当前位置:网站首页>MySQL advanced review
MySQL advanced review
2022-07-04 11:58:00 【Nanyidao street】
Business
MyISAM and InnoDB difference
1. Is row level lock supported
MyISAM Only Table lock ,InnoDB Yes Row level lock and table level lock
MyISAM A lock locks the whole watch ,InnoDB Better concurrency
2. Support transactions
MyISAM I won't support it
InnoDB Support , Yes commit and rollback The function of
3. Support for foreign keys
MyISAM I won't support it
InnoDB Support
- MySQL InnoDB Engine USES redo log( Redo log ) Guarantee the business persistence , Use undo log( Rollback log ) To ensure that the business is Atomicity .
- MySQL InnoDB The engine goes through Locking mechanism 、MVCC And other means to ensure the Isolation, ( The default isolation level supported is
REPEATABLE-READ). - Ensure the persistence of the transaction 、 Atomicity 、 After isolation , Consistency is guaranteed .
Lock mechanism and InnoDB Lock algorithm
MyISAM and InnoDB Lock of storage engine
- ** Table lock :**MySQL Locked in The largest particle size A lock of , Implement a simple , Locked fast , It won't form a deadlock , High probability of conflict , Low concurrency
- Row-level locks : The smallest particle size A lock of , Only for the present Lock the operation line
InnoDB There are three algorithms for storing engine locks
- Record lock: Record locks , Locks on a single line record
- Gap lock: Clearance lock , Lock a range , Not including the record itself
- Next-key lock:record+gap Temporary key lock , Lock a range , Include the record itself
What are the problems of concurrent transactions
- Dirty reading (Dirty Read): A Write B read
- Missing changes (Lost to modify): A read B read A Write B Write , such A Changes will be lost
- It can't be read repeatedly (Unrepeatable read): Read the same data multiple times in a transaction ,A read B read B Write A read This leads to unrepeatable reading
- Fantasy reading (Phantom read): A Read several sets of data then B Insert several sets of data , There will be records that do not exist
The difference between nonrepeatable reading and unreal reading :
Read a piece of data many times , But what cannot be repeated is that some columns have been modified , Unreal reading is to add or delete a record It is found that the record increases or decreases
Transaction isolation level
- READ-UNCOMMITTED( Read uncommitted ): Lowest isolation level , allow Read uncommitted data changes , Can cause dirty reading 、 Phantom or unrepeatable reading .
- READ-COMMITTED( Read committed ): Allow reading Data that has been committed by concurrent transactions , Can prevent dirty reading , But phantom or unrepeatable reads can still occur .
- REPEATABLE-READ( Repeatable ): Multiple reads of the same field are consistent , Unless the data is modified by the transaction itself , Can prevent dirty and unrepeatable read , But phantom reading can still happen .
- SERIALIZABLE( Serializable ): Highest isolation level , Completely obey ACID Isolation level . All transactions are executed one by one , In this way, there is no interference between transactions , in other words , This level prevents dirty reads 、 Unrepeatable reading and phantom reading .
stay RR Isolation level (REPEATABLE-READ Below grade )
Innodb Use MVCC and next-key locks Solve unreal reading ,
MVCC The solution is Unreal reading of ordinary reading ,next-keylocks solve Unreal reading in the current reading situation
Fantasy reading :
Business A do A The operation of , Inquire about A The business of , But other records were found
How? ?
The current reading
stay RR Under the circumstances , Suppose you use the current read , Locked reading
select * from table where id>3 What's locked is id=3 This record and id>3 This range , Lock the range between index records , Avoid inserting records between ranges , To avoid phantom row records .
