This paper is the fourth in a series of typical distributed systems analysis , This paper mainly introduces Dynamo, In a Amazon Decentralised used within the company 、 Highly available distributed key-value The storage system .
In the first part of a typical distributed systems analysis series MapReduce The main concerns of this series are presented in :
- The system is in performance 、 Extensibility 、 Usability 、 The measure of consistency , especially CAP
- How to realize the horizontal expansion of the system , How it's sliced
- The performance of the metadata server of the system 、 Usability
- The replica control protocol of the system , Is it centrization or decentralization
- For centralized replica control protocols , How the center is elected
- What protocols are used in the system 、 theory 、 Algorithm
The core purpose of this paper is to answer these questions .
This paper addresses :https://www.cnblogs.com/xybaby/p/13944662.html
Dynamo brief introduction
Dynamo Compared with the previous analysis Bigtable, Or I use the most NoSql MongoDB The biggest difference , I think it's De centralization (decentralized). stay Dynamo The various technologies used in , Such as Vector Clock、Consistent Hash、Gossip etc. , In part, it's all about decentralization .
What's called decentralization here , It's in the replica set (replicaset) There is no central node in , All nodes have equal status , Everyone can accept the update request , Reach agreement on data through mutual consultation . Its advantage lies in its strong usability , But the consistency is weak , Basically, it's all final consistency (eventually-consistent), therefore , It can be said that CAP I chose A - Availability.
And the opposite of decentralization -- Centralization , Already in the article Study the central replication set of distributed systems with problems It is introduced in detail in , In short , The replica set is updated by a central node (Leader、Primary) To execute , Maximize consistency , If the central node fails , Even if there is a master-slave switch , It also often causes tens of seconds of unavailability , therefore , It can be said that CAP I chose C - Consistency .
How to balance consistency and usability , It depends on the specific business requirements and application scenarios .Dynamo Is in Amazon A distributed internal use KV The storage system , and Amazon As an e-commerce website , High availability is necessary ,“always-on”. Even if there are occasional data inconsistencies , Business is also acceptable , And it's relatively easy to deal with inconsistencies , For example, the example of shopping cart mentioned in the paper .
What needs to be noted here is ,Dynamo and DynamDB It's two different things . The former is Amazon For internal use kv Storage , stay 07 Year paper Dynamo: Amazon's Highly Available Key-value Store Appearance ; While the latter is AWS Provided NoSql Data storage services , Began in 2012.
Dynamo Detailed explanation
What's interesting is that , In the paper , There is no such thing as an architecture diagram , There's only one watch , It introduces Dynamo Some of the general technologies used :
focuses on the core distributed systems techniques used in Dynamo: partitioning, replication, versioning, membership, failure handling and scaling.
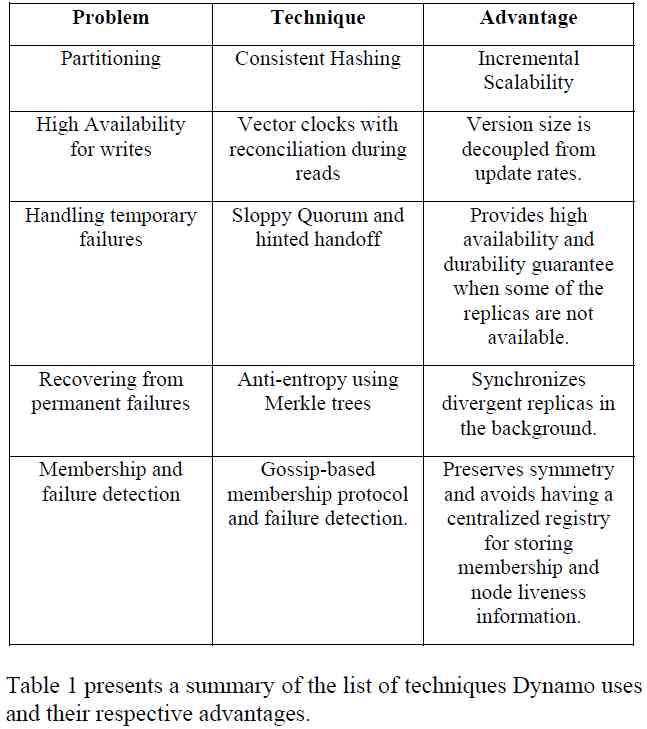
The main contribution of this work for the research community is the evaluation of how different techniques can be combined to
provide a single highly-available system.
