当前位置:网站首页>R language [data management]
R language [data management]
2022-07-05 21:04:00 【桜キャンドル yuan】
Catalog
1、 Direct horizontal consolidation
2. If you need to specify an index
6、 ... and 、 Get subset of data set
1、 Select the variable ( Column )
2、 Remove variables ( Column )
7、 ... and 、 Using functions subset() Select observation
8、 ... and 、 Utility functions for processing data objects
Ten 、 Apply the function to each list element
11、 ... and 、 Apply functions to rows or columns
Twelve 、 Apply functions to group data
13、 ... and 、 Apply functions to row groups
fourteen 、 User defined functions
One 、mode Access to type
stu_name <- "Richard"
yield <- 100
mode(stu_name)
mode(yield)

List related operations
v <- c(1,2,3)
v
v <- c(v,4,5)
v
w <- c(6,7,8,9)
v <- c(v,w)
v[15] <- 0
v
append operation
append You can append elements , In the specified after Then you can specify the location of the append
x <- 1:10
x
y <- append(x,100,after=5)
y
z <- append(x,100,after=0)
z

Here we can see that we can specify to add some two columns in the table , Averaging , The generated data will generate a new column of data .
mydata <- data.frame( x1 = c(1,2,3,4), x2 = c(5,6,7,8))
mydata
mydata$sumx <- mydata$x1+mydata$x2
mydata
mydata$meanx <- (mydata$x1+mydata$x2)/2
mydata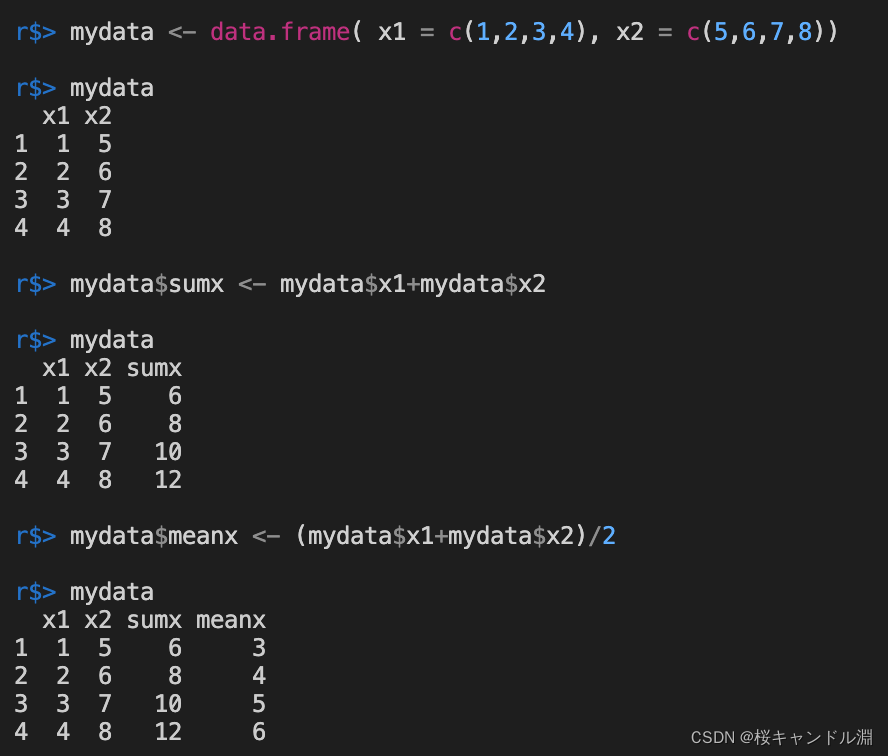
attach And detach
attach And detach It's used in pairs .attach It can be connected to the table ,detach You can cancel the connection with the table
attach(mydata)
mydata$sumx <- x1+x2
mydata$meanx <- (x1+x2)/2
detach(mydata)
mydata <- transform(mydata, sumx=x1+x2, meanx=(x1+x2)/2)
transform
Use transform To change the data frame
mydata <- transform(mydata, sumx=x1+x2, meanx=(x1+x2)/2)
mydata

Two 、 Special values
From the following test , We can see if it's NULL Words ,R Language loss generates an object for us , But there is no storage space . If it is NA Words ,R Missing allocates a space to the object , But the content in this space is spatiotemporal .