Ordinary reading
Default isolation level (REPEATABLE READ) Next , The addition, deletion and search have changed into this :
SELECT
Read create version less than or equal to current transaction version number , and And delete records whose version is empty or greater than the current transaction version number . This ensures that records exist before they are read
INSERT
take The version number of the current transaction is saved to the creation version number of the row
UPDATE
Insert a new line , And take the version number of the current transaction as the creation version number of the new line , At the same time, the original record line of Delete the version number and set it to the current transaction version number
DELETE
The version number of the current transaction Delete version number saved to line
SQL Optimize
SQL Optimize
MySQL The assignment principle and process of
The role of master-slave replication :
1. There is something wrong with the main database , Can switch from database
2. Realize read-write separation at the database level
3. Daily database backup
Master slave replication solves the problem :
- The data distribution : Start and stop replication at will
- ** Load balancing :** Reduce the pressure on a single server
- High availability and fail over : Help applications avoid single point of failure
- Upgrade test : You can use a higher version MySQL As a slave Library
Master slave replication principle :
- The master database data is updated to the binary log
- The log of the slave library is copied from the log of the master library to the log of the slave Library
- Read the event of interrupt log from the Library
Basic principle flow ,3 Threads and their associations
Lord :binlog Threads —— Record all statements that change database data , In the master Upper binlog in ;
from :io Threads —— In the use of start slave after , In charge of from master Pull up binlog Content , Put it in your own relay log in ;
from :sql Execute thread —— perform relay log The statement in ;
The copying process
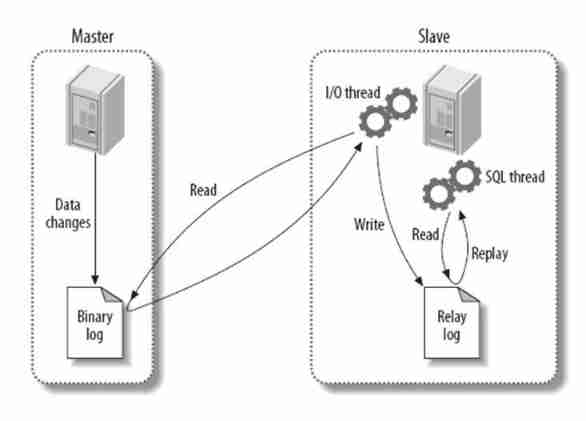
Scheme 1
Use mysql-proxy agent
advantage : Direct implementation of read-write separation and load balancing , No need to change the code ,master and slave Use the same account number ,mysql Officials do not recommend the use of
shortcoming : Reduce performance , Unsupported transaction
Option two
Use AbstractRoutingDataSource+aop+annotation stay dao The layer determines the data source .
Option three
Use AbstractRoutingDataSource+aop+annotation stay service The layer determines the data source , Can support transactions .
shortcoming : Class internal methods are passed through this.xx() When the methods are called to each other ,aop No interception , Special treatment is required .
Indexes
The underlying data structure of the index
Hash surface &B+ Trees
adopt Hashtable + The hash algorithm We can adopt key To find the index And find out value
problem :
The hash table has Hash The question of conflict , Many different key Got index identical , Our solution is Chain address ,JDK1.8 After that, I used The method of red black tree
Hash The watch is so fast , Why? MySQL Not used as The data structure of the index
1.Hash The question of conflict
2.Hash Indexes Sequence and range queries are not supported
B Trees and B+ Trees
B Trees are also called B- Trees , The full name is Multiway balanced search tree ,B Trees and B+ Trees are **Balance( Balance )** It means
B Trees & B+ What are the similarities and differences between trees ?
- B All nodes of the tree are stored key, Also stored data,B+ Only leaf nodes are stored key and data, Other nodes only store key
- B Trees Leaf nodes are independent ,B+ The leaf nodes of the tree have A reference chain goes to its adjacent nodes
- B Tree adoption Two points search , The search may end before reaching the leaf node ,B+ All the trees are From the root -> Leaf node
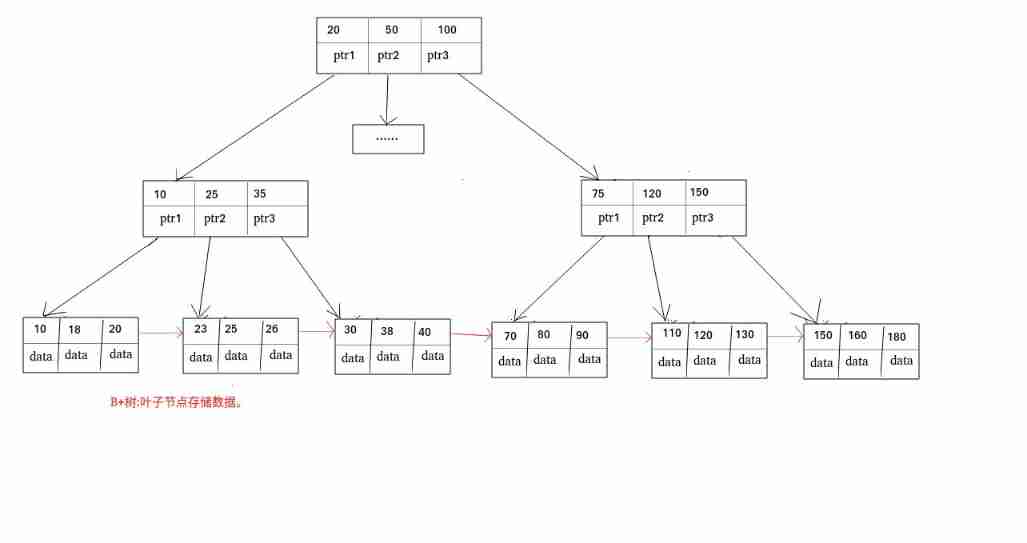
Index type
primary key
The primary key column of the data table uses primary key
No, When indicating the primary key ,InnoDB Will automatically check Whether to uniquely index the field , If yes, this field is the default primary key , No rules InnoDB Will create 6Byte The auto primary key of
Secondary indexes ( Secondary index )
Secondary indexes are also called secondary indexes , Secondary index Leaf nodes store primary keys , So you can find the location of the primary key through the secondary index
- unique index : Duplicate data cannot appear in the attribute column of unique index , But allow the data to be NULL, A table allows multiple unique indexes to be created
- General index : The only function of an ordinary index is to query data quickly , A table allows the creation of multiple normal indexes , And allow data duplication and NULL.
