当前位置:网站首页>如何精准识别主数据?
如何精准识别主数据?
2022-07-06 02:34:00 【浊酒南街】
什么是主数据?
MBOK里的定义是这样婶儿的:
主数据是有关业务实体(如雇员、客户、产品、金融结构、资产和 位置等)的数据,这些实体为业务交易和分析提供了语境信息。实体是客观世界的对象(人、组织、地方或事物等)。实体被实体、实例以数据/记录的方式表示。
发现没有?主数据和实体有关系哟~~~所以主数据其实跟模型关系是很紧密的。
其实理解主数据很简单,简单来说,就是核心业务中,非数值的关键数据。这个理解不精准,但是容易理解。
不过这哥们的问题,显然不是这篇文章能解决的,因为他肯定是在进行主数据识别的时候遇到模棱两可的内容,无法进行区分了。
主数据识别
想要确认两个内容是否是主数据,就得从主数据的定义入手,从主数据特征入手。
当然,也有一些偏门的手法可以辅助识别。
石秀峰石老师在他的书《一本书讲透数据治理》里写了两个方法:
1、主数据特征识别法
2、业务影响和共享程度分析矩阵法
主数据特征识别法顾名思义,就是对着主数据的特征比划一下就行了: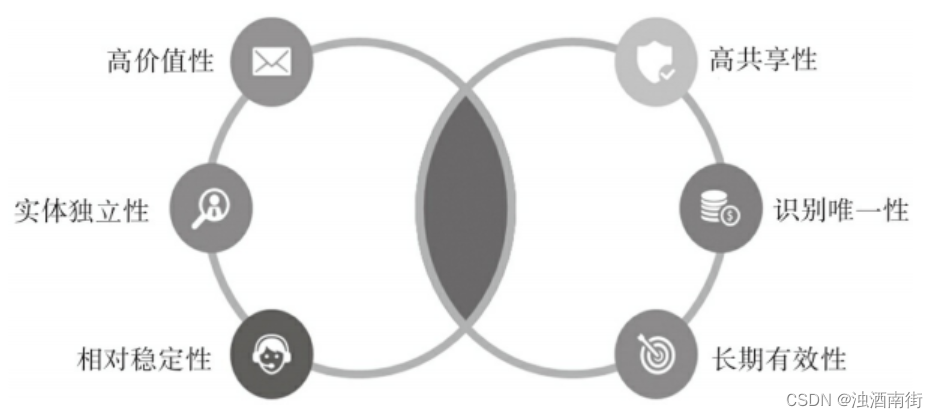
我们看看这些数据是否有以上特征,如果都有,那么是。如果缺一两个,可以考虑考虑。
一般可列为6个问题:
1、是否体现业务核心价值?这一点非常非常重要!(客户信息肯定是,但是配送地址所在省份就不是核心价值数据了)
2、是否是独立的实体?(商品是独立不可拆分的实体,但是临期商品则不是)
3、是否相对稳定?(之所以加上相对,就是某些主数据是会变的,比如客户信息)
4、是否会在其他系统共享?(如果只是单个系统使用,即便是核心价值的,一般也不会列为主数据)
5、是否具有唯一性?(如果这个数据不强制唯一,全局可能重复,那么可以踢出去了)
6、是否长期有效?(如果是短期使用,一般不作为主数据。但是这个长期短期和业务有关,比如互联网的订单和造船厂的订单时效性就不一样,前者半个月后大概率就无了,后者一般都持续好几年)
至于业务共享矩阵法,其实就是看这个数据的重要程度和共享程度: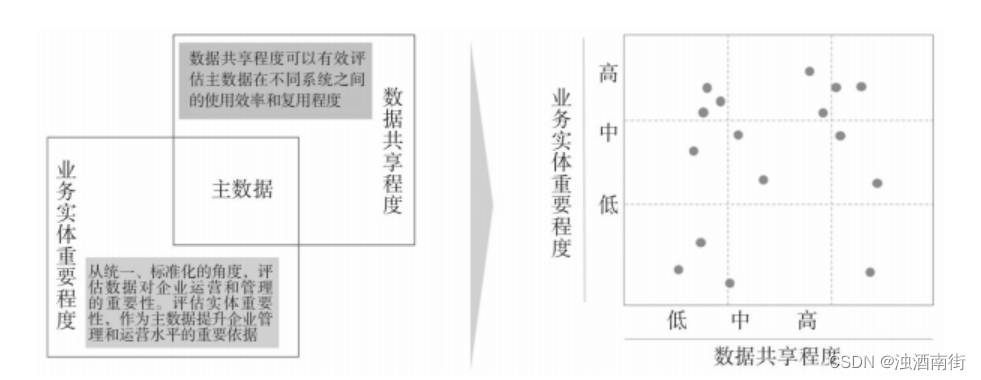
按照重要程度和共享程度一分,优先级别自然就出来了。至于那些又不重要又不共享的,自然就排除在外了。
区分难题
虽然已经有方法了,但是有些时候遇到不熟悉的业务,还是会蒙圈。一般容易搞混淆的是参考数据和主数据。
因为参考数据有很多特征和主数据非常类似,比如也是长期有效、跨系统共享、也很重要(价值不一定高)、非常稳定、全局唯一等。
一些大家熟知的还行,但是一旦跟业务挂钩,如果你不懂业务,几乎就没办法与主数据拆分开。
DMBOK里提出了二者管理重点的区别:
对于参考数据和主数据,管理的重点是不同的:
1)参考数据管理(Reference Data Management,RDM)。需要对定义的域值及其定义进行控制。参考数据管理的目标是确保组织能够访问每个概念的一整套准确且最新的值。
2)主数据管理(Master Data Management,MDM)。需要对主数据的值和标识符进行控制,以便能够跨系统地、一致地使用核心业务实体中最准确、最及时的数据。主数据管理的目标包括确保当前值的准确性和可用性,同时降低由那些不明确的标识符所引发的相关风险(那些 被识别为具有多个实例的实体和那些涉及多个实体的实例)。
至于如何区分二者,除了分清楚数据价值之外,还有一个比较取巧的方式:看表字段多寡和数据量。
一般来说,参考数据的数据集通常会比交易数据集或主数据集小,复杂程度低,拥有的列和行也更少。
所以如果你看到一个3列的数据表,无法区分这是主数据还是参考数据,那么盲猜一波参考数据准没错~~~
当然,更重要的区分,还是看其价值,就是参与到核心业务的程度和价值。以及该数据是否完成“识别和管理来自不同系统和流程的数据之间的关联关系”。
参考数据会在核心流程里体现,比如配送地址所在省份,但是程度比较低,价值也不是特别大,丢失了甚至都没太大关系(可以通过其他数据推出来)。
而且,该数据也无需识别和管理不停系统和流程的数据之间的关联关系。所以,列为参考数据是没问题的。
小结
主数据很容易与参考数据混淆。
区分方式有很多种,常规方法有两个:
1、主数据特征识别法
2、业务影响和共享程度分析矩阵法
非常规方法有很多:
1、管理重心区分法
2、字段、数据量判断法
3、不同系统数据关联法
4、经验判断法
边栏推荐
- Number conclusion LC skimming review - 1
- Multi function event recorder of the 5th National Games of the Blue Bridge Cup
- MySQL winter vacation self-study 2022 11 (9)
- Zero basic self-study STM32 wildfire review of GPIO use absolute address to operate GPIO
- Accident index statistics
- Paper notes: limit multi label learning galaxc (temporarily stored, not finished)
- "Hands on learning in depth" Chapter 2 - preparatory knowledge_ 2.3 linear algebra_ Learning thinking and exercise answers
- Template_ Quick sort_ Double pointer
- 729. 我的日程安排表 I / 剑指 Offer II 106. 二分图
- Initial understanding of pointer variables
猜你喜欢