NA Indicates a value that cannot be obtained
NULL Indicates a value that cannot be obtained because it does not exist
Inf infinite ,,1/0 What you get is Inf
NAN Can't express , It's not a number , Use Inf-Inf What you get is NAN
x <- NULL
y <- NA
length(x)
length(y)
Check to see if there is NA
y <- c(1,2,3,NA)
is.na(y)
If the data contains NA It cannot be calculated , But we can use na.rm=T Come and take our NA It's ignored
x <- y[1]+y[2]+y[3]+y[4]
x
z <- sum(y)
z
l <- sum(y, na.rm=T)
l
na.omit
We can also use na.omit() To remove all of us including NA The observation of .
mydata <- read.table("/Users/yangkailiang/Documents/R/data/leadership.csv",
header=T, sep=",")
mydata
newdata <- na.omit(mydata)
newdata
3、 ... and 、 Type conversion
| Determine whether it is this type | Type conversion |
| is.character() | as.character() |
| is.vector() | as.vector() |
| is.matrix() | as.matrix() |
| is.data.frame() | as.data.frame() |
| is.factor() | as.factor() |
| is.logical() | as.logical() |
| is.numeric() | as.numeric() |
a <- c(1,2,3)
a
is.numeric(a)
is.vector(a)
a <- as.character(a)