- Prefix index : take String data type The first few characters of
- Full-text index : Full text indexing is for Detect keyword information in large text data
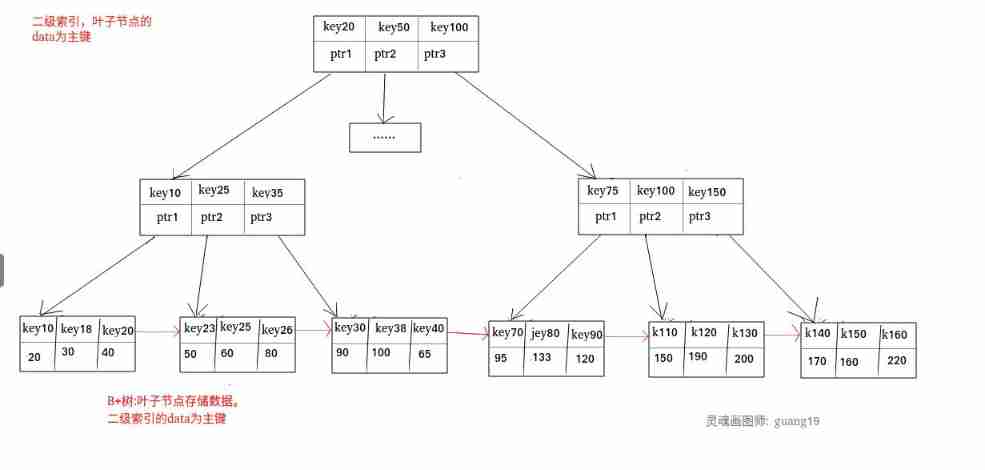
Clustered index and nonclustered index
Clustered index
A clustered index is an index in which the index structure and data are stored together . The primary key index belongs to the clustered index
advantage :
Fast query speed , because B+ Is balanced tree , The leaves are orderly , So it's easy to locate
shortcoming :
1. Rely on ordered data : You need to sort when inserting , For strings or UUID Type data is very troublesome
2. It's expensive to update : When updating data , The index will also be updated
Nonclustered indexes
A secondary index is a nonclustered index .
MyISAM The engine's table .MYI The file includes the index of the table , The index of the table (B+ Trees ) Each leaf non leaf node stores the index , The leaf node stores the index and the pointer to the corresponding data of the index , Point to .MYD File data .
