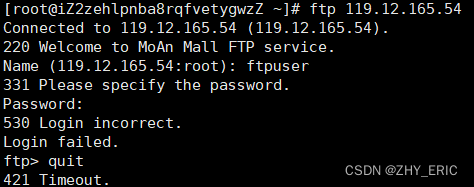
ftp登录时,报错“530 Login incorrect.Login failed”
【学习笔记】dp 状态与转移
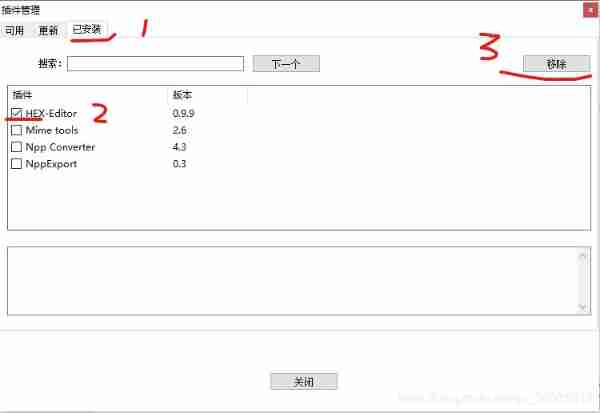
Viewing binary bin files with notepad++ editor
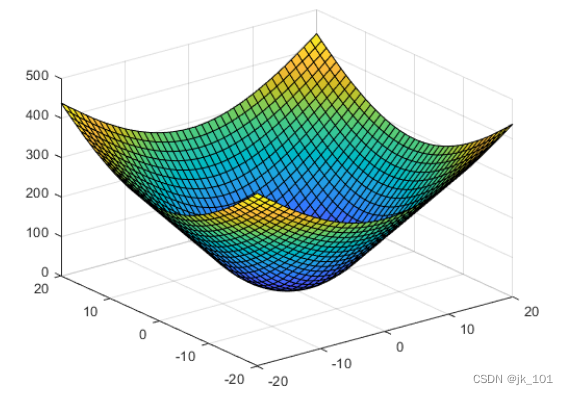
外插散点数据
2022 northeast four provinces match VP record / supplementary questions
随机推荐
STL tutorial 10 container commonalities and usage scenarios
Groovy test class and JUnit test
金额计算用 BigDecimal 就万无一失了?看看这五个坑吧~~
抓包整理外篇fiddler———— 会话栏与过滤器[二]
R语言使用gridExtra包的grid.arrange函数将ggplot2包的多个可视化图像横向组合起来,ncol参数自定义组合图列数、nrow参数自定义组合图行数
DNS multi-point deployment IP anycast+bgp actual combat analysis
Mmc5603nj geomagnetic sensor (Compass example)
鸿蒙第四次培训
STL教程9-容器元素深拷贝和浅拷贝问题
如何将数字字符串转换为整数
Excel表格转到Word中,表格不超边缘纸张范围
优化接口性能
R language uses the aggregate function to calculate the mean value (sum) of dataframe data grouping aggregation without setting na The result of RM calculation. If the group contains the missing value
银泰百货点燃城市“夜经济”
Niuniu's team competition
836. 合并集合(DAY 63)并查集
R语言使用原生包(基础导入包、graphics)中的hist函数可视化直方图(histogram plot)
Test classification in openstack
Dynamically monitor disk i/o with ZABBIX
The uniapp scroll view solves the problems of high adaptability and bullet frame rolling penetration.