is.numeric(a)
is.vector(a)
is.character(a) 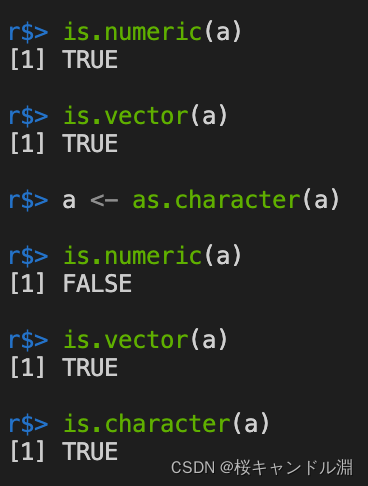
Four 、 Data sorting
sort()/order()
We can see from the following test code , If used directly sort Its own words , The order of its own data will not change , Burning stone, if we send the sorted data to other variables to receive , The received data is in good order . The default order is ascending .
x <- c(12,4,7,11,2)
sort(x)
x
y <- sort(x)
y
z <- order(x)
x[z]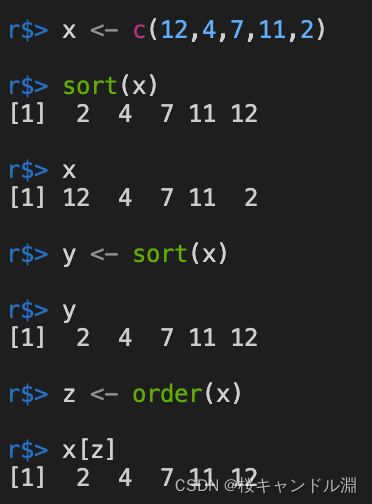
Besides , We can also use order Make our data orderly . but order What is generated is the index value sorted by the size of each element in the array . So we need to use x[z] Make our data present an orderly state . As we can see from the figure below x The first element in should be placed in the fifth position , The second element should be in the second position , And so on .

Sort a column in the table
# According to our age Sort columns
newdata <- mydata[order(mydata$age),]
# According to our age Sort columns in descending order
newdata2 <- mydata[order(mydata$age,decreasing=T),]