advantage :
Low update cost
shortcoming :
- Rely on ordered data
- It's possible to double check
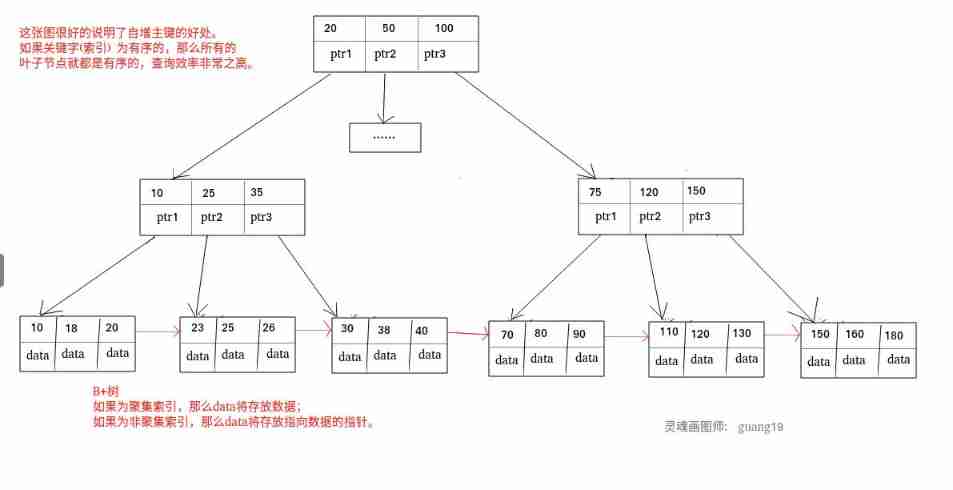
Notes on index creation
1. Select the appropriate field to create the index
- Not for NULL Field of
- Frequently queried fields
- Fields that are queried as conditions
- Fields that need to be sorted frequently
- Fields that are often used for connections
2. Frequently updated fields should be indexed carefully
3. Consider building a federated index rather than a single column index as much as possible
4. Be careful to avoid redundant indexes
5. Consider using a prefix index instead of a normal index on a string type field
边栏推荐
- Decrypt the advantages of low code and unlock efficient application development
- Data communication and network: ch13 Ethernet
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 8
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 9
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 7
- 2018 meisai modeling summary +latex standard meisai template sharing
- re. Sub() usage
- Reptile learning winter vacation series (2)
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 10
- Attributes and methods in math library
猜你喜欢
How to create a new virtual machine
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 13](/img/29/49da279efed22706545929157788f0.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 13

Some summaries of the 21st postgraduate entrance examination 823 of network security major of Shanghai Jiaotong University and ideas on how to prepare for the 22nd postgraduate entrance examination pr
Practical dry goods: deploy mini version message queue based on redis6.0
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 9](/img/ed/0edff23fbd3880bc6c9dabd31755ac.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 9
Day01 preliminary packet capture
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 19](/img/7c/f728e88ca36524f92c56213370399b.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 19
Reptile learning 4 winter vacation series (3)
2018 meisai modeling summary +latex standard meisai template sharing
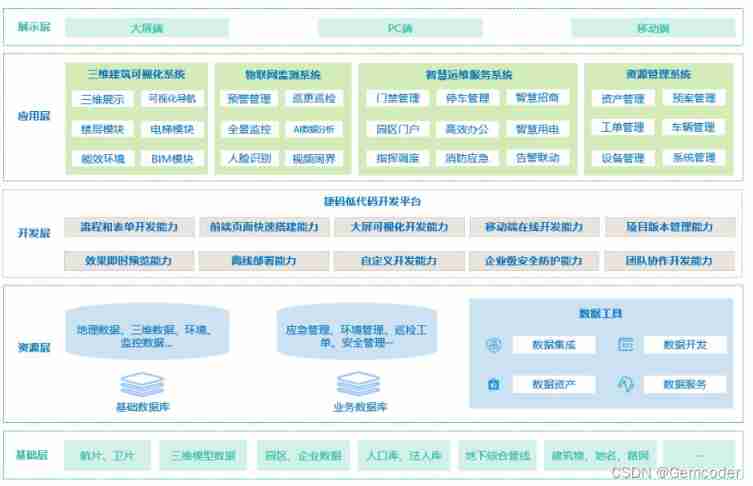
Enter the smart Park, and change begins here
随机推荐
[ES6] template string: `string`, a new symbol in es2015
OSI model notes
Solaris 10网络服务
Take advantage of the world's sleeping gap to improve and surpass yourself -- get up early
How to judge the advantages and disadvantages of low code products in the market?
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 17
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 9
Summary of collection: (to be updated)
QQ get group member operation time
Shift EC20 mode and switch
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 18
Realize cross tenant Vnet connection through azure virtual Wan
Polymorphic system summary
三立期货安全么?期货开户怎么开?目前期货手续费怎么降低?
03_ Armv8 instruction set introduction load and store instructions
The latest idea activation cracking tutorial, idea permanent activation code, the strongest in history
Usage of case when then else end statement
2021-10-20
Enter the smart Park, and change begins here
Here, the DDS tutorial you want | first experience of fastdds - source code compilation & Installation & Testing