It's through the combination that these are well known (well-known) Technology , The implementation of such a highly available storage system .
Next, I'll take a look at it in detail Dynamo How to use these technologies to solve the related problems .
Consistent hash
Dynamo A consistent hash is used (consistent hash) As data fragmentation (data partition) The way , Before that Data partition of distributed system with problem learning Different ways of data fragmentation have been introduced , It also includes consistent hashing . In short ,Consistent hash:
- It's a distributed hash table (DHT, distribution hash table) A concrete realization of
- Metadata ( Data to storage node mapping relationship ) Less
- Join in storage node 、 When you exit the cluster , Less impact on Clusters
- By introducing virtual nodes (virtual node), It can make full use of heterogeneous information of storage nodes
Generally speaking ,partition and replication It's two separate questions , But in Dynamo in , Both are based on consistent hash.
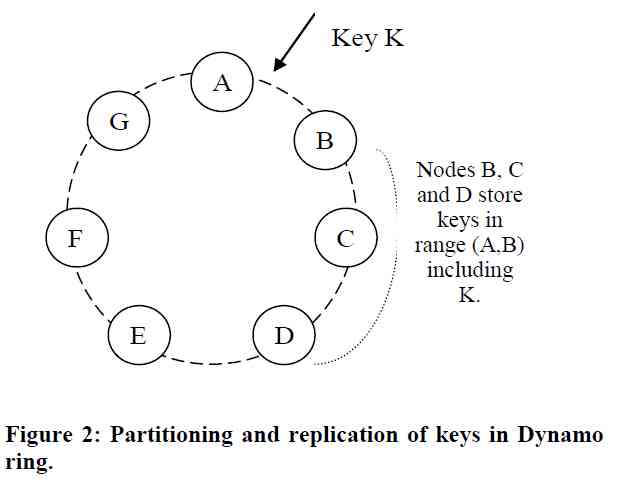
Suppose the number of replica sets is N, So one key First map to the corresponding node(virtual node), This node is called coordinator, And then copied into this coordinator Clockwise N - 1 A node , This introduces another concept preference list, That is, a key List of nodes that should be stored .
As shown in the figure above , Key K Corresponding coordinator by node B, meanwhile ,Node C, D It also stores key K The data of , Namely its preference list by [B、C、D...]
There are two points to note :
- Aforementioned node It's all virtual nodes , So for fault tolerance ,preference list It should be different physical nodes , So it's possible to skip some virtual nodes on the ring
- The replica set is N when ,preference list It will be longer than N, This is also to achieve "always writeable“ The goal of , Later on sloppy quorum and hinted handoff It will be mentioned again .
Object versioning(vector clock)
In decentralized replica set , Each node can accept reading and writing data , Maybe it's because of something client Unable to connect to coordinator, It may also be for load balancing . If multiple nodes simultaneously accept write operations , Then you can use object versioning (object versioning) To maintain a consistent view of data on different nodes . stay Dynamo in , And vector clock is used vector clock To determine the order between writes .
vector clock Record an incremental sequence number for each node , Every time the node operates , Its serial number is added with 1, Data synchronization between nodes 、 And when reading data from a node , It will also carry the corresponding version number .
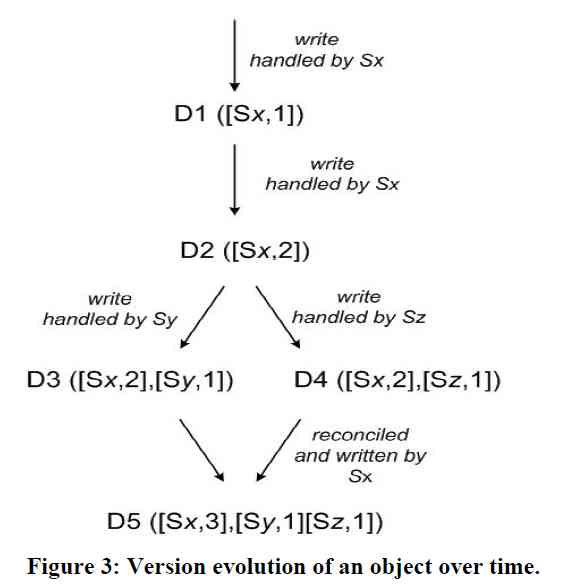
As shown in the figure above , Replica sets are created by Sx, Sy, Sz Three nodes , At the beginning, the serial number was 0, And then to some key There are the following operations :
- node Sx Accept write operations ,value by D1, Corresponding vector clock by [Sx, 1]
- node Sx Accept the write again ,value Turn into D2, Corresponding vector clock by [Sx, 2]
- This data ( together with vector clock) Copied to node Sy,Sz
- Two operations happened at the same time
- node Sy Accept write operations ,value Turn into D3, Corresponding vector clock by ([Sx, 2], [Sy, 1])
- node Sz Accept write operations ,value Turn into D4, Corresponding vector clock by ([Sx, 2], [Sz, 1])
- Sy、Sz Synchronize data to Sx,D3、D4 The corresponding version number does not have a partial order relationship ( The so-called partial order relation , namely A Every dimension of a vector is equal to or greater than B The corresponding dimension of a vector ), So there's no way to be sure of this key Corresponding value Should be D3, still D4, So both values will be saved .