# First according to gender Sort , Again according to age Sort in ascending order
newdata3 <- mydata[order(mydata$gender,mydata$age),]
attach(mydata)
# First according to gender Sort , Then sort by age in descending order
newdata4 <- mydata[order(gender,-age),]
newdata4
detach(mydata)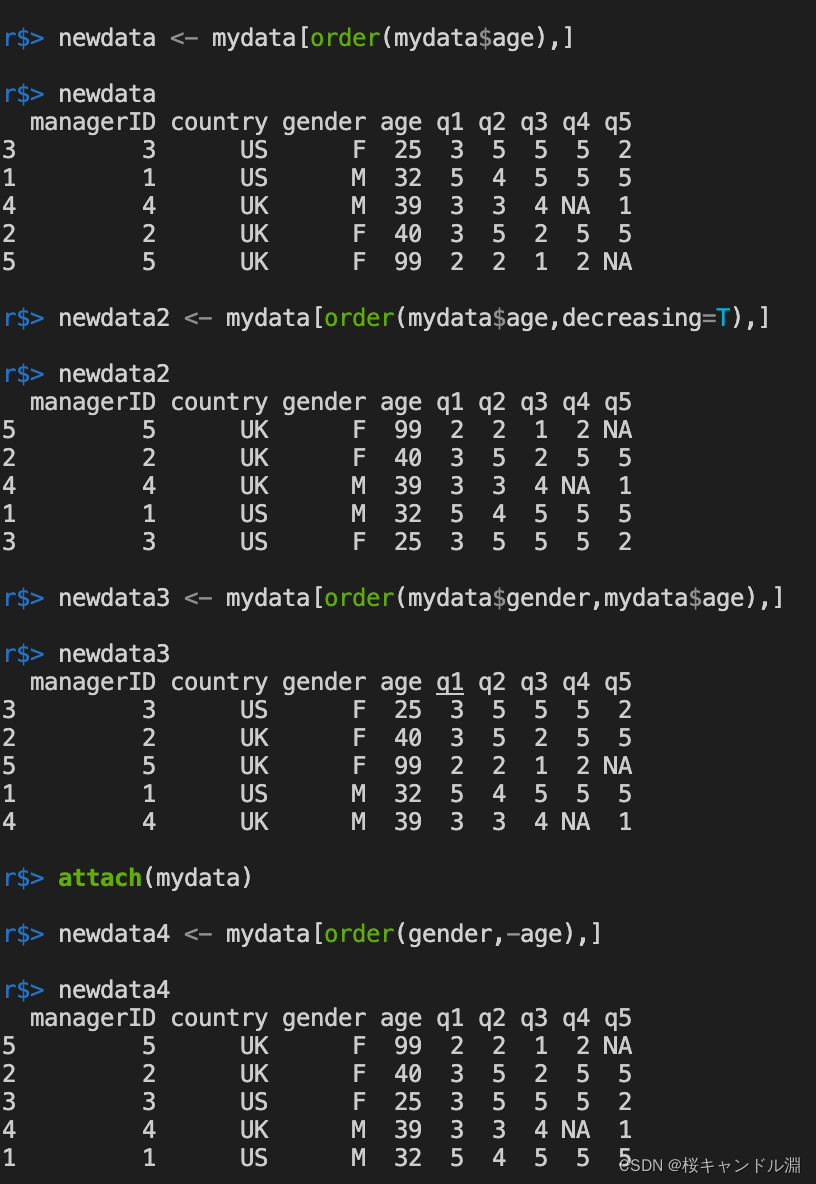
5、 ... and 、 Data set merging
1、 Direct horizontal consolidation
Direct horizontal merge does not need to specify a public index
C = cbind(A,B)
2. If you need to specify an index
C = merge(A,B, by=" Public index ")
C = merge(A,B, by="ID")
C = merge(A,B, by=c("ID","Country"))
3. Vertical merger
If vertical consolidation is required ,A And B,A And B You need to have exactly the same variables ( The order can be different )
4. Example
Here are the data of our four tables
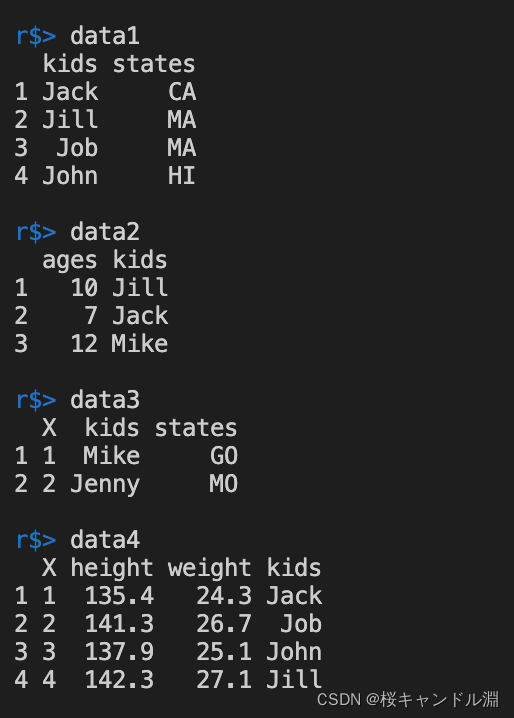
# Merge our two tables directly ( about )
cdata <- cbind(data1,data3)
data5 <- cbind(data1,data4)
# Use merge Function words , The corresponding values will be merged automatically
data6 <- merge(data1,data2)
data7 <- merge(data1,data4)
