当前位置:网站首页>【云原生】快出数量级的性能是怎样炼成的?就提升了亿点点
【云原生】快出数量级的性能是怎样炼成的?就提升了亿点点
2022-08-02 09:26:00 【码农飞哥】
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
️ 2. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
5. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
全网同名【码农飞哥】欢迎关注,个人VX: wei158556
1. 拿事实说话
我们之前做过一些性能优化的案例,不算很多,还没有失手过。少则提速数倍,多则数十倍,极端情况还有提速上千倍的。提速一个数量级基本上是常态。下面是一些案例材料:
开源 SPL 提速保险公司团保明细单查询 2000+ 倍
开源 SPL 提升银行自助分析从 5 并发到 100 并发
开源 SPL 提速银行用户画像客群交集计算 200+ 倍
开源 SPL 优化银行预计算固定查询成实时灵活查询
开源 SPL 将银行手机账户查询的预先关联变成实时关联
开源 SPL 提速银行资金头寸报表 20+ 倍
开源 SPL 提速银行贷款协议跑批 10+ 倍
开源 SPL 优化保险公司跑批优从 2 小时到 17 分钟
开源 SPL 提速银行 POS 机交易报表 30+ 倍
开源 SPL 提速银行贷款跑批任务 150+ 倍
开源 SPL 提速资产负债表 60 倍
2. 这是怎么做到的呢?
这些被提速的场景都有一个共同点:原先都是用各种数据库(也有HADOOP/Spark)上的SQL实现的,包括查询用的几百行SQL也有跑批用的几千行存储过程,然后我们改用集算器的SPL重新实现之后就有了这样的效果。
集算器SPL有什么神奇之处?是不是能让各种运算跑得更快?
有点遗憾,并没有这样的好事。集算器也是一个软件,而且是用Java写的,完成同样运算通常比C/C++写的数据库还要慢一点。
那是怎么回事?
根本原因在于我们用SPL实现了不同的算法。软件不能提高硬件的速度,但我们可以设计出更低复杂度的算法,有效地减少计算量,然后速度自然就上去了。一个运算任务本来要做1亿次加法,如果能减到100万次,那自然就能快100倍,即使每次运算都变得稍慢一点,总体性能仍然会提高,这一点也不神奇。
只要能实现高性能算法和存储,用什么技术来做并不重要了。用C/C++、Java当然都能做出来。事实上,集算器是用Java写的,用Java直接实现这些算法原则上还会更快一点,用C/C++ 一般还能更快(Java的内存分配消耗时间还是有点多)。
不过,虽然用Java和C++能写出比SPL更快的代码,但要长得多(估计会长出50-100倍),这会导致开发工作量过大,这在实际应用时也是要权衡的一个指标。有时候,跑得快和写着简单其实是一回事,就是能高效率地实现高性能算法。
集算器的SPL中强化了结构化数据的数据类型,并提供了很多基础的高性能算法。写代码就是组合运用这些算法,当然会方便得多。要说神奇之处,也就是这一点了。
那么,继续SQL就不能做到同样的事吗?