Both versions of the data must be kept and presented to a client (upon a read) for semantic reconciliation.
- Until Sx There was a read operation on , The return value of the read operation should be D3、D4 A list of , The client decides how to handle the conflict , Then, the value after the conflict is resolved D5 Write To Sx, The vector clock is [(Sx, 3), (Sy, 1), (Sz, 1)]. here D5 And D3、D4 There is obviously a partial order relationship between them .
But in step six above , If at the node Sy At the same time “ Reading data -- Conflict resolution ” The process of , write in D6 [(Sx, 3), (Sy, 2), (Sz, 1)], that D5、D6 Conflict again .
You can see from above that ,vector clock Will automatically merge conflicts with partial order relations . But logically concurrent ,vector clock There's nothing we can do , At this time, how to solve the conflict faces two problems
First of all : When to resolve conflicts ?
It's when you write data , When reading data . The difference is ,Dynamo Choose to resolve conflicts when reading data , In order to make sure You can always write (always writeable). Of course , Conflicts are handled only when data is read , It may also lead to data conflict for a long time -- If you don't use it to read data .
second : Who's going to solve the conflict ?
It's by the system ( And Dynamo Oneself ) Or by the application ? The system lacks necessary business information , It's hard to make the right choice in a complex situation , So you can only do some simple and crude strategies , such as last write win, And it depends on global time, Need to cooperate with NTP Use together .Dynamo It's up to application developers to handle conflicts , Because specific applications clearly know how to deal with conflicts in specific environments .
Does this increase the burden on developers ? stay Amazon In the technical architecture of , It's always been about decentralizing 、 Service Oriented Design ,“Design for failure ” Has become the basic principle of system architecture , So this is for Amazon There is no extra complexity for the program .
Quorum
Quorum It's a very simple replica management mechanism , In short ,N Of the copies , Each write request W Copies succeeded , Every read from R Copy reads , as long as W+R > N, To ensure that the latest data is read .
This mechanism is very intuitive , I learned it in high school ,W and R There must be intersection between them .
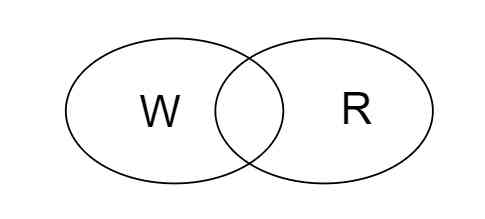
Of course , In engineering practice, it's not just operation W or R Nodes , But just wait until W or R The return of nodes can be , For example Dynamo in , All operations will be sent to preference list In front of N Active nodes .
Dynamo in , Allow configuration R、W、N Parameters , So that the application can be considered comprehensively Usability 、 Uniformity 、 performance 、 cost Other factors , Choose the combination that best suits the specific business . This is in Cassandra、Mongodb There are also relevant expressions in .
But here's the thing ,DDIA Pointed out in , Even if quorum, To ensure the W+R > N, There will still be some Corner case Make the data read out of date (stale data)
- Write at different nodes concurrently , There was a conflict , If the system automatically handles conflicts , Used a similar LWW(Last Write Win) The arbitration mechanism of , Due to clock drift on different nodes , There may be inconsistencies
- Most distributed storage , There's no isolation Isolation, So when reading and writing are concurrent , It is possible to read the data being written
- If the writing fails , That is, the number of successful writes is less than W, Nodes that have been written are not rolled back .