# according to kids Merge and sort columns
data8 <- merge(data1,data4,by="kids")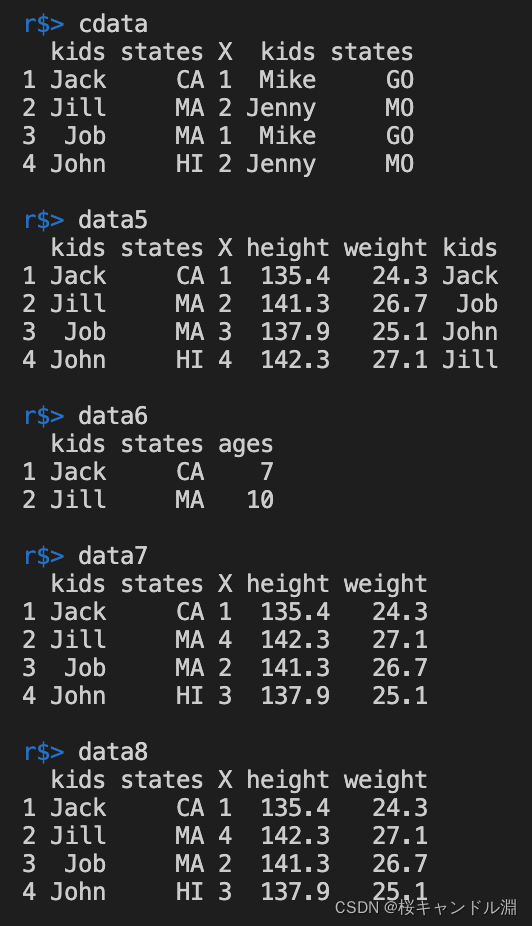
6、 ... and 、 Get subset of data set
1、 Select the variable ( Column )
# From our mydata Select all rows , Take the first place 1,2,4 Column
newdata <- mydata[,c(1,2,4)]
# From our mydata Select all rows , take managerID,country,age Column
newdata2 <- mydata[,c("managerID","country","age")]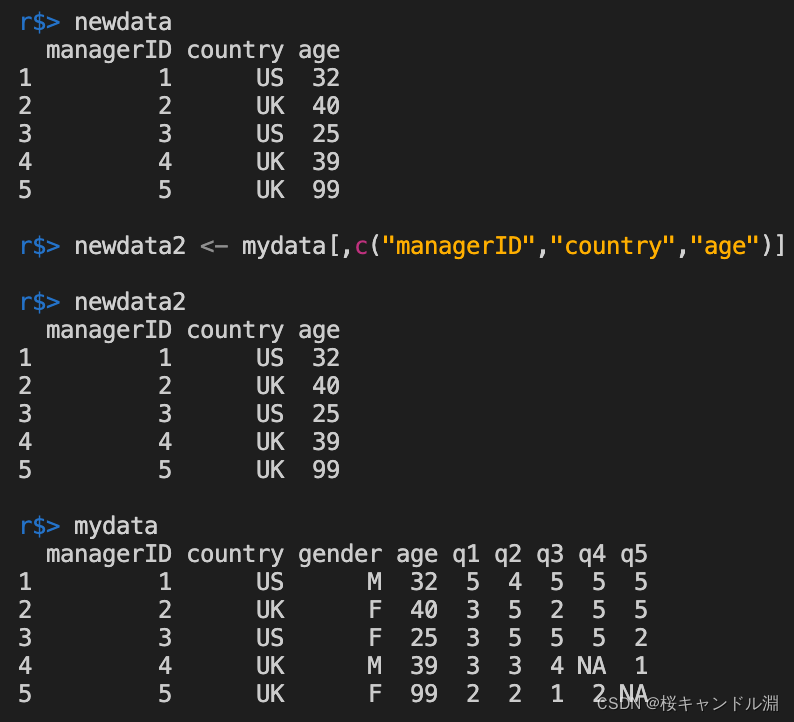
2、 Remove variables ( Column )
mydata
# Method 1
# To eliminate mydata The first row of planting , Second column , The fourth column
newdata <- mydata[,c(-1,-2,-4)]
newdata
# Method 2
# To eliminate "managerID","country","age" These three columns , Will return a vector of boolean type
#%in% For an operator
delvar <- names(mydata) %in% c("managerID","country","age")
newdata2 <- mydata[!delvar] 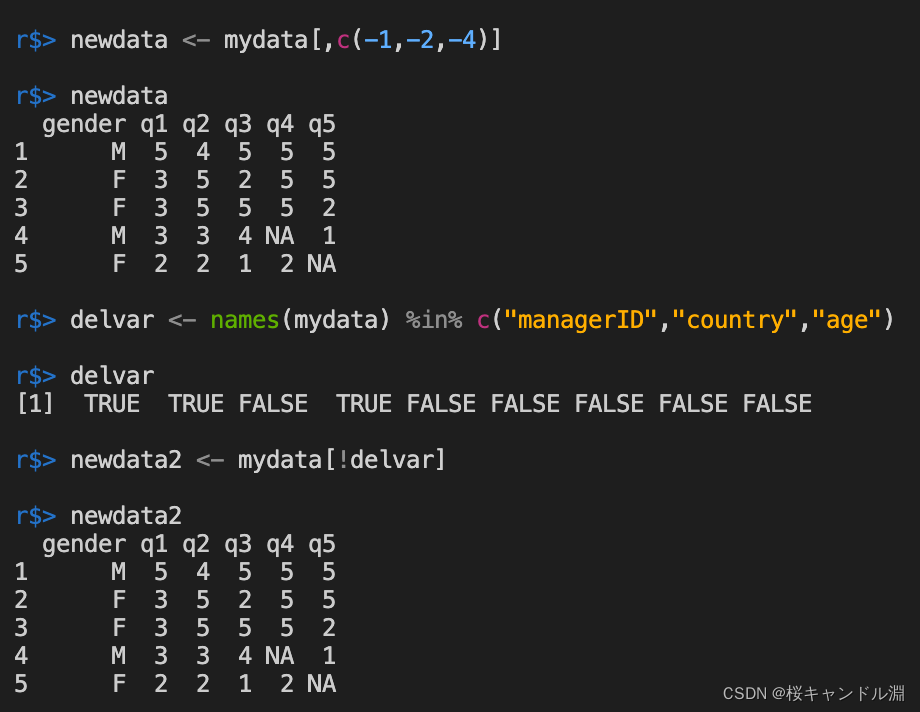
3. Selected Observations
# Select one to three rows , All columns
newdata <- mydata[1:3,]
newdata
# The selected gender is M, And older than 30 The observation of
newdata1 <- mydata[which(mydata$gender=="M" & mydata$age>30),]