是的。SQL设计得过于粗线条,关系代数这个理论基础中缺乏很多数据类型和基础运算,很多高性能算法都无法描述,结果只能使用慢算法。虽然现在很多数据库和大数据平台都在工程上有所优化,但也只能针对简单的场景,情况复杂之后数据库的优化器都会“晕”掉,所以解决不了根本问题。这是个理论上的问题,无法在工程层面解决。
SPL基于的理论基础不再是关系代数,而是我们发明的离散数据集。在这个体系下有更多的数据类型和运算,就能写出更多高性能算法了。SPL是离散数据集的一种实现,封装了许多现成的算法。用Java和C++当然也能从头来实现这个代数体系,因而都能写出来高性能代码。而SQL却不可以。
举个简单的例子,我们想在1亿条数据中取出前10名,用SQL写出来是这样的:
select top 10 x,y from T order by x desc
这个语句中有个order by,严格按它执行就会涉及大排序,而排序非常慢。其实我们可以想出一个不用大排序的算法,但用SQL却无法描述,只能指望数据库优化器了。对于这句SQL描述的简单情况,很多商用数据库确实都能优化,使用不必大排序的算法,性能通常很好。但情况复杂一些,比如在每个分组中取前10名,要用窗口函数和子查询把SQL写成这样:
select * from
(select y,*,row_number() over (partition by y order by x desc) rn from T)
where rn<=10
这时候,数据库优化器就会犯晕了,猜不出这句SQL的目的,只能老老实实地执行排序的逻辑(这个语句中还是有order by的字样),结果性能陡降。
而SPL不一样,离散数据集中有普遍集合的概念,TopN这种运算被认为是和SUM和COUNT一样的聚合运算,只不过返回值是个集合而已。这时候写出来的取前10名的语句中并没有排序动作:
T.groups(;top(-5;x))
分组后的写法也很简单,都不需要执行大排序:
T.groups(y;top(-5;x))
这里 性能优化技巧:TopN 还有关于这个问题的更详细测试对比。
所以,我们做性能优化时要重写代码,不能继续使用SQL保持兼容。要读懂原来的逻辑重新实现,这个工作量还是很大的,不过能换来数倍数十倍的性能提升,常常还是值得的。
另外,存储也非常重要,好算法要有合适的存储机制配合才能生效,所以不能继续把数据继续存在数据库里获得高性能,需要搬出来换种办法组织存放。改变存储后,有可能把原来需要缓存的计算过程变成不需要了,原来要遍历多遍的运算变成只遍历一次甚至不用遍历了,减少硬盘访问量对性能的提升非常有效。
从上面这个原理上看,如果我们不能针对计算目标设计出更好的算法,那就做不到提速了。比如一个很简单的大表求和,用SQL要做1亿次,用SPL也要做1亿次,那就不可能做得更快,一般还会更慢一点(Java赶不上C/C++)。但是,当运算任务足够复杂时,碰到几百上千行的嵌套N层SQL(慢的SQL通常也不会太简单),几乎总能找到足够多可优化的环节,所以我们经历过的案子还没有失手过。结果,在实践上用Java写出来集算器大幅度超越了C/C++写的数据库,这都是算法造就的。
我们甚至曾经发过一个广告 慢得受不了的查询跑批
寻找用SQL写的慢过程,我们负责提速一个数量级。
换个角度再看这个提速原理:高性能靠的不是代码,而是代数,代码只是个实现手段而已。其中最关键的是掌握和运用这些算法,而不是SPL语法。SPL语法很简单,比Java容易多了,两小时就能基本上手,两三周就能比较熟练了。但算法却没那么简单,需要认真学习反复练习才能掌握。这些案例直接由没有经验的用户自己做常常效果并不好,主要原因也是对算法没有吃透。
反过来,而只要掌握了算法,用什么语法就是个相对次要的问题了(当然用SQL这种太粗线条的语言还是不行)。这就像给病人看病,找出病理原因后,能分析出什么成分的药能管用。无论直接购买成药(使用封装过的SPL),还是上山采药(使用Java/C++硬写),都可以治好病,无非就是麻烦程度和支付成本不同。
可能有读者对SPL提供了哪些与SQL不同的高性能算法感兴趣,推荐一下乾学院上的性能优化图书 【性能优化】 前言及目录 和视频课程 《性能优化》课程
我们已经把这些算法都整理成有体系的知识了。有些算法是业界首创的,其它教科书和论文中都找不到。
跟着这些图书课程学习,掌握这些算法后,就可以自己写到快出数量级的高性能代码。即使自己不写代码,也能理解原理,不会再被很多大数据产品喊什么“万亿秒查”的说法忽悠了。
SPL资料
边栏推荐
- Jenkins--基础--07--Blue Ocean
- It's time for bank data people who are driven crazy by reporting requirements to give up using Excel for reporting
- The god-level Alibaba "high concurrency" tutorial "basic + actual combat + source code + interview + architecture"
- 自定义View实现波浪荡漾效果
- 谈谈对Volatile的理解
- 不用Swagger,那我用啥?