- There's another situation , Namely Dynamo Used in the Sloppy quorum
Sloppy quorum and hinted handoff
As mentioned earlier preference list, That is, a key List of storage locations in the ring , Although the number of replica sets is N, but preference list The length of is usually longer than N, This is to ensure that “always writable”. such as N=3,W=2 The situation of , If there is 2 Temporary failures of nodes , So strictly (strict) quorum, Can't write success , But loose (sloppy) quorum Next , You can write data to a temporary node . stay Dynamo in , This temporary node will be added to preference list At the end of , In fact, it is the next node on the consistent hash ring that does not have the partition .
Of course , This temporary node knows where the data should theoretically exist , So it will be temporarily stored in a special location .
The replica sent to temp node will have a hint in its metadata that suggests which node was the intended recipient of the replica
Wait until the original node of the data (home node) After recovery , Getting data in packaging , This process is called hinted handoff
therefore ,sloppy quorums Not in the traditional sense Quorum, Even satisfy W+R > N, There's no guarantee of reading the latest data , Just to provide better write availability .
Replica synchronization
hinted handoff Only temporary failures of nodes can be solved , Consider this scenario , The temporary node will send the data a moment before home node Before , The temporary node is also down , that home node The data in is inconsistent with the data of other nodes in the replica set , At this time, we need to find out which data are inconsistent , And then synchronize this data .
Because of the written keys May be anywhere in the ring , So how to find out what's inconsistent , This reduces the number of disks IO、 And the amount of data transmitted over the network ,Dynamo Used in Merkle Tree.
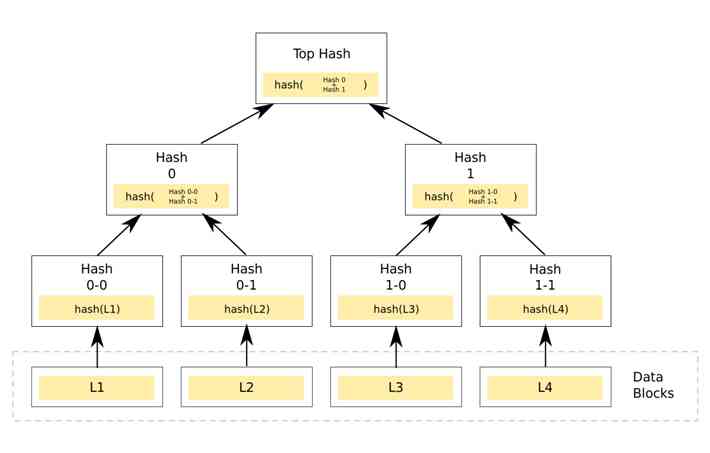
stay Merkle Tree Study In this article , There are clear and easy to understand introductions , Here is just a brief summary of the main points :
- Each leaf node corresponds to one data block, And record it hash value , A non leaf node records all its children hash value
- Start the comparison at the root node , If hash Value consistent , That means the two trees are the same , Otherwise, compare the left and right subtrees respectively
- Uniform recursion , Until the leaf node , Just copy inconsistent leaf nodes
Specifically Dynamo How to apply Merkle Tree What about
- The physical node maintains an independent for each virtual node Merkle Tree
- When comparing , Just follow Merkle Tree How to do it , Start the comparison at the root node
Merkle Tree Speed up the comparison operation , But build one Merkle Tree It's also a time-consuming process , So when adding or deleting nodes , Some virtual node The maintenance of key range It's going to change , So we need to rebuild this Merkle Tree.
Nodes to join 、 The effect of deletion is more than that , For example, when adding nodes , Part of it needs to be moved key range, This requires scanning the storage files of the original node , Find out this part keys , And then send it to the target node , It's going to bring a huge amount of IO operation ( Of course , This is highly dependent on how the storage engine organizes files ). These operations will affect online services , So it can only be executed slowly in the background , Efficiency is very low , It is mentioned in the paper that It takes almost a whole day to get a node online .
Advanced partition scheme
The nature of the problem , It's about data partition Depend on virtual node The location of , Two faces adjacent virtual node Between key range It's just one. partition, And every one of them individual partition Corresponding to a storage unit . This is what the paper says
The fundamental issue with this strategy is that the schemes for data partitioning and data placement are intertwined.
data placement Is refers to data Storage form of , In fact, that is virtual node Position on Hash ring .