newdata1
attach(mydata)
# The selected gender is M, And older than 30 The observation of
newdata2 <- mydata[which(gender=="M" & age>30),]
newdata2
detach(mydata)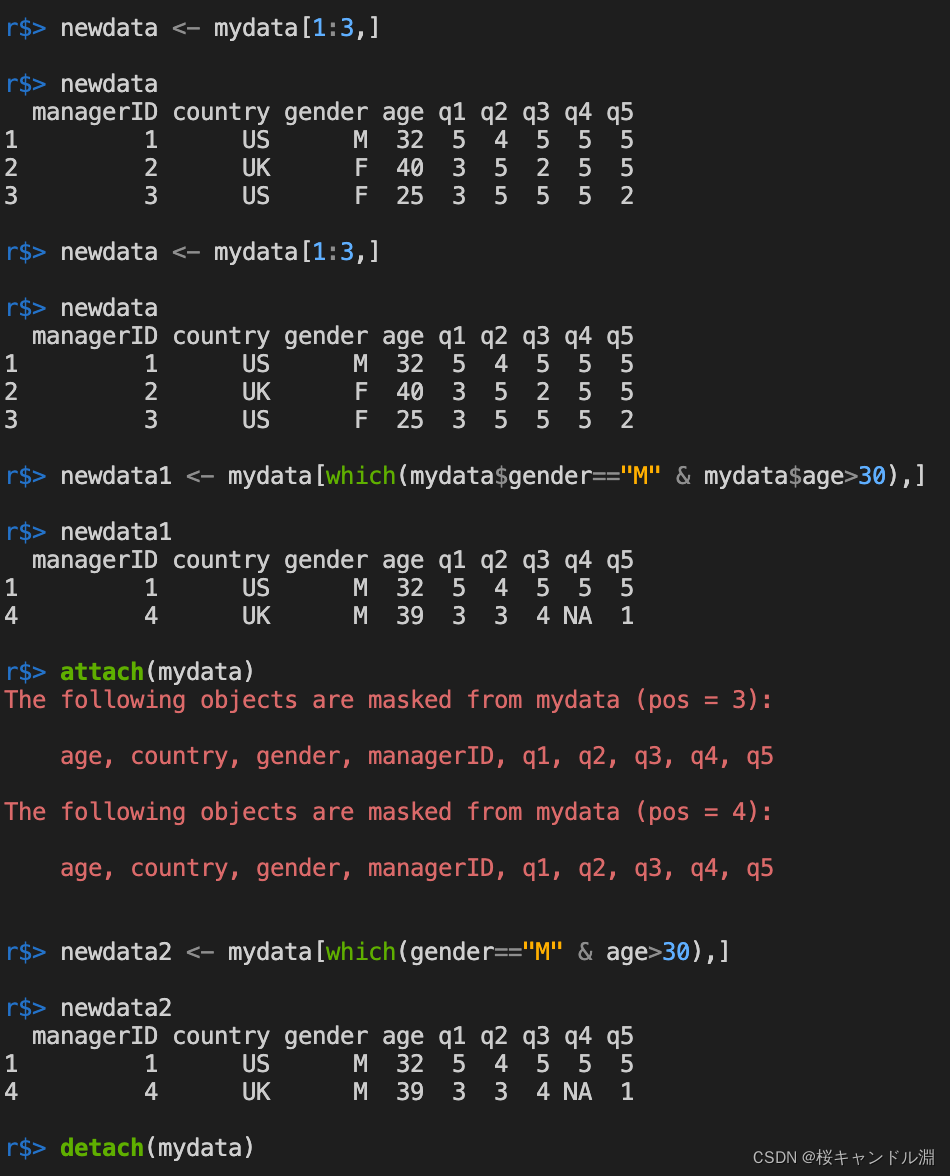
7、 ... and 、 Using functions subset() Select observation
# For us mydata Filter age ≥ in data frame 35 Or younger than 24 Observation of , And put it q1,q2,q3 The data of the column is displayed
newdata <- subset(mydata, age>=35 | age < 24,select=c("q1","q2","q3"))
newdata
# take mydata The gender of the data frame is M, And older than 25, Will the gender List to q4 The columns are all displayed
newdata2 <- subset(mydata, gender == "M" & age >25,select=gender:q4)
newdata2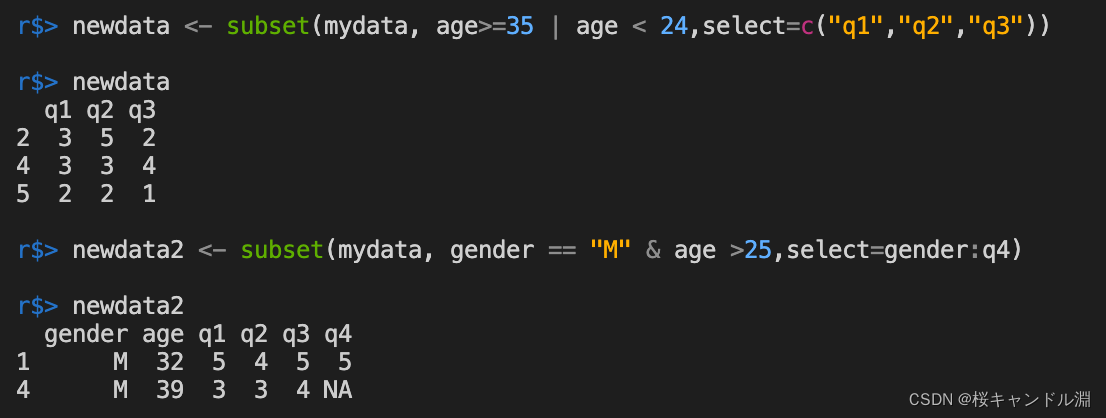
8、 ... and 、 Utility functions for processing data objects
length(newdata)
dim(newdata)
#str yes struct Abbreviation
str(newdata)
class(newdata)
mode(newdata)
names(newdata)
head(newdata)
tail(newdata)
ls(newdata)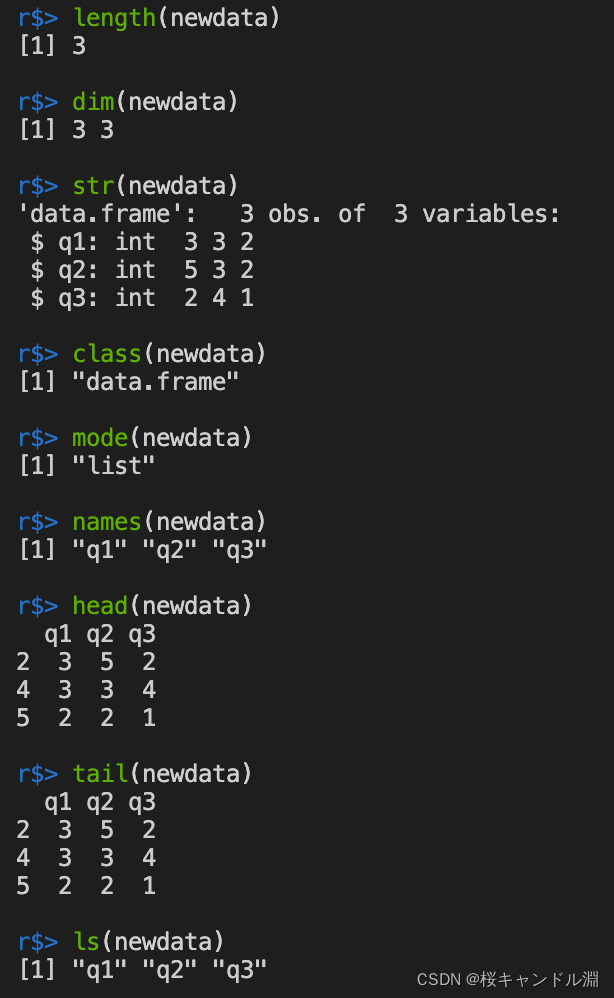
Nine 、 Vector grouping
split() The return value is a list , Separate the data set according to a factor variable .