Pat grade a 1033 to fill or not to fill
零基础自学STM32-野火——GPIO复习篇——使用绝对地址操作GPIO
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 24](/img/2e/b1f348ee6abaef24b439944acf36d8.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 24
爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架

【社区人物志】专访马龙伟:轮子不好用,那就自己造!
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 6](/img/38/51797fcdb57159b48d0e0a72eeb580.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 6

力扣今日题-729. 我的日程安排表 I
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 19](/img/7c/f728e88ca36524f92c56213370399b.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 19
【MySQL 15】Could not increase number of max_ open_ files to more than 10000 (request: 65535)
![[Wu Enda machine learning] week5 programming assignment EX4 - neural network learning](/img/37/83953c24ec141667b304f9dac440f1.jpg)
[Wu Enda machine learning] week5 programming assignment EX4 - neural network learning
随机推荐
What should we pay attention to when using the built-in tool to check the health status in gbase 8C database?
Accident index statistics
[postgraduate entrance examination English] prepare for 2023, learn list5 words
Compact lidar global and Chinese markets 2022-2028: technology, participants, trends, market size and share Research Report
Formatting occurs twice when vs code is saved
一个复制也能玩出花来
会员积分营销系统操作的时候怎样提升消费者的积极性?
事故指标统计
好用的 JS 脚本
Template_ Quick sort_ Double pointer
Looking at the trend of sequence modeling of recommended systems in 2022 from the top paper
[coppeliasim] efficient conveyor belt
更改对象属性的方法
继承的构造函数
Data preparation
[untitled] a query SQL execution process in the database
米家、涂鸦、Hilink、智汀等生态哪家强?5大主流智能品牌分析
Bigder:34/100 面试感觉挺好的,没有收到录取
球面透镜与柱面透镜
JS events (add, delete) and delegates