- 初学者怎么快速学会SQL
- 了解下C# 多线程
- net start mysql MySQL 服务正在启动 . MySQL 服务无法启动。 服务没有报告任何错误。
- 每天花2小时恶补腾讯T8纯手打688页SSM框架和Redis,成功上岸美团
猜你喜欢

openpyxl 单元格合并

spark:页面单跳转换率统计(案例)

Jenkins--基础--6.1--Pipeline--介绍
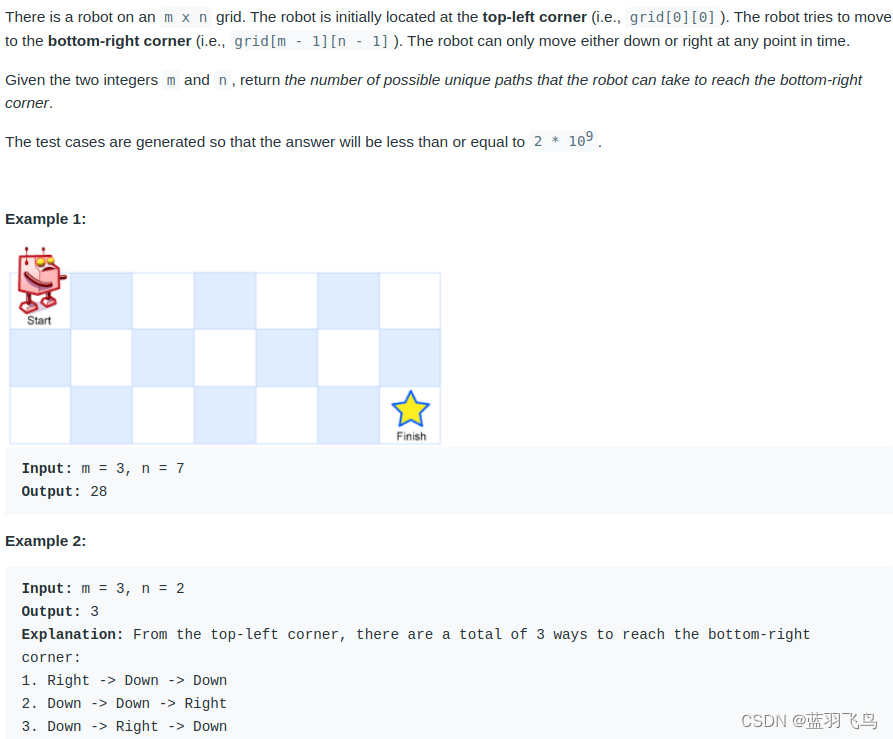
leetcode 62. Unique Paths(独特的路径)

【新版干货书】深度伪造 (DeepFakes):创造,检测和影响
二维数组零碎知识梳理
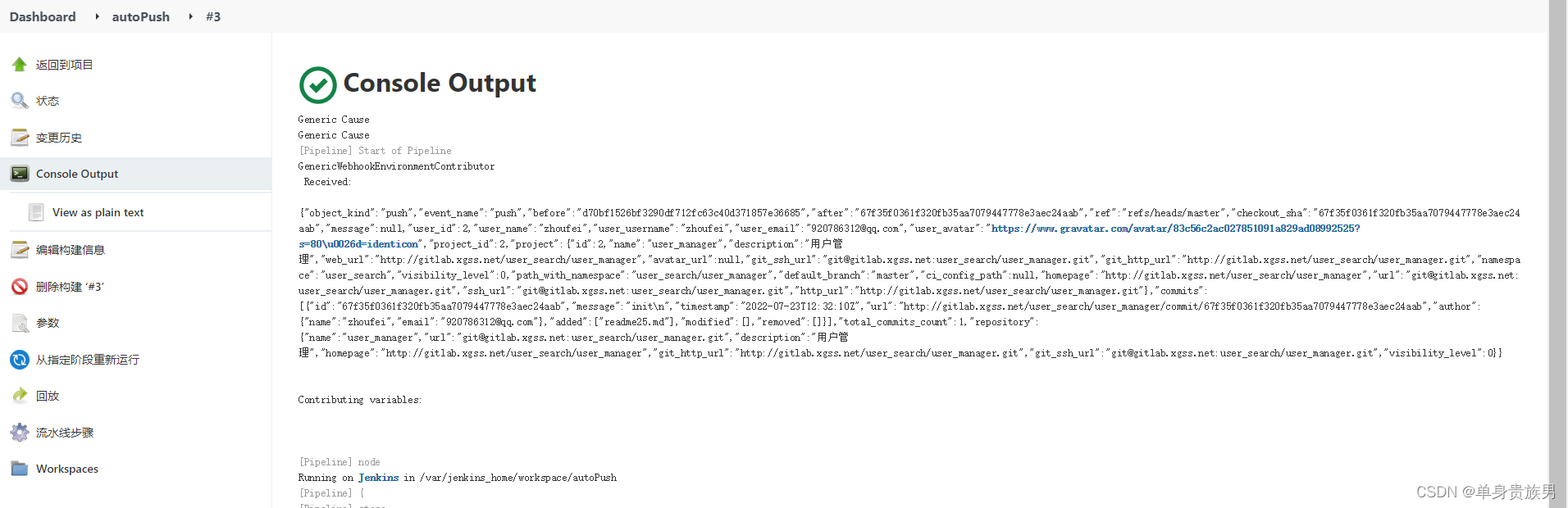
Jenkins--部署--3.1--代码提交自动触发jenkins--方式1

高效时代,电商运营如何靠RPA快速提效?