library(MASS)
groups<-split(Cars93$MPG.city,Cars93$Origin)
groups[[1]]
groups[[2]]Ten 、 Apply the function to each list element
lapply The return result is a list
sapply The return result is a vector
scores <- list(S1=numeric(0),S2=numeric(0),S3=numeric(0),S4=numeric(0))
scores$S1 <- c(89,85,85,62,93,77,85)
scores$S2 <- c(60,100,83,77,86)
scores$S3 <- c(95,86,91,82,63,67,97,64,55)
scores$S4 <- c(67,63,83,89)
lapply(scores,length)
sapply(scores,mean)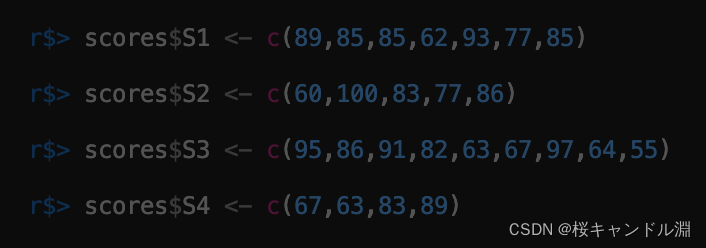

11、 ... and 、 Apply functions to rows or columns
apply()
results <- apply(matrix,1,function) # Process the rows of the matrix
results <- apply(matrix,2,function) # Process the columns of the matrixFor data frames , If the data type of each row is consistent , You can use apply To deal with it
If the column data types of the data frame are inconsistent , You need to use the above lapply And sapply To process
Mat_long <- matrix(c(-1.85,0.94,-0.54,-1.41,1.35,-1.71,-1.01,-0.16,-0.35,-3.72,1.63,-0.28,-0.28,2.45,-1.22),nrow=3,dimnames=list(c("Moe", "Larry","Curly"),c("trial1","trial2","trial3","trial4","trial")))
apply(Mat_long,1,mean)
apply(Mat_long,1,range)
apply(Mat_long,2,mean) 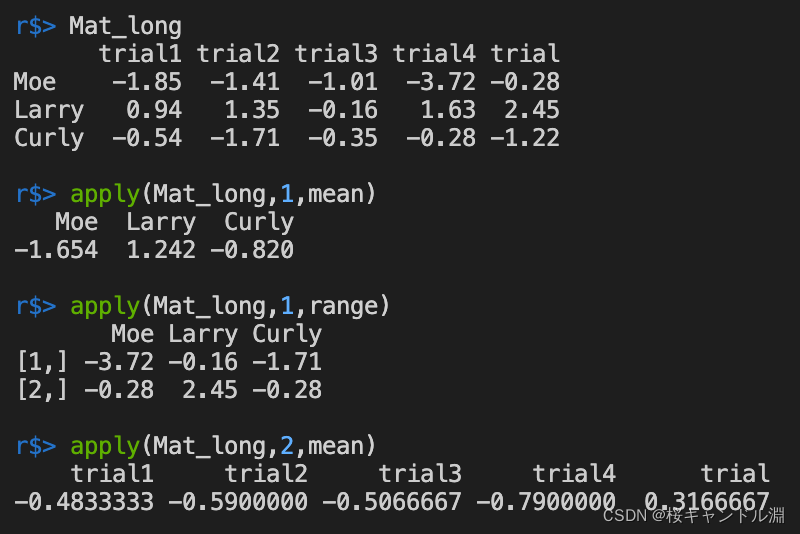
Twelve 、 Apply functions to group data
tapply(vector,factor,function)
vector It's a vector ,factor Is a grouping factor ,function It's a function , That is to say, we need to be right vector The method of carrying out
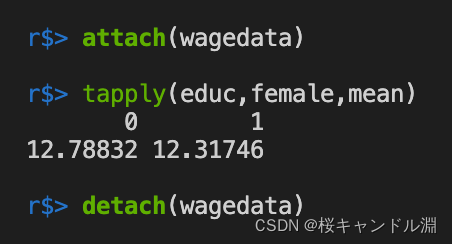
wagedata <- read.csv("/Users/Documents/R/data/wagedata.csv")
attach(wagedata)
# First the edu according to female Grouping , Then calculate the average value respectively
tapply(educ,female,mean)
detach(wagedata)
educ
13、 ... and 、 Apply functions to row groups
by(dataframe,factor,function)
dataframe It's a vector ,factor Is a grouping factor ,function It's a function
wagedata <- read.csv("/Users/Documents/R/data/wagedata.csv")
by(wagedata,female,mean)
fourteen 、 User defined functions
myfunction <- function(arg1,arg2,...){
statements
return(object)
}
# The following is the compilation of Pythagorean theorem
# The square of a vector is the square of each component , Then we add the squares of each component and square it , We can get the length of our third side .