So the solution is decoupling partitioning and placement, That's data partition No longer dependent on virtual node The absolute position on the ring .
stay Dynamo in , The improvement plan is as follows : take hash The rings are equally divided into Q Share , Of course Q Much more than the number of nodes , Each node is Q/S Share partition(S Is the number of nodes ), When nodes are added or deleted , Just adjust partition Mapping to nodes .
This solves the two problems mentioned in the premise :
- When nodes are added or deleted , The transfer of data to partition In units of , Can be directly in the unit of file , No need to scan the file and send it again , Realization zero copy, More efficient
- One partition It's just one. Merkle Tree, So there's no need to rebuild Merkle Tree
This kind of plan is similar to redis cluter It's like ,redis cluter It is also divided into 16384 individual slot, According to the approximate number of nodes slot Assign to different nodes .
Failure Detection
What's interesting is that ,Dynamo The fault of the node is considered to be short-term 、 Recoverable , So it won't take extreme automatic fault tolerance , That is, it will not actively migrate data to achieve rebalance. therefore ,Dynamo Using the explicit mechanism (explicit mechanism), Manual operation by the administrator , Add or delete nodes to the cluster .
A node outage rarely signifies a permanent departure and therefore should not result in rebalancing of the partition assignment or repair of the unreachable replicas.
It's different from other systems , If more than half of the nodes think that a node is not available , Then the node will be kicked out of the cluster , Next, execute the fault-tolerant logic . Of course , Automatic fault tolerance is complex , It's also a complex process for more than half of the nodes to reach a consensus that a node is not available .
There may be questions , that Dynamo This will not be able to respond to failures in a timely manner ? Will it lead to unavailability 、 Even lost data ? In fact, it was mentioned before ,Dynamo Yes Sloppy quorum and hinted handoff Mechanism , Even if the response to the fault is delayed, there will be no problem .
therefore ,Dynamo The fault detection of is very simple , Point to point ,A Can't access B,A You can think of it unilaterally B It's broken down . An example , hypothesis A Act as a data write Coordinator, Need to operate to B, I can't visit B, Then it will be in Preference list Find a node in ( Such as D) To store B The content of .
Membership
stay Dynamo in , There is no metadata server (metadata server) To manage the metadata of the cluster : such as partition The mapping of nodes is concerned with . When the administrator manually adds nodes to 、 remove hash After the ring , First of all, the mapping needs to change , secondly hash All nodes on the ring need to know the mapping relationship after the change ( Thus we know the addition and deletion of nodes ), Reach a consensus view .Dynamo Used Gossip-Based Protocol to synchronize this information .
Gossip agreement This article is about Gossip The agreement has a detailed introduction , I won't repeat it here . But you can have a look later Gossip stay redis cluster The specific implementation of .
Summary
Answer the questions at the beginning of the article
- The system is in performance 、 Extensibility 、 Usability 、 The measure of consistency , especially CAP
Sacrifice consistency , The pursuit of high availability
- How to realize the horizontal expansion of the system , How it's sliced
Use consistency hash, First put the whole hash ring All of them are Q branch , And then it's equally distributed to nodes
- The performance of the metadata server of the system 、 Usability
No additional metadata server , Metadata through Gossip The protocol broadcasts between nodes
- The replica control protocol of the system , Is it centrization or decentralization
De centralization
- For centralized replica control protocols , How the center is elected
nothing
- What protocols are used in the system 、 theory 、 Algorithm
Quorum、 Merkle Tree、Gossip
Introduce in the paper Merkle Tree when , The term is used anti-entropy, Translate it into Anti entropy , You should have learned entropy The concept , But now I forget about it . Loosely interpreted as Entropy is the degree of chaos , Anti entropy is regional stability 、 Agreement ,gossip That's one anti-entropy protocol.
A very sympathetic sentence : The reliability and scalability of the system depends on how to manage the application related state
The reliability and scalability of a system is dependent on how its application state is managed.
Is a stateless Stateless, Or manage it by yourself , Or leave it to a third party (redis、zookeeper), It greatly affects the design of architecture .
References
Dynamo: Amazon's Highly Available Key-value Store
[ translate ] [ The paper ] Dynamo: Amazon's Highly Available Key-value Store(SOSP 2007)