Have you ever learned about these architecture designs and architecture knowledge systems?(Architecture book recommendation)
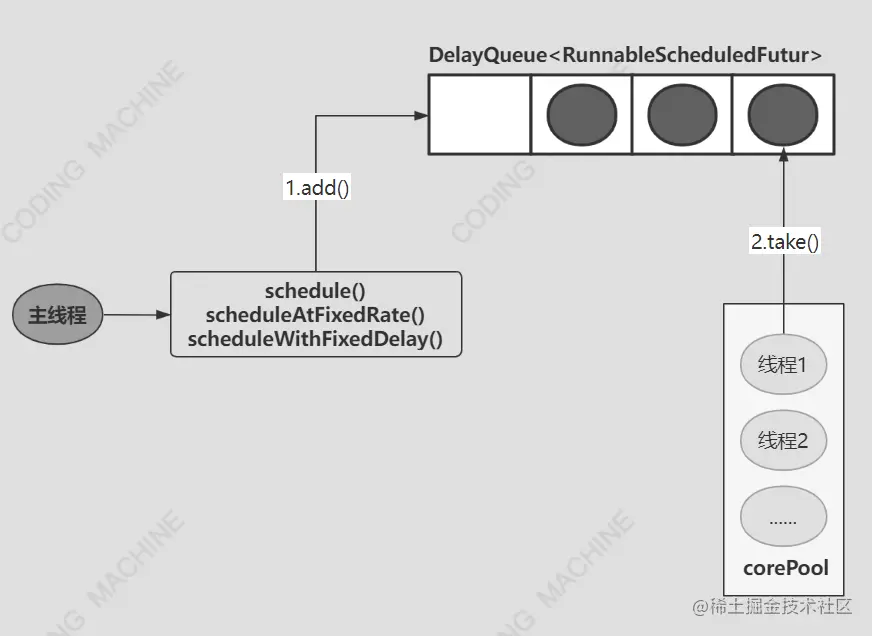
线程池的使用及ThreadPoolExecutor源码分析
随机推荐
【微信小程序】本地服务页面案例实现
HikariCP database connection pool, too fast!
【Redis】通用命令
用了TCP协议,就一定不会丢包嘛?
RetinaFace: Single-stage Dense Face Localisation in the Wild
mysql连接池的实现
Pytorch的LSTM参数解释
2022牛客暑期多校训练营4(ADHKLMN)
瑞吉外卖项目剩余功能补充
system_error错误处理库学习
Jenkins--基础--07--Blue Ocean
Rust from entry to master 03-helloworld
【Flink 问题】Flink 如何提交轻量jar包 依赖该如何存放 会遇到哪些问题
AI目标分割能力,无需绿幕即可实现快速视频抠图
“蔚来杯“2022牛客暑期多校训练营4
每天花2小时恶补腾讯T8纯手打688页SSM框架和Redis,成功上岸美团
[Must read] Mylander valuation analysis, electrical stimulation products for pelvic and postpartum rehabilitation
一文带你了解推荐系统常用模型及框架
LeetCode第三题(Longest Substring Without Repeating Characters)三部曲之一:解题思路
十、 网络管理