lengththm <- function(x) {
thirdl <- sqrt(sum(x^2))
return(thirdl)
}
a <- c(3,4)
lengththm(a) 
15、 ... and 、 loop
for (var in seq) {
statements
}
while (condition) {
statements
}
x <- c(2,5,10)
for (n in x)
print(n^2) 
边栏推荐
- Simple getting started example of Web Service
- 【案例】定位的运用-淘宝轮播图
- hdu2377Bus Pass(构建更复杂的图+spfa)
- The transformation based on vertx web sstore redis to realize the distributed session of vertx HTTP application
- Web Service简单入门示例
- Open source SPL eliminates tens of thousands of database intermediate tables
- Is it safe to open a stock account by mobile phone? My home is relatively remote. Is there a better way to open an account?
- 判断横竖屏的最佳实现
- 《SAS编程和数据挖掘商业案例》学习笔记# 19
- CLion配置visual studio(msvc)和JOM多核编译
猜你喜欢

Using webassembly to operate excel on the browser side

Duchefa low melting point agarose PPC Chinese and English instructions
基于flask写一个接口
ArcGIS\QGIS无插件加载(无偏移)MapBox高清影像图
haas506 2.0开发教程 - 阿里云ota - pac 固件升级(仅支持2.2以上版本)
使用WebAssembly在浏览器端操作Excel
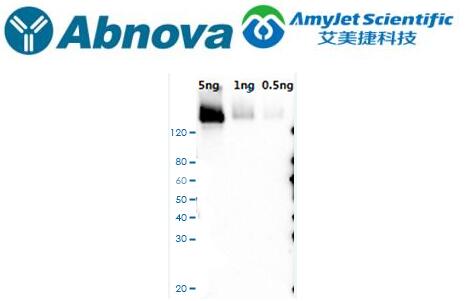
Abnova CRISPR spcas9 polyclonal antibody protocol
2. < tag hash table, string> supplement: Sword finger offer 50 The first character DBC that appears only once
教你自己训练的pytorch模型转caffe(二)
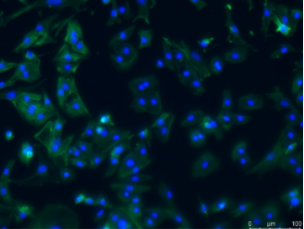
Abbkine trakine F-actin Staining Kit (green fluorescence) scheme
随机推荐
基于flask写一个接口
序列联配Sequence Alignment
CLion配置visual studio(msvc)和JOM多核编译
Duchefa cytokinin dihydrozeatin (DHZ) instructions
Traps in the explode function in PHP
Specification of protein quantitative kit for abbkine BCA method
研學旅遊實踐教育的開展助力文旅產業發展
Influence of oscilloscope probe on signal source impedance
ViewRootImpl和WindowManagerService笔记
Is it safe to open a stock account by mobile phone? My home is relatively remote. Is there a better way to open an account?
Use of thread pool
Sophomore personal development summary
Test of incombustibility of cement adhesives BS 476-4
学习机器人无从下手?带你体会当下机器人热门研究方向有哪些
Generics of TS
WPF gets the control in the datagridtemplatecolumn of the specified row and column in the DataGrid
2.<tag-哈希表, 字符串>补充: 剑指 Offer 50. 第一个只出现一次的字符 dbc
AITM2-0002 12s或60s垂直燃烧试验
Wood board ISO 5660-1 heat release rate mapping test
ODPS 下一个map / reduce 准备